Posting terakhir ini membahas tentang analisis varians. Lihat postingan sebelumnya di sini .
Analisis varians
Analisis varians (variance), yang dalam literatur khusus disebut juga sebagai ANOVA dari bahasa Inggris. ANalysis Of VAriance adalah sekumpulan metode statistik yang digunakan untuk mengukur signifikansi statistik dari perbedaan antar kelompok. Ini dikembangkan oleh ahli statistik yang sangat berbakat Ronald Fisher, yang juga mempopulerkan uji signifikansi statistik dalam makalah penelitian pengujian biologisnya.
Catatan... Dalam rangkaian posting sebelumnya dan ini, istilah "varians" digunakan dalam istilah "varians" yang diterima dan istilah "varian" diindikasikan dalam tanda kurung di beberapa tempat. Ini bukan kebetulan. Di luar negeri ada istilah berpasangan "varians" dan "kovarian", dan dalam teori keduanya harus diterjemahkan dengan satu akar, misalnya, sebagai "varian" dan "kovarian", tetapi kenyataannya, kami memiliki sambungan berpasangan yang rusak, dan keduanya diterjemahkan sebagai "varians" dan "kovarian" yang sama sekali berbeda. Tapi itu belum semuanya. "Dispersi" (varians statistik) di luar negeri adalah konsep dispersi generik yang terpisah, yaitu sejauh mana distribusi membentang atau menyusut, dan ukuran varians statistik adalah varians, deviasi standar, dan rentang interkuartil. Dispersi, sebagai konsep umum dispersi, dan varians, sebagai salah satu tolok ukurnya,mengukur jarak dari mean adalah dua konsep yang berbeda. Selanjutnya dalam teks untuk varians, istilah "varians" yang diterima secara umum akan digunakan di seluruh bagian. Namun, perbedaan dalam terminologi ini harus diperhitungkan.
Uji statistik- z dan statistik- t kami berfokus pada rata-rata sampel sebagai mekanisme utama untuk membedakan antara dua sampel. Dalam setiap kasus, kami mencari perbedaan rata-rata, dibagi dengan tingkat ketidaksesuaian yang dapat kami perkirakan, dan diukur dengan kesalahan standar.
Mean bukan satu-satunya indikator sampel yang dapat menunjukkan ketidaksesuaian antar sampel. Faktanya, varians sampel juga dapat digunakan sebagai indikator ketidaksesuaian statistik.
, halaman demi halaman dan gabungan")
, , . - . , , .
— . , , . , , .
F-
F- — .
— 1, — . k , n — , :


F- pandas plot
:
def ex_2_Fisher():
''' F- '''
mu = 0
d1_values, d2_values = [4, 9, 49], [95, 90, 50]
linestyles = ['-', '--', ':', '-.']
x = sp.linspace(0, 5, 101)[1:]
ax = None
for (d1, d2, ls) in zip(d1_values, d2_values, linestyles):
dist = stats.f(d1, d2, mu)
df = pd.DataFrame( {0:x, 1:dist.pdf(x)} )
ax = df.plot(0, 1, ls=ls,
label=r'$d_1=%i,\ d_2=%i$' % (d1,d2), ax=ax)
plt.xlabel('$x$\nF-')
plt.ylabel(' \n$p(x|d_1, d_2)$')
plt.show()

F- , 100 , 5, 10 50 .
F-
, , F-. F- , . F- :
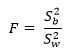
S2b — , S2w — .
F . , , . , , , .
F- , F. F .
F- . , . , k , x̅k, :

SSW — , xjk — j- .
SSW , Python, ssdev
, :
def ssdev( xs ):
'''
'''
mu = xs.mean()
square_deviation = lambda x : (x - mu) ** 2
return sum( map(square_deviation, xs) )
F- :

SST — , SSW — , . «» , :

, SST — - . Python SST SSW , .
ssw = sum( groups.apply( lambda g: ssdev(g) ) ) #
#
sst = ssdev( df['dwell-time'] ) #
ssb = sst – ssw #
F- . ssb
ssw
, F-.
Python F- :
msb = ssb / df1 #
msw = ssw / df2 #
f_stat = msb / msw
F- , F-.
F-
, , () , , .
scipy stats.f.sf
, . F- 20 , . , , F-. F-, F- F-, . f_test
, :
def f_test(groups):
m, n = len(groups), sum(groups.count())
df1, df2 = m - 1, n - m
ssw = sum( groups.apply(lambda g: ssdev(g)) )
sst = ssdev( df['dwell-time'] )
ssb = sst - ssw
msb = ssb / df1
msw = ssw / df2
f_stat = msb / msw
return stats.f.sf(f_stat, df1, df2)
def ex_2_24():
''' - F-'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
return f_test(groups)
0.014031745203658217
F- p-, scipy stats.f.sf
, . P- , .. - . . 5%- .
p-, 0.014, .. . - , .

- , :
def ex_2_25():
'''
- '''
df = load_data('multiple-sites.tsv')
df.boxplot(by='site', showmeans=True)
plt.xlabel(' -')
plt.ylabel(' , .')
plt.title('')
plt.suptitle('')
plt.show()
boxplot
, -. - 0, .

, - 10 , . , , , , 6, 144 .:
def ex_2_26():
'''T- 0 10 -'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
site_0 = groups.get_group(0)
site_10 = groups.get_group(10)
_, p_val = stats.ttest_ind(site_0, site_10, equal_var=False)
return p_val
0.0068811940138903786
F-, , - 6 :
def ex_2_27():
'''t- 0 6 -'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
site_0 = groups.get_group(0)
site_6 = groups.get_group(6)
_, p_val = stats.ttest_ind(site_0, site_6, equal_var=False)
return p_val
0.005534181712508717
, , , - 6 -. AcmeContent -. - - !
, , . , — , . . , , .
d
d — , , , , . , :
Sab — ( ) . :
def pooled_standard_deviation(a, b):
'''
( )'''
return sp.sqrt( standard_deviation(a) ** 2 +
standard_deviation(b) ** 2)
, 6 - d :
def ex_2_28():
''' d
- 6'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
a = groups.get_group(0)
b = groups.get_group(6)
return (b.mean() - a.mean()) / pooled_standard_deviation(a, b)
0.38913648705499848
p-, d . , , . 0.5, , , 0.38 — . - , -, .
, . , , z-, t- F-.
, , , . — , — . , , F- 1- 2- .
.
Dalam rangkaian posting berikutnya, jika pembaca menginginkannya, kami akan menerapkan apa yang telah kami pelajari tentang varians dan uji F ke sampel tunggal. Kami akan menyajikan metode analisis regresi dan menggunakannya untuk menemukan korelasi antara variabel dalam sampel atlet Olimpiade.