Untuk waktu yang lama saya belum menulis artikel apa pun dan, menurut saya, inilah saatnya untuk menulis tentang bagaimana pengetahuan dalam ilmu data, yang diperoleh selama pelatihan spesialisasi terkenal dari Yandex dan MIPT "Pembelajaran Mesin dan Analisis Data", berguna. Benar, dalam keadilan, perlu dicatat bahwa pengetahuan belum sepenuhnya diperoleh - keahlian khusus belum selesai :) Namun, sudah mungkin untuk menyelesaikan masalah bisnis nyata yang sederhana. Atau apakah itu perlu? Pertanyaan ini akan dijawab hanya dalam beberapa paragraf.
Jadi, hari ini di artikel ini saya akan memberi tahu para pembaca yang budiman tentang pengalaman pertama saya mengikuti kompetisi terbuka. Saya ingin segera mencatat bahwa tujuan saya dari kompetisi ini bukanlah untuk mendapatkan hadiah apa pun. Keinginan satu-satunya adalah menjajal tangan saya di dunia nyata :) Ya, selain itu ternyata topik lomba praktis tidak bersinggungan dengan materi dari mata kuliah yang telah dilalui. Ini menambah beberapa komplikasi, tetapi dengan itu persaingan menjadi lebih menarik dan berharga pengalaman yang didapat dari sana.
Sesuai tradisi, saya akan menunjuk siapa yang mungkin tertarik dengan artikel tersebut. Pertama, jika Anda telah menyelesaikan dua kursus pertama dari spesialisasi di atas, dan ingin mencoba tangan Anda pada masalah praktis, tetapi malu dan khawatir itu mungkin tidak berhasil dan Anda akan ditertawakan, dll. Setelah membaca artikel ini, saya berharap ketakutan seperti itu akan hilang. Kedua, mungkin Anda sedang memecahkan masalah serupa dan sama sekali tidak tahu harus masuk ke mana. Dan di sini ada yang bersahaja yang sudah jadi, seperti yang dikatakan para penghubung data nyata, garis dasar :)
Di sini kita seharusnya sudah menguraikan rencana penelitian, tetapi kita akan sedikit menyimpang dan mencoba menjawab pertanyaan dari paragraf pertama - seandainya seorang pemula dalam pencitraan data perlu mencoba tangannya di kompetisi semacam itu. Pendapat berbeda tentang skor ini. Secara pribadi, pendapat saya itu perlu! Izinkan saya menjelaskan alasannya. Ada banyak alasan, saya tidak akan mencantumkan semuanya, saya akan menunjukkan yang paling penting. Pertama, kompetisi semacam itu membantu mengkonsolidasikan pengetahuan teoretis dalam praktik. Kedua, dalam praktik saya, hampir selalu, pengalaman yang diperoleh dalam kondisi yang dekat dengan pertempuran, sangat memotivasi untuk eksploitasi lebih lanjut. Ketiga, dan ini yang paling penting - selama kompetisi Anda memiliki kesempatan untuk berkomunikasi dengan peserta lain dalam obrolan khusus, Anda bahkan tidak perlu berkomunikasi, Anda cukup membaca apa yang orang tulis dan ini a) sering mengarah pada pemikiran yang menarik tentangapa perubahan lain yang harus dilakukan dalam penelitian; dan b) memberi keyakinan untuk memvalidasi ide-ide mereka sendiri, terutama jika hal itu diungkapkan dalam obrolan. Keunggulan ini harus didekati dengan kehati-hatian tertentu, agar tidak ada perasaan maha tahu ...
Sekarang sedikit tentang bagaimana saya memutuskan untuk berpartisipasi. Saya mengetahui tentang kompetisi hanya beberapa hari sebelum dimulai. Pikiran pertama adalah “baiklah, jika saya mengetahui tentang kompetisi sebulan yang lalu, saya akan mempersiapkan diri, tetapi saya akan mempelajari beberapa materi tambahan yang dapat berguna untuk melakukan penelitian, jika tidak, tanpa persiapan saya mungkin tidak memenuhi tenggat waktu ...”, yang kedua pemikiran “sebenarnya, yang mungkin tidak akan berhasil jika tujuannya bukan hadiah, tetapi partisipasi, terutama karena peserta dalam 95% kasus berbicara bahasa Rusia, ditambah ada obrolan khusus untuk diskusi, akan ada semacam webinar dari penyelenggara. Pada akhirnya, Anda dapat melihat daftar data langsung dari semua garis dan ukuran ... ". Seperti yang Anda tebak, pikiran kedua menang, dan tidak sia-sia - secara harfiah beberapa hari kerja keras dan saya mendapat pengalaman berharga, meskipun yang sederhana,tapi tugas bisnis yang lumayan. Oleh karena itu, jika Anda sedang dalam perjalanan untuk menaklukkan ketinggian ilmu data dan melihat kompetisi yang akan datang, ya dalam bahasa ibu Anda, dengan dukungan dalam obrolan dan Anda memiliki waktu luang - jangan ragu untuk waktu yang lama - coba dan semoga kekuatan itu datang bersama Anda! Pada catatan positif, kami melanjutkan ke tugas dan rencana penelitian.
Nama yang cocok
Kami tidak akan menyiksa diri kami sendiri dan memberikan deskripsi masalahnya, tetapi kami akan memberikan teks asli dari situs web penyelenggara kompetisi.
Sebuah tugas
Saat mencari klien baru, SIBUR harus memproses informasi tentang jutaan perusahaan baru dari berbagai sumber. Pada saat yang sama, nama perusahaan mungkin memiliki ejaan yang berbeda, mengandung singkatan atau kesalahan, dan berafiliasi dengan perusahaan yang sudah dikenal dengan SIBUR.
Untuk memproses informasi tentang calon pelanggan dengan lebih efisien, SIBUR perlu mengetahui apakah kedua nama tersebut terkait (yaitu milik perusahaan yang sama atau perusahaan afiliasi).
Dalam hal ini, SIBUR akan dapat menggunakan informasi yang sudah diketahui tentang perusahaan itu sendiri atau tentang perusahaan afiliasi, tidak menggandakan panggilan ke perusahaan atau tidak membuang waktu pada perusahaan atau anak perusahaan pesaing yang tidak relevan.
Contoh pelatihan berisi pasangan nama dari berbagai sumber (termasuk yang khusus) dan markup.
Markup diperoleh sebagian dengan tangan, sebagian - secara algoritme. Selain itu, markup mungkin mengandung kesalahan. Anda akan membuat model biner yang memprediksi apakah dua nama terkait. Metrik yang digunakan dalam tugas ini adalah F1.
Dalam tugas ini, dimungkinkan dan bahkan perlu untuk menggunakan sumber data terbuka untuk memperkaya kumpulan data atau untuk menemukan informasi tambahan yang penting untuk mengidentifikasi perusahaan afiliasi.
Informasi tambahan tentang tugas
Temukan saya untuk informasi lebih lanjut
, . , : , , Sibur Digital, , Sibur international GMBH , “ International GMBH” .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source , . — . .
, - – . , , - , , , .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
, , , .. crowdsource
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source
open source , . — . .
, - – . , , - , , , .
Data
train.csv - set pelatihan
test.csv - set tes
sample_submission.csv - contoh solusi dalam format yang benar
Penamaan baseline.ipynb - kode
baseline_submission.csv - solusi dasar
Harap dicatat bahwa penyelenggara kompetisi merawat generasi muda dan memposting solusi dasar untuk masalah tersebut, yang memberikan kualitas f1 sekitar 0,1. Ini adalah pertama kalinya saya berpartisipasi dalam kompetisi dan pertama kali saya melihat ini :)
Jadi, setelah membiasakan diri dengan masalah itu sendiri dan persyaratan solusinya, mari kita lanjutkan ke rencana solusi.
Rencana pemecahan masalah
Menyiapkan instrumen teknis
Mari memuat pustaka.
Mari menulis fungsi tambahan
Pemrosesan awal data
… -. !
50 & Drop it smart.
Mari kita hitung jarak Levenshtein
Menghitung jarak Levenshtein ternormalisasi
Visualisasikan fitur
Bandingkan kata-kata dalam teks untuk setiap pasangan dan buat banyak fitur
Bandingkan kata-kata dari teks dengan kata-kata dari nama 50 merek induk teratas di industri petrokimia dan konstruksi. Mari kita dapatkan banyak fitur kedua. CHIT Kedua
Mempersiapkan data untuk dimasukkan ke dalam model
Menyiapkan dan melatih model
Hasil kompetisi
Sumber informasi
Sekarang setelah kita membiasakan diri dengan rencana penelitian, mari kita lanjutkan ke penerapannya.
Menyiapkan instrumen teknis
Memuat Perpustakaan
Sebenarnya semuanya sederhana disini, pertama kita akan menginstall library yang hilang
Instal perpustakaan untuk menentukan daftar negara dan kemudian hapus dari teks
pip install pycountry
Instal perpustakaan untuk menentukan jarak Levenshtein antara kata-kata dari teks satu sama lain dan dengan kata-kata dari daftar yang berbeda
pip install strsimpy
Kami akan menginstal perpustakaan, dengan bantuan yang kami akan mentransliterasi teks Rusia ke dalam bahasa Latin
pip install cyrtranslit
Tarik perpustakaan
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import pycountry
import re
from tqdm import tqdm
tqdm.pandas()
from strsimpy.levenshtein import Levenshtein
from strsimpy.normalized_levenshtein import NormalizedLevenshtein
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import seaborn as sns
sns.set()
sns.set_style("whitegrid")
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import StratifiedShuffleSplit
from scipy.sparse import csr_matrix
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report, f1_score
# import googletrans
# from googletrans import Translator
import cyrtranslitMari menulis fungsi tambahan
Menentukan fungsi dalam satu baris dianggap praktik yang baik daripada menyalin sebagian besar kode. Kami akan melakukannya, hampir selalu.
Saya tidak akan membantah bahwa kualitas kode dalam fungsinya sangat baik. Di beberapa tempat, ini pasti harus dioptimalkan, tetapi untuk tujuan penelitian cepat, hanya keakuratan perhitungan yang cukup.
Jadi fungsi pertama mengubah teks menjadi huruf kecil
Kode
# convert text to lowercase
def lower_str(data,column):
data[column] = data[column].str.lower()Empat fungsi berikut membantu memvisualisasikan ruang fitur yang diteliti dan kemampuannya untuk memisahkan objek dengan label target - 0 atau 1.
Kode
# statistic table for analyse float values (it needs to make histogramms and boxplots)
def data_statistics(data,analyse,title_print):
data0 = data[data['target']==0][analyse]
data1 = data[data['target']==1][analyse]
data_describe = pd.DataFrame()
data_describe['target_0'] = data0.describe()
data_describe['target_1'] = data1.describe()
data_describe = data_describe.T
if title_print == 'yes':
print ('\033[1m' + ' ',analyse,'\033[m')
elif title_print == 'no':
None
return data_describe
# histogramms for float values
def hist_fz(data,data_describe,analyse,size):
print ()
print ('\033[1m' + 'Information about',analyse,'\033[m')
print ()
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
min_data = data_describe['min'].min()
max_data = data_describe['max'].max()
data0_mean = data_describe.loc['target_0']['mean']
data0_median = data_describe.loc['target_0']['50%']
data0_min = data_describe.loc['target_0']['min']
data0_max = data_describe.loc['target_0']['max']
data0_count = data_describe.loc['target_0']['count']
data1_mean = data_describe.loc['target_1']['mean']
data1_median = data_describe.loc['target_1']['50%']
data1_min = data_describe.loc['target_1']['min']
data1_max = data_describe.loc['target_1']['max']
data1_count = data_describe.loc['target_1']['count']
print ('\033[4m' + 'Analyse'+ '\033[m','No duplicates')
figure(figsize=size)
sns.distplot(data_0,color='darkgreen',kde = False)
plt.scatter(data0_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data0_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data0_count,
' Min:', round(data0_min,2),
' Max:', round(data0_max,2),
' Mean:', round(data0_mean,2),
' Median:', round(data0_median,2))
print ()
print ('\033[4m' + 'Analyse'+ '\033[m','Duplicates')
figure(figsize=size)
sns.distplot(data_1,color='darkred',kde = False)
plt.scatter(data1_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data1_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data_1.count(),
' Min:', round(data1_min,2),
' Max:', round(data1_max,2),
' Mean:', round(data1_mean,2),
' Median:', round(data1_median,2))
# draw boxplot
def boxplot(data,analyse,size):
print ('\033[4m' + 'Analyse'+ '\033[m','All pairs')
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
figure(figsize=size)
sns.boxplot(x=analyse,y='target',data=data,orient='h',
showmeans=True,
meanprops={"marker":"o",
"markerfacecolor":"dimgray",
"markeredgecolor":"black",
"markersize":"14"},
palette=['palegreen', 'salmon'])
plt.ylabel('target', size=14)
plt.xlabel(analyse, size=14)
plt.show()
# draw graph for analyse two choosing features for predict traget label
def two_features(data,analyse1,analyse2,size):
fig = plt.subplots(figsize=size)
x0 = data[data['target']==0][analyse1]
y0 = data[data['target']==0][analyse2]
x1 = data[data['target']==1][analyse1]
y1 = data[data['target']==1][analyse2]
plt.scatter(x0,y0,c='green',marker='.')
plt.scatter(x1,y1,c='black',marker='+')
plt.xlabel(analyse1)
plt.ylabel(analyse2)
title = [analyse1,analyse2]
plt.title(title)
plt.show()Fungsi kelima dirancang untuk menghasilkan tabel tebakan dan kesalahan dari algoritma, yang lebih dikenal dengan tabel konjugasi.
Dengan kata lain, setelah terbentuknya vektor forecast, kita perlu membandingkan forecast dengan label target. Hasil perbandingan tersebut harus berupa tabel konjugasi untuk setiap pasangan perusahaan dari sampel pelatihan. Dalam tabel konjugasi untuk setiap pasangan, hasil dari pencocokan perkiraan dengan kelas dari sampel pelatihan akan ditentukan. Klasifikasi pencocokan diterima sebagai berikut: 'Positif benar', 'Positif palsu', 'Negatif benar' atau 'Negatif palsu'. Data ini sangat penting untuk menganalisis pengoperasian algoritme dan mengambil keputusan untuk meningkatkan model dan ruang fitur.
Kode
def contingency_table(X,features,probability_level,tridx,cvidx,model):
tr_predict_proba = model.predict_proba(X.iloc[tridx][features].values)
cv_predict_proba = model.predict_proba(X.iloc[cvidx][features].values)
tr_predict_target = (tr_predict_proba[:, 1] > probability_level).astype(np.int)
cv_predict_target = (cv_predict_proba[:, 1] > probability_level).astype(np.int)
X_tr = X.iloc[tridx]
X_cv = X.iloc[cvidx]
X_tr['predict_proba'] = tr_predict_proba[:,1]
X_cv['predict_proba'] = cv_predict_proba[:,1]
X_tr['predict_target'] = tr_predict_target
X_cv['predict_target'] = cv_predict_target
# make true positive column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false positive column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make true negative column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false negative column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
return X_tr,X_cvFungsi keenam digunakan untuk membentuk matriks konjugasi. Jangan bingung dengan Tabel Kopling. Meskipun yang satu mengikuti dari yang lain. Anda sendiri akan melihat segalanya lebih jauh
Kode
def matrix_confusion(X):
list_matrix = ['True_Positive','False_Positive','True_Negative','False_Negative']
tr_pos = X[list_matrix].sum().loc['True_Positive']
f_pos = X[list_matrix].sum().loc['False_Positive']
tr_neg = X[list_matrix].sum().loc['True_Negative']
f_neg = X[list_matrix].sum().loc['False_Negative']
matrix_confusion = pd.DataFrame()
matrix_confusion['0_algorythm'] = np.array([tr_neg,f_neg]).T
matrix_confusion['1_algorythm'] = np.array([f_pos,tr_pos]).T
matrix_confusion = matrix_confusion.rename(index={0: '0_target', 1: '1_target'})
return matrix_confusionFungsi ketujuh dirancang untuk memvisualisasikan laporan operasi algoritma, yang meliputi matriks konjugasi, nilai-nilai presisi metrik, recall, f1
Kode
def report_score(tr_matrix_confusion,
cv_matrix_confusion,
data,tridx,cvidx,
X_tr,X_cv):
# print some imporatant information
print ('\033[1m'+'Matrix confusion on train data'+'\033[m')
display(tr_matrix_confusion)
print ()
print(classification_report(data.iloc[tridx]["target"].values, X_tr['predict_target']))
print ('******************************************************')
print ()
print ()
print ('\033[1m'+'Matrix confusion on test(cv) data'+'\033[m')
display(cv_matrix_confusion)
print ()
print(classification_report(data.iloc[cvidx]["target"].values, X_cv['predict_target']))
print ('******************************************************')Dengan menggunakan fungsi kedelapan dan kesembilan, kita akan menganalisis kegunaan fitur untuk model yang digunakan dari Light GBM dalam hal nilai koefisien 'Keuntungan informasi' untuk setiap fitur yang diselidiki
Kode
def table_gain_coef(model,features,start,stop):
data_gain = pd.DataFrame()
data_gain['Features'] = features
data_gain['Gain'] = model.booster_.feature_importance(importance_type='gain')
return data_gain.sort_values('Gain', ascending=False)[start:stop]
def gain_hist(df,size,start,stop):
fig, ax = plt.subplots(figsize=(size))
x = (df.sort_values('Gain', ascending=False)['Features'][start:stop])
y = (df.sort_values('Gain', ascending=False)['Gain'][start:stop])
plt.bar(x,y)
plt.xlabel('Features')
plt.ylabel('Gain')
plt.xticks(rotation=90)
plt.show()Fungsi kesepuluh diperlukan untuk membentuk larik jumlah kata yang cocok untuk setiap pasangan perusahaan.
Fungsi ini juga dapat digunakan untuk membentuk larik kata yang TIDAK cocok.
Kode
def compair_metrics(data):
duplicate_count = []
duplicate_sum = []
for i in range(len(data)):
count=len(data[i])
duplicate_count.append(count)
if count <= 0:
duplicate_sum.append(0)
elif count > 0:
temp_sum = 0
for j in range(len(data[i])):
temp_sum +=len(data[i][j])
duplicate_sum.append(temp_sum)
return duplicate_count,duplicate_sum Fungsi kesebelas mentransliterasi teks Rusia ke dalam alfabet Latin
Kode
def transliterate(data):
text_transliterate = []
for i in range(data.shape[0]):
temp_list = list(data[i:i+1])
temp_str = ''.join(temp_list)
result = cyrtranslit.to_latin(temp_str,'ru')
text_transliterate.append(result)
.
, , , . , ,
<spoiler title="">
<source lang="python">def rename_agg_columns(id_client,data,rename):
columns = [id_client]
for lev_0 in data.columns.levels[0]:
if lev_0 != id_client:
for lev_1 in data.columns.levels[1][:-1]:
columns.append(rename % (lev_0, lev_1))
data.columns = columns
return datareturn text_transliterate Fungsi
ketiga belas dan keempat belas diperlukan untuk melihat dan menghasilkan tabel jarak Levenshtein dan indikator penting lainnya.
Tabel macam apa itu, metrik apa saja yang ada di dalamnya dan bagaimana bentuknya? Mari kita lihat bagaimana tabel dibentuk selangkah demi selangkah:
- Langkah 1. Mari tentukan data apa yang kita perlukan. Pair ID, Text Finishing - Kedua Kolom, Daftar Nama Holding (50 Perusahaan Petrokimia & Konstruksi Teratas).
- Langkah 2. Di kolom 1, di setiap pasangan dari setiap kata, kami mengukur jarak Levenshtein untuk setiap kata dari daftar nama induk, serta panjang setiap kata dan rasio jarak terhadap panjang.
- 3. , 0.4, id , .
- 4. , 0.4, .
- 5. , ID , — . id ( id ). .
- Langkah 6. Rekatkan tabel yang dihasilkan dengan tabel penelitian.
Fitur penting:
penghitungan membutuhkan waktu lama karena kode yang ditulis tergesa-gesa
Kode
def dist_name_to_top_list_view(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
words1 = []
words2 = []
top_words = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist1
df['levenstein_dist_w2_top_w'] = dist2
df['length_w1_top_w'] = len(word1)
df['length_w2_top_w'] = len(word2)
df['length_top_w'] = len(top_word)
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
display(data)
print ('Words:', word1,word2,top_word)
print ('Levenstein distance:',dist1,dist2)
print ('Length of word:',len(word1),len(word2),len(top_word))
print ('Ratio (distance/length word):',ratio1,ratio2)
def dist_name_to_top_list_make(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
dist_w1 = []
dist_w2 = []
length_w1 = []
length_w2 = []
length_top_w = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
dist_w1.append(dist1)
dist_w2.append(dist2)
length_w1.append(float(len(word1)))
length_w2.append(float(len(word2)))
length_top_w.append(float(len(top_word)))
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist_w1
df['levenstein_dist_w2_top_w'] = dist_w2
df['length_w1_top_w'] = length_w1
df['length_w2_top_w'] = length_w2
df['length_top_w'] = length_top_w
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
return dataPemrosesan awal data
Dari pengalaman kecil saya, pemrosesan awal data dalam arti luas dari ungkapan ini yang membutuhkan lebih banyak waktu. Ayo pergi secara berurutan.
Muat data
Semuanya sangat sederhana di sini. Mari muat data dan ganti nama kolom dengan label target "is_duplicate" dengan "target". Ini untuk kemudahan penggunaan fungsi - beberapa di antaranya ditulis sebagai bagian dari penelitian sebelumnya dan mereka menggunakan nama kolom dengan label target sebagai "target".
Kode
# DOWNLOAD DATA
text_train = pd.read_csv('train.csv')
text_test = pd.read_csv('test.csv')
# RENAME DATA
text_train = text_train.rename(columns={"is_duplicate": "target"})Mari kita lihat datanya
Data telah dimuat. Mari kita lihat berapa banyak objek secara total dan seberapa seimbangnya mereka.
Kode
# ANALYSE BALANCE OF DATA
target_1 = text_train[text_train['target']==1]['target'].count()
target_0 = text_train[text_train['target']==0]['target'].count()
print ('There are', text_train.shape[0], 'objects')
print ('There are', target_1, 'objects with target 1')
print ('There are', target_0, 'objects with target 0')
print ('Balance is', round(100*target_1/target_0,2),'%')Tabel №1 "Balance of marks"

Ada banyak objek - hampir 500 ribu dan mereka tidak seimbang sama sekali. Artinya, dari hampir 500 ribu objek, total kurang dari 4 ribu memiliki label target 1 (kurang dari 1%).
Mari kita lihat tabel itu sendiri. Mari kita lihat lima objek pertama berlabel 0 dan lima objek pertama berlabel 1.
Kode
display(text_train[text_train['target']==0].head(5))
display(text_train[text_train['target']==1].head(5))Tabel No. 2 "5 objek pertama kelas 0", tabel No. 3 "5 objek pertama dari kelas 1"
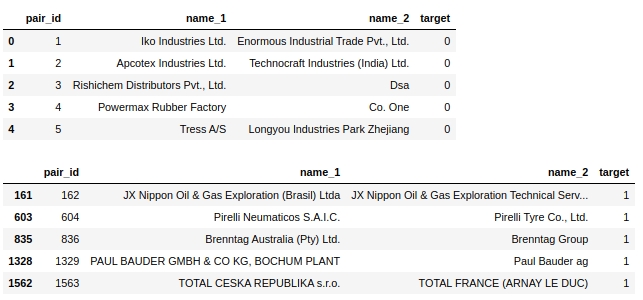
Beberapa langkah sederhana langsung menyarankan diri mereka sendiri: bawa teks ke satu register, hapus kata-kata berhenti, seperti 'ltd', hapus negara dan pada saat yang sama nama-nama geografis benda.
Sebenarnya, hal seperti ini dapat diselesaikan dalam masalah ini - Anda melakukan beberapa praproses, memastikan bahwa itu berfungsi sebagaimana mestinya, menjalankan model, melihat kualitas dan secara selektif menganalisis objek yang modelnya salah. Beginilah cara saya melakukan penelitian. Namun dalam artikel itu sendiri, solusi akhir diberikan dan kualitas algoritma setelah setiap preprocessing tidak dipahami, di akhir artikel kami akan melakukan analisis akhir. Jika tidak, artikel itu akan menjadi ukuran yang tak terlukiskan :)
Ayo buat salinan
Sejujurnya, saya tidak tahu mengapa saya melakukan ini, tetapi untuk beberapa alasan saya selalu melakukannya. Saya akan melakukannya kali ini juga
Kode
baseline_train = text_train.copy()
baseline_test = text_test.copy()Mari kita ubah semua karakter dari teks menjadi huruf kecil
Kode
# convert text to lowercase
columns = ['name_1','name_2']
for column in columns:
lower_str(baseline_train,column)
for column in columns:
lower_str(baseline_test,column)Hapus nama negara
Perlu dicatat bahwa penyelenggara kompetisi adalah orang-orang yang hebat! Bersamaan dengan penugasan tersebut, mereka memberikan laptop dengan baseline yang sangat sederhana yang di dalamnya disediakan termasuk kode di bawah ini.
Kode
# drop any names of countries
countries = [country.name.lower() for country in pycountry.countries]
for country in tqdm(countries):
baseline_train.replace(re.compile(country), "", inplace=True)
baseline_test.replace(re.compile(country), "", inplace=True)Hapus tanda dan karakter khusus
Kode
# drop punctuation marks
baseline_train.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_test.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_train.replace(re.compile(r"[^\w\s]"), "", inplace=True)
baseline_test.replace(re.compile(r"[^\w\s]"), "", inplace=True)Hapus nomor
Menghapus nomor dari teks langsung di dahi, pada upaya pertama, sangat merusak kualitas model. Saya akan memberikan kodenya di sini, tetapi ternyata kode itu tidak digunakan.
Perhatikan juga bahwa hingga saat ini, kami telah melakukan transformasi langsung pada kolom yang diberikan kepada kami. Sekarang mari buat kolom baru untuk setiap preprocessing. Akan ada lebih banyak kolom, tetapi jika di suatu tempat pada beberapa tahap preprocessing terjadi kegagalan, tidak apa-apa, Anda tidak perlu melakukan semuanya dari awal, karena kita akan memiliki kolom dari setiap tahap preprocessing.
Kode yang merusak kualitas. Anda harus lebih lembut
# # first: make dictionary of frequency every word
# list_words = baseline_train['name_1'].to_string(index=False).split() +\
# baseline_train['name_2'].to_string(index=False).split()
# freq_words = {}
# for w in list_words:
# freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame of frequency words
# df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
# df_freq.columns = ['word','frequency']
# df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
# df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
# df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
# # third: make drop list of digits
# string = df_freq_agg['word'].to_string(index=False)
# digits = [int(digit) for digit in string.split() if digit.isdigit()]
# digits = set(digits)
# digits = list(digits)
# # drop the digits
# baseline_train['name_1_no_digits'] =\
# baseline_train['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_train['name_2_no_digits'] =\
# baseline_train['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_1_no_digits'] =\
# baseline_test['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_2_no_digits'] =\
# baseline_test['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))Mari kita hapus ... daftar stopword pertama. Secara manual!
Sekarang disarankan untuk mendefinisikan dan menghapus kata berhenti dari daftar kata dalam nama perusahaan.
Kami telah menyusun daftar tersebut berdasarkan tinjauan manual dari sampel pelatihan. Logikanya, daftar seperti itu harus dikompilasi secara otomatis menggunakan pendekatan berikut:
- pertama, gunakan 10 (20,50.100) kata umum teratas.
- kedua, menggunakan pustaka kata stop standar dalam berbagai bahasa. Misalnya, penunjukan bentuk organisasi dan hukum organisasi dalam berbagai bahasa (LLC, PJSC, CJSC, ltd, gmbh, inc, dll.)
- ketiga, menyusun daftar nama tempat dalam berbagai bahasa
Kami akan kembali ke opsi pertama untuk secara otomatis menyusun daftar kata-kata yang paling sering muncul, tetapi untuk saat ini kami melihat prapemrosesan manual.
Kode
# drop some stop-words
drop_list = ["ltd.", "co.", "inc.", "b.v.", "s.c.r.l.", "gmbh", "pvt.",
'retail','usa','asia','ceska republika','limited','tradig','llc','group',
'international','plc','retail','tire','mills','chemical','korea','brasil',
'holding','vietnam','tyre','venezuela','polska','americas','industrial','taiwan',
'europe','america','north','czech republic','retailers','retails',
'mexicana','corporation','corp','ltd','co','toronto','nederland','shanghai','gmb','pacific',
'industries','industrias',
'inc', 'ltda', '', '', '', '', '', '', '', '', 'ceska republika', 'ltda',
'sibur', 'enterprises', 'electronics', 'products', 'distribution', 'logistics', 'development',
'technologies', 'pvt', 'technologies', 'comercio', 'industria', 'trading', 'internacionais',
'bank', 'sports',
'express','east', 'west', 'south', 'north', 'factory', 'transportes', 'trade', 'banco',
'management', 'engineering', 'investments', 'enterprise', 'city', 'national', 'express', 'tech',
'auto', 'transporte', 'technology', 'and', 'central', 'american',
'logistica','global','exportacao', 'ceska republika', 'vancouver', 'deutschland',
'sro','rus','chemicals','private','distributors','tyres','industry','services','italia','beijing',
'','company','the','und']
baseline_train['name_1_non_stop_words'] =\
baseline_train['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_non_stop_words'] =\
baseline_train['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_non_stop_words'] =\
baseline_test['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_non_stop_words'] =\
baseline_test['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))Mari selektif memeriksa apakah kata-kata berhenti kita benar-benar telah dihapus dari teks.
Kode
baseline_train[baseline_train.name_1_non_stop_words.str.contains("factory")].head(3)Tabel 4 "Pemeriksaan selektif kode untuk menghapus kata-kata berhenti"

Semuanya tampaknya bekerja. Menghapus semua kata berhenti yang dipisahkan oleh spasi. Apa yang kami inginkan. Bergerak.
Mari mentransliterasi teks Rusia ke dalam alfabet Latin
Saya menggunakan fungsi yang ditulis sendiri dan perpustakaan cyrtranslit untuk ini. Sepertinya berhasil. Diperiksa secara manual.
Kode
# transliteration to latin
baseline_train['name_1_transliterated'] = transliterate(baseline_train['name_1_non_stop_words'])
baseline_train['name_2_transliterated'] = transliterate(baseline_train['name_2_non_stop_words'])
baseline_test['name_1_transliterated'] = transliterate(baseline_test['name_1_non_stop_words'])
baseline_test['name_2_transliterated'] = transliterate(baseline_test['name_2_non_stop_words'])Mari kita lihat pasangan dengan id 353150. Di dalamnya, kolom kedua ("name_2") ada kata "Michelin", setelah preprocessing kata tersebut sudah tertulis seperti ini "mishlen" (lihat kolom "name_2_transliterated"). Tidak sepenuhnya benar, tapi jelas lebih baik.
Kode
pair_id = 353150
baseline_train[baseline_train['pair_id']==353150]Tabel nomor 5 "Verifikasi kode selektif untuk transliterasi"

Mari kita mulai kompilasi otomatis dari daftar 50 kata teratas yang paling sering muncul & Jatuhkan dengan cerdas. CHIT pertama
Judul yang agak rumit. Mari kita lihat apa yang akan kita lakukan di sini.
Pertama, kita akan menggabungkan teks dari kolom pertama dan kedua menjadi satu larik dan menghitung berapa kali itu muncul untuk setiap kata unik.
Kedua, mari kita pilih 50 kata teratas ini. Dan tampaknya Anda dapat menghapusnya, tetapi tidak. Kata-kata ini mungkin berisi nama-nama kepemilikan ('total', 'knauf', 'shell', ...), tetapi ini adalah informasi yang sangat penting dan tidak dapat hilang, karena kami akan menggunakannya lebih lanjut. Oleh karena itu, kami akan melakukan trik curang (terlarang). Untuk memulainya, atas dasar studi yang cermat dan selektif terhadap sampel pelatihan, kami akan menyusun daftar nama kepemilikan yang sering ditemui. Daftarnya tidak akan lengkap, jika tidak maka tidak akan adil sama sekali :) Meskipun, karena kita tidak mengejar hadiah, mengapa tidak. Kemudian kita akan membandingkan larik dari 50 kata teratas yang sering muncul dengan daftar nama induk dan menghapus dari daftar kata yang cocok dengan nama kepemilikan.
Daftar stopword kedua sekarang sudah selesai. Anda dapat menghapus kata-kata dari teks.
Namun sebelum itu, saya ingin menyisipkan sedikit komentar terkait daftar curang nama holding. Fakta bahwa kami telah menyusun daftar nama-nama kepemilikan berdasarkan pengamatan membuat hidup kami jauh lebih mudah. Namun kenyataannya, kami dapat menyusun daftar seperti itu dengan cara yang berbeda. Misalnya, Anda dapat mengambil peringkat perusahaan terbesar di industri petrokimia, konstruksi, otomotif, dan lainnya, menggabungkannya dan mengambil nama kepemilikan dari sana. Tetapi untuk tujuan penelitian kami, kami akan membatasi diri pada pendekatan sederhana. Pendekatan ini dilarang dalam kompetisi! Selain itu, penyelenggara kompetisi, pekerjaan calon tempat hadiah diperiksa untuk teknik yang dilarang. Hati-hati!
Kode
list_top_companies = ['arlanxeo', 'basf', 'bayer', 'bdp', 'bosch', 'brenntag', 'contitech',
'daewoo', 'dow', 'dupont', 'evonik', 'exxon', 'exxonmobil', 'freudenberg',
'goodyear', 'goter', 'henkel', 'hp', 'hyundai', 'isover', 'itochu', 'kia', 'knauf',
'kraton', 'kumho', 'lusocopla', 'michelin', 'paul bauder', 'pirelli', 'ravago',
'rehau', 'reliance', 'sabic', 'sanyo', 'shell', 'sherwinwilliams', 'sojitz',
'soprema', 'steico', 'strabag', 'sumitomo', 'synthomer', 'synthos',
'total', 'trelleborg', 'trinseo', 'yokohama']
# drop top 50 common words (NAME 1 & NAME 2) exept names of top companies
# first: make dictionary of frequency every word
list_words = baseline_train['name_1_transliterated'].to_string(index=False).split() +\
baseline_train['name_2_transliterated'].to_string(index=False).split()
freq_words = {}
for w in list_words:
freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame
df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
df_freq.columns = ['word','frequency']
df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
drop_list = list(set(df_freq_agg[0:50]['word'].to_string(index=False).split()) - set(list_top_companies))
# # check list of top 50 common words
# print (drop_list)
# drop the top 50 words
baseline_train['name_1_finish'] =\
baseline_train['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_finish'] =\
baseline_train['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_finish'] =\
baseline_test['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_finish'] =\
baseline_test['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
Di sinilah kita selesai dengan pemrosesan awal data. Mari mulai membuat fitur baru dan menilai mereka secara visual untuk kemampuan memisahkan objek dengan 0 atau 1.
Pembuatan dan analisis fitur
Mari kita hitung jarak Levenshtein
Mari kita gunakan pustaka strsimpy dan di setiap pasangan (setelah semua pemrosesan awal) kita akan menghitung jarak Levenshtein dari nama perusahaan dari kolom pertama ke nama perusahaan di kolom kedua.
Kode
# create feature with LEVENSTAIN DISTANCE
levenshtein = Levenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["levenstein"] = baseline_train.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)
baseline_test["levenstein"] = baseline_test.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)Mari kita hitung jarak Levenshtein yang dinormalisasi
Semuanya sama seperti di atas, hanya saja kita akan menghitung jarak yang dinormalisasi.
Header spoiler
# create feature with NORMALIZATION LEVENSTAIN DISTANCE
normalized_levenshtein = NormalizedLevenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["norm_levenstein"] = baseline_train.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)
baseline_test["norm_levenstein"] = baseline_test.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)Kami menghitung, dan sekarang kami memvisualisasikan
Memvisualisasikan fitur
Mari kita lihat persebaran sifat 'levenstein'
Kode
data = baseline_train
analyse = 'levenstein'
size = (12,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Grafik # 1 "Histogram dan kotak dengan kumis untuk menilai pentingnya fitur"
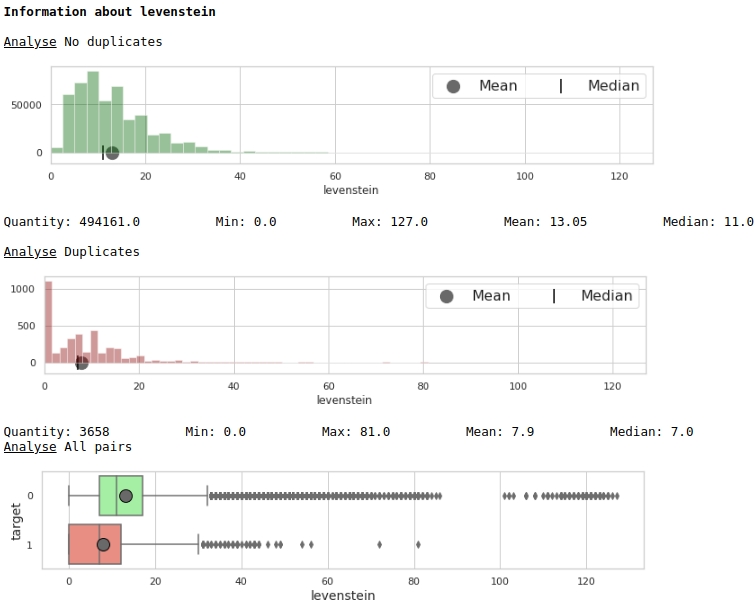
Sekilas, metrik dapat menandai data. Jelas tidak terlalu bagus, tapi bisa digunakan.
Mari kita lihat distribusi sifat 'norm_levenstein'
Header spoiler
data = baseline_train
analyse = 'norm_levenstein'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Grafik №2 "Histogram dan kotak dengan kumis untuk menilai signifikansi tanda"

Sudah lebih baik. Sekarang, mari kita lihat bagaimana dua fitur gabungan akan membagi ruang menjadi objek 0 dan 1.
Kode
data = baseline_train
analyse1 = 'levenstein'
analyse2 = 'norm_levenstein'
size = (14,6)
two_features(data,analyse1,analyse2,size)Grafik No. 3 "Diagram sebar"
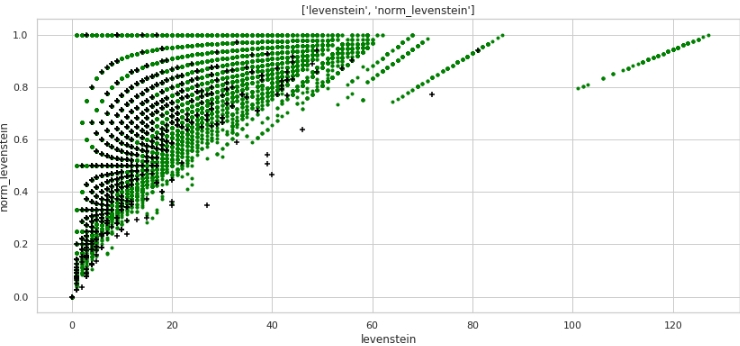
Markup yang sangat baik diperoleh. Jadi tidak sia-sia jika kita melakukan pra-pemrosesan data terlalu banyak :)
Semua orang mengerti bahwa secara horizontal - nilai metrik "levenstein", dan secara vertikal - nilai metrik "norm_levenstein", dan titik hijau dan hitam adalah objek 0 dan 1. Mari kita lanjutkan.
Mari bandingkan kata-kata dalam teks untuk setiap pasangan dan buat banyak fitur
Di bawah ini kami akan membandingkan kata-kata dalam nama perusahaan. Mari buat fitur-fitur berikut:
- daftar kata-kata yang digandakan di kolom # 1 dan # 2 dari setiap pasangan
- daftar kata-kata yang TIDAK diduplikasi
Berdasarkan daftar kata ini, kami akan membuat fitur yang akan kami masukkan ke dalam model yang dilatih:
- jumlah kata duplikat
- jumlah kata BUKAN duplikat
- jumlah karakter, kata duplikat
- jumlah karakter, BUKAN kata duplikat
- panjang rata-rata kata duplikat
- panjang rata-rata dari kata-kata yang TIDAK digandakan
- rasio jumlah duplikat dengan jumlah NOT duplikat
Kode di sini mungkin tidak terlalu bersahabat, karena, sekali lagi, ditulis dengan tergesa-gesa. Tapi itu berhasil, tapi itu akan pergi untuk penelitian cepat.
Kode
# make some information about duplicates and differences for TRAIN
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_train.shape[0]):
list1 = list(baseline_train[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_train[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TRAIN
baseline_train['duplicate'] = duplicates
baseline_train['difference'] = difference
baseline_train['duplicate_count'] = duplicate_count
baseline_train['duplicate_sum'] = duplicate_sum
baseline_train['duplicate_mean'] = baseline_train['duplicate_sum'] / baseline_train['duplicate_count']
baseline_train['duplicate_mean'] = baseline_train['duplicate_mean'].fillna(0)
baseline_train['dif_count'] = dif_count
baseline_train['dif_sum'] = dif_sum
baseline_train['dif_mean'] = baseline_train['dif_sum'] / baseline_train['dif_count']
baseline_train['dif_mean'] = baseline_train['dif_mean'].fillna(0)
baseline_train['ratio_duplicate/dif_count'] = baseline_train['duplicate_count'] / baseline_train['dif_count']
# make some information about duplicates and differences for TEST
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_test.shape[0]):
list1 = list(baseline_test[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_test[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TEST
baseline_test['duplicate'] = duplicates
baseline_test['difference'] = difference
baseline_test['duplicate_count'] = duplicate_count
baseline_test['duplicate_sum'] = duplicate_sum
baseline_test['duplicate_mean'] = baseline_test['duplicate_sum'] / baseline_test['duplicate_count']
baseline_test['duplicate_mean'] = baseline_test['duplicate_mean'].fillna(0)
baseline_test['dif_count'] = dif_count
baseline_test['dif_sum'] = dif_sum
baseline_test['dif_mean'] = baseline_test['dif_sum'] / baseline_test['dif_count']
baseline_test['dif_mean'] = baseline_test['dif_mean'].fillna(0)
baseline_test['ratio_duplicate/dif_count'] = baseline_test['duplicate_count'] / baseline_test['dif_count']
Kami memvisualisasikan beberapa tanda.
Kode
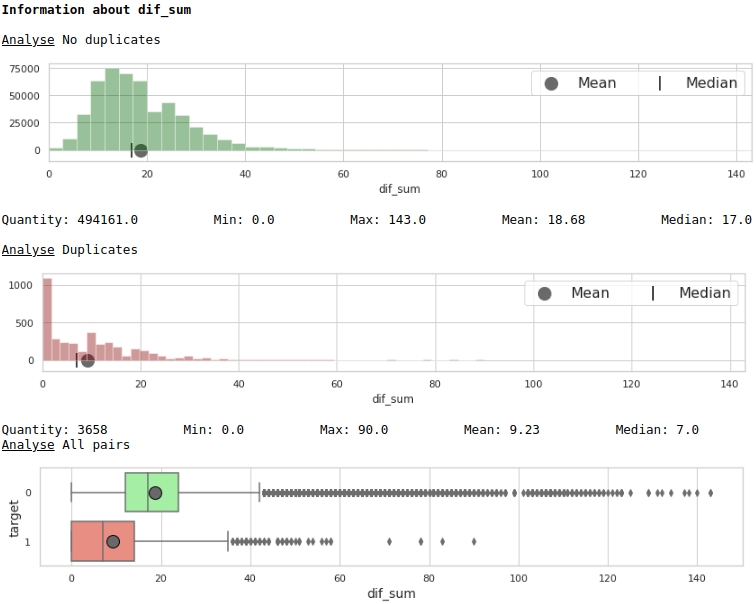
data = baseline_train
analyse = 'dif_sum'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Grafik No. 4 "Histogram dan kotak dengan kumis untuk menilai pentingnya tanda"
Kode
data = baseline_train
analyse1 = 'duplicate_mean'
analyse2 = 'dif_mean'
size = (14,6)
two_features(data,analyse1,analyse2,size)Grafik №5 "Diagram sebar"
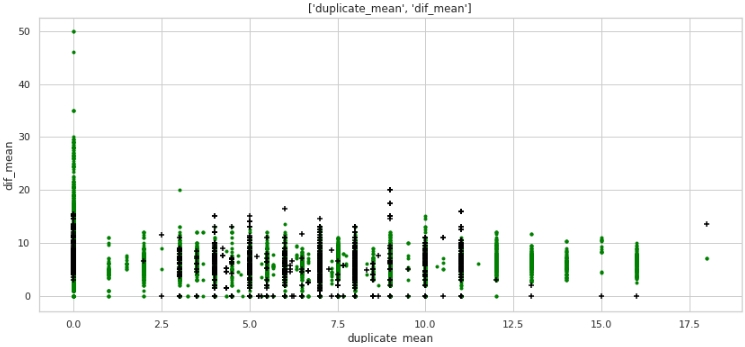
Apa tidak, tapi markup. Perhatikan bahwa banyak perusahaan dengan label target 1 tidak memiliki duplikat dalam teks, dan juga banyak perusahaan dengan duplikat dalam namanya, rata-rata lebih dari 12 kata, termasuk dalam perusahaan dengan label target 0.
Mari kita lihat data tabel, siapkan kueri untuk Dalam kasus pertama: tidak ada duplikat atas nama perusahaan, tetapi perusahaannya sama.
Kode
baseline_train[
baseline_train['duplicate_mean']==0][
baseline_train['target']==1].drop(
['duplicate', 'difference',
'name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated'],axis=1)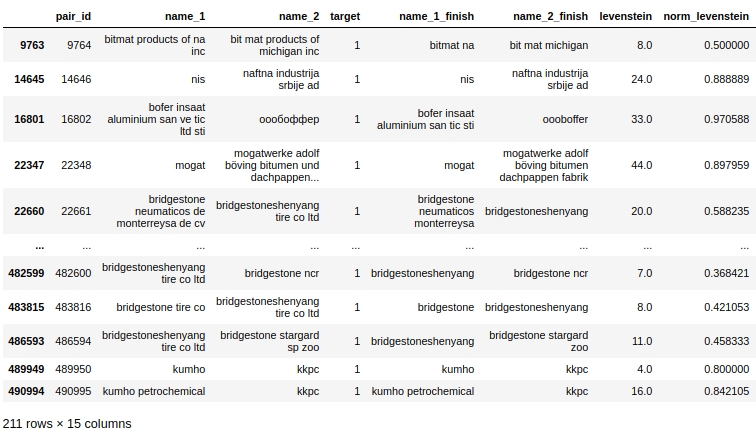
Jelas ada kesalahan sistem dalam pemrosesan kami. Kami tidak memperhitungkan bahwa kata-kata dapat dieja tidak hanya dengan kesalahan, tetapi juga hanya bersama-sama atau, sebaliknya, secara terpisah di mana ini tidak diperlukan. Misalnya, pasangkan # 9764. Di kolom pertama 'bitmat' di 'bit mat' kedua dan sekarang ini bukan double, tetapi perusahaannya sama. Atau contoh lain, pasangkan # 482600 'bridgestoneshenyang' dan 'bridgestone'.
Apa yang bisa dilakukan. Hal pertama yang terpikir oleh saya adalah membandingkan tidak langsung di dahi, tetapi menggunakan metrik Levenshtein. Tapi di sini, juga, penyergapan menanti kita: jarak antara 'bridgestoneshenyang' dan 'bridgestone' tidak akan kecil. Mungkin lemmatisasi akan membantu, tetapi sekali lagi tidak segera jelas bagaimana nama-nama perusahaan dapat dilemmatisasi. Atau Anda dapat menggunakan koefisien Tamimoto, tetapi biarkan momen ini untuk rekan yang lebih berpengalaman dan lanjutkan.
Mari kita bandingkan kata-kata dari teks dengan kata-kata dari nama-nama dari 50 merek induk teratas di industri petrokimia, konstruksi dan lainnya. Mari kita dapatkan banyak fitur kedua. CHIT kedua
Padahal, ada dua pelanggaran aturan untuk mengikuti kompetisi:
- -, , «duplicate_name_company»
- -, . , .
Kedua teknik tersebut dilarang oleh peraturan kompetisi. Anda dapat melewati larangan tersebut. Untuk melakukannya, Anda perlu mengompilasi daftar nama holding tidak secara manual berdasarkan tampilan selektif dari sampel pelatihan, tetapi secara otomatis - dari sumber eksternal. Tetapi kemudian, pertama, daftar kepemilikan akan menjadi besar dan perbandingan kata-kata yang diusulkan dalam pekerjaan akan memakan waktu sangat, yah, hanya banyak waktu, dan kedua, daftar ini masih perlu disusun :) Oleh karena itu, untuk tujuan kesederhanaan penelitian, kami akan memeriksa seberapa besar kualitas model akan meningkat dengan tanda-tanda ini. Ke depan - kualitas tumbuh luar biasa!
Dengan metode pertama, semuanya tampak jelas, tetapi pendekatan kedua membutuhkan penjelasan.
Jadi, mari kita tentukan jarak Levenshtein dari setiap kata di setiap baris pada kolom pertama dengan nama perusahaan untuk setiap kata dari daftar perusahaan petrokimia teratas (dan tidak hanya).
Jika rasio jarak Levenshtein dengan panjang kata kurang dari atau sama dengan 0,4, maka kami menentukan rasio jarak Levenshtein ke kata yang dipilih dari daftar perusahaan teratas untuk setiap kata dari kolom kedua - nama perusahaan kedua.
Jika koefisien kedua (rasio jarak terhadap panjang kata dari daftar perusahaan teratas) ternyata di bawah atau sama dengan 0,4, maka kami menetapkan nilai-nilai berikut pada tabel:
- Jarak Levenshtein dari sebuah kata dari daftar perusahaan No. 1 ke sebuah kata dalam daftar perusahaan teratas
- Jarak Levenshtein dari sebuah kata dari daftar perusahaan No. 2 ke sebuah kata dalam daftar perusahaan teratas
- panjang kata dari daftar # 1
- panjang kata dari daftar # 2
- panjang kata dari daftar perusahaan teratas
- rasio panjang kata dari daftar # 1 dengan jarak
- rasio panjang kata dari daftar No. 2 dengan jarak
Mungkin ada lebih dari satu kecocokan dalam satu baris, mari kita pilih jumlah minimumnya (fungsi agregasi).
Saya ingin sekali lagi menarik perhatian Anda pada fakta bahwa metode yang diusulkan untuk menghasilkan fitur cukup intensif sumber daya dan dalam kasus mendapatkan daftar dari sumber eksternal, perubahan dalam kode untuk menyusun metrik akan diperlukan.
Kode
# create information about duplicate name of petrochemical companies from top list
list_top_companies = list_top_companies
dp_train = []
for i in list(baseline_train['duplicate']):
dp_train.append(''.join(list(set(i) & set(list_top_companies))))
dp_test = []
for i in list(baseline_test['duplicate']):
dp_test.append(''.join(list(set(i) & set(list_top_companies))))
baseline_train['duplicate_name_company'] = dp_train
baseline_test['duplicate_name_company'] = dp_test
# replace name duplicate to number
baseline_train['duplicate_name_company'] =\
baseline_train['duplicate_name_company'].replace('',0,regex=True)
baseline_train.loc[baseline_train['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
baseline_test['duplicate_name_company'] =\
baseline_test['duplicate_name_company'].replace('',0,regex=True)
baseline_test.loc[baseline_test['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
# create some important feature about similar words in the data and names of top companies for TRAIN
# (levenstein distance, length of word, ratio distance to length)
baseline_train = dist_name_to_top_list_make(baseline_train,
'name_1_finish','name_2_finish',list_top_companies)
# create some important feature about similar words in the data and names of top companies for TEST
# (levenstein distance, length of word, ratio distance to length)
baseline_test = dist_name_to_top_list_make(baseline_test,
'name_1_finish','name_2_finish',list_top_companies)
Mari kita lihat kegunaan fitur melalui prisma grafik
Kode
data = baseline_train
analyse = 'levenstein_dist_w1_top_w_min'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)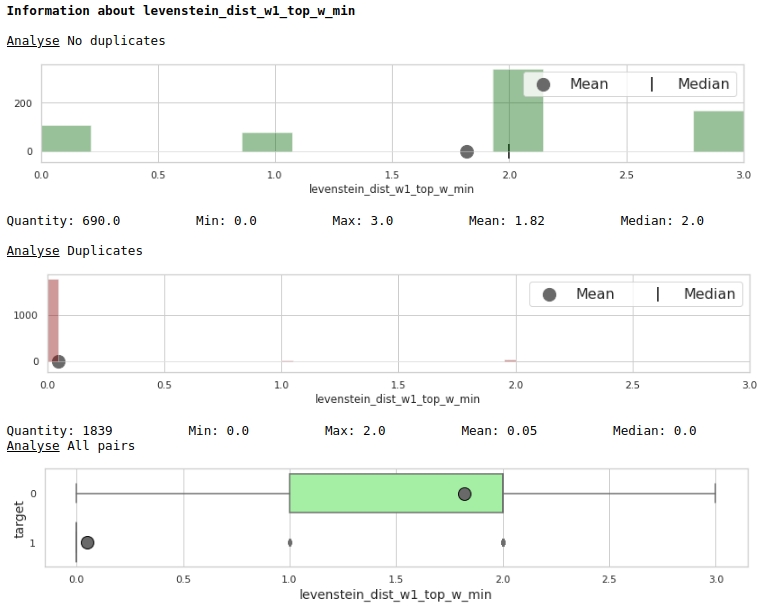
Baik sekali.
Mempersiapkan data untuk dikirimkan ke model
Kami memiliki tabel besar dan kami tidak membutuhkan semua data untuk analisis. Mari kita lihat nama-nama kolom tabel.
Kode
baseline_train.columns
Mari pilih kolom yang akan kita analisis.
Mari perbaiki benih untuk reproduktifitas hasil.
Kode
# fix some parameters
features = ['levenstein','norm_levenstein',
'duplicate_count','duplicate_sum','duplicate_mean',
'dif_count','dif_sum','dif_mean','ratio_duplicate/dif_count',
'duplicate_name_company',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min'
]
seed = 42Sebelum akhirnya melatih model pada semua data yang tersedia dan mengirimkan solusi untuk verifikasi, sebaiknya uji model tersebut. Untuk melakukan ini, kami membagi sampel pelatihan menjadi pelatihan bersyarat dan pengujian bersyarat. Kami akan mengukur kualitasnya dan jika sesuai dengan kami, maka kami akan mengirimkan solusi ke kompetisi.
Kode
# provides train/test indices to split data in train/test sets
split = StratifiedShuffleSplit(n_splits=1, train_size=0.8, random_state=seed)
tridx, cvidx = list(split.split(baseline_train[features],
baseline_train["target"]))[0]
print ('Split baseline data train',baseline_train.shape[0])
print (' - new train data:',tridx.shape[0])
print (' - new test data:',cvidx.shape[0])Menyiapkan dan melatih model
Kami akan menggunakan pohon keputusan dari pustaka Light GBM sebagai model.
Tidak masuk akal untuk mengakhiri parameter terlalu banyak. Kami melihat kodenya.
Kode
# learning Light GBM Classificier
seed = 50
params = {'n_estimators': 1,
'objective': 'binary',
'max_depth': 40,
'min_child_samples': 5,
'learning_rate': 1,
# 'reg_lambda': 0.75,
# 'subsample': 0.75,
# 'colsample_bytree': 0.4,
# 'min_split_gain': 0.02,
# 'min_child_weight': 40,
'random_state': seed}
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train.iloc[tridx][features].values,
baseline_train.iloc[tridx]["target"].values)Model disetel dan dilatih. Sekarang mari kita lihat hasilnya.
Kode
# make predict proba and predict target
probability_level = 0.99
X = baseline_train
tridx = tridx
cvidx = cvidx
model = model
X_tr, X_cv = contingency_table(X,features,probability_level,tridx,cvidx,model)
train_matrix_confusion = matrix_confusion(X_tr)
cv_matrix_confusion = matrix_confusion(X_cv)
report_score(train_matrix_confusion,
cv_matrix_confusion,
baseline_train,
tridx,cvidx,
X_tr,X_cv)
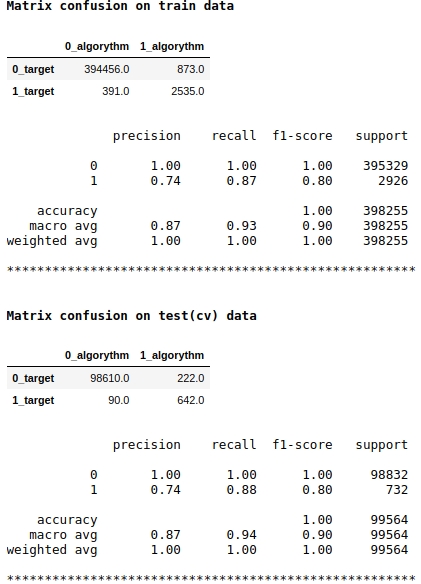
Perhatikan bahwa kami menggunakan metrik kualitas f1 sebagai skor model. Ini berarti bahwa masuk akal untuk mengatur tingkat probabilitas penugasan suatu objek ke kelas 1 atau 0. Kami telah memilih level 0,99, yaitu, jika probabilitasnya sama atau lebih tinggi dari 0,99, objek tersebut akan ditempatkan ke kelas 1, di bawah 0,99 - ke kelas 0. Ini adalah poin penting - Anda dapat meningkatkan kecepatan secara signifikan trik sederhana yang rumit.
Kualitasnya sepertinya lumayan. Pada sampel uji bersyarat, algoritme membuat kesalahan saat mendefinisikan 222 objek kelas 0 dan pada 90 objek milik kelas 0 membuat kesalahan dan menugaskannya ke kelas 1 (lihat Kebingungan matriks pada data uji (cv)).
Mari kita lihat tanda mana yang paling penting dan mana yang tidak.
Kode
start = 0
stop = 50
size = (12,6)
tg = table_gain_coef(model,features,start,stop)
gain_hist(tg,size,start,stop)
display(tg)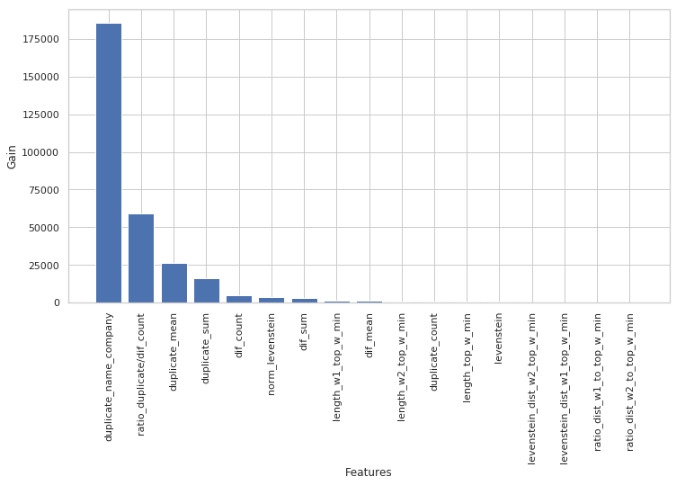
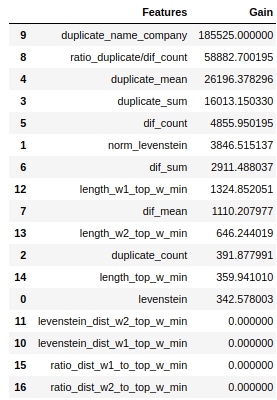
Perhatikan bahwa kami menggunakan parameter 'gain', bukan parameter 'split' untuk menilai signifikansi fitur. Ini penting karena dalam versi yang sangat sederhana, parameter pertama berarti kontribusi fitur terhadap penurunan entropi, dan yang kedua menunjukkan berapa kali fitur digunakan untuk menandai spasi.
Sekilas, fitur yang sudah lama kita lakukan, "levenstein_dist_w1_top_w_min", ternyata tidak informatif sama sekali - kontribusinya 0. Tapi ini hanya sekilas saja. Ini hampir sepenuhnya digandakan artinya dengan atribut "nama_perusahaan_duplikat". Jika Anda menghapus "nama_perusahaan_duplikat" dan meninggalkan "levenstein_dist_w1_top_w_min", maka fitur kedua akan menggantikan yang pertama dan kualitasnya tidak akan berubah. Diperiksa!
Secara umum, tanda seperti itu adalah hal yang berguna, terutama ketika Anda memiliki ratusan fitur dan model dengan banyak lonceng dan peluit serta 5.000 iterasi. Anda dapat menghapus fitur secara berkelompok dan melihat bagaimana kualitas tumbuh dari tindakan yang tidak licik ini. Dalam kasus kami, penghapusan fitur tidak akan memengaruhi kualitas.
Mari kita lihat tabel pasangan. Pertama-tama, mari kita lihat objek "False Positive", yaitu, yang ditentukan oleh algoritme kami agar sama dan menugaskannya ke kelas 1, tetapi sebenarnya objek tersebut termasuk kelas 0.
Kode
X_cv[X_cv['False_Positive']==1][0:50].drop(['name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated', 'duplicate', 'difference',
'levenstein',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min',
'True_Positive','True_Negative','False_Negative'],axis=1)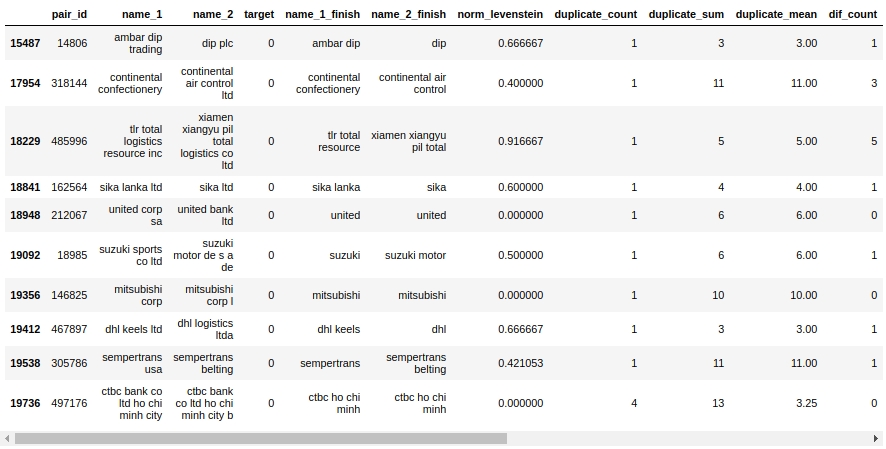
Ya. Di sini, seseorang tidak akan langsung menentukan 0 atau 1. Misalnya pasangan # 146825 "mitsubishi corp" dan "mitsubishi corp l". Mata mengatakan itu hal yang sama, tetapi sampel mengatakan itu perusahaan yang berbeda. Siapa yang harus dipercaya?
Anggap saja Anda dapat langsung memeras - kami memeras. Sisanya akan kami serahkan kepada rekan-rekan yang berpengalaman :)
Ayo upload datanya ke website penyelenggara dan cari tahu penilaian kualitas pekerjaannya.
Hasil kompetisi
Kode
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train[features].values,
baseline_train["target"].values)
sample_sub = pd.read_csv('sample_submission.csv', index_col="pair_id")
sample_sub['is_duplicate'] = (model.predict_proba(
baseline_test[features].values)[:, 1] > probability_level).astype(np.int)
sample_sub.to_csv('baseline_submission.csv')
Jadi, kecepatan kami, dengan mempertimbangkan metode terlarang: 0,5999
Tanpa itu, kualitasnya berada di antara 0,3 dan 0,4. Kita perlu me-restart model untuk akurasi, tapi saya agak terlalu malas :)
Mari kita rangkum pengalamannya dengan lebih baik.
Pertama, seperti yang Anda lihat, kami memiliki kode yang cukup dapat direproduksi dan struktur file yang cukup memadai. Karena sedikit pengalaman saya, saya pernah mengisi banyak gundukan justru karena saya mengisi pekerjaan dengan tergesa-gesa, hanya untuk mendapatkan kecepatan yang kurang lebih menyenangkan. Akibatnya, file tersebut ternyata sedemikian rupa sehingga setelah seminggu sudah menakutkan untuk membukanya - tidak ada yang begitu jelas. Oleh karena itu, pesan saya adalah segera menulis kode dan membuat file dapat dibaca, sehingga dalam setahun Anda dapat kembali ke data, lihat strukturnya terlebih dahulu, pahami langkah-langkah apa yang diambil dan kemudian agar setiap langkah dapat dengan mudah dibongkar. Tentu saja, jika Anda seorang pemula, maka pada percobaan pertama file tersebut tidak akan indah, kode akan rusak, akan ada kruk, tetapi jika Anda menulis ulang kode secara berkala selama proses penelitian,kemudian dengan 5-7 kali penulisan ulang, Anda sendiri akan terkejut melihat betapa lebih bersihnya kode tersebut dan bahkan mungkin menemukan kesalahan dan meningkatkan kecepatan. Jangan lupa tentang fungsinya, itu membuat file sangat mudah dibaca.
Kedua, setelah setiap pemrosesan data, periksa apakah semuanya berjalan sesuai rencana. Untuk melakukan ini, Anda harus dapat memfilter tabel di panda. Ada banyak penyaringan dalam pekerjaan ini, gunakan untuk kesehatan :)
Ketiga, selalu, selalu, dalam tugas klasifikasi, membentuk tabel dan matriks konjugasi. Dari tabel tersebut, Anda dapat dengan mudah menemukan objek mana yang algoritmanya salah. Untuk memulainya, coba perhatikan kesalahan-kesalahan yang disebut kesalahan sistem, mereka membutuhkan lebih sedikit pekerjaan untuk memperbaikinya, dan memberikan lebih banyak hasil. Kemudian, saat Anda menyelesaikan kesalahan sistem, buka kasus khusus. Dengan matriks kesalahan, Anda akan melihat di mana algoritme membuat lebih banyak kesalahan: pada kelas 0 atau 1. Dari sini Anda akan menggali kesalahan. Sebagai contoh, saya perhatikan bahwa pohon saya mendefinisikan kelas 1 dengan baik, tetapi membuat banyak kesalahan pada kelas 0, yaitu, pohon sering "mengatakan" bahwa objek ini adalah kelas 1, padahal sebenarnya 0. Saya berasumsi bahwa itu mungkin terkait dengan tingkat kemungkinan mengklasifikasikan objek sebagai 0 atau 1. Level saya ditetapkan pada 0,9.Peningkatan tingkat probabilitas untuk menetapkan objek ke kelas 1 menjadi 0,99 membuat pemilihan objek kelas 1 lebih sulit dan voila - kecepatan kami telah memberikan peningkatan yang signifikan.
Sekali lagi, saya akan mencatat bahwa tujuan mengikuti kompetisi bukanlah untuk memenangkan hadiah, tetapi untuk mendapatkan pengalaman. Mengingat sebelum dimulainya kompetisi, saya tidak tahu bagaimana menggunakan teks dalam pembelajaran mesin, dan pada akhirnya, dalam beberapa hari, saya mendapatkan model yang sederhana namun tetap berfungsi, maka kita dapat mengatakan bahwa tujuan telah tercapai. Juga, untuk setiap samurai pemula di dunia ilmu data, menurut saya penting untuk mendapatkan pengalaman, bukan hadiah, atau lebih tepatnya, pengalaman adalah hadiahnya. Karena itu, jangan takut untuk berpartisipasi dalam kompetisi, lakukanlah, semua orang adalah berang-berang!
Pada saat artikel dipublikasikan, kompetisi belum selesai. Berdasarkan hasil penyelesaian kompetisi, dalam komentar artikel, saya akan menulis tentang kecepatan wajar maksimum, tentang pendekatan dan fitur yang meningkatkan kualitas model.
Dan Anda adalah pembaca yang budiman, jika Anda memiliki ide tentang cara meningkatkan kecepatan sekarang, tulis di komentar. Lakukan perbuatan baik :)
Sumber informasi, bahan pembantu
- "Github dengan Data dan Notebook Jupyter"
- "Platform Kompetisi SIBUR CHALLENGE 2020"
- "Situs penyelenggara kompetisi SIBUR CHALLENGE 2020"
- "Artikel bagus tentang Habré" Dasar-dasar Pemrosesan Bahasa Alami untuk Teks ""
- "Artikel bagus lainnya tentang Habré" Perbandingan string kabur: mengerti saya jika Anda bisa ""
- "Publikasi dari majalah APNI"
- "Artikel tentang koefisien Tanimoto" Kesamaan string "tidak digunakan di sini"