1 Apa itu Naskah Voynich?
Naskah Voynich adalah manuskrip misterius (kodeks, manuskrip atau hanya sebuah buku) dalam 240 halaman bagus yang datang kepada kita, mungkin, dari abad ke-15. Naskah itu secara tidak sengaja diperoleh dari seorang antik oleh suami dari penulis karbonarian terkenal Ethel Voynich - Wilfred Voynich - pada tahun 1912 dan segera menjadi milik masyarakat umum.
Bahasa naskah belum ditentukan. Sejumlah peneliti manuskrip menyarankan agar teks manuskrip tersebut dienkripsi. Yang lain yakin bahwa manuskrip itu ditulis dalam bahasa yang tidak ada dalam teks yang kita kenal sekarang. Yang lain menganggap manuskrip Voynich tidak masuk akal (lihat himne modern untuk absurdisme Codex Seraphinianus ).
Sebagai contoh, saya akan memberikan fragmen yang dipindai dari subjek dengan teks dan nimfa:

2 Mengapa manuskrip aneh ini begitu menarik?
Mungkinkah ini pemalsuan yang terlambat? Sepertinya tidak. Tidak seperti Kain Kafan Turin, baik analisis radiokarbon maupun upaya lain untuk membantah keaslian perkamen tersebut belum memberikan jawaban yang jelas. Tetapi Voynich tidak dapat meramalkan analisis isotop pada awal abad ke-20 ...
Tetapi bagaimana jika manuskrip itu adalah sekumpulan huruf yang tidak berarti dari pena seorang biksu yang ceria, seorang bangsawan dalam kesadaran yang berubah? Tidak, tentu tidak. Menampar tombol tanpa berpikir, saya, misalnya, akan menggambarkan derau putih keyboard QWERTY termodulasi yang sudah dikenal semua orang seperti “ asfds dsf". Pemeriksaan grafis menunjukkan bahwa penulis menulis dengan tangan yang kuat simbol-simbol alfabet yang dikenalnya. Plus, korelasi distribusi huruf dan kata dalam teks manuskrip sesuai dengan teks "hidup". Misalnya, dalam sebuah manuskrip, yang secara kondisional dibagi menjadi 6 bagian, terdapat kata - "endemik", sering ditemukan di salah satu bagian, tetapi tidak ada di bagian lain.
Tetapi bagaimana jika manuskrip itu adalah sandi yang kompleks, dan upaya untuk memecahkannya secara teoritis tidak ada artinya? Jika kita percaya pada usia teks yang terhormat, versi enkripsi sangat tidak mungkin. Abad Pertengahan hanya bisa menawarkan sandi pengganti, yang dipatahkan oleh Edgar Allan Poe dengan begitu mudah dan elegan . Sekali lagi, korelasi huruf dan kata dari teks tidak tipikal untuk sebagian besar cipher.
Terlepas dari keberhasilan kolosal dalam menerjemahkan naskah kuno, termasuk dengan penggunaan sumber daya komputasi modern, naskah Voynich masih menentang ahli bahasa profesional berpengalaman atau ilmuwan data muda yang ambisius.
3 Tapi bagaimana jika bahasa naskah itu kita kenal
... tapi ejaannya berbeda? Siapa, misalnya, yang mengenali bahasa Latin dalam teks ini ?

Dan berikut adalah contoh lain - transliterasi teks bahasa Inggris ke bahasa Yunani:
in one of the many little suburbs which cling to the outskirts of london
ιν ονε οφ θε μανυ λιττλε συμπυρμπσ whιχ cλιγγ το θε ουτσκιρτσ οφ λονδονLibrary Transliterasi Python . NB: ini bukan lagi sandi pengganti - beberapa kombinasi huruf banyak ditransmisikan dalam satu huruf dan sebaliknya.
Saya akan mencoba untuk mengidentifikasi (mengklasifikasikan) bahasa manuskrip, atau menemukan kerabat terdekatnya dari bahasa yang diketahui, menyoroti fitur karakteristik dan melatih model di atasnya:
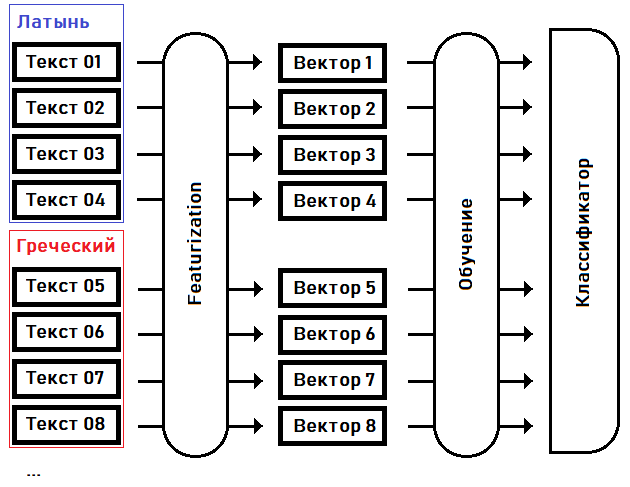
Pada tahap pertama - fiturisasi- kita mengubah teks menjadi vektor fitur: array bilangan real berukuran tetap, di mana setiap dimensi vektor bertanggung jawab atas fitur khusus (fitur) teks sumbernya sendiri. Misalnya, mari kita sepakati dalam dimensi ke-15 dari vektor untuk mempertahankan frekuensi kata yang paling umum dalam teks, dalam dimensi ke-16 - kata terpopuler kedua ... dalam dimensi ke-N - panjang terpanjang dari urutan kata berulang yang sama, dll.
Pada langkah kedua - pelatihan - kami memilih koefisien pengklasifikasi berdasarkan pengetahuan sebelumnya tentang bahasa masing-masing teks.
Setelah pengklasifikasi dilatih, kita dapat menggunakan model ini untuk menentukan bahasa teks yang tidak disertakan dalam sampel pelatihan. Misalnya, untuk teks manuskrip Voynich.
4 Gambarannya sangat sederhana - apa tujuannya?
Bagian yang sulit adalah bagaimana tepatnya mengubah file teks menjadi vektor. Memisahkan gandum dari sekam dan hanya menyisakan ciri-ciri yang menjadi ciri khas bahasa secara keseluruhan, dan bukan setiap teks spesifik.
Jika, untuk menyederhanakan, mengubah teks sumber menjadi pengkodean (yaitu angka), dan "memasukkan" data ini seperti yang ada pada salah satu dari banyak model jaringan saraf, hasilnya mungkin tidak akan menyenangkan kami. Kemungkinan besar, model yang dilatih pada data semacam itu akan dikaitkan dengan alfabet dan berdasarkan simbol yang, pertama-tama, akan mencoba menentukan bahasa dari teks yang tidak dikenal.
Tetapi alfabet manuskrip "tidak memiliki analog." Selain itu, kami tidak dapat sepenuhnya mengandalkan pola dalam distribusi surat. Secara teoritis, dimungkinkan juga untuk mentransfer fonetik satu bahasa dengan aturan bahasa lain ( bahasanya Elvish - dan rune adalah Mordor).
Penulis yang licik tidak menggunakan tanda baca atau angka seperti yang kita kenal. Semua teks dapat dianggap sebagai aliran kata, dibagi menjadi paragraf. Bahkan tidak ada kepastian tentang di mana satu kalimat berakhir dan kalimat lainnya dimulai.
Karenanya, kami akan naik ke level yang lebih tinggi dalam kaitannya dengan huruf dan akan mengandalkan kata-kata. Kami akan menyusun kamus berdasarkan teks manuskrip dan melacak pola yang sudah ada di tingkat kata.
5 Teks asli dari naskah
Tentu saja, Anda tidak perlu menyandikan karakter rumit dari manuskrip Voynich ke dalam padanan Unicode dan sebaliknya - pekerjaan ini telah dilakukan untuk kami, misalnya, di sini . Dengan opsi default, saya mendapatkan persamaan berikut dengan baris pertama manuskrip:
fachys.ykal.ar.ataiin.shol.shory.cth!res.y.kor.sholdy!-Titik dan tanda seru (serta sejumlah simbol alfabet EVA lainnya ) hanyalah pemisah, yang untuk keperluan kita dapat diganti dengan spasi. Tanda tanya dan tanda bintang adalah kata / huruf yang tidak dikenal.
Untuk verifikasi, mari kita gantikan teks di sini dan dapatkan fragmen dari manuskripnya:
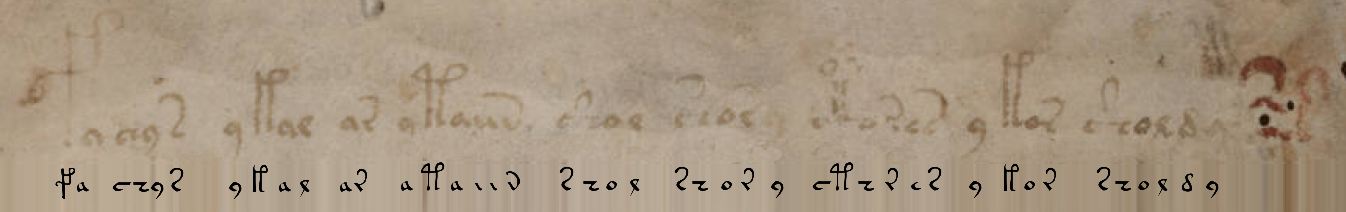
6 Program - pengklasifikasi teks (Python)
Berikut ini tautan ke repositori kode dengan petunjuk README minimum yang Anda perlukan untuk menguji kode dalam tindakan.
Saya mengumpulkan 20+ teks dalam bahasa Latin, Rusia, Inggris, Polandia, dan Yunani, mencoba menjaga volume setiap teks dalam ± 35.000 kata (volume manuskrip Voynich).
Saya mencoba memilih kencan dekat dalam teks, dalam satu ejaan - misalnya, dalam teks bahasa Rusia saya menghindari huruf Ѣ, dan variasi penulisan huruf Yunani dengan diakritik berbeda mengarah ke penyebut yang sama. Saya juga menghapus nomor, spesial dari teks. karakter, spasi ekstra, mengubah huruf menjadi satu huruf.
Langkah selanjutnya adalah membuat "kamus" yang berisi informasi seperti:
- frekuensi penggunaan setiap kata dalam teks (teks),
- "Akar" dari sebuah kata - atau lebih tepatnya, bagian umum yang tidak dapat diubah untuk sekumpulan kata,
- umum "awalan" dan "akhiran" - atau lebih tepatnya, awal dan akhir kata, bersama dengan "akar" yang menyusun kata sebenarnya,
- urutan umum dari 2 dan 3 kata yang identik dan frekuensi kemunculannya.
Saya mengambil "akar" kata dalam tanda kutip - algoritma sederhana (dan terkadang saya sendiri) tidak dapat menentukan, misalnya, apa akar dari kata dukungan? Dengan menjadi ka? Di bawah tarif ?
Secara umum, kosakata ini adalah data setengah jadi untuk membuat vektor fitur. Mengapa saya memilih tahap ini - menyusun dan menyimpan kamus untuk setiap teks dan untuk satu set teks untuk masing-masing bahasa? Faktanya adalah bahwa kamus semacam itu membutuhkan waktu lama untuk dibuat, sekitar setengah menit untuk setiap file teks. Dan saya sudah memiliki lebih dari 120 file teks.
7 Keistimewaan
Mendapatkan vektor fitur hanyalah tahap awal untuk keajaiban lebih lanjut dari pengklasifikasi. Sebagai orang aneh OOP, tentu saja, saya membuat kelas BaseFeaturizer abstrak untuk logika hulu, agar tidak melanggar prinsip inversi ketergantungan . Kelas ini diwariskan kepada turunan agar dapat mengubah satu atau banyak file teks sekaligus menjadi vektor numerik.
Selain itu, kelas pewaris harus memberi setiap fitur individu (koordinat-i vektor fitur) nama. Ini akan berguna jika kita memutuskan untuk memvisualisasikan logika mesin klasifikasi. Misalnya, dimensi ke-0 dari vektor akan ditandai sebagai CRw1 - autokorelasi frekuensi penggunaan kata-kata yang diambil dari teks pada posisi yang berdekatan (dengan jeda 1).
Dari kelas BaseFeaturizer, saya mewarisi kelas tersebutWordMorphFeaturizer , logikanya didasarkan pada frekuensi penggunaan kata di seluruh teks dan dalam jendela geser 12 kata.
Aspek penting adalah bahwa kode pewaris tertentu dari BaseFeaturizer, selain teks itu sendiri, juga membutuhkan kamus yang disiapkan berdasarkan mereka (kelas CorpusFeatures ), yang kemungkinan besar sudah di-cache di disk pada saat memulai pelatihan dan menguji model.
8 Klasifikasi
Kelas abstrak berikutnya adalah BaseClassifier . Objek ini dapat dilatih dan kemudian mengklasifikasikan teks berdasarkan vektor fiturnya.
Untuk implementasinya (kelas RandomForestLangClassifier ), saya memilih algoritma Random Forest Classifier dari perpustakaan sklearn . Mengapa pengklasifikasi khusus ini?
- Random Forest Classifier cocok dengan saya dengan parameter defaultnya,
- itu tidak membutuhkan normalisasi data masukan,
- menawarkan visualisasi yang sederhana dan intuitif dari algoritme pengambilan keputusan.
Karena, menurut pendapat saya, Pengklasifikasi Hutan Acak mengatasi tugasnya dengan baik, saya belum menulis implementasi lainnya.
9 Pelatihan dan pengujian
80% file - fragmen besar dari karya Byron, Aksakov, Apuleius, Pausanias, dan penulis lain, yang teksnya dapat saya temukan dalam format txt - dipilih secara acak untuk melatih pengklasifikasi. 20% sisanya (28 file) ditentukan untuk pengujian di luar sampel.
Saat saya menguji pengklasifikasi pada ~ 30 teks bahasa Inggris dan 20 teks Rusia, pengklasifikasi memberikan persentase kesalahan yang besar: di hampir setengah kasus, bahasa teks ditentukan dengan tidak benar. Tetapi ketika saya memulai ~ 120 file teks dalam 5 bahasa (Rusia, Inggris, Latin, Yunani Kuno, dan Polandia) pengklasifikasi berhenti membuat kesalahan dan mulai mengenali dengan benar bahasa dari 27 - 28 file dari 28 kasus uji.
Kemudian saya sedikit memperumit masalah: Saya mentranskripsikan novel Irlandia abad ke-19 "Rachel Grey" ke dalam bahasa Yunani dan menyerahkannya kepada pengklasifikasi terlatih. Bahasa teks dalam transliterasi kembali didefinisikan dengan benar.
10 Algoritma klasifikasi jelas
Beginilah tampilan salah satu dari 100 pohon di Random Forest Classifier yang terlatih (untuk membuat gambar lebih mudah dibaca, saya memotong 3 simpul dari sub pohon kanan):
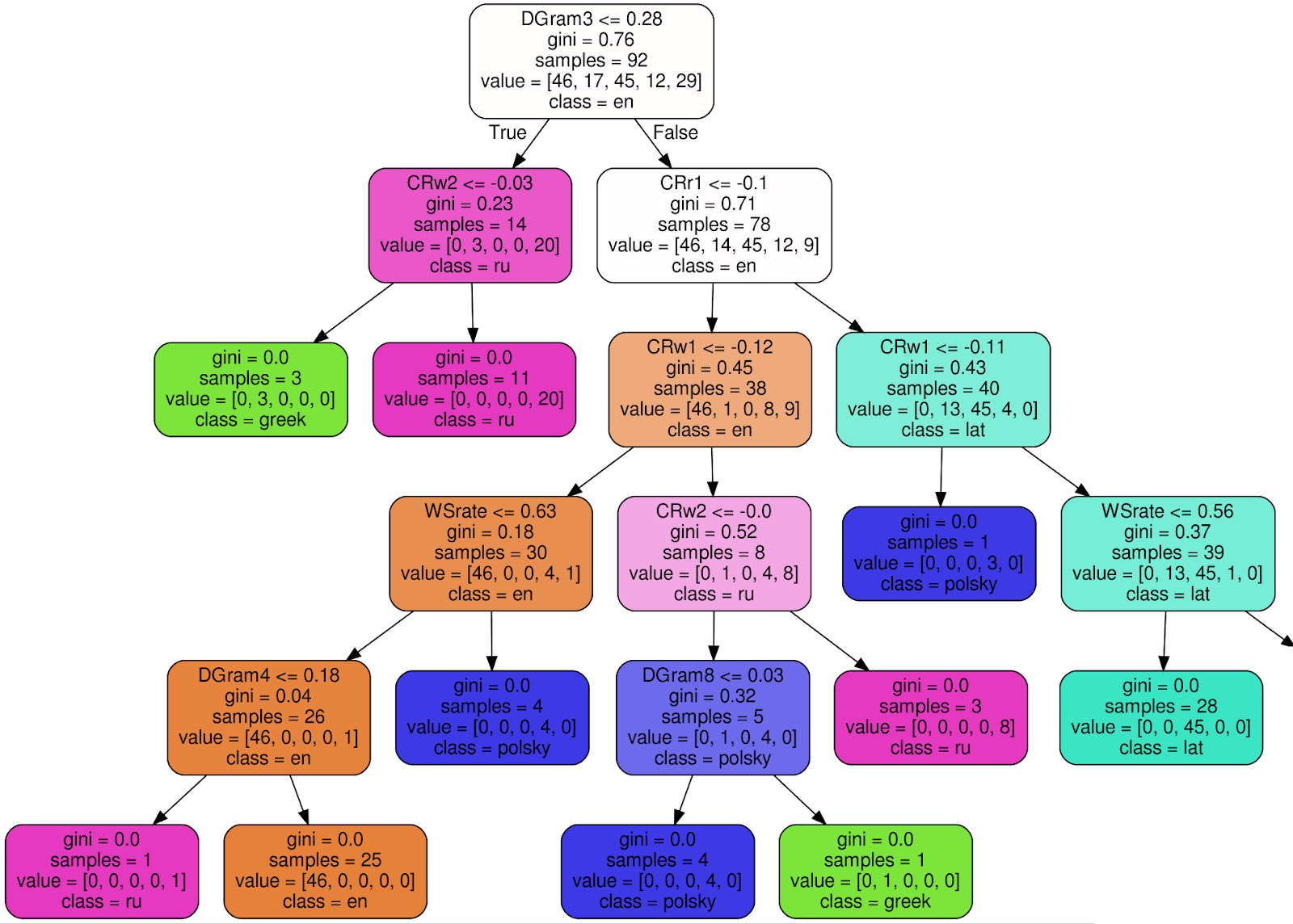
Dengan menggunakan simpul akar sebagai contoh , saya akan menjelaskan arti dari setiap tanda tangan:
- DGram3 <= 0,28 - kriteria klasifikasi. Dalam hal ini, DGram3 adalah pengukuran khusus dari vektor fitur yang dinamai oleh kelas WordMorphFeaturizer, yaitu frekuensi kata paling umum ketiga dalam jendela geser 12 kata,
- gini = 0.76 — , Gini impurity, , , . , , - . . , gini, , 0 ( ),
- samples = 92 — , ,
- value = [46, 17, 45, 12, 29] — , (46 , 17 , 45 ..),
- class = en ( ) — .
Jika kriteria (DGram3 <= 0.28 untuk simpul akar) terpenuhi, pergi ke subtree kiri, jika tidak - ke kanan. Dalam setiap lembar, semua teks harus ditetapkan ke satu kelas (bahasa) dan kriteria ketidakpastian Gini ≡ 0.
Keputusan akhir dibuat oleh ansambel yang terdiri dari 100 pohon serupa yang dibangun selama pelatihan pengklasifikasi.
11 Dan bagaimana program tersebut mendefinisikan bahasa manuskrip?
Latin , perkiraan probabilitas 0,59. Dan, tentu saja, ini belum menjadi solusi untuk masalah abad ini.
Korespondensi satu-ke-satu antara kamus manuskrip dan bahasa Latin tidaklah mudah - jika bukan tidak mungkin. Misalnya, berikut sepuluh kata yang paling sering digunakan: manuskrip Voynich, bahasa Latin,

Yunani Kuno , dan Rusia: Tanda
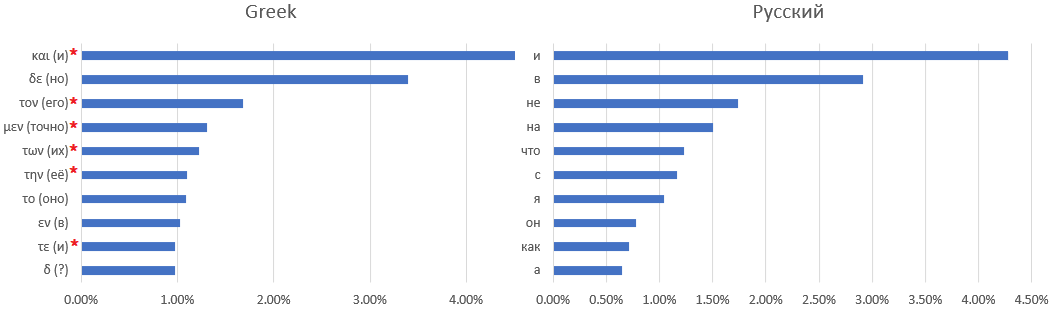
bintang menandai kata-kata yang sulit ditemukan padanannya dalam bahasa Rusia - misalnya, artikel atau preposisi yang mengubah arti bergantung pada konteksnya.
Pertandingan yang jelas seperti
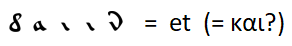
dengan perpanjangan aturan untuk mengganti huruf dengan kata-kata lain yang sering digunakan, saya tidak dapat menemukan. Anda hanya dapat membuat asumsi - misalnya, kata yang paling umum adalah kata sambung "dan" - seperti dalam semua bahasa lain yang dianggap kecuali bahasa Inggris, di mana kata sambung "dan" didorong ke posisi kedua oleh kata sandang tertentu "the".
Apa berikutnya?
Pertama, ada baiknya mencoba melengkapi sampel bahasa dengan teks dalam bahasa Prancis, Spanyol, ..., Timur Tengah modern, jika memungkinkan - Inggris Kuno, bahasa Prancis (sebelum abad ke-15), dan lainnya. Sekalipun tidak satupun dari bahasa-bahasa ini yang menjadi bahasa naskah, akurasi definisi bahasa yang dikenal akan tetap meningkat, dan padanan yang lebih dekat mungkin akan dipilih ke bahasa naskah.
Tantangan yang lebih kreatif adalah mencoba mendefinisikan bagian pidato untuk setiap kata. Untuk sejumlah bahasa (tentu saja, pertama-tama - Inggris) tokenizers PoS (Part of Speech) sebagai bagian dari paket yang tersedia untuk diunduh, melakukan tugas ini dengan baik. Tetapi bagaimana menentukan peran kata-kata dalam bahasa yang tidak dikenal?
Masalah serupa dipecahkan oleh ahli bahasa Soviet B.V. Sukhotin - misalnya, dia menggambarkan algoritme:
- pemisahan karakter dari alfabet yang tidak diketahui menjadi vokal dan konsonan - sayangnya, tidak 100% dapat diandalkan, terutama untuk bahasa dengan fonetik non-sepele, seperti Prancis,
- pemilihan morfem dalam teks tanpa spasi.
Untuk tokenisasi PoS, kita bisa mulai dari frekuensi penggunaan kata-kata, kejadian dalam kombinasi 2/3 kata, distribusi kata-kata di atas bagian teks: penyatuan dan partikel harus didistribusikan lebih merata daripada kata benda.
literatur
Saya tidak akan meninggalkan tautan ke buku dan tutorial di NLP di sini - itu cukup di internet. Sebagai gantinya, saya akan membuat daftar karya seni yang menjadi penemuan hebat bagi saya sebagai seorang anak, di mana para pahlawan harus bekerja keras untuk mengungkap teks yang disandikan:
- E. A. Poe: The Golden Beetle adalah karya klasik abadi
- V. Babenko: "Meeting" adalah kisah detektif yang terkenal melintir dan agak visioner di akhir tahun 80-an,
- K. Kirita: “Ksatria dari Jalan Chereshnevaya, atau Kastil Gadis Berkulit Putih” adalah novel remaja yang menarik, ditulis tanpa diskon untuk usia pembaca.