
Melihat ke belakang, saya dapat mengatakan bahwa semua tindakan penempatan sejak saat itu adalah gerakan paksa. Dan baru sekarang untuk tahun kelima belas kita dapat mengkonfigurasi infrastruktur yang kita butuhkan.
Sekarang kita berdiri di 4 pusat data yang berbeda secara fisik, dihubungkan oleh cincin optik gelap, menempatkan 5 kumpulan sumber daya independen di sana. Dan kebetulan bahwa jika meteorit jatuh ke salah satu persimpangan, maka 3 dari kolam ini akan segera jatuh, dan dua sisanya tidak akan menarik beban. Karena itu, kami melakukan penyeimbangan ulang total untuk memulihkan ketertiban.
Pusat data pertama
Awalnya tidak ada pusat data sama sekali. Ada seorang sistemis tua di asrama Universitas Negeri Moskow. Kemudian, hampir seketika - hosting virtual dari Masterhost (mereka masih hidup, setan). Lalu lintas ke situs dengan jadwal kereta api berlipat ganda setiap 4 minggu, jadi kami segera beralih ke KVM-VPS, itu terjadi sekitar tahun 2005. Di beberapa titik, kami mengalami pembatasan lalu lintas, karena itu perlu untuk menjaga keseimbangan antara masuk dan keluar. Kami memiliki dua instalasi, dan kami menggeser beberapa file yang berat dari satu ke yang lain setiap malam untuk mempertahankan proporsi yang diperlukan.
Pada bulan Maret 2009 hanya ada VPS. Ini adalah hal yang baik, kami memutuskan untuk beralih ke colocation. Kami membeli beberapa server besi fisik (salah satunya adalah dari dinding, tubuh yang kami simpan sebagai memori). Kami menempatkan Fiord di pusat data (dan mereka masih hidup, iblis). Mengapa? Karena tidak jauh dari kantor saat itu, seorang teman merekomendasikan, dan saya harus bangun dengan cepat. Plus itu relatif murah.
Pembagian beban antara server sederhana: masing-masing memiliki back-end, MySQL dengan replikasi master-slave, bagian depan berada di tempat yang sama dengan replika. Baik itu hampir tanpa pembagian berdasarkan jenis beban. Tak lama kemudian mereka juga mulai ketinggalan, membeli yang ketiga.
Sekitar 1 Oktober 2009, kami menyadari bahwa sudah ada lebih banyak server, tetapi kami akan berbaring untuk tahun baru... Prakiraan lalu lintas menunjukkan bahwa kapasitas yang mungkin akan tumpang tindih dengan margin. Dan kami berlari ke dalam kinerja database. Ada satu setengah bulan untuk dipersiapkan sebelum pertumbuhan lalu lintas. Ini adalah saat optimasi pertama. Kami membeli beberapa server murni di bawah basis data. Mereka fokus pada disk cepat dengan kecepatan rotasi 15 krpm (saya tidak ingat alasan pasti mengapa kami tidak menggunakan SSD, tetapi kemungkinan besar mereka memiliki batas rendah pada jumlah operasi penulisan, dan pada saat yang sama biayanya seperti pesawat terbang). Kami membagi bagian depan, belakang, basis data, mengubah nginx, pengaturan MySQL, melakukan reseksi untuk mengoptimalkan kueri SQL. Selamat

Sekarang kita berada dalam sepasang pusat data Tier-III dan di Tier-II oleh UI (dengan ayunan di T3, tetapi tanpa sertifikat). Tapi Fiord bahkan tidak pernah T-II. Mereka memiliki masalah dengan kemampuan bertahan hidup, ada situasi dari kategori "semua kabel listrik berada dalam satu kolektor, dan ada api, dan generator mengemudi selama tiga jam." Secara umum, kami memutuskan untuk pindah.
Pilih pusat data lain, Caravan. Tantangan: bagaimana cara memindahkan server tanpa downtime? Kami memutuskan untuk tinggal di dua pusat data untuk sementara waktu. Manfaat lalu lintas di dalam sistem pada waktu itu tidak sebanyak seperti sekarang, memungkinkan untuk mengarahkan lalu lintas VPN antar lokasi untuk beberapa waktu (terutama di luar musim). Lalu lintas seimbang. Kami secara bertahap meningkatkan porsi Caravan, setelah beberapa saat kami benar-benar pindah ke sana. Dan sekarang kita memiliki satu pusat data yang tersisa. Dan kami membutuhkan dua, kami sudah memahami ini, berkat kegagalan di Fiord. Melihat kembali ke masa itu, saya dapat mengatakan bahwa TIER III juga bukan obat mujarab, tingkat kesintasan 99,95, tetapi ketersediaannya berbeda. Jadi satu pusat data untuk ketersediaan 99,95 dan di atas jelas tidak cukup. Stordata
terpilih kedua, dan sudah ada kemungkinan tautan optik dengan situs Caravan. Kami berhasil meregangkan pembuluh darah pertama. Segera setelah mereka mulai memuat pusat data baru, Caravan mengumumkan bahwa mereka mendapatkan pantat mereka kacau. Mereka harus meninggalkan situs itu karena bangunan itu sedang dihancurkan. Sudah. Mengherankan! Ada situs baru, mereka mengusulkan untuk memadamkan semuanya, untuk mengangkat rak dengan peralatan dengan crane (maka kita sudah memiliki 2,5 rak besi), menerjemahkan, menyalakannya, dan itu akan bekerja ... 4 jam untuk semuanya ... dongeng ... Aku diam bahwa kita bahkan memiliki satu jam downtime tidak cocok, tapi di sini ceritanya akan berlarut-larut setidaknya selama sehari. Dan semua ini disajikan dalam semangat "Semuanya hilang, plester dihapus, klien pergi!" Pada 29 September, telepon pertama, dan pada 10 Oktober, mereka ingin mengambil semuanya dan menerima. Selama 3-5 hari kami harus mengembangkan rencana bergerak, dan dalam 3 tahap,mematikan 1/3 peralatan sekaligus dengan layanan penuh dan uptime, mengangkut mobil ke Stordata. Akibatnya, waktu henti adalah 15 menit dalam satu bukan layanan yang paling kritis.
Jadi sekali lagi kami dibiarkan dengan satu pusat data.
Pada saat ini, kami lelah bergaul dengan server di bawah lengan dan bermain penggerak. Ditambah lelah berurusan dengan perangkat keras itu sendiri di pusat data. Mereka mulai melihat ke arah awan publik.
Dari 2 hingga 5 (hampir) pusat data
Mulai mencari opsi dengan cloud. Kami pergi ke Krok, mencobanya, mengujinya, menyetujui persyaratan. Kami masuk ke cloud, yang ada di pusat data Compressor. Mereka membuat cincin optik gelap antara Stordata, Compressor dan kantor. Di mana-mana uplink sendiri dan dua lengan optik. Memotong sinar apa pun tidak akan merusak jaringan. Hilangnya uplink tidak merusak jaringan. Mendapat status LIR, memiliki subnet sendiri, pengumuman BGP, redundansi jaringan, kecantikan. Saya tidak akan menjelaskan bagaimana mereka pergi ke cloud dari sudut pandang jaringan, tetapi ada nuansa.
Jadi kami memiliki 2 pusat data.
Krok juga memiliki pusat data di Volochaevskaya, mereka memperluas cloud mereka di sana, dan menawarkan untuk mentransfer sebagian sumber daya kami di sana. Tetapi mengingat kisah Caravan, yang, pada kenyataannya, tidak pernah pulih setelah penghancuran pusat data, saya ingin mengambil sumber daya cloud dari penyedia yang berbeda untuk mengurangi risiko bahwa perusahaan akan berhenti ada (negara sedemikian rupa sehingga risiko seperti itu tidak dapat diabaikan). Karena itu, mereka tidak terlibat dengan Volochaevskaya pada waktu itu. Nah, vendor kedua juga melakukan sihir dengan harga. Karena ketika Anda dapat mengambil dan meninggalkan fleksibel, itu memberi Anda daya tawar yang kuat pada harga.
Kami melihat berbagai opsi, tetapi pilihan ada di #CloudMTS. Ada beberapa alasan untuk ini: cloud terbukti bagus dalam pengujian, orang-orang juga tahu cara bekerja dengan jaringan (setelah semua operator telekomunikasi), dan kebijakan pemasaran yang sangat agresif untuk menangkap pasar, akibatnya, harga yang menarik.
Total 3 pusat data.
Setelah itu, kami menghubungkan Volochaevskaya juga - kami membutuhkan sumber daya tambahan, tetapi Kompresor sudah agak sempit. Secara umum, kami mendistribusikan kembali beban antara tiga awan dan peralatan kami di Stordat.
4 pusat data. Dan sudah dalam hal vitalitas di mana-mana T3. Tidak semua orang tampaknya memiliki sertifikat, tetapi saya tidak akan mengatakannya dengan pasti.
MTS memiliki nuansa. Hanya MGTS yang bisa mencapai mil terakhir. Pada saat yang sama, tidak mungkin untuk menarik optik gelap MGTS sepenuhnya dari pusat data ke pusat data (untuk waktu yang lama, itu mahal, dan jika saya tidak bingung, mereka tidak menyediakan layanan seperti itu). Saya harus melakukannya dengan sambungan, mengeluarkan dua sinar dari pusat data ke sumur terdekat, di mana penyedia optik gelap kami Mastertel berada. Mereka memiliki jaringan optik yang luas di seluruh kota, dan, jika ada, mereka hanya mengelas rute yang diinginkan dan memberi Anda tempat tinggal. Sementara itu, Piala Dunia datang ke kota, tanpa diduga, seperti salju di musim dingin, dan akses ke sumur-sumur di Moskow ditutup. Kami menunggu keajaiban ini berakhir, dan kami dapat membuang tautan kami. Tampaknya perlu meninggalkan pusat data MTS dengan optik di tangan, bersiul untuk sampai ke lubang yang diinginkan dan menurunkannya di sana. Bersyarat. Kami melakukannya selama tiga setengah bulan. Lebih tepatnya, balok pertama dibuat agak cepat,pada awal Agustus (saya ingat bahwa Piala Dunia berakhir 15 Juli). Tapi saya harus bermain-main dengan bahu kedua - opsi pertama berarti bahwa perlu untuk menggali jalan raya Kashirskoe, di mana jalan itu diblokir selama seminggu (selama rekonstruksi beberapa terowongan diblokir, di mana komunikasi berada, perlu untuk menggali itu). Untungnya, kami menemukan alternatif: rute lain, geo-independen yang sama. Ternyata dua urat nadi dari pusat data ini ke titik yang berbeda dari kehadiran kami. Cincin optik telah berubah menjadi cincin dengan pegangan.Ternyata dua urat nadi dari pusat data ini ke titik yang berbeda dari kehadiran kami. Cincin optik telah berubah menjadi cincin dengan pegangan.Ternyata dua urat nadi dari pusat data ini ke titik yang berbeda dari kehadiran kami. Cincin optik telah berubah menjadi cincin dengan pegangan.
Berjalan sedikit di depan, saya akan mengatakan bahwa mereka tetap menaruhnya kepada kami. Untungnya, pada awal operasi, ketika tidak banyak yang ditransfer. Kebakaran terjadi di satu sumur, dan sementara installer bersumpah dalam busa, di sumur kedua seseorang menarik konektor untuk melihat (entah bagaimana itu dari desain baru, saya bertanya-tanya). Secara matematis, kemungkinan kegagalan simultan dapat diabaikan. Kami praktis menangkapnya. Sebenarnya, kami beruntung di Fjord - makanan utama dipotong di sana, dan alih-alih menyalakannya kembali, seseorang mencampur saklar dan mematikan jalur cadangan.
Tidak hanya persyaratan teknis untuk mendistribusikan beban antar lokasi: tidak ada keajaiban, dan kebijakan pemasaran yang agresif dengan harga bagus menyiratkan tingkat pertumbuhan tertentu dalam konsumsi sumber daya. Jadi kami selalu mengingat berapa persen sumber daya yang harus dikirim ke MTS. Kami mendistribusikan ulang semua yang lainnya di antara pusat data lainnya secara lebih merata.
Sekali lagi besi Anda
Pengalaman menggunakan cloud publik telah menunjukkan kepada kita bahwa nyaman untuk menggunakannya ketika Anda perlu menambahkan sumber daya dengan cepat, untuk eksperimen, untuk pilot, dll. Saat digunakan di bawah beban konstan, ternyata lebih mahal daripada memuntir setrika Anda. Tapi kami tidak bisa lagi meninggalkan gagasan tentang kontainer, migrasi mesin virtual tanpa batas dalam sebuah cluster, dll. Kami menulis otomatisasi untuk memadamkan beberapa mobil di malam hari, tetapi ekonomi masih belum berhasil. Kami tidak memiliki kompetensi yang cukup untuk mendukung cloud pribadi, kami harus mengembangkannya.
Kami mencari solusi yang memungkinkan Anda mendapatkan cloud di perangkat keras dengan relatif mudah. Pada saat itu, kami tidak pernah bekerja dengan server Cisco, hanya dengan tumpukan jaringan, ini adalah risiko. Di Dells, ini adalah besi sederhana yang terkenal, dapat diandalkan sebagai senapan serbu Kalashnikov. Kami sudah memiliki ini selama bertahun-tahun, dan masih ada di suatu tempat. Tetapi ide di balik Hyperflex adalah bahwa ia mendukung hiper-konvergensi solusi akhir di luar kotak. Dan di Della semuanya hidup di router biasa, dan ada nuansa. Secara khusus, kinerja sebenarnya tidak sekeren pada presentasi karena overhead. Dalam beberapa hal, mereka dapat dikonfigurasi dengan benar dan akan menjadi hebat, tetapi kami memutuskan bahwa ini bukan urusan kami, dan biarkan Dell mempersiapkan mereka yang menemukan panggilan dalam hal ini. Sebagai hasilnya, kami memilih Cisco Hyperflex. Opsi ini menang secara agregat sebagai yang paling menarik: lebih sedikit wasir dalam pengaturan dan operasi,dan selama tes semuanya baik-baik saja. Pada musim panas 2019, kami meluncurkan cluster ke pertempuran. Kami memiliki rak setengah kosong di Kompresor, sebagian besar hanya ditempati dengan peralatan jaringan, dan mereka ditempatkan di sana. Jadi, kami mendapat "pusat data" kelima - secara fisik, empat, tetapi kumpulan sumber daya ternyata lima.
Mereka mengambil, menghitung volume beban konstan dan volume variabel. Mereka mengubah konstanta menjadi beban pada besi mereka. Tetapi agar pada tingkat peralatan itu memberikan keuntungan cloud dalam hal toleransi kesalahan dan redundansi.
Periode pengembalian proyek besi adalah pada harga rata-rata awan kami untuk tahun ini.
Kamu di sini
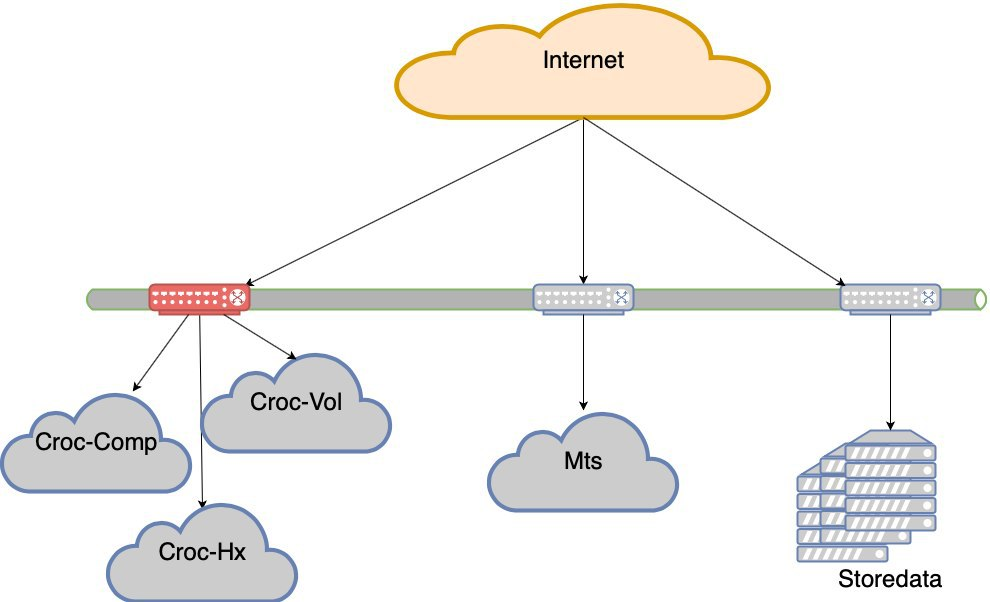
Pada saat ini, kami mengakhiri gerakan paksa. Seperti yang Anda lihat, kami tidak memiliki banyak pilihan ekonomi, dan kami terus-menerus memuat apa yang kami perjuangkan karena suatu alasan. Ini menyebabkan situasi yang aneh bahwa bebannya tidak merata. Kegagalan segmen mana pun (dan segmen dengan pusat data Croc dipegang oleh dua Nexus dalam bottleneck) adalah hilangnya pengalaman pengguna. Artinya, situs akan dilestarikan, tetapi akan ada kesulitan yang jelas dengan aksesibilitas.
Ada kegagalan di MTS dengan seluruh pusat data. Ada dua lagi di yang lain. Dari waktu ke waktu, awan jatuh, atau pengontrol cloud, atau beberapa masalah jaringan yang kompleks muncul. Singkatnya, kami kehilangan pusat data dari waktu ke waktu. Ya, singkat, tetapi masih tidak menyenangkan. Pada titik tertentu, mereka menerima begitu saja bahwa pusat data jatuh.
Kami memutuskan untuk mencari toleransi kesalahan tingkat pusat data.
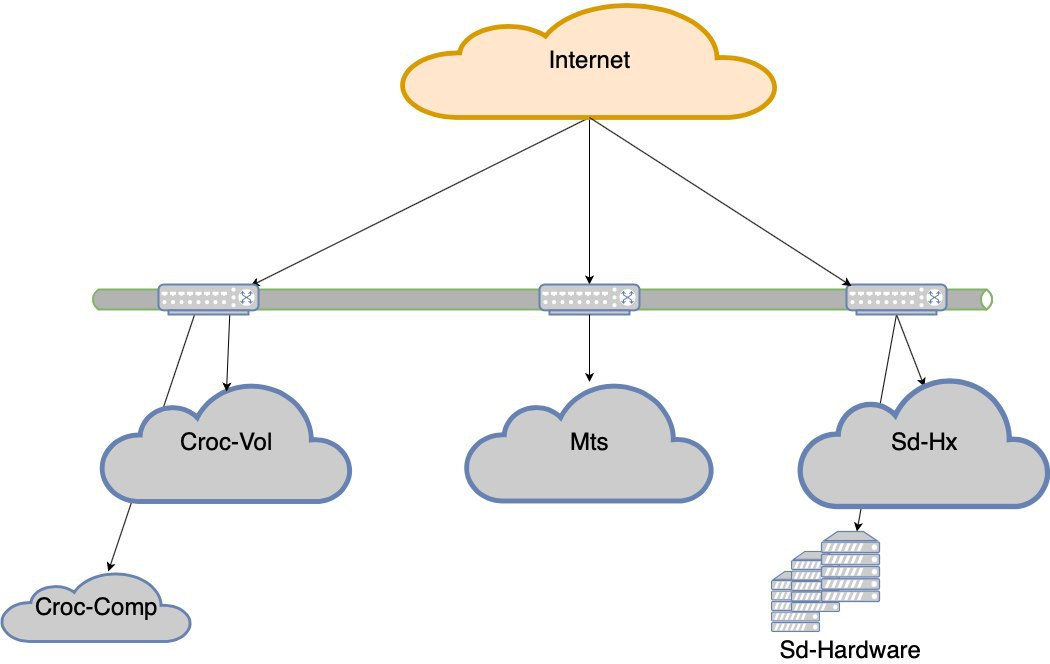
Sekarang kita tidak akan tidur jika salah satu dari 5 pusat data gagal. Tetapi jika kita kehilangan bahu Croc, akan ada drawdown yang sangat serius. Maka proyek ketahanan pusat data lahir. Tujuannya adalah ini - jika DC mati, jaringan mati sebelum atau peralatan mati, situs harus bekerja tanpa intervensi dengan tangan. Plus, setelah kecelakaan itu, kita harus pulih secara teratur.
Apa perangkapnya?
Sekarang:
Perlu:
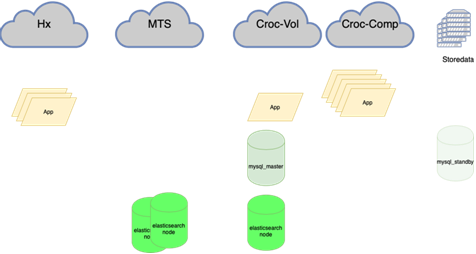
Sekarang:
Perlu:
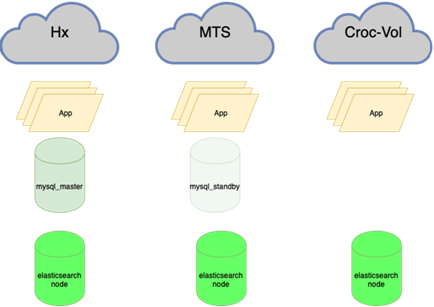
Elastisnya tahan terhadap hilangnya satu simpul:
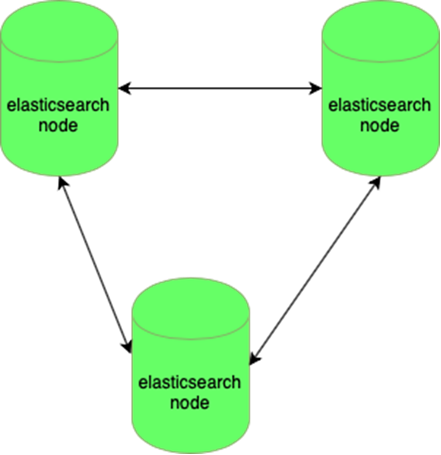
Database MySQL (banyak yang kecil) sulit dikelola:
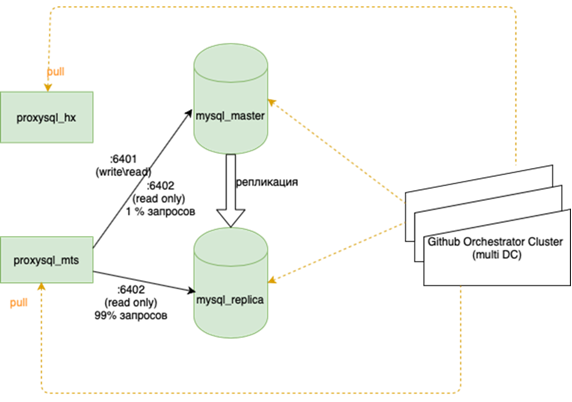
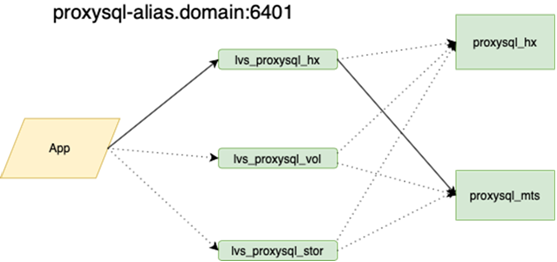
Tentang ini lebih baik ditulis secara lebih detail oleh kolega saya yang melakukan balancing. Yang penting adalah bahwa sebelum kita menggantungnya, jika kita kehilangan tuan, kita harus pergi ke cadangan dengan tangan kita dan memeriksa kotak r / o = 0, membangun kembali semua replika dengan ansambel ini, dan ada lebih dari dua di karangan bunga utama puluhan, ubah konfigurasi aplikasi, lalu jalankan konfigurasi dan tunggu pembaruan. Sekarang aplikasi berjalan di atas satu ip-anycast, yang melihat penyeimbang LVS. Konfigurasi permanen tidak berubah. Seluruh topologi pangkalan di orkestra.
Sekarang, optik gelap direntangkan di antara pusat data kami, yang memungkinkan kami untuk mengakses sumber daya apa pun di dalam cincin kami sebagai yang lokal. Waktu respons antara pusat data dan waktu di dalam plus atau minus adalah sama. Ini adalah perbedaan penting dari perusahaan lain yang sedang membangun geoclusters. Kami sangat terikat dengan perangkat keras dan jaringan kami, dan kami tidak mencoba untuk melokalkan permintaan di dalam pusat data. Ini keren di satu sisi, dan di sisi lain, jika kita ingin pergi ke Eropa atau Cina, kita tidak akan mengeluarkan optik gelap kita.
Ini berarti menyeimbangkan kembali hampir semua, terutama database. Ada banyak skema, ketika master aktif memegang seluruh beban untuk membaca dan menulis, dan di sebelahnya ada replika sinkron untuk pengalihan cepat (kita tidak menulis dua sekaligus, tetapi mereplikasi, kalau tidak itu tidak bekerja dengan baik) Basis utama di satu pusat data, dan replika di yang lain. Ada juga sebagian salinan di aplikasi ketiga untuk masing-masing. Ada 10 hingga 15 contoh seperti itu tergantung pada waktu tahun. Orchestrator adalah cluster yang membentang antara pusat data dan 3 pusat data. Di sini kami akan memberi tahu Anda lebih detail ketika Anda memiliki kekuatan untuk menggambarkan bagaimana semua musik ini diputar.
Anda harus menggali aplikasi. Ini masih diperlukan sekarang: kadang-kadang terjadi bahwa jika koneksi terputus, maka benar untuk memadamkan yang lama, buka yang baru. Tetapi kadang-kadang permintaan untuk koneksi yang sudah hilang diulang dalam satu lingkaran sampai proses mati. Hal terakhir yang tertangkap adalah tugas mahkota, pengingat tentang kereta tidak ditulis.
Secara umum, masih ada sesuatu yang harus dilakukan, tetapi rencananya jelas.