pengantar
Halo, Habr!
Banyak orang menyukai bagian sebelumnya, jadi saya sekali lagi menyekop setengah dari dokumentasi pendorong dan menemukan sesuatu untuk ditulis. Sangat aneh bahwa tidak ada kegembiraan di sekitar boost.compute seperti di sekitar boost.asio. Lagipula, cukup, perpustakaan ini adalah lintas platform, dan juga menyediakan antarmuka yang nyaman (dalam kerangka c ++) untuk berinteraksi dengan komputasi paralel pada GPU dan CPU.
Semua bagian
- Bagian 1
- Bagian 2
Kandungan
- Operasi asinkron
- Fungsi kustom
- Perbandingan kecepatan perangkat yang berbeda dalam mode berbeda
- Kesimpulan
Operasi asinkron
Akan terlihat jauh lebih cepat? Salah satu cara untuk mempercepat pekerjaan Anda dengan container di ruang nama komputasi adalah dengan menggunakan fungsi asinkron. Boost.compute memberi kita beberapa alat. Dari jumlah tersebut, kelas compute :: future untuk mengontrol penggunaan fungsi dan fungsi copy_async (), fill_async () untuk menyalin atau mengisi array. Tentu saja, ada juga alat untuk bekerja dengan acara, tetapi tidak perlu mempertimbangkannya. Berikut ini akan menjadi contoh penggunaan semua hal di atas:
auto device = compute::system::default_device();
auto context = compute::context::context(device);
auto queue = compute::command_queue(context, device);
std::vector<int> vec_std = {1, 2, 3};
compute::vector<int> vec_compute(vec_std.size(), context);
compute::vector<int> for_filling(10, context);
int num_for_fill = 255;
compute::future<void> filling = compute::fill_async(for_filling.begin(),
for_filling.end(), num_for_fill, queue); //
compute::future<void> copying = compute::copy_async(vec_std.begin(),
vec_std.end(), vec_compute.begin(), queue); //
filling.wait();
copying.wait();
Tidak ada yang istimewa untuk dijelaskan di sini. Tiga baris pertama adalah inisialisasi standar dari kelas yang diperlukan, kemudian dua vektor untuk disalin, satu vektor untuk diisi, variabel yang masing-masing akan mengisi vektor sebelumnya dan secara langsung fungsi untuk mengisi dan menyalin. Lalu kami menunggu eksekusi mereka.
Bagi mereka yang bekerja dengan std :: future dari STL, semuanya sama di sini, hanya di namespace yang berbeda dan tidak ada analog dari std :: async ().
Fungsi kustom untuk penghitungan
Di bagian sebelumnya, saya mengatakan bahwa saya akan menjelaskan cara menggunakan metode saya sendiri untuk memproses kumpulan data. Saya menghitung 3 cara untuk melakukan ini: gunakan makro, gunakan make_function_from_source <> () dan gunakan kerangka kerja khusus untuk ekspresi lambda.
Saya akan mulai dengan opsi pertama - makro. Pertama saya akan melampirkan kode sampel dan kemudian saya akan menjelaskan cara kerjanya.
BOOST_COMPUTE_FUNCTION(float,
add,
(float x, float y),
{ return x + y; });
Argumen pertama adalah tipe nilai yang dikembalikan, lalu nama fungsi, argumennya, dan isi fungsi. Lebih jauh di bawah nama add, fungsi ini dapat digunakan, misalnya, dalam fungsi compute :: transform (). Menggunakan makro ini sangat mirip dengan ekspresi lambda biasa, tetapi saya telah memeriksa bahwa mereka tidak akan berfungsi.
Metode kedua dan mungkin yang paling sulit sangat mirip dengan yang pertama. Saya melihat kode makro sebelumnya dan ternyata itu menggunakan metode kedua.
compute::function<float(float)> add = compute::make_function_from_source<float(float)>
("add", "float add(float x, float y) { return x + y; }");
Di sini semuanya lebih jelas daripada yang terlihat pada pandangan pertama, fungsi make_function_from_source () hanya menggunakan dua argumen, salah satunya adalah nama fungsi, dan yang kedua adalah implementasinya. Setelah sebuah fungsi dideklarasikan, itu bisa digunakan dengan cara yang sama seperti setelah implementasi makro.
Nah, opsi terakhir adalah framework ekspresi lambda. Contoh penggunaan:
compute::transform(com_vec.begin(),
com_vec.end(),
com_vec.begin(),
compute::_1 * 2,
queue);
Sebagai argumen keempat, kami menunjukkan bahwa kami ingin mengalikan setiap elemen dari vektor pertama dengan 2, semuanya cukup sederhana dan selesai di tempat.
Ekspresi Boolean dapat ditentukan dengan cara yang sama. Misalnya, dalam metode compute :: count_if ():
std::vector<int> source_std = { 1, 2, 3 };
compute::vector<int> source_compute(source_std.begin() ,source_std.end(), queue);
auto counter = compute::count_if(source_compute.begin(),
source_compute.end(),
compute::lambda::_1 % 2 == 0,
queue);
Jadi, kita telah menghitung semua bilangan genap dalam array, penghitung akan sama dengan satu.
Perbandingan kecepatan perangkat yang berbeda dalam mode berbeda
Nah, hal terakhir yang ingin saya tulis di artikel ini adalah perbandingan kecepatan pemrosesan data pada perangkat yang berbeda dan dalam mode yang berbeda (hanya untuk CPU). perbandingan ini akan membuktikan penggunaan GPU untuk komputasi dan komputasi paralel secara umum.
Saya akan menguji seperti ini: menggunakan komputasi untuk semua perangkat, saya akan memanggil fungsi compute :: sort () untuk mengurutkan larik 100 juta nilai float. Untuk menguji mode single-threaded, panggil std :: sort pada larik dengan ukuran yang sama. Untuk setiap perangkat, saya akan mencatat waktu dalam milidetik menggunakan pustaka standar chrono dan menampilkan semuanya ke konsol.
Hasilnya adalah sebagai berikut:

Sekarang saya akan melakukan hal yang sama hanya untuk seribu nilai. Kali ini waktunya akan dalam mikrodetik.

Kali ini prosesor dalam mode single-threaded berada di depan semua orang. Dari sini kami menyimpulkan bahwa operasi semacam ini hanya layak dilakukan jika menyangkut data yang sangat besar.
Saya ingin melakukan beberapa tes lagi, jadi mari kita lakukan tes untuk menghitung kosinus, akar kuadrat dan kuadrat.
Dalam menghitung cosinus, perbedaannya sangat besar (GPU bekerja 60 kali lebih cepat dari CPU dalam satu thread).
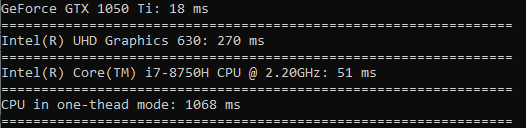
Akar kuadrat dihitung dengan kecepatan yang hampir sama dengan pengurutan.
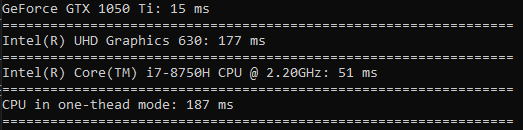
Waktu yang dihabiskan untuk mengkuadratkan lebih sedikit perbedaannya daripada pengurutan (GPU hanya 3,5 kali lebih cepat).

Kesimpulan
Jadi, setelah membaca artikel ini, Anda belajar bagaimana menggunakan fungsi asynchronous untuk menyalin array dan mengisinya. Kami mempelajari cara apa saja yang dapat Anda gunakan untuk menggunakan fungsi Anda sendiri untuk melakukan penghitungan pada data. Dan juga dengan jelas melihat kapan layak menggunakan GPU atau CPU untuk komputasi paralel, dan kapan Anda bisa bertahan dengan satu utas.
Saya akan senang menerima umpan balik positif, terima kasih atas waktu Anda!
Semoga beruntung untuk semuanya!