Kiat untuk memisahkan gangguan dari informasi yang bermanfaat

Jika Anda mengambil kursus pengantar tentang statistik, Anda akan menyadari bahwa data dapat digunakan untuk mencari inspirasi atau menguji teori, tetapi tidak untuk keduanya. Mengapa demikian?
Orang-orang terlalu pandai menemukan pola dalam segala hal. Anda sendiri yang menentukan pola mana yang benar-benar ada dan mana yang ditemukan. Kami adalah makhluk yang menemukan wajah Elvis di keripik kentang. Jika Anda tergoda untuk menyamakan pola dengan konsep, ingatlah bahwa ada tiga jenis pola:
- Pola yang ada baik di dataset Anda dan di luar.
- Pola yang hanya ada di dataset Anda.
- Pola yang hanya ada dalam imajinasi Anda (apophenia).
Pola data dapat ada (1) di seluruh populasi yang diminati, (2) hanya dalam sampel, atau (3) hanya di kepala Anda.
Pola dan pola data apa yang dapat berguna bagi Anda? Itu tergantung pada tujuan Anda.
Inspirasi
Jika Anda membutuhkan inspirasi murni, data dapat bekerja dengan sangat baik. Bahkan apofenia (kecenderungan manusia untuk secara keliru memahami hubungan dan makna antara hal-hal yang tidak berhubungan) - dapat membuat karya kreatif Anda sepenuhnya. Kreativitas tidak memiliki jawaban yang benar, jadi yang harus Anda lakukan adalah melihat data Anda dan bermain dengannya. Sebagai bonus tambahan, cobalah untuk tidak membuang waktu terlalu banyak (milik Anda atau mereka yang tertarik) dengan sia-sia.
Fakta
Ketika pemerintah Anda ingin memungut pajak dari Anda, pemerintah tidak dapat mengabaikan nilai-nilai yang melampaui data keuangan Anda untuk tahun itu. IRS perlu membuat keputusan faktual tentang berapa banyak Anda berutang dan cara utama untuk mengambil keputusan itu adalah dengan menganalisis data dari tahun lalu. Dengan kata lain, lihat data dan terapkan rumusnya. Dalam hal ini, kita berbicara tentang analisis deskriptif murni yang terkait dengan data yang tersedia. Salah satu dari dua jenis pola pertama sangat cocok untuk ini.
Analisis deskriptif terkait dengan data yang ada.
(Saya tidak pernah menyembunyikan laporan keuangan saya, tetapi saya pikir pemerintah Amerika Serikat tidak akan senang jika saya menggunakan metode penghitungan data yang saya pelajari di sekolah pascasarjana untuk membayar pajak secara statistik untuk menggantikannya.
Keputusan dalam menghadapi ketidakpastian
Terkadang fakta yang tersedia tidak sesuai dengan yang diinginkan. Ketika Anda tidak memiliki semua informasi yang Anda butuhkan untuk membuat keputusan, Anda harus menavigasi ketidakpastian, mencoba memilih tindakan yang masuk akal.
Inilah tepatnya statistik - ilmu tentang bagaimana mengubah pikiran Anda dalam menghadapi ketidakpastian. Permainan ini untuk melompat ke yang tidak diketahui seperti Icarus ... dan pada saat yang sama tidak menabrak berkeping-keping.
Ini adalah tantangan utama ilmu data: bagaimana tidak menjadi * bodoh * sebagai hasil dari ilmu data.
Sebelum melompat dari tebing ini, lebih baik berharap bahwa pola yang Anda temukan dalam pandangan Anda yang terbatas tentang kenyataan benar-benar bekerja di luar pandangan Anda. Dengan kata lain, templat perlu digeneralisasi agar bermanfaat bagi Anda.

Dari tiga jenis pola, ketika membuat keputusan di bawah ketidakpastian, hanya yang pertama (digeneralisasi) yang aman. Sayangnya, Anda akan menemukan jenis pola lain dalam data Anda - ini adalah masalah besar yang mendasari ilmu data: bagaimana tidak kehilangan kesadaran Anda sendiri sebagai hasil dari mempelajari data.
Generalisasi
Jika Anda berpikir bahwa menemukan pola yang tidak berguna dalam data adalah hak istimewa manusia murni - pikirkan lagi! Jika Anda tidak hati-hati, mesin dapat melakukan hal yang sama secara otomatis.
Inti dari pembelajaran mesin dan AI adalah untuk menyamaratakan situasi baru dengan tepat.
Pembelajaran mesin adalah pendekatan untuk membuat banyak keputusan serupa yang melibatkan pencarian algoritmik untuk pola dalam data Anda dan menggunakannya untuk merespons dengan benar terhadap data yang benar-benar baru. Dalam jargon pembelajaran mesin dan AI, generalisasi mengacu pada kemampuan model Anda untuk bekerja dengan baik dengan data yang belum terlihat. Apa gunanya model berbasis template yang hanya berfungsi dengan baik dengan data lama? Untuk melakukan ini, Anda cukup menggunakan tabel pencarian. Inti dari pembelajaran mesin dan AI adalah membuat generalisasi yang benar dengan benar dalam situasi baru.

Inilah sebabnya mengapa jenis pola pertama dalam daftar kami adalah satu-satunya yang bekerja dengan baik untuk pembelajaran mesin. Jenis data ini adalah sinyal, yang lainnya hanyalah noise (faktor-faktor yang hanya ada di data lama Anda dan mengganggu penciptaan model yang dapat digeneralisasikan).
Sinyal: Pola yang ada baik di dalam dataset Anda dan di luar.
Noise: pola yang hanya ada di set data Anda.
Pada dasarnya, mendapatkan solusi yang menangani kebisingan lama, bukan data baru, adalah apa yang disebut overfitting dalam pembelajaran mesin (kami menggunakan istilah ini dengan nada yang sama yang Anda gunakan untuk mengucapkan kata sumpah favorit Anda). Dalam pembelajaran pembelajaran mesin, hampir semuanya dilakukan untuk menghindari overfitting.
Jadi, mengacu pada apa * sampel * ini?
Misalkan pola yang Anda (atau komputer Anda) telah ekstrak dari data Anda ada di luar imajinasi Anda - apa yang termasuk kategori itu? Apakah ini fenomena nyata yang ada dalam populasi yang diminati (sinyal) atau apakah itu fitur dataset Anda (noise)? Bagaimana cara menentukan jenis pola yang terdeteksi saat bekerja dengan data?
Jika Anda mempelajari semua data yang tersedia, maka Anda tidak akan dapat melakukan ini. Anda akan bingung dan tidak dapat mengetahui apakah template Anda ada di tempat lain. Semua retorika tentang pengujian hipotesis statistik tergantung pada yang tidak terduga, dan untuk berpura-pura bahwa pola yang sudah diketahui mengejutkan Anda adalah selera buruk (pada kenyataannya, ini peretasan).

Ini seperti melihat awan berbentuk kelinci dan kemudian memeriksa untuk melihat apakah semua awan itu terlihat seperti kelinci ... melihat awan yang sama. Saya harap Anda mengerti bahwa Anda akan membutuhkan awan baru untuk menguji teori Anda.
Setiap data yang digunakan untuk merumuskan teori atau pertanyaan tidak dapat digunakan untuk memverifikasi teori yang sama.
Apa yang akan Anda lakukan jika Anda tahu bahwa Anda hanya memiliki akses ke satu cloud? Bermeditasi di lemari, itulah yang terjadi. Ajukan pertanyaan Anda sebelum Anda melihat data.
Matematika tidak pernah bertentangan dengan akal sehat.
Di sini kita sampai pada kesimpulan paling menyedihkan. Jika Anda menggunakan dataset Anda untuk inspirasi, maka Anda tidak dapat menggunakannya lagi untuk menguji secara menyeluruh teori yang diilhami (tidak peduli apa pun trik jiu-jitsu matematika yang Anda gunakan, matematika tidak pernah bertentangan dengan akal sehat).
Pilihan yang sulit
Intinya adalah Anda harus membuat pilihan! Jika Anda hanya memiliki satu dataset, maka Anda harus bertanya pada diri sendiri, “Saya bermeditasi di lemari, merumuskan hipotesis saya untuk pengujian statistik, dan kemudian dengan hati-hati mengambil pendekatan yang ketat - semua sehingga saya bisa menganggap diri saya serius? Atau apakah saya hanya mengumpulkan data untuk inspirasi, dan dengan melakukan itu saya menyadari bahwa saya mungkin menipu diri saya sendiri dan ingat bahwa saya harus menggunakan frasa seperti 'Saya merasa' atau 'itu menginspirasi' atau 'Saya tidak yakin'? " Pilihan yang sulit!
Atau adakah cara makan satu potong kue dua kali? Masalahnya adalah Anda hanya memiliki satu dataset, dan Anda membutuhkan lebih dari satu dataset. Dan jika Anda memiliki cukup data, maka saya punya trik itu. Akan meledak. Anda. Otak.

Trik rumit
Untuk berhasil dalam ilmu data, ubah satu set data menjadi dua (setidaknya) dengan membagi data Anda. Kemudian gunakan satu untuk inspirasi dan yang lainnya untuk pengujian yang ketat. Jika pola yang awalnya menginspirasi Anda juga ada dalam data yang tidak dapat memengaruhi pendapat Anda, kemungkinan besar pola ini merupakan aturan umum yang berlaku di kotoran kucing tempat Anda mengambil data.
Jika fenomena yang sama diamati di kedua set data, ini mungkin aturan umum yang memanifestasikan dirinya dalam semua sumber data ini.
RSChD!
Karena hidup tanpa eksplorasi sama sekali bukan kehidupan, berikut adalah empat kata untuk dijalani: Bagikan data sialan Anda .
Dunia akan menjadi tempat yang lebih baik jika semua orang berbagi data. Kami akan memiliki jawaban yang lebih baik (berkat statistik) dan pertanyaan yang lebih baik (terima kasih kepada analitik). Satu-satunya alasan orang tidak menganggap berbagi data sebagai kebiasaan wajib adalah bahwa pada abad terakhir ini merupakan kemewahan yang sangat sedikit orang sanggup bayar. Set data sangat kecil sehingga jika Anda mencoba untuk memisahkannya, maka mungkin tidak ada yang tersisa dari mereka.
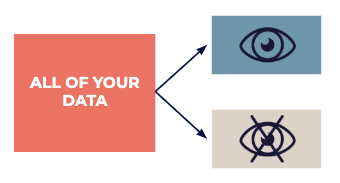
Pisahkan data Anda ke dalam kumpulan data penelitian yang tersedia untuk semua orang yang dapat digunakan untuk inspirasi, dan yang uji, yang nantinya akan digunakan oleh para ahli untuk mengkonfirmasi secara akurat setiap “tebakan” yang ditemukan pada tahap penelitian.
Beberapa proyek masih menghadapi masalah ini, terutama dalam penelitian medis (saya dulu melakukan neurobiologi, jadi saya sangat menghormati kompleksitas bekerja dengan set data kecil), tetapi banyak dari Anda memiliki begitu banyak data sehingga Anda perlu menyewa insinyur, hanya untuk mengatur pergerakan mereka ... alasan apa yang kamu miliki ?! Jangan pelit, bagikan data Anda.
Jika Anda tidak memiliki kebiasaan berbagi data, Anda mungkin akan terjebak di abad ke-20.
Jika Anda memiliki banyak data, dan set mereka tidak terpisah, maka Anda ada dalam paradigma yang ketinggalan zaman. Orang-orang yang ada dalam paradigma ini telah mengundurkan diri ke pemikiran kuno dan menolak untuk melangkah lebih jauh dalam waktu.
Pembelajaran mesin - keturunan dari partisi data
Pada akhirnya, idenya sederhana. Gunakan satu set data untuk membentuk teori, pahami data ini, dan kemudian lakukan keajaiban - buktikan kebenaran ide Anda pada set data yang benar-benar baru.
Berbagi data adalah perbaikan cepat termudah untuk budaya data yang lebih sehat.
Dengan cara ini Anda dapat dengan aman menggunakan metode statistik dan memastikan diri Anda tidak overfitting. Faktanya, sejarah pembelajaran mesin adalah sejarah berbagi data.
Cara menggunakan ide terbaik dalam ilmu data
Untuk mengambil keuntungan dari ide terbaik dalam ilmu data, yang harus Anda lakukan adalah memastikan Anda menjauhkan data uji dari jangkauan mata yang mengintip, dan kemudian membiarkan analis Anda tergila-gila dengan yang lainnya.
Agar berhasil dalam ilmu data, cukup ubah satu dataset menjadi (setidaknya) dua dengan memisahkan data Anda.
Ketika Anda berpikir mereka telah membawakan Anda informasi yang berguna di luar apa yang telah mereka pelajari, gunakan simpanan rahasia data pengujian Anda untuk menguji temuan Anda.

Pelajari detail cara mendapatkan profesi yang dicari dari awal atau Tingkatkan keterampilan dan gaji dengan menyelesaikan kursus online berbayar SkillFactory:
- Kursus Pembelajaran Mesin (12 minggu)
- Belajar Ilmu Data dari awal (12 bulan)
- (9 )
- «Python -» (9 )