Jaringan saraf performa tinggi yang dalam untuk data tabular TabNet
pengantar
Jaringan saraf dalam (GNN) telah menjadi salah satu alat yang paling menarik untuk membuat sistem kecerdasan buatan (SRI), misalnya, pengenalan suara, komunikasi alami, penglihatan komputer [2-3], dll. Secara khusus, karena pemilihan otomatis GNS penting, mendefinisikan fitur, koneksi dari data. Arsitektur jaringan saraf (neokognitronik, konvolusional, kepercayaan mendalam, dll.), Model dan algoritme untuk mempelajari GNS (pembuat kode otomatis, mesin Boltzmann, pengulangan terkontrol, dll.) Sedang berkembang. GNS sulit untuk dilatih, terutama karena masalah gradien yang menghilang.
Artikel ini membahas arsitektur kanonik GNS baru untuk data tabular (TabNet), yang dirancang untuk menampilkan "pohon keputusan". Tujuannya adalah untuk mewarisi keuntungan dari metode hierarki (interpretabilitas, pemilihan fitur yang jarang) dan metode berbasis GNS (pembelajaran langkah demi langkah dan ujung ke ujung). Secara khusus, TabNet menangani dua kebutuhan utama - kinerja tinggi dan interpretabilitas. Performa tinggi seringkali tidak cukup - GNS harus menafsirkan, mengganti metode seperti pohon.
TabNet adalah jaringan neural dari lapisan yang sepenuhnya terhubung dengan mekanisme perhatian sekuensial yang:
menggunakan pilihan objek yang jarang oleh instance, yang diperoleh dari set data pelatihan;
membuat arsitektur multistage sekuensial di mana setiap langkah keputusan dapat berkontribusi pada bagian keputusan yang didasarkan pada fungsi yang dipilih;
meningkatkan kemampuan belajar melalui transformasi non-linier dari fungsi yang dipilih;
mensimulasikan ansambel, yang melibatkan pengukuran yang lebih akurat dan lebih banyak langkah peningkatan.
Setiap lapisan dari arsitektur tertentu (Gbr. 1) adalah langkah solusi yang berisi blok dengan lapisan yang sepenuhnya terhubung untuk mengubah karakteristik - Transformator Fitur dan mekanisme perhatian untuk menentukan pentingnya karakteristik asli masukan.

1. Pengubah fungsi
1.1. Normalisasi batch
- . . , (, ), , . (covariate shift).
. , — . ( ) , . , , , .
. , — , . , , ( , – ) . . - (batch normalization), 2015 [4].
- .
1. d: x = (x1, . . . , xd). k- x ( ):

2. . , . , , (

[−1, 1] ).
, :

γ, β .
3. , , -,


4. .
-:
, , ;
, ;
, ;
.
1.2. GLU
[5] Gated Linear Unit, , , LSTM-.
GLU
, , , . H = [h0 ,..., hN] w0, ... ,wN, P (wi |hi). f H hi = f(hi - 1 , wi - 1) , i ( , ).
f H = f * w , , , , , . . , , [5] , , .
. 2 . , D |V| x e, |V| - ( ), e - . w0, … , wN, E = [Dw0, … , DwN]. h0 , …hL

m, n – , , k - , X ∈ R N×m - hl ( , ),
, σ - ⊗ .
, hi . , . , k-1, , - , , k - .

X * W + b, σ(X * V + c). LSTM, X * W + b , . (GLU). E H = hL◦. . .◦h0 (E).
(GLU) , .
3.3 LSTM
LSTM (long short-term memory, – ) — , . LSTM , , [5].
LSTM . — , !
. , , tanh.
LSTM
LSTM .
LSTM , . , « ». h x 0 1 C. 1 « », 0 — « ».
. , . , . , .
, . . , « », , . tanh - C, . .
, .
C. , .
f, , . i*C. , , .
, .
, , . . , , . tanh ( [-1, 1]) .
, , , . , , ( ) .
TabNet

3.4. Split:
Feature Transformer , . , , Attentive Transformer , . (backpropagation) , «» , ( ). , . , Attentive Transformer . , "" , , .
SPLIT
: (. . 1) .
, , ( ), , .
. 3 . FC BN (GLU) , . √0.5 , , . . BN, , , BN BV mB. , , BN. , , . 3,
:
. softmax ( argmax ).
4.
. (), ( ) Softmax, , , : , - , — .
, , ht, t=1 …m, d , .
C d di−1 .
s — hi « ».
, s softmax. e=softmax(s)
softmax :
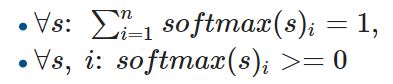
:

cc , hi ei.
. , , , , , . Softmax, Sparsemax. , , - , Softmax , . «» «» , - .
5. SPARSEMAX
, z z, . :

τ(z) S(z), p. softmax , , , softmax .
, . softmax , sparsemax :
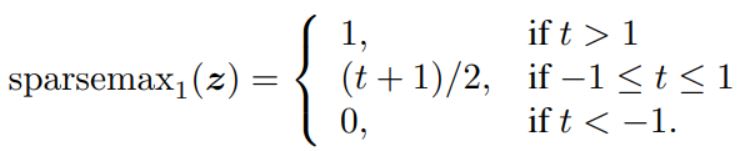
, :

, sparsemax , , :

|S(z)| - S(z).
, , , , Sparsemax.
,
6.
, , , , - . . , , . ( ), () , , , .
:
. , , , , . : M[i] · f. (. . 1) , , a[i − 1]:
Sparsemax [6] , .
,
h[i] - , . 4., FC, BN, P[i] - , , :

γ - : γ = 1, γ, . P[0] ,
- . ( ), P[0] , . :
ϵ - . λ, , .
, , . , , , - . , [5] , .
TabNet - . TabNet . , () , .
, , , .
.. // . : . 2017. .6, №3. .28–59. DOI: 10.14529/cmse170303
LeCun Y., Bengio Y., Hinton G. Deep Learning // Nature. 2015. Vol.521. Pp.436–444. DOI: 10.1038/nature14539.
Rav`ı D., Wong Ch., Deligianni F., et al. Deep Learning for Health Informatics // IEEE Journal of Biomedical and Health Informatics. 2017. Vol.21, No.1. PP.4–21. DOI: 10.1109/JBHI.2016.2636665.
Sergey Ioffe, Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal // Proceedings of The 32nd International Conference on Machine Learning (2015), pp.448-456.
Sercan O. Arik, Tomas Pfister. TabNet: Attentive Interpretable Tabular Learning // ICLR 2020 Conference Blind Submission 25 Sept 2019 (modified: 24 Dec 2019). URL:https://drive.google.com/file/d/1oLQRgKygAEVRRmqCZTPwno7gyTq22wbb/view?usp=sharing
Andre F. T. Martins and Ram´on Fern´andez Astudillo. 2016. From Softmax´ to Sparsemax: A Sparse Model of Attention and Multi-Label Classification. arXiv:1602.02068.