LightGBM memperluas algoritme Gradient Boosting dengan menambahkan jenis pemilihan objek otomatis, serta berfokus pada contoh peningkatan dengan gradien besar. Hal ini dapat menyebabkan akselerasi pembelajaran yang dramatis dan kinerja prediksi yang lebih baik. Dengan demikian, LightGBM telah menjadi algoritme de facto untuk kompetisi pembelajaran mesin saat bekerja dengan data tabel untuk masalah pemodelan prediktif regresi dan klasifikasi. Tutorial ini akan menunjukkan cara mendesain ansambel mesin Light Gradient Boosted untuk klasifikasi dan regresi. Setelah menyelesaikan tutorial ini, Anda akan mengetahui:
- Light Gradient Boosted Machine (LightGBM) adalah implementasi open source yang efisien dari ansambel peningkatan gradien stokastik.
- Cara mengembangkan ansambel LightGBM untuk klasifikasi dan regresi menggunakan scikit-learn API.
- LightGBM .

- LightBLM.
- Scikit-Learn API LightGBM.
— LightGBM .
— LightGBM . - LightGBM.
— .
— .
— .
— .
LightBLM
Peningkatan gradien mengacu pada kelas algoritma pembelajaran mesin ensemble yang dapat digunakan untuk masalah klasifikasi atau pemodelan regresi prediktif.
Ensemble dibangun berdasarkan model pohon keputusan. Pohon ditambahkan satu per satu ke ansambel dan dilatih untuk memperbaiki kesalahan prediksi yang dibuat oleh model sebelumnya. Ini adalah jenis model pembelajaran mesin ensemble yang disebut penguat.
Model dilatih menggunakan fungsi kerugian yang dapat dibedakan dan algoritme pengoptimalan penurunan gradien. Hal ini memberi nama metode "peningkatan gradien" karena gradien kerugian diminimalkan saat model dilatih, seperti jaringan neural. Untuk informasi lebih lanjut tentang peningkatan gradien, lihat tutorial:"Pengenalan halus tentang algoritme peningkatan gradien ML . "
LightGBM adalah implementasi open source untuk peningkatan gradien yang dirancang agar efisien, dan bahkan mungkin lebih efisien daripada implementasi lainnya.
Dengan demikian, LightGBM adalah proyek sumber terbuka, pustaka perangkat lunak, dan algoritma pembelajaran mesin. Artinya, proyek tersebut sangat mirip dengan teknik Extreme Gradient Boosting atau XGBoost .
LightGBM telah dijelaskan oleh Golin, K., et al. Untuk informasi lebih lanjut, lihat artikel 2017 berjudul "LightGBM: Pohon Keputusan Pendorong Gradien Sangat Efisien" . Pelaksanaannya memperkenalkan dua ide utama: GOSS dan EFB.
Gradient One-Way Sampling (GOSS) adalah modifikasi dari Gradient Boosting yang berfokus pada tutorial yang menghasilkan gradien yang lebih besar, yang pada gilirannya mempercepat pembelajaran dan mengurangi kompleksitas komputasi metode.
Dengan GOSS, kami mengecualikan sebagian besar instance data dengan gradien kecil dan hanya menggunakan instance data lainnya untuk memperkirakan perolehan informasi. Kami berpendapat bahwa karena instance data dengan gradien besar memainkan peran yang lebih penting dalam menghitung perolehan informasi, GOSS dapat memperoleh perkiraan perolehan informasi yang cukup akurat dengan ukuran data yang jauh lebih kecil.
Paket Fitur Eksklusif, atau EFB, adalah pendekatan untuk menggabungkan fitur yang jarang (kebanyakan nol) saling eksklusif, seperti variabel masukan kategorikal yang dienkode dengan enkode kesatuan. Jadi, ini adalah jenis pemilihan fitur otomatis.
... kami mengemas fitur yang saling eksklusif (yaitu, fitur tersebut jarang mengambil nilai selain nol pada saat yang sama) untuk mengurangi jumlah fitur.
Bersama-sama, kedua perubahan ini dapat mempercepat waktu pelatihan algoritme hingga 20 kali lipat. Dengan demikian, LightGBM dapat dianggap sebagai Gradient Boosted Decision Trees (GBDTs) dengan tambahan GOSS dan EFB.
Kami menyebut penerapan GBDT baru kami GOSS dan EFB LightGBM. Eksperimen kami pada beberapa kumpulan data yang tersedia untuk umum menunjukkan bahwa LightGBM mempercepat proses pembelajaran GBDT konvensional lebih dari 20 kali, mencapai akurasi yang hampir sama.
Scikit-Learn API untuk LightGBM
LightGBM dapat diinstal sebagai pustaka yang berdiri sendiri dan model LightGBM dapat dikembangkan menggunakan scikit-learn API.
Langkah pertama adalah menginstal pustaka LightGBM. Pada kebanyakan platform, hal ini dapat dilakukan dengan menggunakan manajer paket pip; misalnya:
sudo pip install lightgbmAnda dapat memeriksa instalasi dan versinya seperti ini:
# check lightgbm version
import lightgbm
print(lightgbm.__version__)Skrip akan menampilkan versi LightGBM yang diinstal. Versi Anda harus sama atau lebih tinggi. Jika tidak, perbarui LightGBM. Jika Anda memerlukan instruksi khusus untuk lingkungan pengembangan Anda, lihat tutorial: Panduan Instalasi LightGBM .
Pustaka LightGBM memiliki API-nya sendiri, meskipun kami menggunakan metode melalui kelas pembungkus scikit-learn: LGBMRegressor dan LGBMClassifier . Ini akan memungkinkan Anda untuk menerapkan seluruh rangkaian alat dari pustaka pembelajaran mesin scikit-learn untuk persiapan data dan evaluasi model.
Kedua model bekerja dengan cara yang sama dan menggunakan argumen yang sama untuk mempengaruhi bagaimana pohon keputusan dibuat dan ditambahkan ke ansambel. Model tersebut menggunakan keacakan. Ini berarti bahwa setiap kali algoritme berjalan pada data yang sama, model yang dibuat sedikit berbeda.
Saat menggunakan algoritme pembelajaran mesin dengan algoritme pembelajaran stokastik, disarankan untuk mengevaluasinya dengan merata-ratakan performanya selama beberapa proses atau pengulangan validasi silang. Saat menyesuaikan model akhir, mungkin diinginkan untuk meningkatkan jumlah pohon sampai varians model berkurang dengan estimasi berulang, atau untuk melatih beberapa model akhir dan rata-rata prediksi mereka. Mari kita lihat merancang ansambel LightGBM untuk klasifikasi dan regresi.
Ansambel LightGBM untuk klasifikasi
Di bagian ini, kita akan melihat penggunaan LightGBM untuk tugas klasifikasi. Pertama, kita bisa menggunakan fungsi make_classification () untuk membuat masalah klasifikasi biner sintetik dengan 1000 contoh dan 20 fitur masukan. Lihat seluruh contoh di bawah ini.
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# summarize the datasetMenjalankan contoh membuat kumpulan data dan merangkum bentuk komponen input dan output.
(1000, 20) (1000,)Kami kemudian dapat mengevaluasi algoritma LightGBM pada kumpulan data ini. Kami akan mengevaluasi model menggunakan validasi silang k-fold bertingkat berulang dengan tiga pengulangan dan k dari 10. Kami akan melaporkan rata-rata dan deviasi standar dari akurasi model atas semua pengulangan dan lipatan.
# evaluate lightgbm algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))Menjalankan contoh menunjukkan keakuratan mean dan deviasi standar model.
Catatan : Hasil Anda mungkin berbeda karena sifat stokastik dari algoritma atau prosedur estimasi, atau perbedaan dalam ketepatan numerik. Coba contoh beberapa kali dan bandingkan hasil rata-rata.
Dalam hal ini, kita dapat melihat bahwa ensembel LightGBM dengan hyperparameter default mencapai akurasi klasifikasi sekitar 92,5% pada dataset pengujian ini.
Accuracy: 0.925 (0.031)Kami juga dapat menggunakan model LightGBM sebagai model terakhir dan membuat prediksi untuk klasifikasi. Pertama, ensembel LightGBM cocok dengan semua data yang tersedia, dan kedua, Anda dapat memanggil fungsi predict () untuk membuat prediksi pada data baru. Contoh di bawah ini menunjukkan hal ini pada kumpulan data klasifikasi biner kami.
# make predictions using lightgbm for classification
from sklearn.datasets import make_classification
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808]
yhat = model.predict([row])
print('Predicted Class: %d' % yhat[0])Menjalankan contoh melatih model ansambel LightGBM untuk seluruh kumpulan data dan kemudian menggunakannya untuk memprediksi baris data baru, seperti yang akan terjadi jika model digunakan dalam aplikasi.
Predicted Class: 1Sekarang setelah kita terbiasa menggunakan LightGBM untuk klasifikasi, mari kita lihat API regresi.
Ensemble LightGBM untuk Regresi
Di bagian ini, kita akan melihat penggunaan LightGBM untuk masalah regresi. Pertama, kita dapat menggunakan fungsi make_regress ()
untuk membuat masalah regresi sintetik dengan 1000 contoh dan 20 fitur masukan. Lihat seluruh contoh di bawah ini.
# test regression dataset
from sklearn.datasets import make_regression
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# summarize the dataset
print(X.shape, y.shape)Menjalankan contoh membuat set data dan merangkum komponen input dan output.
(1000, 20) (1000,)Kedua, kita dapat mengevaluasi algoritma LightGBM pada dataset ini.
Seperti di bagian terakhir, kita akan mengevaluasi model dengan mengulang k-fold cross-validation dengan tiga ulangan dan k sama dengan 10. Kita akan melaporkan mean absolute error (MAE) model di semua ulangan dan kelompok cross-validation. Library scikit-learn membuat MAE negatif sehingga ia dimaksimalkan daripada diminimalkan. Ini berarti MAE negatif yang besar lebih baik dan model ideal memiliki MAE 0. Contoh lengkap ditampilkan di bawah ini.
# evaluate lightgbm ensemble for regression
from numpy import mean
from numpy import std
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# evaluate the model
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))Menjalankan contoh melaporkan mean dan deviasi standar model.
Catatan : Hasil Anda mungkin berbeda karena sifat stokastik dari algoritme atau prosedur estimasi, atau perbedaan dalam ketepatan numerik. Pertimbangkan menjalankan contoh beberapa kali dan membandingkan hasil rata-rata. Dalam hal ini, kita melihat bahwa ensembel LightGBM dengan hyperparameter default mencapai MAE sekitar 60.
MAE: -60.004 (2.887)Kita juga dapat menggunakan model LightGBM sebagai model terakhir dan membuat prediksi untuk regresi. Pertama, ensembel LightGBM dilatih pada semua data yang tersedia, kemudian fungsi predict () dapat dipanggil untuk memprediksi data baru. Contoh di bawah ini menunjukkan hal ini pada set data regresi kami.
# gradient lightgbm for making predictions for regression
from sklearn.datasets import make_regression
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.20543991,-0.97049844,-0.81403429,-0.23842689,-0.60704084,-0.48541492,0.53113006,2.01834338,-0.90745243,-1.85859731,-1.02334791,-0.6877744,0.60984819,-0.70630121,-1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,-0.11154792]
yhat = model.predict([row])
print('Prediction: %d' % yhat[0]) Menjalankan contoh melatih model ansambel LightGBM di seluruh kumpulan data dan kemudian menggunakannya untuk memprediksi baris data baru, seperti jika menggunakan model dalam aplikasi.
Prediction: 52Sekarang setelah kita terbiasa menggunakan scikit-learn API untuk mengevaluasi dan menerapkan ansambel LightGBM, mari kita lihat penyiapan model.
Hyperparameter LightGBM
Di bagian ini, kita akan melihat lebih dekat beberapa hyperparameter yang penting untuk ansambel LightGBM dan pengaruhnya terhadap kinerja model. LightGBM memiliki banyak hyperparameter untuk dilihat, di sini kita melihat jumlah pohon dan kedalamannya, kecepatan pemelajaran dan jenis peningkatannya. Untuk tip umum tentang mengubah hyperparameter LightGBM, lihat dokumentasi: Tuning LightGBM Parameters .
Memeriksa jumlah pohon
Hyperparameter penting untuk algoritme ansambel LightGBM adalah jumlah pohon keputusan yang digunakan dalam ansambel. Ingatlah bahwa pohon keputusan ditambahkan ke model secara berurutan dalam upaya untuk memperbaiki dan meningkatkan prediksi yang dibuat oleh pohon sebelumnya. Aturannya sering kali berhasil: lebih banyak pohon lebih baik. Jumlah pohon dapat ditentukan dengan menggunakan argumen n_estimators, yang defaultnya adalah 100. Contoh di bawah ini membahas pengaruh jumlah pohon, dari 10 hingga 5000.
# explore lightgbm number of trees effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
trees = [10, 50, 100, 500, 1000, 5000]
for n in trees:
models[str(n)] = LGBMClassifier(n_estimators=n)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Menjalankan contoh terlebih dahulu menampilkan presisi rata-rata untuk setiap jumlah pohon keputusan.
Catatan : Hasil Anda mungkin berbeda karena sifat stokastik dari algoritma atau prosedur estimasi, atau perbedaan dalam ketepatan numerik. Pertimbangkan menjalankan contoh beberapa kali dan membandingkan hasil rata-rata.
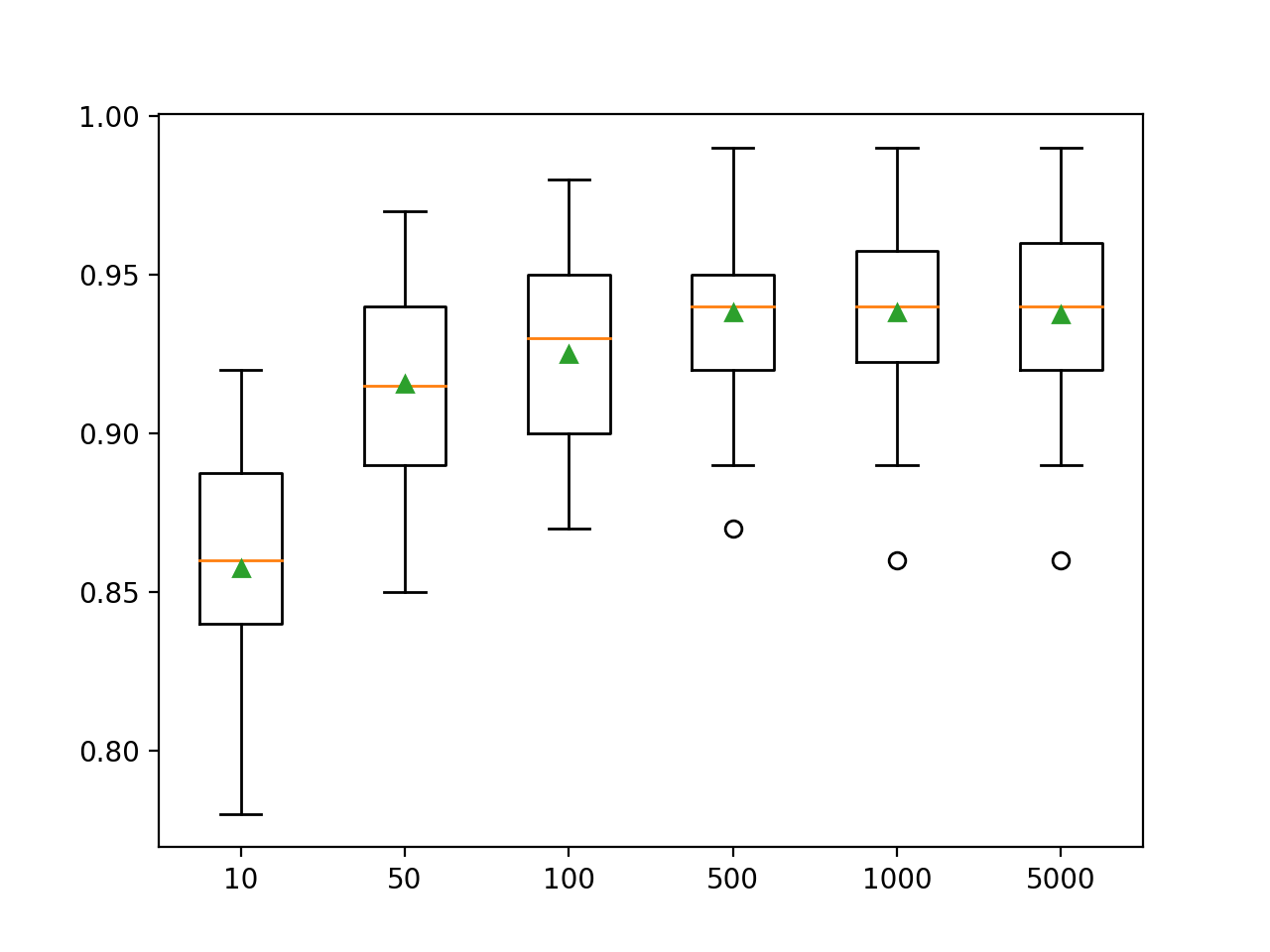
Di sini kita melihat bahwa kinerja meningkat untuk kumpulan data ini menjadi sekitar 500 pohon, setelah itu tampaknya menjadi datar.
>10 0.857 (0.033)
>50 0.916 (0.032)
>100 0.925 (0.031)
>500 0.938 (0.026)
>1000 0.938 (0.028)
>5000 0.937 (0.028)Plot kotak dan kumis dibuat untuk mendistribusikan skor akurasi untuk setiap jumlah pohon yang dikonfigurasi. Ada kecenderungan umum menuju peningkatan kinerja model dan ukuran ansambel.
Memeriksa kedalaman pohon
Mengubah kedalaman setiap pohon yang ditambahkan ke ansambel adalah hyperparameter penting lainnya untuk peningkatan gradien. Kedalaman pohon menentukan seberapa besar spesialisasi setiap pohon dalam set data pelatihan: seberapa umum atau terlatihnya hal itu. Pohon yang tidak boleh terlalu dangkal dan umum (misalnya AdaBoost ) dan tidak terlalu dalam dan terspesialisasi (misalnya agregasi bootstrap ) lebih disukai .
Peningkatan gradien biasanya bekerja dengan baik pada pohon dengan kedalaman sedang, menyeimbangkan pelatihan dan keumuman. Kedalaman pohon dikontrol oleh argumen max_depth, dan defaultnya adalah nilai yang tidak ditentukan, karena mekanisme default untuk mengelola kompleksitas pohon adalah dengan menggunakan node dalam jumlah terbatas.
Ada dua cara utama untuk mengelola kompleksitas pohon: melalui kedalaman pohon maksimum dan jumlah maksimum simpul terminal (daun) pohon. Kami memeriksa jumlah daun di sini, jadi kami perlu menambah jumlah untuk mendukung pohon yang lebih dalam dengan menentukan argumen num_leaves . Di bawah ini kami memeriksa kedalaman pohon dari 1 hingga 10 dan dampaknya terhadap kinerja model.
# explore lightgbm tree depth effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for i in range(1,11):
models[str(i)] = LGBMClassifier(max_depth=i, num_leaves=2**i)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Menjalankan contoh terlebih dahulu menampilkan presisi rata-rata untuk setiap kedalaman pohon yang disesuaikan.
Catatan : Hasil Anda mungkin berbeda karena sifat stokastik dari algoritma atau prosedur estimasi, atau perbedaan dalam ketepatan numerik. Pertimbangkan menjalankan contoh beberapa kali dan membandingkan hasil rata-rata.
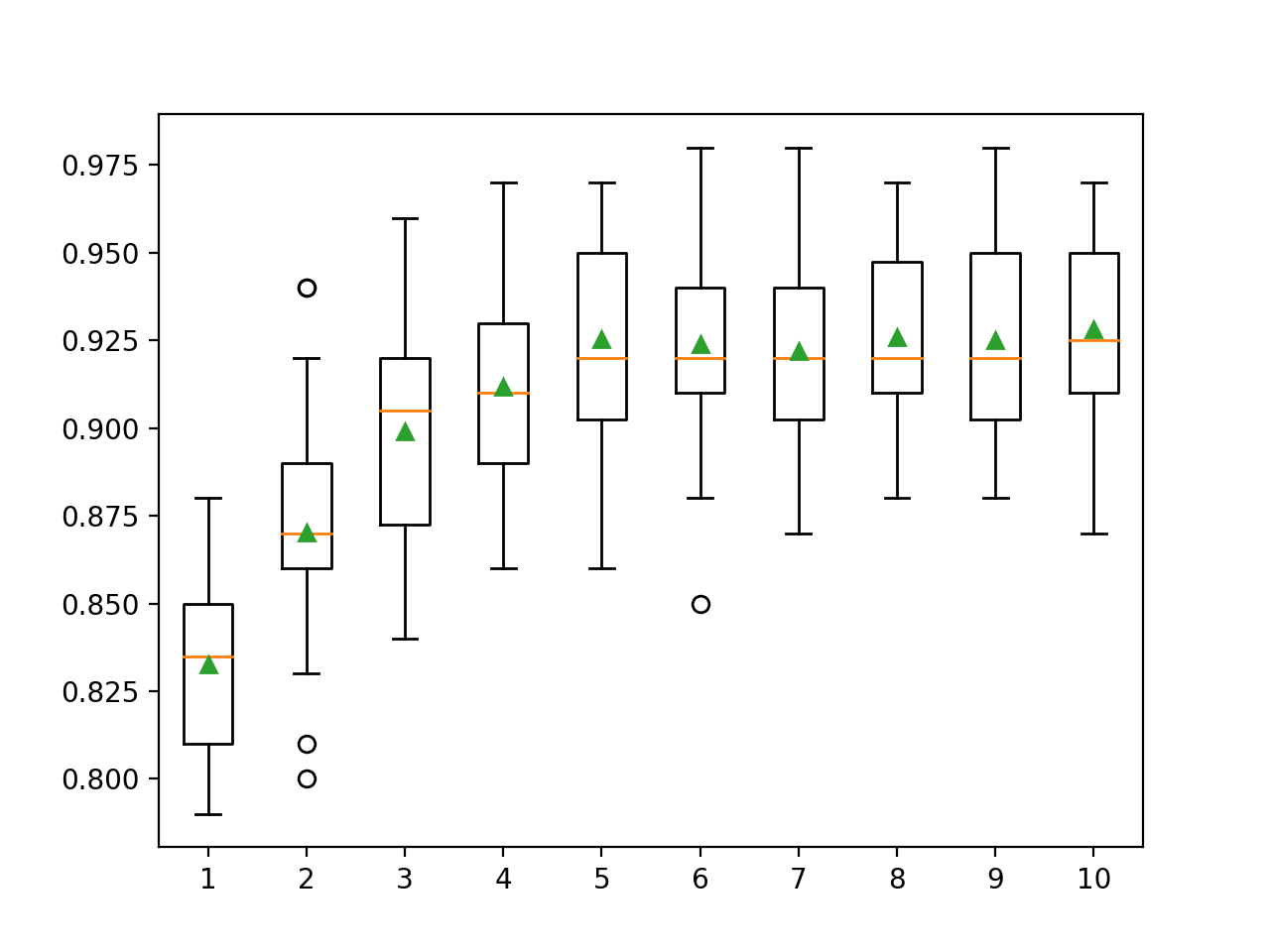
Di sini kita dapat melihat bahwa kinerja meningkat dengan bertambahnya kedalaman pohon, mungkin hingga 10 level. Akan menarik untuk menjelajahi pepohonan yang lebih dalam.
>1 0.833 (0.028)
>2 0.870 (0.033)
>3 0.899 (0.032)
>4 0.912 (0.026)
>5 0.925 (0.031)
>6 0.924 (0.029)
>7 0.922 (0.027)
>8 0.926 (0.027)
>9 0.925 (0.028)
>10 0.928 (0.029)Plot persegi panjang dan kumis dibuat untuk mendistribusikan skor akurasi untuk setiap kedalaman pohon yang dikonfigurasi. Ada kecenderungan umum untuk kinerja model meningkat dengan kedalaman pohon hingga lima tingkat, setelah itu kinerja tetap cukup datar.
Penelitian tingkat pembelajaran
Kecepatan pembelajaran mengontrol sejauh mana setiap model berkontribusi pada prediksi ansambel. Kecepatan yang lebih rendah mungkin membutuhkan lebih banyak pohon keputusan dalam ansambel. Kecepatan pembelajaran dapat dikontrol dengan argumen learning_rate, secara default adalah 0,1. Berikut ini pemeriksaan kecepatan pemelajaran dan membandingkan efek nilai dari 0,0001 hingga 1,0.
# explore lightgbm learning rate effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
rates = [0.0001, 0.001, 0.01, 0.1, 1.0]
for r in rates:
key = '%.4f' % r
models[key] = LGBMClassifier(learning_rate=r)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Menjalankan contoh terlebih dahulu menampilkan akurasi rata-rata untuk setiap kecepatan pemelajaran yang dikonfigurasi.
Catatan : Hasil Anda dapat bervariasi karena sifat stokastik dari algoritme atau prosedur estimasi, atau perbedaan dalam ketepatan numerik. Pertimbangkan menjalankan contoh beberapa kali dan membandingkan hasil rata-rata.
Di sini kita melihat bahwa kecepatan pemelajaran yang lebih tinggi menghasilkan kinerja yang lebih baik pada kumpulan data ini. Kami berharap bahwa menambahkan lebih banyak pohon ke ansambel untuk kecepatan pembelajaran yang lebih rendah akan lebih meningkatkan kinerja.
>0.0001 0.800 (0.038)
>0.0010 0.811 (0.035)
>0.0100 0.859 (0.035)
>0.1000 0.925 (0.031)
>1.0000 0.928 (0.025)Kotak kumis dibuat untuk mendistribusikan skor akurasi untuk setiap kecepatan pembelajaran yang dikonfigurasi. Ada kecenderungan umum untuk performa model meningkat dengan peningkatan kecepatan pemelajaran hingga 1.0.

Meningkatkan jenis penelitian
Keunikan LightGBM adalah ia mendukung sejumlah algoritme penguat yang disebut jenis penguat. Jenis boosting ditentukan menggunakan argumen boosting_type dan menggunakan string untuk menentukan jenisnya. Nilai yang memungkinkan:
- 'gbdt' : Gradient Boosted Decision Tree (GDBT);
- 'dart' : konsep dropout masuk ke MART, kita dapat DART;
- 'goss' : Pengambilan satu arah gradien (GOSS).
Standarnya adalah GDBT, algoritme peningkatan gradien klasik.
DART dijelaskan dalam artikel 2015 berjudul " DART: Dropout memenuhi Beberapa Pohon Regresi Aditif " dan, seperti namanya, menambahkan konsep dropout dari deep learning ke algoritme Multiple Additive Regression Trees (MART), pendahulu untuk pohon keputusan yang meningkatkan gradien.
Algoritma ini dikenal dengan banyak nama, termasuk Gradient TreeBoost, Boosted Trees, dan Multiple Additive Regression Trees and Trees (MART). Kami menggunakan nama terakhir untuk merujuk ke algoritme.
GOSS disajikan dengan pekerjaan pada LightGBM dan perpustakaan lightbgm. Pendekatan ini bertujuan untuk menggunakan hanya contoh yang menghasilkan gradien kesalahan besar untuk memperbarui model dan menghapus contoh yang tersisa.
... Kami mengecualikan sebagian besar contoh data dengan gradien kecil dan hanya menggunakan sisanya untuk memperkirakan peningkatan informasi.
Di bawah LightGBM dilatih tentang kumpulan data klasifikasi sintetis dengan tiga metode peningkatan utama.
# explore lightgbm boosting type effect on performance
from numpy import arange
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
types = ['gbdt', 'dart', 'goss']
for t in types:
models[t] = LGBMClassifier(boosting_type=t)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Menjalankan contoh terlebih dahulu menampilkan akurasi rata-rata untuk setiap jenis peningkatan yang dikonfigurasi.
Catatan : Hasil Anda mungkin berbeda karena sifat stokastik dari algoritma atau prosedur estimasi, atau perbedaan dalam ketepatan numerik. Pertimbangkan menjalankan contoh beberapa kali dan membandingkan hasil rata-rata.
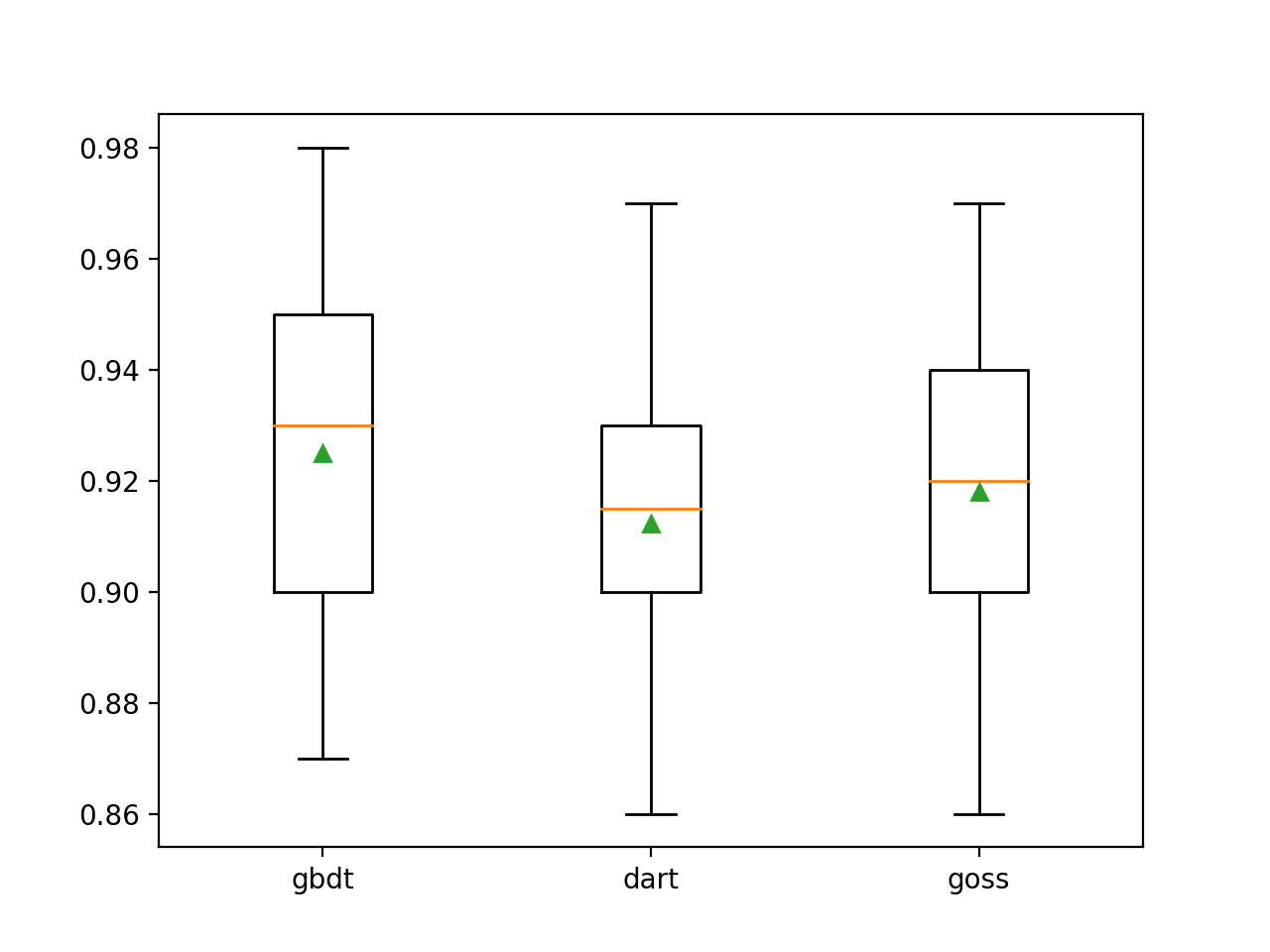
Kita dapat melihat bahwa metode boost default berkinerja lebih baik daripada dua metode evaluasi lainnya.
>gbdt 0.925 (0.031)
>dart 0.912 (0.028)
>goss 0.918 (0.027)Diagram kotak-dan-kumis dibuat untuk mendistribusikan perkiraan akurasi untuk setiap metode amplifikasi yang dikonfigurasi, memungkinkan perbandingan langsung dari metode tersebut.

- Kursus Machine Learning
- Pelatihan profesi Ilmu Data
- Pelatihan Analis Data
- Python untuk Kursus Pengembangan Web
Lebih banyak kursus