Google Sheets → Node.js → Google Charts → Situs kartu nama → Top 3 dalam pencarian Nama lengkap + spesialisasi
Berdasarkan data dalam tabel, saya memutuskan untuk melengkapi situs kartu nama dengan informasi tentang publikasi yang akan dibuat secara otomatis. Apa yang ingin saya dapatkan:
- Ringkasan publikasi terbaru, terletak di garis waktu Google Charts .
- Pembuatan otomatis data keluaran dan tautan ke artikel dari tabel google ke dalam versi html kartu nama.
- Artikel versi PDF dari semua situs, karena kekhawatiran tentang penutupan beberapa situs lama di masa mendatang.
Anda dapat melihat bagaimana itu terjadi di sini . Diimplementasikan pada platform Node.js menggunakan Bootstrap, Google Charts dan Google Sheets untuk menyimpan data mentah.
Data mentah tentang publikasi di Google Spreadsheet
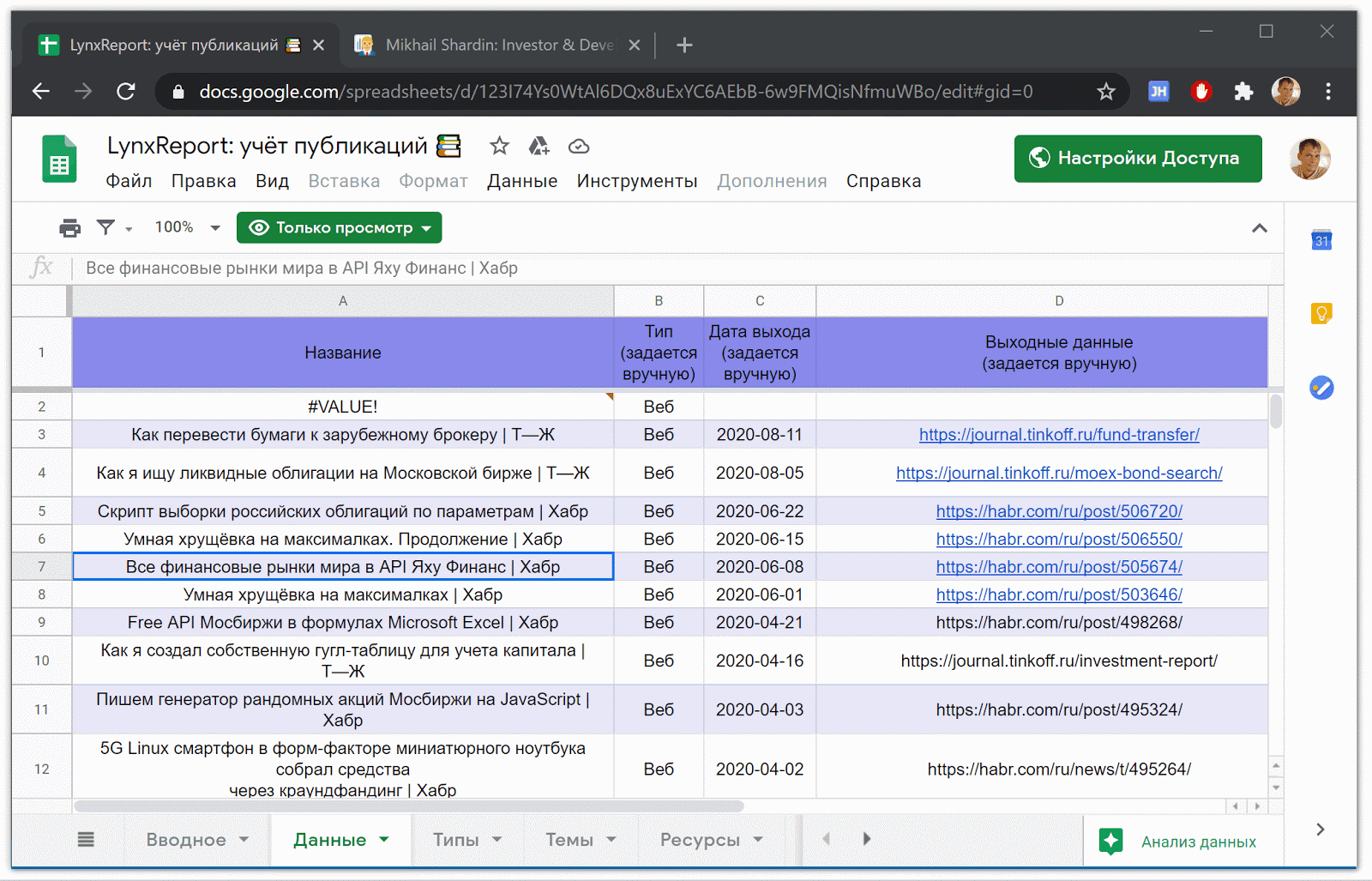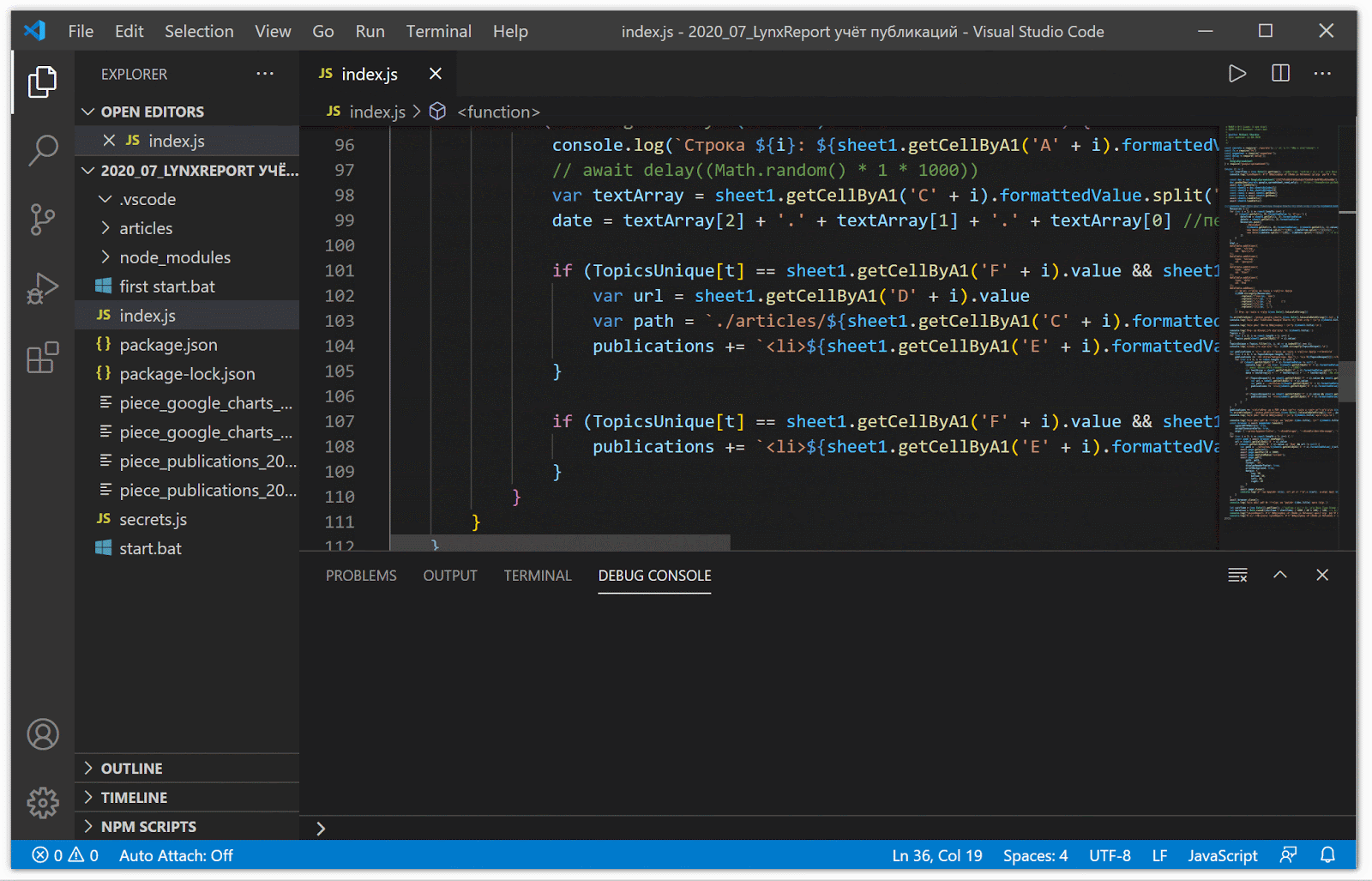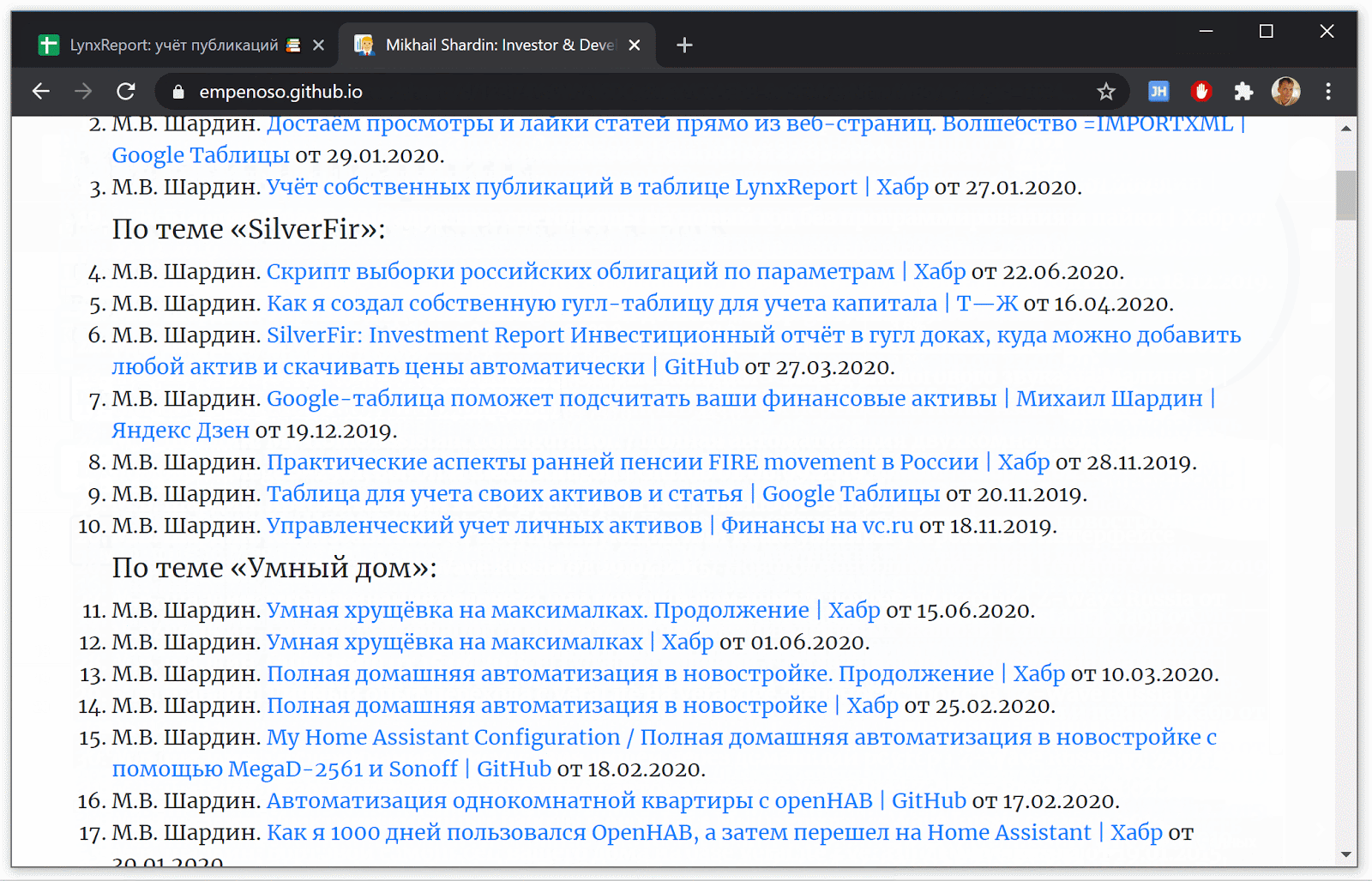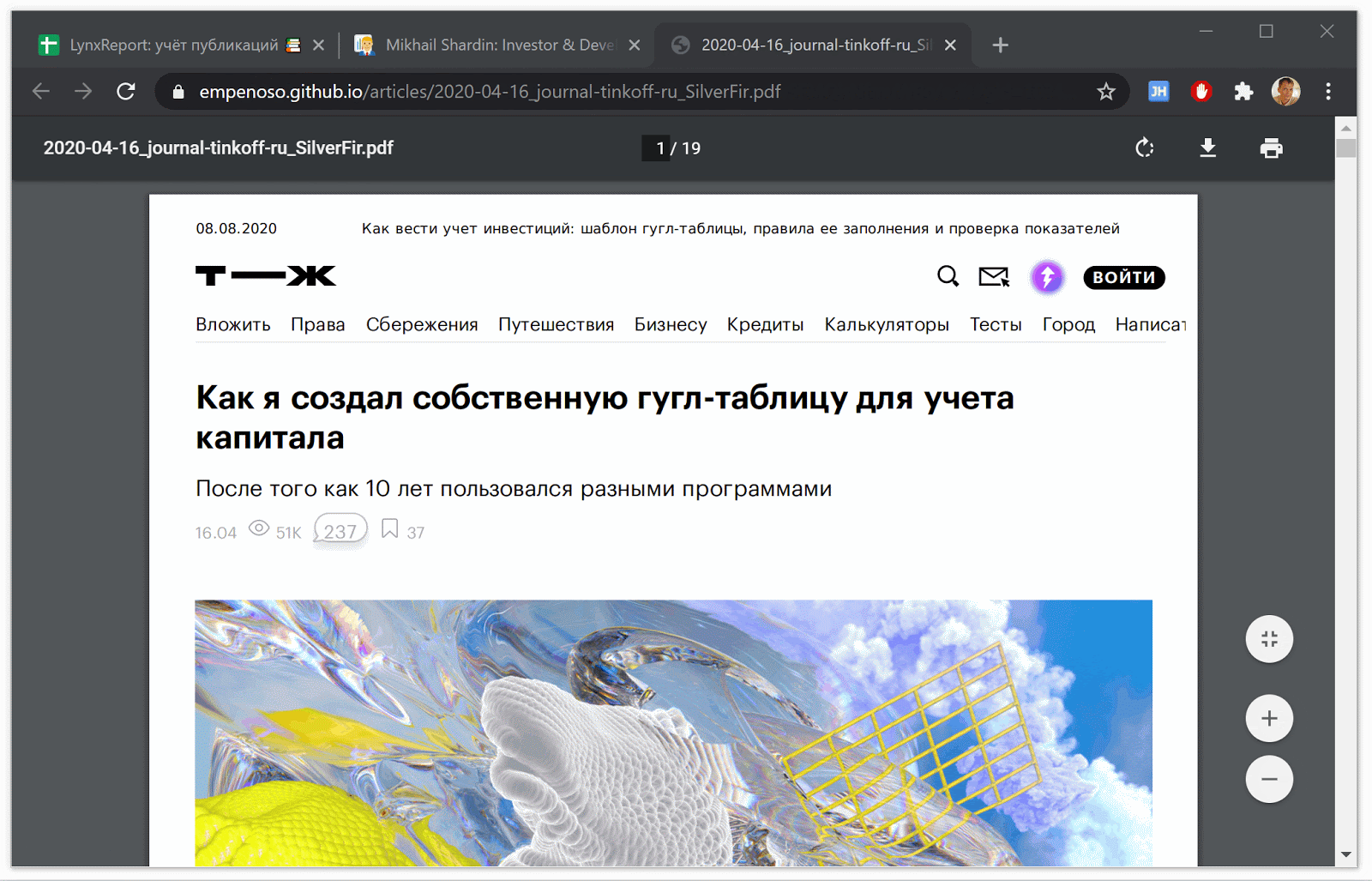
Google Spreadsheet LynxReport: Akuntansi publikasi berisi semua data sumber dan analitik untuk publikasi. Saya terus memperbarui informasi pada tab "Data" dengan memasukkan tautan baru ke artikel secara manual, sisanya diunduh secara otomatis.
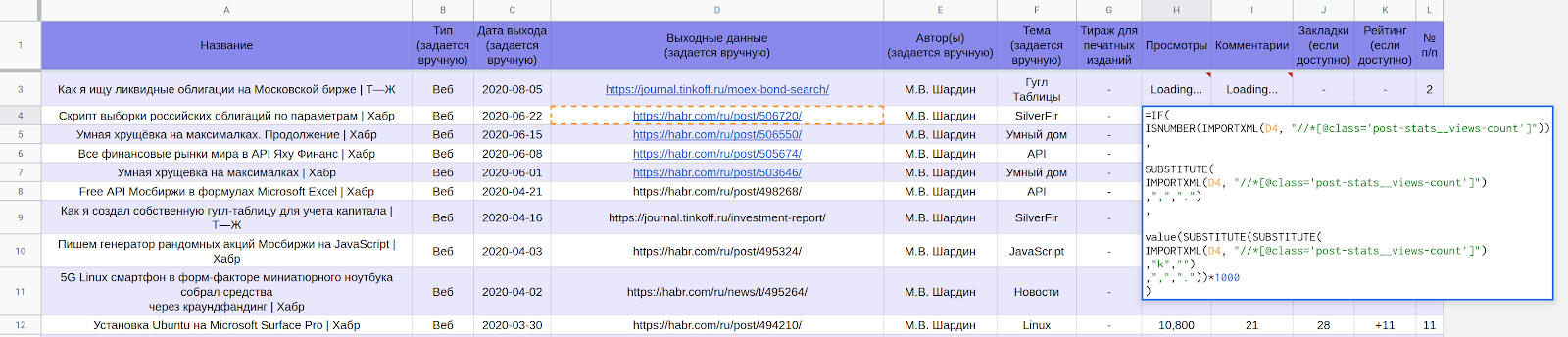
Bagian dari tabel LynxReport: akuntansi untuk publikasi dengan data awal Data
aktual pada tampilan dan komentar dimuat melalui rumus.
Misalnya, untuk mendapatkan jumlah tampilan dari halaman Habr di sel tabel Google, gunakan rumus:
=IF(
ISNUMBER(IMPORTXML(D6, "//*[@class='post-stats__views-count']"))
,
SUBSTITUTE(
IMPORTXML(D6, "//*[@class='post-stats__views-count']")
,",",".")
,
value(SUBSTITUTE(SUBSTITUTE(
IMPORTXML(D6, "//*[@class='post-stats__views-count']")
,"k","")
,",","."))*1000
)
Rumus bukanlah pilihan tercepat dan Anda harus menunggu sekitar setengah jam untuk mendapatkan beberapa ratus posisi. Setelah pengunduhan selesai, Anda dapat melihat semua nomor seperti pada gambar di bawah. Mereka memberikan jawaban atas topik mana yang populer dan mana yang tidak.

Bagian dari tabel LynxReport: memposting dengan analitik
Membaca data dari spreadsheet dan mengonversinya ke format Google Charts
Untuk mengubah data pivot ini dari spreadsheet Google menjadi situs kartu nama, saya perlu mengonversi data ke format garis waktu Google Charts .

Timeline yang dihasilkan dari Google Charts di situs kartu bisnis
Untuk menggambar grafik seperti itu dengan benar, data harus diatur sebagai berikut:

Data untuk Google Charts di situs kartu nama dalam bentuk html
Untuk melakukan semua transformasi secara otomatis, saya menulis skrip di bawah Node.js yang tersedia di GitHub .
Jika Anda tidak terbiasa dengan Node.js, maka di artikel saya sebelumnya, saya menjelaskan secara rinci bagaimana Anda dapat menggunakan skrip di bawah sistem yang berbeda:
- Windows
- macOS
- Linux
Tautkan dengan instruksi di sini . Prinsipnya serupa.

Pekerjaan skrip untuk mengubah ke format data yang diinginkan dan menghasilkan artikel versi pdf dari situs (semua baris diproses secara instan - Saya sengaja menyetel penundaan untuk merekam video ini)
Untuk membaca data dari tabel Google dalam mode otomatis, saya menggunakan otorisasi kunci .
Anda bisa mendapatkan kunci ini di Konsol Manajemen Proyek

Google : Kredensial di Google Cloud Platform
Setelah skrip selesai, dua file teks dengan data html grafik dan semua salinan pdf dari artikel online harus dibuat.
Saya mengimpor data dari file teks ke dalam kode html situs kartu nama.
Generasi salinan pdf artikel dari situs
Menggunakan Puppeteer, saya menyimpan tampilan artikel saat ini bersama dengan semua komentar dalam bentuk pdf.
Jika Anda tidak menunda, maka beberapa lusin artikel dalam daftar dapat disimpan sebagai file pdf hanya dalam beberapa menit.
Dan penundaan diperlukan agar komentar dapat dimuat di beberapa situs ( misalnya, di - ).
hasil
Sejak penulisan skrip dimulai untuk lebih cocok dengan algoritma pencarian, Anda dapat mengevaluasi hasil menggunakan pencarian.
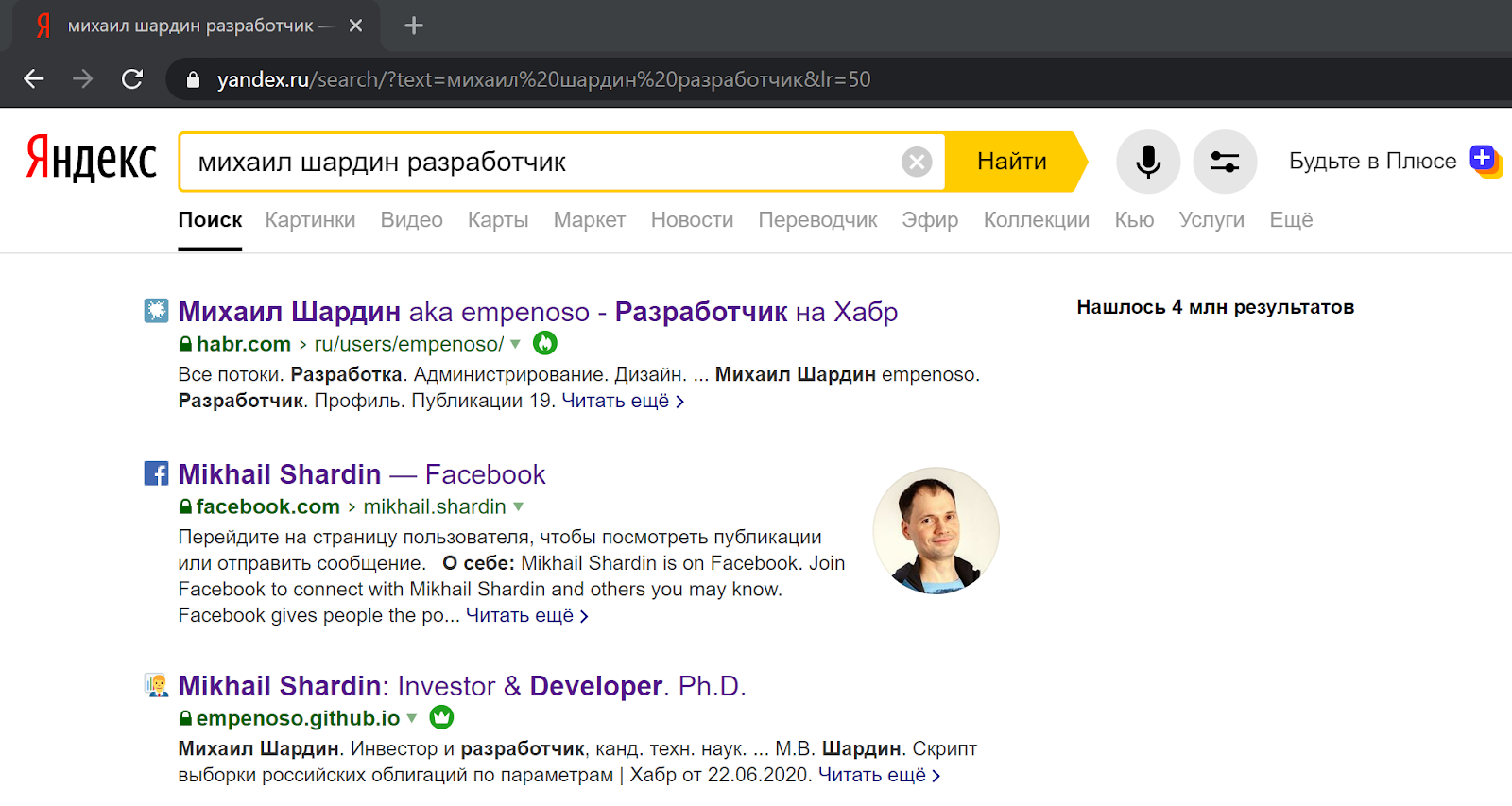
Pencarian berdasarkan nama dan nama keluarga + indikasi spesialisasi dalam kedua kasus mengembalikan tautan ke artikel saya dan bahkan situs kartu nama:
Dalam hasil pencarian Yandex :
Dalam hasil pencarian Google :

Saya masih tidak dapat memutuskan apakah layak mendaftarkan nama domain terpisah jika kartu nama adalah empenoso.github.io dan apakah itu di baris teratas pencarian?
Alih-alih kesimpulan
- Mungkin artikel ini akan membuat seseorang berpikir tentang seperti apa penampilannya di Internet.
- Mungkin artikel ini akan membantu seseorang untuk mendirikan akuntansi dan organisasi publikasi.
- Kode sumber untuk skrip terletak di GitHub .
Oleh: Mikhail Shardin
17 Agustus 2020