Tensorflow, meski kehilangan landasan di lingkungan penelitian, masih populer dalam pengembangan praktis. Salah satu kekuatan TF yang membuatnya tetap bertahan adalah kemampuan untuk mengoptimalkan model untuk penerapan di lingkungan terbatas sumber daya. Ada kerangka kerja khusus untuk ini: Tensorflow Lite untuk perangkat seluler dan Penyajian Tensorflowuntuk keperluan industri. Ada cukup banyak tutorial tentang penggunaannya di Web (dan bahkan di Habré). Pada artikel ini, kami telah mengumpulkan pengalaman kami dalam mengoptimalkan model tanpa menggunakan kerangka kerja ini. Kami akan melihat beberapa metode dan pustaka yang menyelesaikan tugas, menjelaskan bagaimana Anda dapat menghemat ruang disk dan RAM, kekuatan dan kelemahan dari setiap pendekatan, dan beberapa efek tak terduga yang kami temui.
Dalam kondisi apa kami bekerja
Salah satu tugas NLP klasik adalah klasifikasi tematik teks pendek. Pengklasifikasi diwakili oleh banyak arsitektur yang berbeda, mulai dari metode klasik seperti SVC hingga arsitektur transformator seperti BERT dan turunannya. Kami akan melihat CNN - model konvolusional.
Batasan penting bagi kami adalah kebutuhan untuk melatih dan menggunakan model (sebagai bagian dari produk) pada mesin tanpa GPU. Ini terutama memengaruhi kecepatan pembelajaran dan kesimpulan.
Kondisi lain adalah bahwa model untuk klasifikasi dilatih dan digunakan dalam set yang terdiri dari beberapa bagian. Seperangkat model, bahkan yang sederhana sekalipun, dapat menggunakan banyak sumber daya, terutama RAM. Kami menggunakan solusi kami sendiri untuk menyajikan model, namun, jika Anda perlu beroperasi dengan sekumpulan model, lihat Penyajian Tensorflow .
Kami dihadapkan pada kebutuhan untuk mengoptimalkan model pada TF versi 1.x, yang sekarang secara resmi dianggap usang. Untuk TF 2.x, banyak teknik yang dibahas tidak relevan atau terintegrasi ke dalam API standar, dan oleh karena itu proses optimasinya cukup sederhana.
Mari kita lihat struktur model kita terlebih dahulu.
Bagaimana model TF bekerja
Pertimbangkan apa yang disebut CNN Dangkal - jaringan dengan satu lapisan konvolusional dan beberapa filter. Model ini telah bekerja cukup baik untuk klasifikasi teks di atas representasi kata vektor.

Untuk mempermudah, kita akan menggunakan himpunan representasi vektor yang telah dilatih sebelumnya dari dimensi v x k , di mana v adalah ukuran kamus, k adalah dimensi embeddings.
:
- Embedding-, .
- w x k. , (1, 1, 2, 3) 4 , 1 , 2 3 , .
- Max-pooling .
- , dropout- softmax- .
Adam, .
: .
, , 128 c w = 2 k = 300 () [filter_height, filter_width, in_channels, output_channels] — , 2*300*1*128 = 76800 float32, , 76800*(32/8) = 307200 .
? ( 220 . ) 300 265 . , .
TF . ( ), , , — ( ), . (). :
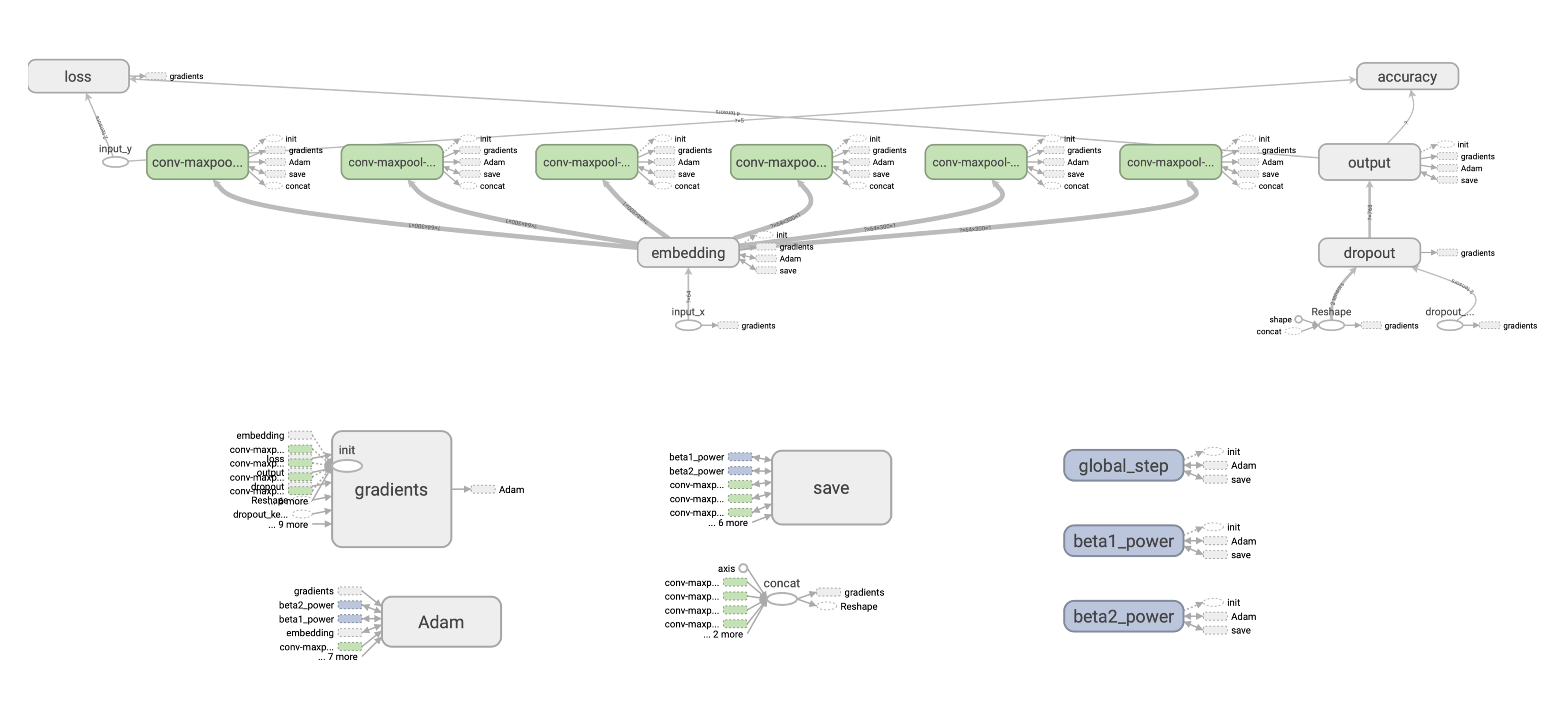
. , : SavedModel. , .
Checkpoint
, Saver API:
saver = tf.train.Saver(save_relative_paths=True)
ckpt_filepath = saver.save(sess, "cnn.ckpt"), global_step=0)global_step , , — cnn-ckpt-0.
<model_path>/cnn_ckpt :

checkpoint — . , TF . , .
.data , . , — 800 . , (≈265 ). ( ). , .
.index .
.meta — , (, , ), GraphDef, . , . — .meta , ? , TF - embedding-. , , , , , . , , :
with tf.Session() as sess:
saver = tf.train.import_meta_graph('models/ckpt_model/cnn_ckpt/cnn.ckpt-0.meta') # load meta
for n in tf.get_default_graph().as_graph_def().node:
print(n.name, n['attr'].shape)SavedModel
, . . API tf.saved_model. tf.saved_model, TF- (TFLite, TensorFlow.js, TensorFlow Serving, TensorFlow Hub).
:
saved_model.pb, , , .meta , (, ), API, ( CLI, ).
SavedModel — , . “” . , , - — , .
, CNN-, TF 1.x, . .
, 1 , :
-
. , , ( tools.optimize_for_inference ). -
. , , — , tf.trainable_variables(). -
, . , (. BERT). -
. , . .
, , . , forward pass, . , . 1 265 .
TF 1.x , .
( ) GraphDef:
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def() . : tf.python.tools.freeze_graph tf.graph_util.convert_variables_to_constants. ( ) (, ['output/predictions']), , , . .
output_graph_def = graph_util.convert_variables_to_constants(self.sess, input_graph_def, output_node_names), .
freeze_graph() ( , , ). graph_util.convert_variables_to_constants() :
with tf.io.gfile.GFile('graph.pb', 'wb') as f:
f.write(output_graph_def.SerializeToString())266 , :
# GraphDef
with tf.io.gfile.GFile(graph_filepath, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
#
self.input_x = tf.placeholder(tf.int32, [None, self.properties.max_len], name="input_x")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# graph_def
input_map = {'input_x': self.input_x, 'dropout_keep_prob': self.dropout_keep_prob}
tf.import_graph_def(graph_def, input_map), import:
predictions = graph.get_tensor_by_name('import/output/predictions:0'):
feed_dict = {self.input_x: encode_sentence(sentence), self.dropout_keep_prob: 1.}
sess.run(self.predictions, feed_dict), :
- . ,
sess.run(...). , CPU 20 ms, ~2700 ms. , . SavedModel . - RAM. RAM, . ~265 , . , TF GraphDef .
- – RAM TF . 1.15, TF 1.x, 118 MiB, 1.14 – 3 MiB.
, . ? / TF- tf.train.Saver. , , , :
- MetaGraph
tf.train.Saver . , :
saver = tf.train.Saver(var_list=tf.trainable_variables())MetaGraph . , meta . MetaGraph save:
ckpt_filepath = saver.save(self.sess, filepath, write_meta_graph=False)1014 M 265 M ( , ).
, TF 1.x:
- Grappler: c tensorflow
- Pruning API: google-research
- Graph Transform Tool:
, — tensorflow, Grappler. Grappler . , set_experimental_options. , zip . , zip , . Grappler .
google-research mask threshold, . . , , mask threshold, , , . .
Grappler, . : ? , ? , 0.99 . , mc, hex :

, , . . -, . -, , , , . , .
CNN. .
, . Graph transform tool.
quantize_weights 8 . , 8- . , , - .
quantize_nodes 8- . .
, - . quantize_weights - , 4 .
, , TensorFlow Lite, .
— , . 64 (32) , .
RAM Ubuntu ( numpy int64) . 220 , int32, int16. .

tf-. float16. , , ( 10%), ( 10 ). , , epsilon learning_rate . , , .
RAM
, . , .
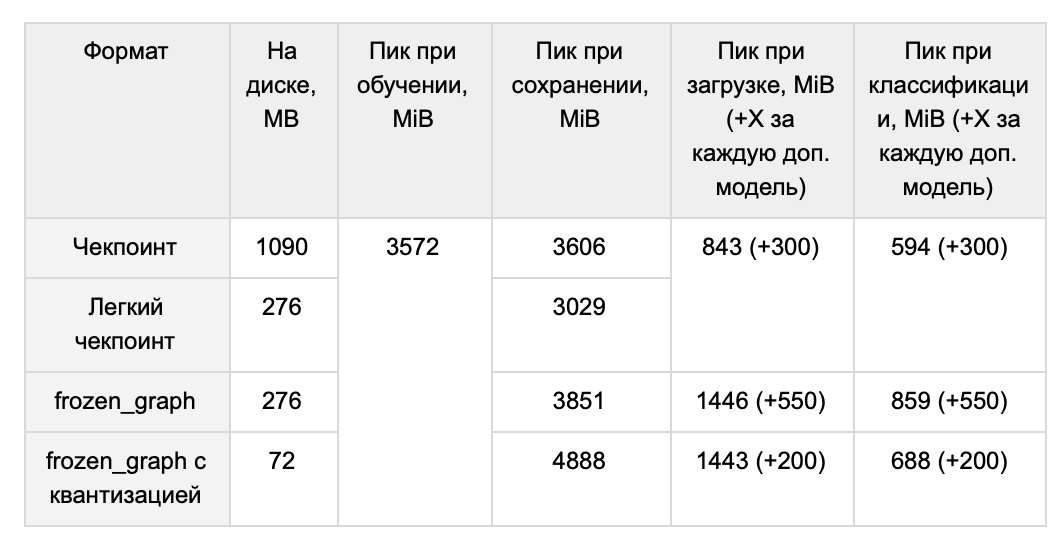
, . . .
QA-
Q: -, - ?
A: , . word2vec. ( , , min count, learning rate), 220 ( — 265 MB) CNN, 439 (510 MB).
- , , , - . , ( ). , . YouTokenToMe, , , .. , .., . . , , , . 30 (37 MB) , 3.7 CPU 2.6 GPU. ( ), OOV-.
Q: , , ?
A: , .
:
1. :
with tf.gfile.GFile(path_to_pb, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def, name='')
return graph2. "" :
sess.run(restored_variable_names) 3. , .
4. , , :
tf.Variable(tensors_to_restore["output/W:0"], name="W"), .
, , .
Kami tidak mencoba melatih ulang model yang dikompresi dengan metode lain yang dijelaskan, tetapi secara teoritis seharusnya tidak ada masalah dengan ini.
T: Apakah ada cara lain untuk mengurangi pengoptimalan yang belum Anda pertimbangkan?
J: Kami memiliki beberapa ide yang tidak pernah kami wujudkan. Pertama, pelipatan konstan adalah "pelipatan" dari himpunan bagian node grafik, pra-perhitungan nilai-nilai bagian dari grafik yang sangat bergantung pada input data. Kedua, dalam model kami, sepertinya solusi yang baik untuk menerapkan pemangkasan embeddings.