Catatan tersebut menjelaskan percobaan untuk membuat salinan kecil dari gudang data perusahaan dengan spesifikasi yang sangat terbatas. Yaitu, berdasarkan pada komputer papan tunggal Raspberry Pi.
Model dan arsitektur akan disederhanakan, tetapi mirip dengan penyimpanan perusahaan. Hasilnya adalah penilaian kemungkinan menggunakan Raspberry Pi di bidang pengolahan dan analisis data.

1
Peran pemain yang berpengalaman dan kuat akan dimainkan oleh kendaraan Exadata X5 (satu unit) dari perusahaan Oracle.
Proses pengolahan data mencakup langkah-langkah berikut:
- Membaca dari file 10,3 GB - 350 juta catatan dalam 90 menit.
- Pemrosesan dan pembersihan data - 2 kueri SQL dan 15 menit (dengan enkripsi data pribadi 180 menit).
- Pengukuran pemuatan - 10 menit.
- Mengunduh tabel fakta dengan 20 juta catatan baru - 5 kueri SQL dan 35 menit.
Total integrasi 350 juta catatan dalam 2,5 jam, yang setara dengan 2,3 juta catatan per menit atau sekitar 39 ribu catatan data mentah per detik.
# 2
Lawan eksperimental akan menjadi Raspberry Pi 3 Model B + dengan prosesor 4-core 1,4 GHz.
Sqlite3 digunakan sebagai penyimpanan, file dibaca menggunakan PHP. File dan basis data terletak pada kartu SD 10 kelas 32GB di pembaca internal. Cadangan dibuat pada flash drive 64 GB yang terhubung ke USB.
Model data dalam database relasional sqlite3 dan laporan dijelaskan dalam artikel tentang penyimpanan kecil .
Model data
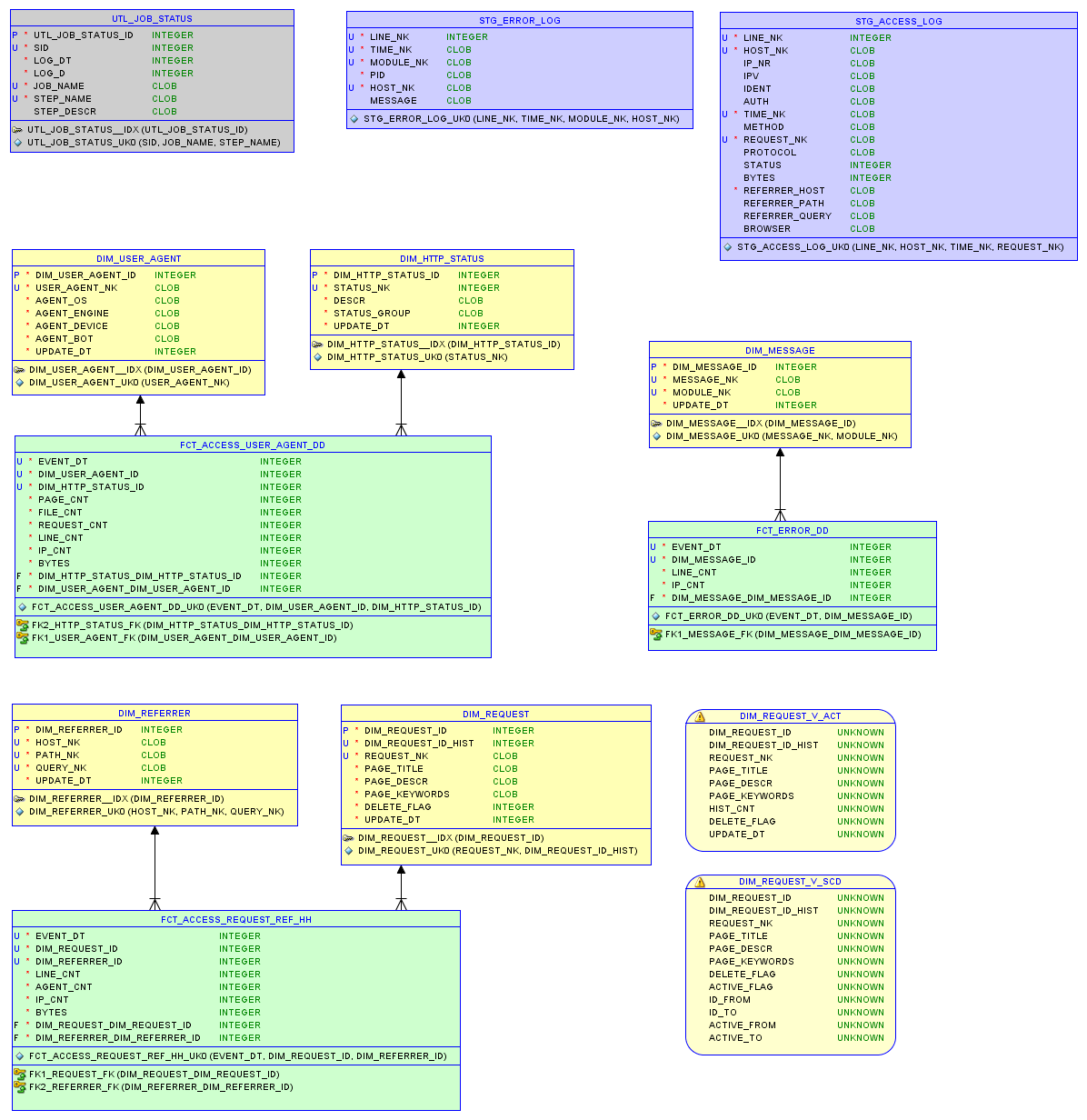
Tes satu
File access.log sumber adalah 37 MB dengan 200 ribu entri.
- Butuh 340 detik untuk membaca log dan menulis ke database.
- Memuat pengukuran dengan 5 ribu catatan berlangsung 5 detik.
- Memuat tabel fakta dengan 90 ribu catatan baru - 32 detik.
Secara total , integrasi 200 ribu catatan memakan waktu hampir 7 menit, yang setara dengan 28 ribu catatan per menit atau 470 catatan data mentah per detik. Basis data menempati 7,5 MB; hanya 8 query SQL untuk pemrosesan data.
Tes kedua
File situs yang lebih aktif. File access.log asli adalah 67MB dengan entri 290K.
- Butuh 670 detik untuk membaca log dan menulis ke database.
- Memuat pengukuran dengan 25 ribu catatan membutuhkan waktu 8 detik.
- Memuat tabel fakta dengan 240 ribu catatan baru - 80 detik.
Secara total , integrasi 290 ribu catatan membutuhkan waktu lebih dari 12 menit, yang setara dengan 23 ribu catatan per menit atau 380 catatan data sumber per detik. Basis data menempati 22,9 MB
Keluaran
Sumber daya komputasi dan material yang signifikan diperlukan untuk mendapatkan data dalam bentuk model yang akan memungkinkan untuk analisis yang efektif, dan waktu dalam hal apapun.
Misalnya, satu unit Exadata harganya lebih dari 100 ribu. Satu Raspberry Pi berharga 60 unit.
Mereka tidak dapat dibandingkan secara linear, karena dengan peningkatan volume data dan persyaratan keandalan, kesulitan muncul.
Namun, jika kita bayangkan sebuah kasus di mana seribu Raspberry Pi bekerja secara paralel, maka, berdasarkan percobaan, mereka akan memproses sekitar 400 ribu catatan data mentah per detik.
Dan jika solusi untuk Exadata dioptimalkan hingga 60 atau 100 ribu catatan per detik, maka ini secara signifikan kurang dari 400 ribu. Ini menegaskan perasaan batin bahwa harga solusi perusahaan terlalu tinggi.
Bagaimanapun, Raspberry Pi akan melakukan pekerjaan yang sangat baik dengan pemrosesan data dan model relasional dari skala yang sesuai.
Tautan
Raspberry Pi rumah telah dikonfigurasi sebagai server web. Saya akan menjelaskan proses ini di posting berikutnya.
Anda dapat bereksperimen dengan kinerja Raspberry Pi dan file access.log sendiri di . Model database (DDL), prosedur pemuatan (ETL) dan database itu sendiri dapat diunduh di sana. Idenya adalah untuk dengan cepat mendapatkan gagasan tentang keadaan situs dari log dengan data dari beberapa minggu terakhir.
Perubahan
Berkat komentar, bug dalam memuat file Exadata telah diperbaiki dan angka dalam catatan telah diperbaiki. Sqlloader digunakan untuk membaca, beberapa bug menghapus parameter BINDSIZE dan ROWS. Karena boot tidak stabil dari drive jarak jauh, metode konvensional dipilih sebagai ganti jalur langsung, yang dapat meningkatkan kecepatan 30-50% lainnya.