
YELP adalah jaringan luar negeri yang membantu orang menemukan bisnis dan layanan lokal berdasarkan umpan balik, preferensi, dan rekomendasi. Dalam artikel saat ini, analisis tertentu akan dilakukan menggunakan platform Neo4j, terkait dengan DBMS grafik, serta bahasa python.
Apa yang akan kita lihat:
- bagaimana bekerja dengan Neo4j dan kumpulan data besar menggunakan YELP sebagai contoh;
- bagaimana kumpulan data YELP bisa berguna;
- sebagian: apa saja fitur di Neo4j versi baru dan mengapa buku "Graph Algorithms" 2019 oleh O'REILLY sudah ketinggalan zaman.
Apa itu dataset YELP dan yelp
Jaringan YELP saat ini mencakup 30 negara, Federasi Rusia belum termasuk dalam jumlah mereka. Bahasa Rusia tidak didukung oleh jaringan. Jaringan itu sendiri berisi sejumlah besar informasi tentang berbagai jenis perusahaan, serta ulasan tentang mereka. Selain itu, yelp dapat dengan aman disebut jejaring sosial, karena berisi data tentang pengguna yang meninggalkan ulasan. Tidak ada data pribadi di sana, hanya nama. Namun demikian, pengguna membentuk komunitas, grup, atau mereka dapat disatukan lebih jauh ke dalam grup dan komunitas ini sesuai dengan berbagai kriteria. Misalnya, dengan jumlah bintang (bintang) yang telah ditetapkan ke titik (restoran, pom bensin, dll.) Yang telah Anda kunjungi.
YELP mendeskripsikan dirinya sebagai berikut:
- 8.635.403 ulasan
- 160.585 perusahaan
- 200.000 gambar
- 8 kota besar
1.162.119 rekomendasi dari 2.189.457 pengguna.
Lebih dari 1,2 juta perlengkapan bisnis: jam buka, parkir, ketersediaan, dan lainnya.
Sejak 2013, Yelp secara teratur menyelenggarakan kompetisi Yelp Dataset, mendorong semua orang untuk
menjelajahi dan menjelajahi kumpulan data terbuka Yelp.
Dataset itu sendiri tersedia di tautan
Dataset cukup banyak dan setelah membukanya terdiri dari 5 file json:
Semuanya akan baik-baik saja, tetapi hanya YELP yang mengunggah data mentah dan belum diproses dan, untuk mulai bekerja dengannya, diperlukan pemrosesan awal.
Instalasi dan pengaturan cepat Neo4j
Untuk analisis, Neo4j akan digunakan, kita akan menggunakan kemampuan grafik DBMS dan bahasa sandi sederhana mereka untuk bekerja dengan dataset.
Tentang Neo4j sebagai database grafik berulang kali ditulis di Habre (di sini dan di sini untuk artikel untuk pemula), jadi kirimkan ulang tidak masuk akal.
Untuk mulai bekerja dengan platform ini, Anda perlu mengunduh versi desktop (sekitar 500Mb) atau bekerja di kotak pasir online. Pada saat penulisan ini, Neo4j Enterprise 4.2.6 untuk Pengembang tersedia, serta versi sebelumnya yang lain untuk penginstalan.
Selanjutnya, opsi akan digunakan - bekerja di versi desktop di lingkungan Windows (Neo4j Desktop 1.4.5, versi database 4.2.5, 4.2.1).
Terlepas dari kenyataan bahwa versi terbaru adalah 4.2.6, lebih baik tidak menginstalnya, karena semua plugin yang digunakan di neo4j belum diperbarui untuk itu. Versi sebelumnya - 4.2.5 sudah cukup.
Setelah menginstal paket yang diunduh, Anda perlu:
- buat database lokal baru, tentukan pengguna neo4j dan kata sandi 123 (mengapa persisnya akan dijelaskan di bawah),
gambar

- instal plugin yang Anda butuhkan - APOC, Graph Data Science Library.
gambar

- periksa apakah database dimulai dan apakah browser terbuka saat Anda mengklik tombol start
gambar


* - aktifkan mode offline sehingga database tidak mencoba menyarankan versi baru dengan sungguh-sungguh.
gambar

Memuat data ke Neo4j
Jika semuanya berjalan lancar dengan penginstalan Neo4j, Anda dapat melanjutkan dan ada tiga cara.
Cara pertama adalah jauh dari mengimpor data ke database dari awal, termasuk pembersihan dan transformasi awal.
Cara kedua adalah memuat database yang sudah selesai dari dump dan mulai mengerjakannya.
Cara ketiga adalah memuat database yang sudah selesai langsung ke folder dengan database yang baru dibuat.
Akibatnya, dalam semua kasus, Anda harus mendapatkan database dengan parameter berikut:

dan skema terakhir:
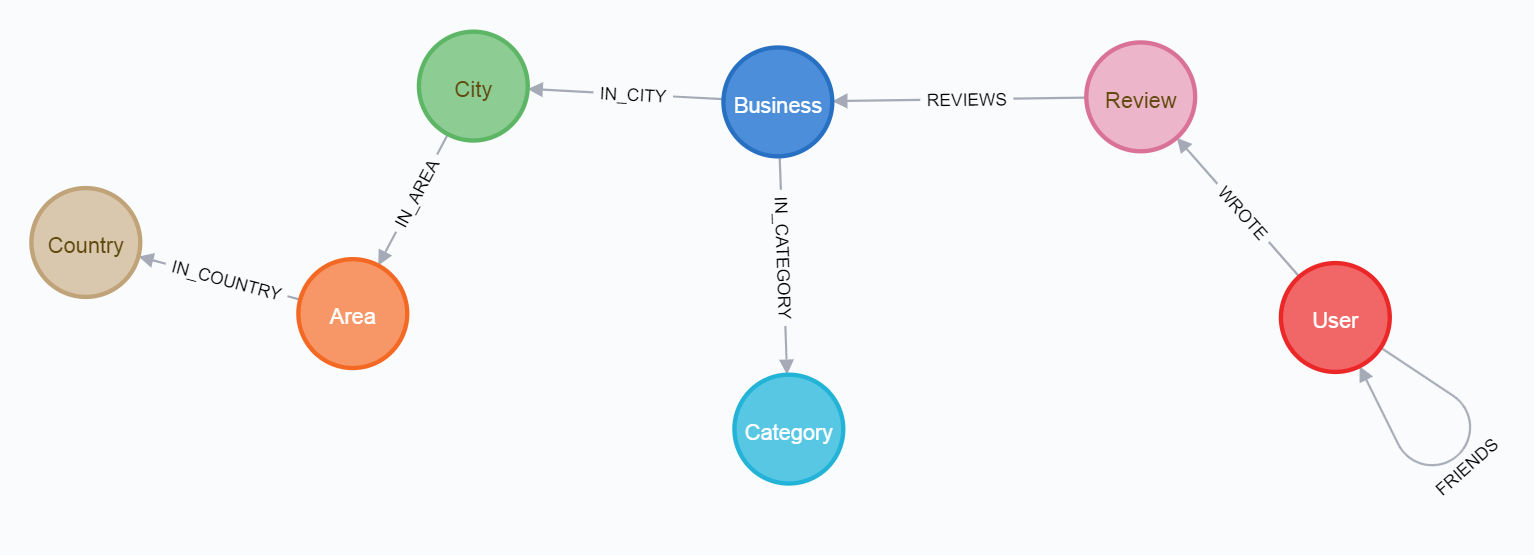
Untuk melalui jalur pertama, lebih baik membaca artikel di media terlebih dahulu .
* Terima kasih banyak kepada TRAN Ngoc Thach untuk ini.
Dan gunakan notebook jupyter yang sudah jadi (diadaptasi oleh saya untuk windows) - link .
Proses import tidak mudah dan memakan waktu cukup lama -

Tidak ada masalah dengan memory, walaupun Ram hanya 8GB, karena batch import digunakan.
Namun, Anda perlu membuat file swap 10GB, karena saat memeriksa data yang diimpor, jupyter macet, hal ini disebutkan di notebook jupyter di atas.
Cara kedua lebih mudah.
Buat database, buka folder dengan neo4j-adminnya (setiap database memiliki database sendiri) dan jalankan:
neo4j-admin load --from=G:\neo4j\dumps\neo4j.dump --database=neo4j --force
di mana G: \ neo4j \ dumps \ neo4j.dump adalah jalur ke database dump.
Cara ketiga adalah yang tercepat dan ditemukan secara tidak sengaja. Ini berarti menyalin database neo4j yang sudah jadi langsung ke database neo4j yang sudah ada. Dari minus (sejauh ini ditemukan) - Anda tidak dapat membuat cadangan database menggunakan Neo4j (neo4j-admin dump --database = neo4j --to = D: \ neo4j \ neo4j.dump). Namun, ini mungkin karena perbedaan versi - di versi 4.2.1, database disalin dari versi 4.2.5. Selain itu, artefak muncul di skema database umum, yang bagaimanapun tidak mempengaruhi operasinya.
Bagaimana metode ini diterapkan:
- buka tab Kelola database tempat impor akan dilakukan
gambar


- buka folder dengan database dan salin folder data di sana, timpa kemungkinan kecocokan
gambar

Dalam hal ini, database itu sendiri, tempat salinan dibuat, tidak boleh dimulai.
- Mulai ulang Neo4j.
Dan di sinilah login-password yang sebelumnya digunakan (neo4j, 123) akan berguna untuk menghindari konflik.
Setelah memulai database yang disalin, database dengan dataset yelp akan tersedia:

Menonton YELP
Anda dapat mempelajari YELP baik dari browser Neo4j, dan dengan mengirimkan kueri ke database dari notebook jupyter yang sama.
Karena database adalah grafik, browser akan disertai dengan gambar visual yang menyenangkan di mana grafik ini akan ditampilkan.
Mulai berkenalan dengan YELP, perlu membuat reservasi bahwa database hanya akan berisi 3 negara AS, KG dan CA:

Anda dapat melihat skema database dengan menulis permintaan dalam bahasa sandi di browser neo4j:
CALL db.schema.visualization()
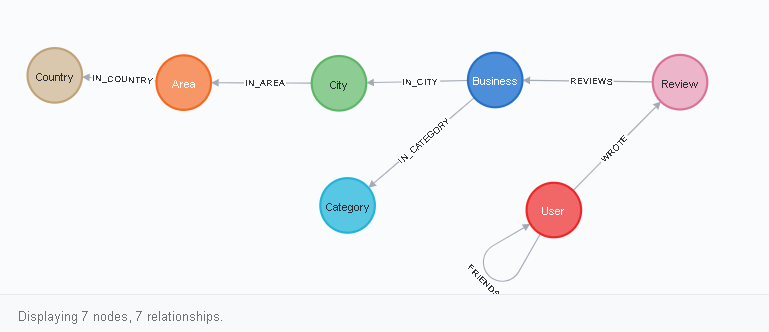
Bagaimana cara membaca diagram ini? Semuanya terlihat seperti ini. Node Pengguna memiliki link ke dirinya sendiri dari jenis FRIENDS, serta link WROTE ke node Review. Rewiew, pada gilirannya, memiliki hubungan REVIEWS dengan Business, dan seterusnya. Anda dapat melihat ini secara visual setelah mengklik salah satu simpul (label simpul), misalnya, pada Pengguna:

database akan memilih 25 pengguna dan menunjukkan kepada mereka:

Jika Anda mengklik ikon yang sesuai langsung pada pengguna, maka semua koneksi langsung darinya akan ditampilkan, dan sebagai koneksi untuk Pengguna dari dua jenis - TEMAN dan REVIEW, maka semuanya akan muncul:
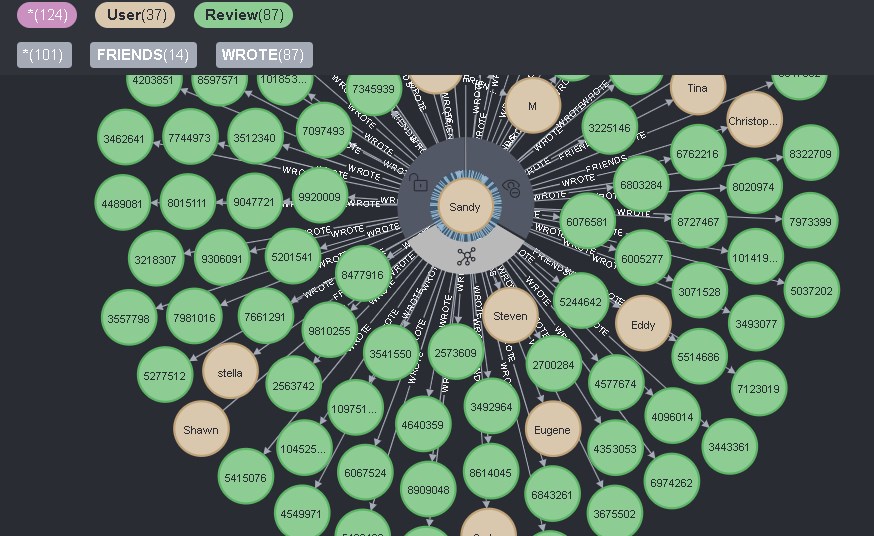
Ini nyaman dan tidak nyaman pada saat yang sama. Di satu sisi, Anda dapat melihat semua informasi tentang pengguna dengan satu klik, tetapi pada saat yang sama, Anda tidak dapat menghapus informasi yang tidak perlu dengan klik ini.
Tetapi tidak ada yang perlu dikhawatirkan, Anda dapat menemukan pengguna ini dan hanya semua temannya dengan id:
MATCH p=(:User {user_id:"u-CFWELen3aWMSiLAa_9VANw"}) -[r:FRIENDS]->() RETURN p LIMIT 25

Dengan cara yang sama, Anda dapat melihat ulasan apa yang ditulis oleh seseorang:

YELP menyimpan ulasan dari tahun 2010! Kegunaannya diragukan, tapi tetap saja.
Untuk membaca ulasan ini, Anda perlu beralih ke tampilan teks dengan mengklik A -

Mari kita lihat tempat yang ditulis Sandy sekitar 10 tahun yang lalu dan temukan di yelp.com -

Tempat seperti itu benar-benar ada - www.yelp.com/ biz / cafe-sushi- cambridge ,
dan ini Sandy sendiri dengan ulasannya sendiri - www.yelp.com/biz/cafe-sushi-cambridge?q=I%20was%20really%20excited
gambar

Kueri Python di Neo4j db dari notebook jupyter
Ini sebagian akan menggunakan informasi dari buku gratis yang disebutkan "Graph Algorithms" 2019 dari O'REILLY. Sebagian karena sintaks dalam buku ini sudah usang di banyak tempat.
Basis tempat kami akan bekerja harus diluncurkan, sementara tidak perlu meluncurkan browser neo4j itu sendiri.
Mengimpor perpustakaan:
from neo4j import GraphDatabase
import pandas as pd
from tabulate import tabulate
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
Koneksi DB:
driver = GraphDatabase.driver("bolt://localhost", auth=("neo4j", "123"))
Mari hitung jumlah simpul untuk setiap label dalam database:
result = {"label": [], "count": []}
with driver.session() as session:
labels = [row["label"] for row in session.run("CALL db.labels()")]
for label in labels:
query = f"MATCH (:`{label}`) RETURN count(*) as count"
count = session.run(query).single()["count"]
result["label"].append(label)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',
tablefmt='psql', showindex=False))
Keluaran:
+ ---------- + --------- +
| label | menghitung |
| ---------- + --------- |
| Negara | 3 |
| Area | 15 |
| Kota | 355 |
| Kategori | 1330 |
| Bisnis | 160585 |
| Pengguna | 2189457 |
| Review | 8635403 |
+ ---------- + --------- +
Sepertinya benar, di database kita ada 3 negara, seperti yang kita lihat sebelumnya melalui browser neo4j.
Dan kode ini akan menghitung jumlah tautan (edge):
result = {"relType": [], "count": []}
with driver.session() as session:
rel_types = [row["relationshipType"] for row in session.run
("CALL db.relationshipTypes()")]
for rel_type in rel_types:
query = f"MATCH ()-[:`{rel_type}`]->() RETURN count(*) as count"
count = session.run(query).single()["count"]
result["relType"].append(rel_type)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',
tablefmt='psql', showindex=False))
Keluaran:
+ ------------- + --------- +
| relType | menghitung |
| ------------- + --------- |
| IN_COUNTRY | 15 |
| IN_AREA | 355 |
| IN_CITY | 160585 |
| IN_CATEGORY | 708884 |
| ULASAN | 8635403 |
| MENULIS | 8635403 |
| TEMAN | 8985774 |
+ ------------- + --------- +
Saya pikir prinsipnya jelas. Terakhir, mari tulis permintaan dan render.
10 Hotel Terbaik Vancouver dengan Ulasan Terbanyak
# Find the 10 hotels with the most reviews
query = """
MATCH (review:Review)-[:REVIEWS]->(business:Business),
(business)-[:IN_CATEGORY]->(category:Category {category_id: $category}),
(business)-[:IN_CITY]->(:City {name: $city})
RETURN business.name AS business, collect(review.stars) AS allReviews
ORDER BY size(allReviews) DESC
LIMIT 10
"""
#MATCH (review:Review)-[:REVIEWS]->(business:Business),
#(business)-[:IN_CATEGORY]->(category:Category {category_id: "Hotels"}),
#(business)-[:IN_CITY]->(:City {name: "Vancouver"})
#RETURN business.name AS business, collect(review.stars) AS allReviews
#ORDER BY size(allReviews) DESC
#LIMIT 10
fig = plt.figure()
fig.set_size_inches(10.5, 14.5)
fig.subplots_adjust(hspace=0.4, wspace=0.4)
with driver.session() as session:
params = { "city": "Vancouver", "category": "Hotels"}
result = session.run(query, params)
for index, row in enumerate(result):
business = row["business"]
stars = pd.Series(row["allReviews"])
#print(dir(stars))
total = stars.count()
#s = pd.concat([pd.Series(x['A']) for x in data]).astype(float)
s = pd.concat([pd.Series(row['allReviews'])]).astype(float)
average_stars = s.mean().round(2)
# Calculate the star distribution
stars_histogram = stars.value_counts().sort_index()
stars_histogram /= float(stars_histogram.sum())
# Plot a bar chart showing the distribution of star ratings
ax = fig.add_subplot(5, 2, index+1)
stars_histogram.plot(kind="bar", legend=None, color="darkblue",
title=f"{business}\nAve:{average_stars}, Total: {total}")
#print(business)
#print(stars)
plt.tight_layout()
plt.show()
Hasilnya akan terlihat seperti ini -

sumbu X mewakili peringkat bintang hotel, dan sumbu Y mewakili persentase total dari setiap peringkat.
Bagaimana kumpulan data YELP bisa berguna
Di antara kelebihannya adalah sebagai berikut :
- bidang informasi yang cukup kaya dalam hal konten. Secara khusus, Anda bisa mengumpulkan ulasan dengan 1,0 atau 5,0 bintang dan mengirim spam ke bisnis apa pun. H'm. Sedikit ke arah yang salah, tetapi vektornya jelas;
- datasetnya besar, yang menciptakan kesulitan tambahan yang menyenangkan dalam hal pengujian kinerja berbagai platform data mining;
- data yang disajikan memiliki retrospektif tertentu dan, pada prinsipnya, adalah mungkin untuk memahami bagaimana perusahaan telah berubah, berdasarkan tinjauan tentangnya;
- data dapat digunakan sebagai tolok ukur untuk bisnis, mengingat bahwa alamat tersedia;
- pengguna dalam dataset sering membentuk struktur interkoneksi yang menarik yang dapat diambil apa adanya, tanpa membentuk pengguna menjadi sosial buatan. jaringan dan tidak mengumpulkan jaringan ini dari jaringan sosial lain yang ada. jaringan.
Kekurangan :
- hanya tiga dari 30 negara yang terwakili dan ada kecurigaan bahwa ini tidak sepenuhnya,
- ulasan disimpan selama 10 tahun, yang dapat mengubah dan sering merusak karakteristik bisnis yang ada,
- ada sedikit data tentang pengguna, mereka tidak bersifat pribadi, oleh karena itu, sistem rekomendasi berdasarkan kumpulan data jelas akan timpang,
- Tautan TEMAN menggunakan grafik terarah, yaitu Anya adalah teman -> Petya. Petya ternyata tidak berteman dengan Anya. Ini dapat diselesaikan secara terprogram, tetapi masih merepotkan.
- set data dibuat "mentah" dan membutuhkan banyak upaya untuk memprosesnya terlebih dahulu.
Neo4j
Neo4j diperbarui secara dinamis dan versi baru dari antarmuka yang digunakan di Neo4j Desktop 1.4.5 sangat tidak nyaman, menurut saya. Secara khusus, ada ketidakjelasan dalam hal informasi tentang jumlah node dan link dalam database, yang ada di versi sebelumnya. Selain itu, antarmuka untuk menavigasi tab saat bekerja dengan database telah diubah dan Anda juga harus membiasakannya.
Gangguan utama dalam pembaruan ini adalah integrasi algoritme grafik ke dalam plugin Perpustakaan Ilmu Data Grafik. Mereka sebelumnya dinamai algoritma-grafik-neo4j .
Setelah integrasi, banyak algoritme mengubah sintaksnya secara signifikan. Untuk alasan ini, mempelajari buku Algoritma Grafik 2019 oleh O'REILLY bisa jadi sulit.
Dump database Yelp untuk neo4j - unduh...