
Halo, Habr! Baru-baru ini, kami menulis tentang kumpulan data terbuka yang dikumpulkan oleh tim mahasiswa pascasarjana Ilmu Data dari NUST MISIS dan Zavtra.Online (departemen universitas SkillFactory) sebagai bagian dari Dataton pendidikan pertama. Dan hari ini kami akan menghadirkan sebanyak 3 dataset dari tim yang juga mencapai babak final.
Mereka semua berbeda: beberapa telah meneliti pasar musik, beberapa telah meneliti pasar tenaga kerja spesialis IT, dan beberapa telah mempelajari kucing domestik. Masing-masing proyek ini relevan di bidangnya masing-masing dan dapat digunakan untuk meningkatkan sesuatu dalam pekerjaan yang biasa. Kumpulan data dengan kucing, misalnya, akan membantu juri di pameran. Dataset yang harus dikumpulkan mahasiswa harus MVP (tabel, json atau struktur direktori), data harus dibersihkan dan dianalisis. Mari kita lihat apa yang mereka lakukan.
Set data 1: Meluncur di atas gelombang musik dengan Data Surfers
Berbaris:
- Plotnikov Kirill - manajer proyek, pengembangan, dokumentasi.
- Dmitry Tarasov - pengembangan, pengumpulan data, dokumentasi.
- Shadrin Yaroslav - pengembangan, pengumpulan data.
- Merzlikin Artyom - manajer produk, presentasi.
- Ksenia Kolesnichenko - analisis data awal.
Sebagai bagian dari partisipasi mereka dalam hackathon, anggota tim mengusulkan beberapa ide menarik yang berbeda, tetapi kami memutuskan untuk fokus mengumpulkan data tentang artis musik Rusia dan lagu terbaik mereka dari Spotify dan MusicBrainz.
Spotify adalah platform musik yang datang ke Rusia belum lama ini, tetapi sudah secara aktif mendapatkan popularitas di pasar. Selain itu, dalam hal analisis data, Spotify menyediakan API yang sangat nyaman dengan kemampuan untuk meminta data dalam jumlah besar, termasuk metriknya sendiri, seperti "kemampuan menari" - skor dari 0 hingga 1 yang menggambarkan seberapa bagus sebuah lagu. untuk menari.
MusicBrainzMerupakan ensiklopedia musik yang berisi informasi terlengkap tentang grup musik yang ada dan yang sudah ada. Semacam "wikipedia musik". Kami membutuhkan data dari sumber ini untuk mendapatkan daftar semua artis dari Rusia.
Mengumpulkan data artis
Kami telah mengumpulkan seluruh tabel yang berisi 1.4363 entri unik untuk berbagai artis. Untuk memudahkan navigasi di dalamnya, terdapat keterangan kolom tabel di bawah spoiler.
Deskripsi bidang tabel
artist – ;
musicbrainz_id – Musicbrainz;
spotify_id – Spotify, ;
type – , Person, Group, Other, Orchestra, Choir Character;
followers – Spotify;
genres – ;
popularity – Spotify 0 100, .
musicbrainz_id – Musicbrainz;
spotify_id – Spotify, ;
type – , Person, Group, Other, Orchestra, Choir Character;
followers – Spotify;
genres – ;
popularity – Spotify 0 100, .

Contoh
artis Record Fields, musicbrainz_id, dan jenisnya diambil dari database musik Musicbrainz, karena ada peluang untuk mendapatkan daftar artis yang terkait dengan satu negara. Ada dua cara untuk mengambil data ini:
- Parse bagian Artis di halaman dengan informasi tentang Rusia.
- Dapatkan data melalui API. MusicBrainz API
Dokumentasi MusicBrainz API
Dokumentasi Cari
Contoh GET Permintaan di musicbrainz.org
Dalam proses pengerjaan, ternyata API MusicBrainz tidak menanggapi permintaan dengan benar dengan parameter Area: Rusia, menyembunyikan dari kami artis-artis yang memiliki Area tertentu, misalnya, Izhevsk atau Moskva. Oleh karena itu, data dari MusicBrainz diambil oleh parser langsung dari situsnya. Di bawah ini adalah contoh halaman tempat data diurai.
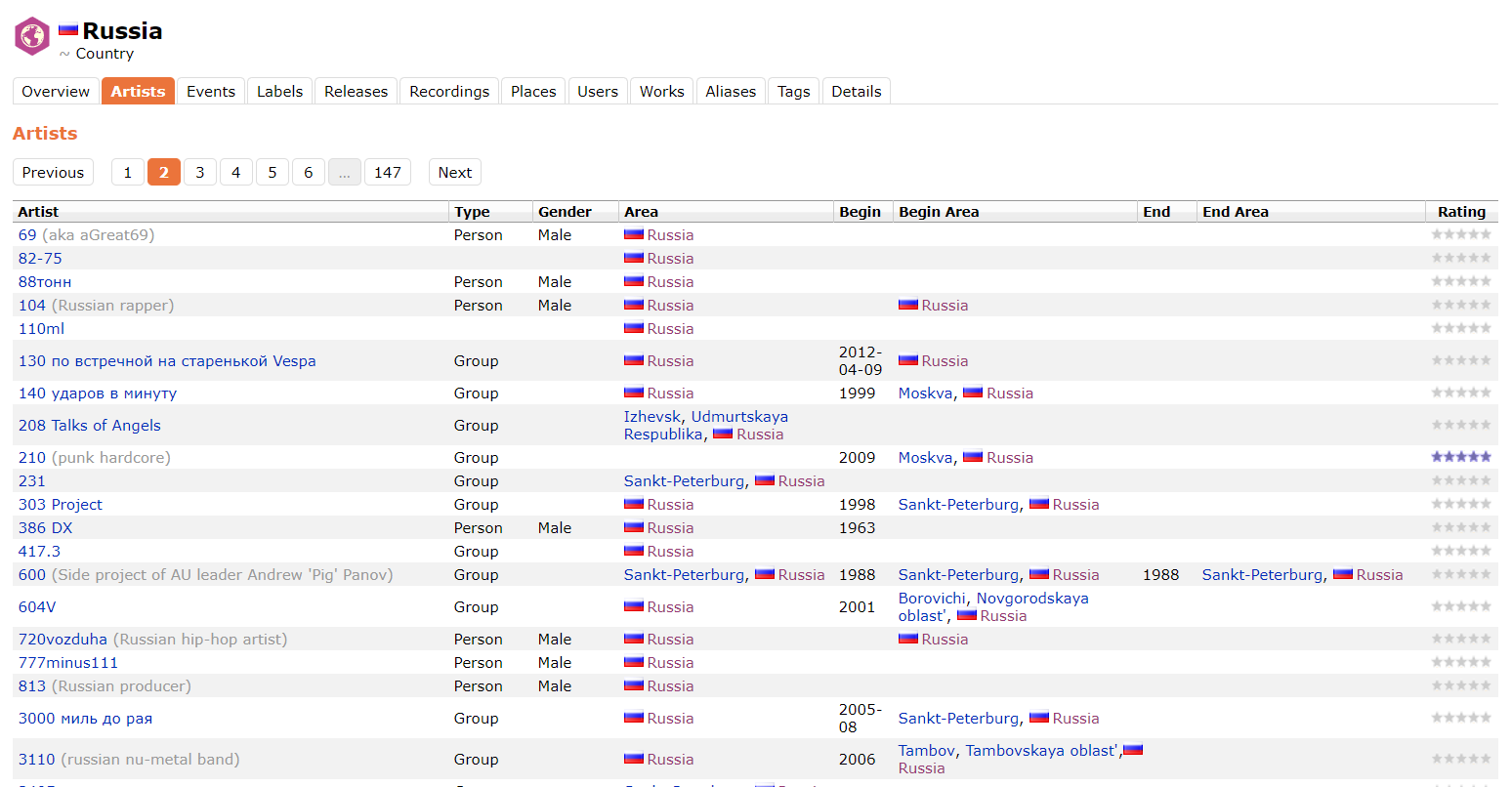
Data yang diperoleh tentang artis Musicbrainz.
Bidang lainnya diperoleh sebagai hasil dari permintaan GET ke titik akhir . Saat mengirim permintaan, tentukan nama artis di nilai parameter q, dan tentukan artis di nilai parameter type.
Mengumpulkan data tentang trek populer
Tabel tersebut berisi 44473 rekaman trek paling populer oleh artis Rusia, disajikan pada tabel di atas. Di bawah spoiler terdapat keterangan kolom tabel.
Deskripsi bidang tabel
artist – ;
artist_spotify_id – Spotify ( , spotify_id );
name – ;
spotify_id – Spotify;
duration_ms – ;
explicit – , true false;
popularity – Spotify *;
album_type – , album, single compilation;
album_name – ;
album_spotify_id – Spotify;
release_date – ;
album_popularity – Spotify.
artist_spotify_id – Spotify ( , spotify_id );
name – ;
spotify_id – Spotify;
duration_ms – ;
explicit – , true false;
popularity – Spotify *;
album_type – , album, single compilation;
album_name – ;
album_spotify_id – Spotify;
release_date – ;
album_popularity – Spotify.
Fitur Audio
key – , , 0 = C, 1 = C♯/D♭, 2 = D ..;
mode – , – 1, – 0;
time_signature – ;
acousticness – 0,0 1,0 , ;
danceability – , 0,0 1,0;
energy – 0,0 1,0;
instrumentalness – , , 0,0 1.0;
liveness – , 0,0 1,0;
loudness – , -60 0 ;
speechiness – , 0,0 1,0;
valence – «», , 0,0 1,0;
tempo – .
mode – , – 1, – 0;
time_signature – ;
acousticness – 0,0 1,0 , ;
danceability – , 0,0 1,0;
energy – 0,0 1,0;
instrumentalness – , , 0,0 1.0;
liveness – , 0,0 1,0;
loudness – , -60 0 ;
speechiness – , 0,0 1,0;
valence – «», , 0,0 1,0;
tempo – .
Anda dapat membaca lebih lanjut tentang setiap parameter di sini .

Contoh rekaman Nama
bidang, spotify_id, durasi_ms, eksplisit, popularitas, jenis_ album, nama_ album, album_spotify_id, tanggal_ rilis diperoleh menggunakan permintaan GET untuk
https://api.spotify.com/v1//v1/artists/{id}/top-tracks
, menentukan id id Spotify artis yang kami terima sebelumnya, dan dalam nilainya dari parameter pasar kami tentukan RU. Dokumentasi .
Bidang album_popularity dapat diperoleh dengan membuat permintaan GET
https://api.spotify.com/v1/albums/{id}
, menentukan album_spotify_id yang diperoleh sebelumnya sebagai nilai untuk parameter id. Dokumentasi .
Hasilnya, kami mendapatkan datatentang lagu terbaik dari artis Spotify. Sekarang tantangannya adalah mendapatkan fitur audio. Ini dapat dilakukan dengan dua cara:
- Untuk mendapatkan data tentang satu lagu, Anda perlu membuat permintaan GET
https://api.spotify.com/v1/audio-features/{id}
, dengan menentukan ID Spotify-nya sebagai nilai parameter id. Dokumentasi .
- Untuk mendapatkan data tentang beberapa trek sekaligus, Anda harus mengirim permintaan GET ke
https://api.spotify.com/v1/audio-features
, meneruskan ID Spotify trek ini yang dipisahkan dengan koma sebagai nilai untuk parameter id. Dokumentasi .
Semua skrip ada di repositori di tautan ini .
Setelah mengumpulkan data, dilakukan analisis pendahuluan yang divisualisasikan di bawah ini.
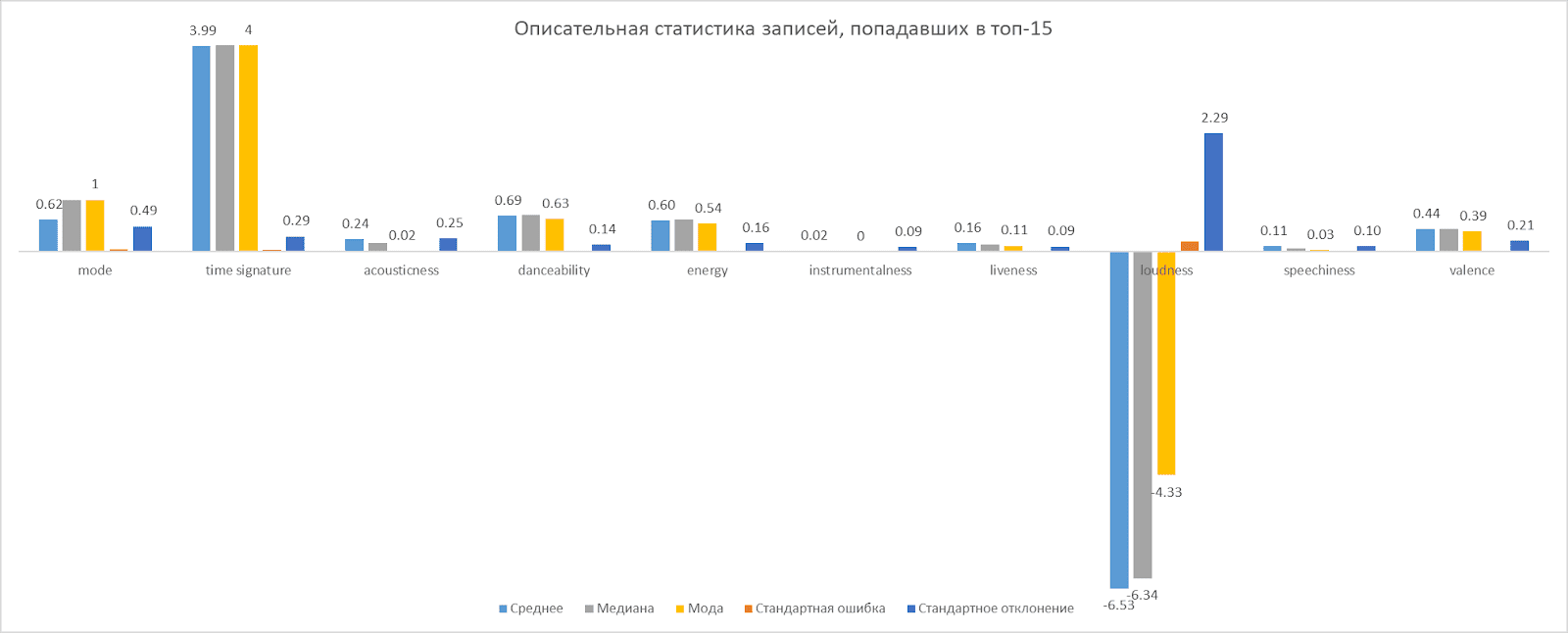
Hasil
Hasilnya, kami berhasil mengumpulkan data pada 14363 artis dan 44473 lagu. Dengan menggabungkan data dari MusicBrainz dan Spotify, kami memperoleh kumpulan data terlengkap hingga saat ini dari semua artis musik Rusia yang diwakili di platform Spotify.
Dataset seperti itu akan memungkinkan pembuatan produk B2B dan B2C di bidang musik. Misalnya, sistem merekomendasikan artis kepada promotor yang konsernya dapat diatur atau sistem untuk membantu artis muda menulis lagu yang lebih mungkin menjadi populer. Selain itu, dengan pengisian ulang kumpulan data secara teratur dengan data baru, Anda dapat menganalisis berbagai tren dalam industri musik, seperti pembentukan dan pertumbuhan popularitas tren tertentu dalam musik, atau menganalisis artis individu. Dataset itu sendiri dapat dilihat di GitHub .
Set Data 2: Kami meneliti pasar kerja dan mengidentifikasi keterampilan utama dengan "Landak jelas"
Berbaris:
- Andrey Pshenichny - mengumpulkan dan memproses data, menulis catatan analitis pada dataset.
- Pavel Kondratenok - Manajer Produk, pengumpulan data dan deskripsi prosesnya, GitHub.
- Svetlana Shcherbakova - pengumpulan dan pemrosesan data.
- Evseeva Oksana - persiapan presentasi akhir proyek.
- Elfimova Anna - Manajer Proyek.
Untuk kumpulan data kami, kami memilih ide mengumpulkan data tentang lowongan di Rusia dari bidang TI dan Telekomunikasi dari situs hh.ru untuk Oktober 2020.
Pengumpulan data keterampilan
Metrik terpenting untuk semua kategori pengguna adalah Keterampilan Utama. Namun, saat menganalisisnya, kami menemui kesulitan: saat mengisi data lowongan, HR memilih keterampilan utama dari daftar, dan juga dapat memasukkannya secara manual, dan oleh karena itu, sejumlah besar keterampilan duplikat dan keterampilan yang salah masuk ke dalam kumpulan data kami (misalnya , kami menemukan nama keterampilan kunci "0,4 Kb"). Ada satu kesulitan lagi yang menyebabkan masalah saat menganalisis dataset yang dihasilkan - hanya sekitar setengah dari lowongan yang berisi data tentang gaji, tetapi kita dapat menggunakan indikator gaji rata-rata dari sumber lain (misalnya, dari sumber My Circle atau Habr.Career).
Kami mulai dengan akuisisi data dan analisis mendalam. Selanjutnya, kami mengambil sampel data, yaitu, kami memilih fitur (fitur atau, dengan kata lain, prediktor) dan objek, dengan mempertimbangkan relevansinya untuk tujuan Data Mining, kendala kualitas dan teknis (volume dan jenis).
Di sini kami dibantu oleh analisis frekuensi menyebutkan keterampilan dalam tag keterampilan yang dibutuhkan dalam deskripsi pekerjaan, karakteristik lowongan apa yang mempengaruhi imbalan yang diusulkan. Pada saat yang sama, 8915 keterampilan kunci diidentifikasi. Di bawah ini adalah bagan yang menunjukkan 10 keterampilan kunci teratas dan seberapa sering keterampilan itu disebutkan.
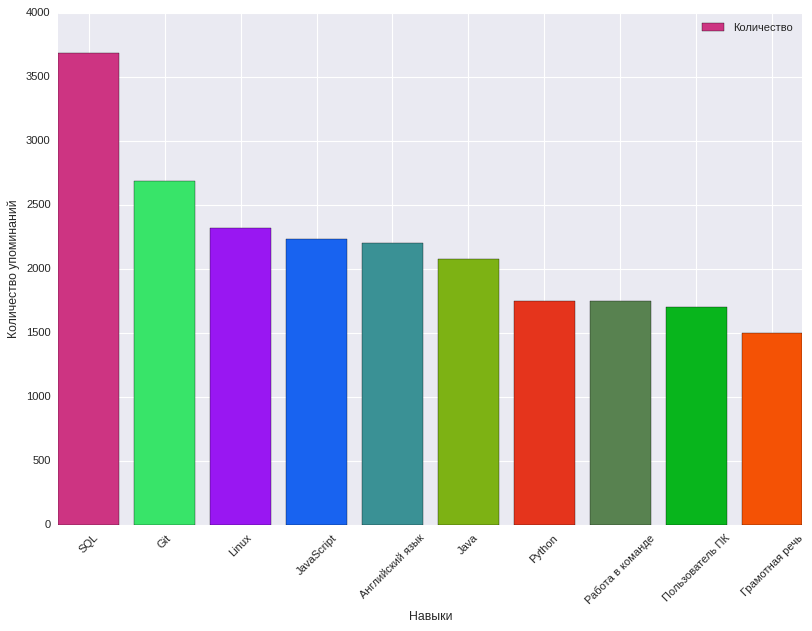
Keterampilan utama yang paling umum dalam lowongan TI, Telecom
Data diperoleh dari situs web hh.ru menggunakan API mereka. Kode untuk mengunggah data dapat ditemukan di sini . Kami telah memilih secara manual fitur yang kami butuhkan untuk dataset. Struktur dan jenis data yang dikumpulkan dapat dilihat pada deskripsi dokumentasi untuk dataset tersebut.
Setelah manipulasi tersebut, didapatkan Dataset dengan ukuran 34.513 baris. Anda dapat melihat contoh data yang dikumpulkan di bawah ini, dan juga menemukan tautannya .

Sampel data dikumpulkan
Hasil
Hasilnya adalah kumpulan data yang dengannya Anda dapat mengetahui keterampilan apa yang paling diminati di antara spesialis TI di berbagai bidang, dan dapat berguna untuk pencari kerja (baik pemula maupun berpengalaman), pemberi kerja, spesialis SDM, organisasi pendidikan, dan penyelenggara. konferensi. Dalam proses pengumpulan data juga terdapat kesulitan: terlalu banyak rambu-rambu dan ditulis dengan bahasa formal yang rendah (uraian keterampilan calon), separuh dari lowongan tidak memiliki open data tentang gaji. Dataset itu sendiri dapat dilihat di GitHub .
Set data 3: Nikmati variasi kucing dengan Tim AA
Berbaris:
- Evgeny Ivanov - pengembangan web scraping.
- Sergey Gurylev - manajer produk, deskripsi proses pengembangan, GitHub.
- Yulia Cherganova - persiapan presentasi proyek, analisis data.
- Elena Tereshchenko - persiapan data, analisis data.
- Yuri Kotelenko - manajer proyek, dokumentasi, presentasi proyek.
Kumpulan data yang didedikasikan untuk kucing? Mengapa tidak, pikir kami. Catset kami berisi gambar sampel kucing dari berbagai ras.
Mengumpulkan data kucing
Awalnya, kami memilih catfishes.ru untuk mengumpulkan data , ia memiliki semua keuntungan yang kami butuhkan: ini adalah sumber gratis dengan struktur HTML sederhana dan gambar berkualitas tinggi. Terlepas dari keunggulan situs ini, situs ini memiliki kekurangan yang signifikan - sejumlah kecil foto secara umum (sekitar 500 untuk semua ras) dan sejumlah kecil gambar untuk setiap ras. Oleh karena itu, kami memilih situs lain - lapkins.ru .

Karena struktur HTML yang sedikit lebih rumit, menyalin situs kedua sedikit lebih sulit daripada yang pertama, tetapi struktur HTML mudah dipahami. Hasilnya, kami berhasil mengumpulkan 2600 foto semua keturunan dari situs kedua.
Kami bahkan tidak perlu memfilter data, karena foto-foto kucing di situs tersebut berkualitas baik dan sesuai dengan rasnya.
Untuk mengumpulkan gambar dari situs tersebut, kami menulis web scraper. Situs tersebut berisi halaman lapkins.ru/cat dengan daftar semua ras. Setelah mem-parsing halaman ini, kami mendapatkan nama semua trah dan link ke halaman untuk setiap trah. Setelah mengulang secara berulang melalui setiap bebatuan, kami mendapatkan semua gambar dan menempatkannya di folder yang sesuai. Kode scraper diimplementasikan dengan Python menggunakan pustaka berikut:
- urllib : berfungsi dengan URL;
- html : berfungsi untuk memproses XML dan HTML;
- Shutil : fungsi tingkat tinggi untuk menangani file, kelompok file dan folder;
- OS : berfungsi untuk bekerja dengan sistem operasi.
Kami menggunakan XPath untuk bekerja dengan tag.
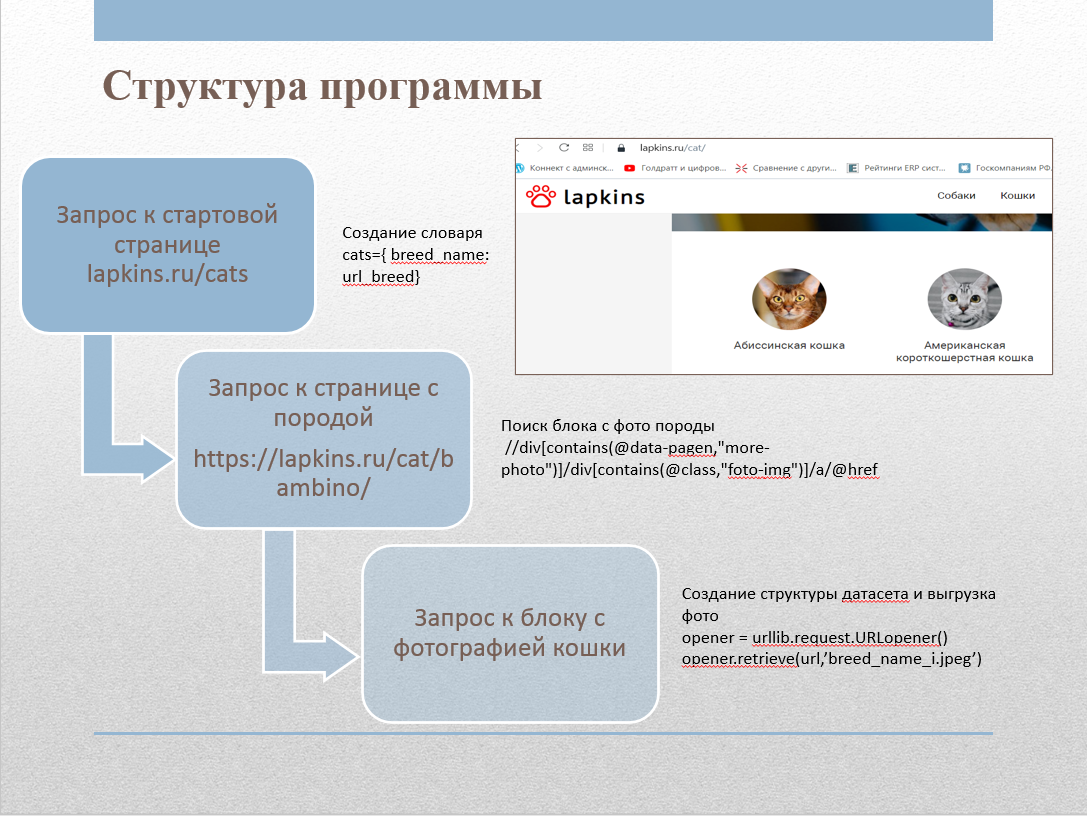
Direktori Cats_lapkins berisi folder yang namanya sesuai dengan nama ras kucing. Repositori berisi 64 direktori untuk setiap trah. Secara total, dataset tersebut berisi 2600 gambar. Semua gambar dalam format .jpg. Format nama file: misalnya "Abyssinian cat 2.jpg", pertama muncul nama trah, lalu nomor - nomor seri sampel.

Hasil
Dataset semacam itu dapat, misalnya, digunakan untuk melatih model yang mengklasifikasikan kucing domestik berdasarkan ras. Data yang dikumpulkan dapat digunakan untuk tujuan berikut: menentukan karakteristik merawat kucing, memilih makanan yang cocok untuk kucing dari ras tertentu, serta mengoptimalkan identifikasi utama ras di pertunjukan dan saat penjurian. Cotoset juga dapat digunakan oleh bisnis - klinik hewan dan produsen pakan. Cotoset itu sendiri tersedia secara gratis di GitHub .
Kata Penutup
Berdasarkan hasil dataton, siswa kami menerima kasus pertama dalam portofolio data scientist dan umpan balik tentang pekerjaan dari mentor dari perusahaan seperti Huawei, Kaspersky Lab, Align Technology, Auriga, Intellivision, Wrike, Merlin AI. Dataton juga berguna karena dia segera memompa profil hard skill dan soft skill yang dibutuhkan oleh data scientist di masa depan ketika mereka sudah akan bekerja dalam tim nyata. Ini juga merupakan kesempatan yang baik untuk saling "pertukaran pengetahuan", karena setiap siswa memiliki latar belakang yang berbeda dan, karenanya, pandangannya sendiri tentang masalah dan kemungkinan solusinya. Kami dapat mengatakan dengan yakin bahwa tanpa kerja praktek seperti itu, serupa dengan beberapa tugas bisnis yang sudah ada, pelatihan para spesialis di dunia modern sama sekali tidak terpikirkan.
Anda dapat mengetahui lebih lanjut tentang program master kami di situs web data.misis.ru dan di saluran Telegram .
Ya, dan, tentu saja, tidak ada satu pun gelar master! Jika Anda ingin mempelajari lebih lanjut tentang Ilmu Data , Pembelajaran Mesin , dan Pembelajaran Mendalam - lihat kursus kami yang sesuai, ini akan sulit, tetapi mengasyikkan. Dan kode promo HABR akan membantu Anda mempelajari hal - hal baru dengan menambahkan diskon 10% pada banner.

Profesi dan kursus lainnya