
Foto oleh Cristian Cristian di Unsplash
Dalam waktu dekat, pengeras suara Amazon Echo atau Nest Audio dapat diaktifkan, cari di Google atau Siri di perangkat Apple tanpa ucapan seperti "Halo, Google!" Dengan menggunakan AI, para ilmuwan dari Amerika Serikat telah mengembangkan algoritme berkat asisten suara pintar yang memahami bahwa seseorang sedang berbicara dengan mereka.
Dalam percakapan biasa, orang menunjuk penerima pesan hanya dengan melihatnya. Tetapi sebagian besar perangkat suara disesuaikan untuk aktivasi dengan frasa kunci yang tidak dikatakan siapa pun dalam komunikasi nyata. Pemahaman isyarat non-verbal oleh asisten suara akan membuat komunikasi lebih mudah dan lebih intuitif. Apalagi jika ada beberapa perangkat seperti itu di rumah.
Ilmuwan dari Carnegie Mellon University mencatat bahwa algoritma yang dikembangkan menentukan arah suara (DoV) menggunakan mikrofon.
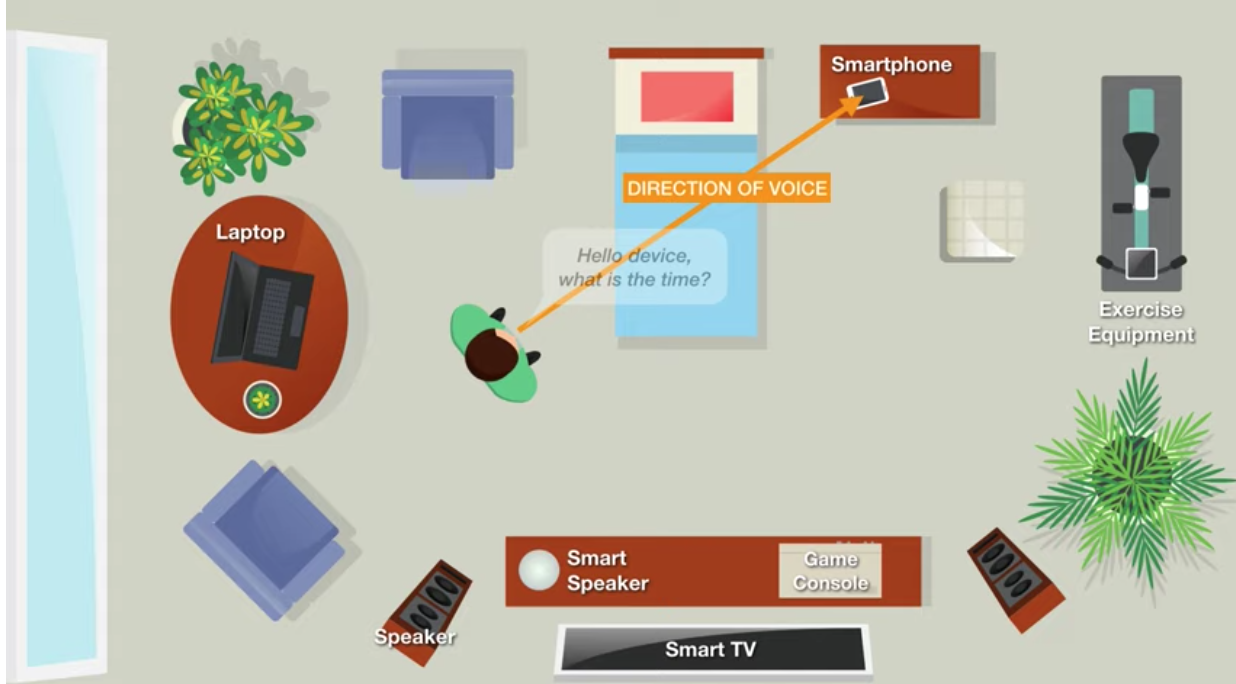
DoV berbeda dengan pendeteksian arah kedatangan (DoA).
Menurut para peneliti, penggunaan DoV memungkinkan perintah yang ditargetkan, yang menyerupai kontak mata dengan lawan bicara saat memulai percakapan. Namun, kamera perangkat tidak terlibat. Dengan demikian, ada interaksi alami dengan berbagai jenis perangkat tanpa kebingungan.
Antara lain, teknologi ini akan mengurangi jumlah pengaktifan asisten suara yang tidak disengaja yang selalu siaga sepanjang waktu.
Teknologi audio baru didasarkan pada fitur propagasi suara ucapan. Jika suara diarahkan ke mikrofon, maka didominasi oleh frekuensi rendah dan tinggi. Jika suara dipantulkan, yang awalnya diarahkan ke perangkat lain, maka akan ada penurunan yang nyata pada frekuensi tinggi dibandingkan dengan frekuensi rendah.
Algoritme juga menganalisispropagasi suara dalam 10 milidetik pertama. Dua skenario dimungkinkan di sini:
Pengguna diarahkan ke mikrofon. Sinyal yang datang lebih dulu ke mikrofon akan jelas dibandingkan dengan sinyal lain yang mungkin dipantulkan dari perangkat lain di rumah.
Pengguna berpaling dari mikrofon. Semua getaran suara akan diduplikasi dan didistorsi.
Algoritme mengukur bentuk sinyal, menghitung puncak intensitasnya, membandingkannya dengan nilai rata-rata, dan menentukan apakah suara diarahkan ke mikrofon atau tidak.
Dengan mengukur penyebaran suara, para ilmuwan dapat menentukan, dengan akurasi 93,1%, apakah seorang pembicara berada di depan mikrofon tertentu atau tidak. Mereka mencatat bahwa ini adalah hasil terbaik hingga saat ini dan langkah penting menuju implementasi solusi di perangkat yang ada. Saat mencoba menentukan salah satu dari delapan sudut pandang seseorang pada perangkat, akurasi 65,4% tercapai . Ini masih belum cukup untuk sebuah aplikasi, yang intinya adalah interaksi aktif dengan pengguna.
Untuk mengumpulkan informasi, para insinyur menggunakan Python, sinyal diproses berdasarkan algoritma pengklasifikasi Extra-Trees.
Data dan algoritma yang dikumpulkan selama pengembangan terbuka untuk GitHub . Mereka dapat digunakan saat membuat asisten suara Anda sendiri.
