
Postingan ini bisa dilihat sebagai pengerjaan ulang materi restorasi melalui deep learning untuk teman-teman atau pemula. Saya telah menulis lebih dari 10 posting terkait dengan pendekatan restorasi gambar menggunakan pembelajaran mendalam. Sekarang adalah waktunya untuk tinjauan singkat tentang apa yang telah dipelajari para pembaca artikel ini, serta untuk menulis pengantar singkat bagi para pemula yang ingin bersenang-senang dengan kami.
Terminologi

Angka: 1. Contoh citra input yang rusak (kiri) dan hasil restorasi (kanan). Gambar diambil dari halaman Github penulis.
Input yang rusak yang ditunjukkan pada Gambar 1 biasanya mengidentifikasi: a) piksel yang tidak valid, hilang atau lubang sebagai piksel yang terletak di area yang akan diisi; b) benar, tersisa, piksel nyata yang dapat kita gunakan untuk mengisi piksel yang hilang. Perhatikan bahwa kita dapat mengambil piksel yang benar dan mengisi ruang terkait.
pengantar
Cara termudah untuk mengisi bagian yang hilang adalah dengan menyalin dan menempel. Ide utamanya adalah menelusuri terlebih dahulu untuk menemukan bagian gambar yang paling mirip dari piksel yang tersisa, atau menemukannya dalam kumpulan data besar dengan jutaan gambar, lalu langsung memasukkan potongan tersebut ke bagian yang hilang. Namun, algoritme pencarian dapat memakan waktu dan menyertakan metrik pengukuran jarak yang dibuat secara manual. Generalisasi algoritma dan efisiensinya masih perlu ditingkatkan.
Dengan pendekatan pembelajaran mendalam di era data besar, kami memiliki pendekatan berbasis data untuk pemulihan pembelajaran mendalam, dengan pendekatan ini kami menghasilkan piksel yang jatuh dengan konsistensi yang baik dan tekstur yang halus. Mari kita lihat 10 pendekatan pembelajaran mendalam yang terkenal untuk restorasi gambar. Saya yakin Anda dapat memahami artikel lain jika Anda memahami artikel ini 10. Mari kita mulai.
Encoder konteks (algoritme pemulihan berbasis GAN pertama, 2016)

Angka: 2. Arsitektur jaringan encoder kontekstual (CE).
Encoder konteks (CE, 2016) [1] adalah implementasi pertama dari restorasi berbasis GAN. Pekerjaan ini mencakup konsep dasar yang berguna dari tugas restorasi. Konsep "konteks" dikaitkan dengan pemahaman gambar seperti itu, inti dari ide pembuat enkode adalah lapisan yang terhubung sepenuhnya oleh saluran (lapisan tengah jaringan ditunjukkan pada Gambar 2). Seperti sebuah layer yang terhubung sepenuhnya standar, poin utamanya adalah bahwa semua lokasi item pada layer sebelumnya akan berkontribusi pada setiap lokasi item pada layer saat ini. Jadi jaringan mempelajari hubungan antara semua pengaturan elemen dan mendapatkan representasi semantik yang lebih dalam dari keseluruhan gambar. CE dianggap baseline, Anda dapat membaca lebih lanjut tentang itu di posting saya [di sini ].
MSNPS ( )

. 3. ( CE) (VGG-19).
(MSNPS, 2016) [3] dapat dilihat sebagai versi lanjutan dari CE [1]. Penulis artikel ini menggunakan CE yang dimodifikasi untuk memprediksi bagian yang hilang pada gambar dan jaringan tekstur untuk menghiasi prediksi guna meningkatkan kualitas bagian yang hilang dari model yang diisi. Ide jaringan tekstur diambil dari tugas mentransfer gaya. Kami ingin mengatur gaya piksel yang ada yang paling mirip dengan piksel yang dihasilkan untuk meningkatkan detail tekstur lokal. Saya akan mengatakan bahwa pekerjaan ini adalah versi awal dari struktur jaringan kasar-ke-halus dua tahap. Jaringan konten pertama (yaitu di sini CE) bertanggung jawab untuk merekonstruksi / memprediksi bagian yang hilang, dan jaringan kedua (yaitu jaringan tekstur) bertanggung jawab untuk menyempurnakan bagian yang diisi.
Selain kehilangan rekonstruksi piksel yang khas (yaitu, kehilangan L1) dan kerugian adversarial standar, konsep kehilangan tekstur yang diusulkan dalam artikel ini memainkan peran penting dalam pekerjaan restorasi citra selanjutnya. Faktanya, kehilangan tekstur dikaitkan dengan hilangnya persepsi dan gaya, yang banyak digunakan dalam banyak tugas pembuatan gambar seperti transfer gaya saraf. Untuk mengetahui lebih lanjut tentang artikel ini, Anda dapat merujuk ke posting saya sebelumnya [di sini ].
GLCIC (pencapaian dalam restorasi pembelajaran mendalam, 2017)
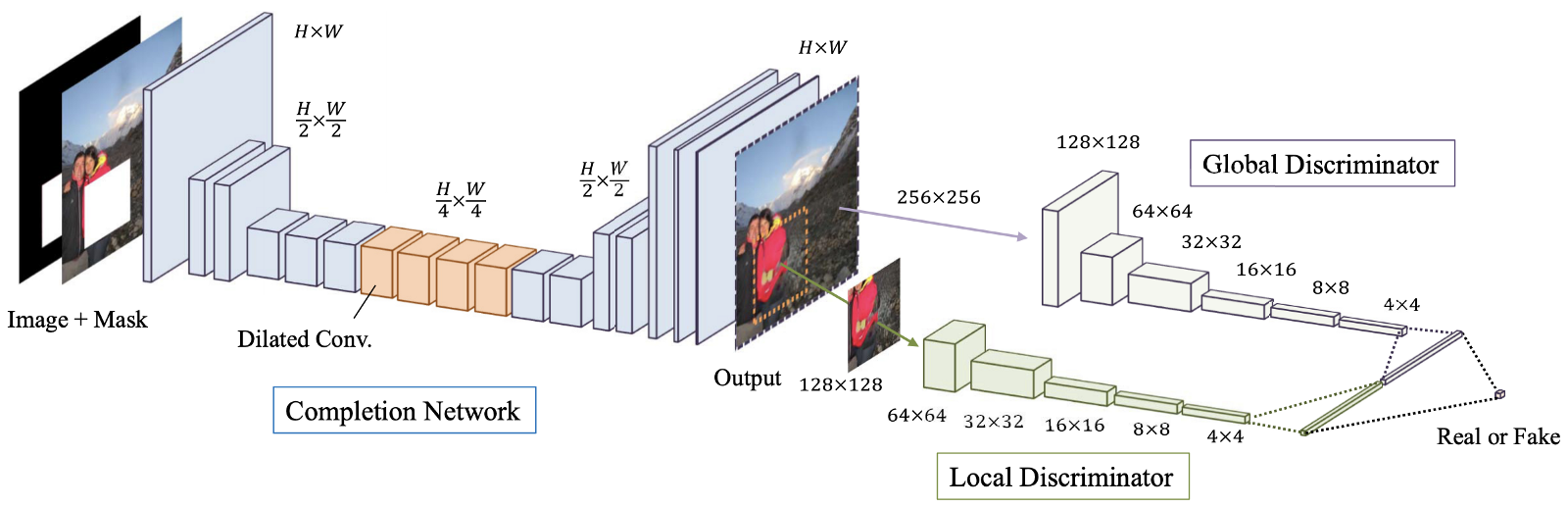
Angka: 4. Gambaran umum dari model yang diusulkan, yang terdiri dari jaringan terminal (jaringan "Generator"), serta diskriminator global dan lokal.
Penyelesaian Gambar yang Konsisten Secara Global dan Lokal (GLCIC, 2017) [4] adalah tonggak penting dalam pemulihan gambar pembelajaran yang mendalam karena mendefinisikan jaringan konvolusional yang diperluas sepenuhnya konvolusional untuk area ini dan pada kenyataannya merupakan arsitektur jaringan yang khas dalam pemulihan gambar. Dengan menggunakan konvolusi lanjutan, jaringan dapat memahami konteks gambar tanpa menggunakan lapisan yang sepenuhnya terhubung dan mahal, sehingga dapat menangani gambar dengan ukuran berbeda.
Selain jaringan konvolusional penuh dengan konvolusi diperpanjang, dua diskriminator pada dua skala juga dilatih bersama dengan jaringan generator. Diskriminator global melihat seluruh gambar, sedangkan diskriminator lokal melihat area tengah yang diisi. Dengan diskriminator global dan lokal, citra yang diisi memiliki konsistensi global dan lokal yang lebih baik. Perhatikan bahwa banyak artikel terbaru tentang pemulihan gambar mengikuti desain diskriminator multiskala ini. Jika Anda tertarik, silakan baca posting saya sebelumnya [di sini ] untuk informasi lebih lanjut.
Restorasi berbasis patch GAN (variasi GLCIC, 2018)

Angka: 5. Usulan arsitektur ResNet generatif dan diskriminator PGGAN.
Restorasi berbasis patch menggunakan GAN [5] dapat dianggap sebagai varian dari GLCIC [4]. Sederhananya, dua konsep lanjutan, pembelajaran sisa [6] dan PatchGAN [7], dibangun ke dalam GLCIC untuk lebih meningkatkan kinerja. Penulis artikel ini telah menggabungkan sambungan sisa dan konvolusi yang diperpanjang untuk membentuk blok sisa yang diperpanjang. Diskriminator GAN tradisional telah digantikan oleh diskriminator PatchGAN untuk mempromosikan detail tekstur lokal yang lebih baik dan konsistensi global.
Perbedaan utama antara diskriminator GAN tradisional dan diskriminator PatchGAN adalah bahwa diskriminator GAN tradisional hanya memberikan satu label prediktif (0 hingga 1) untuk menunjukkan realisme sinyal input, sedangkan diskriminator PatchGAN memberikan matriks label (juga 0 hingga 1) ) untuk menunjukkan realisme setiap area lokal dari sinyal input. Perhatikan bahwa setiap elemen matriks mewakili area lokal dari data masukan. Anda juga dapat melihat gambaran umum pembelajaran sisa dan PatchGAN [dengan mengunjungi posting saya ].
Shift-Net (Salin dan Tempel Deep Learning, 2018)

Angka: 6. Arsitektur jaringan Shift-Net. Lapisan join-slip ditambahkan pada resolusi 32x32.
Shift-Net [8] memanfaatkan kedua CNN berbasis data modern dan metode "salin dan tempel" tradisional untuk mempartisi ulang elemen secara mendalam menggunakan lapisan gabungan pergeseran yang diusulkan. Ada dua ide utama dalam artikel ini.
Pertama, penulis telah mengusulkan hilangnya tengara yang menyebabkan elemen yang diterjemahkan dari bagian yang hilang (mengingat bagian tersembunyi dari gambar) menjadi dekat dengan elemen kode dari bagian yang hilang (mengingat keadaan gambar yang baik). Hasilnya, proses decoding dapat menggantikan bagian yang hilang dengan perkiraan yang masuk akal pada gambar dalam kondisi baik (yaitu, sumber kebenaran untuk bagian yang hilang).
Kedua, lapisan join-shift yang diusulkan memungkinkan jaringan untuk secara efisien meminjam informasi yang disediakan oleh tetangga terdekatnya di luar bagian yang hilang untuk menyempurnakan struktur semantik global dan detail tekstur lokal dari bagian yang dihasilkan. Sederhananya, kami menyediakan tautan terkait untuk menyempurnakan penilaian kami. Saya pikir pembaca yang tertarik dengan restorasi gambar akan merasa terbantu dengan mengkonsolidasikan ide-ide yang disarankan dalam artikel ini. Saya sangat menyarankan Anda membaca posting sebelumnya [di sini ] untuk detailnya.
DeepFill v1 (Breakthrough Image Restoration, 2018)

Angka: 7. Arsitektur jaringan kerangka yang diusulkan.
Pemulihan generatif dengan perhatian kontekstual (CA, 2018), juga disebut DeepFill v1 atau CA [9], dapat dilihat sebagai versi diperpanjang atau varian dari Shift-Net [8]. Para penulis mengembangkan gagasan salin dan tempel dan menawarkan lapisan perhatian kontekstual yang dapat dibedakan dan sepenuhnya konvolusional.
Mirip dengan layer join-shift di [8], dengan mencocokkan elemen yang dihasilkan di dalam piksel yang hilang dan karakteristik di luar piksel yang hilang, kita dapat mengetahui kontribusi semua elemen di luar piksel yang hilang ke setiap lokasi di dalam piksel yang hilang. Oleh karena itu, kombinasi dari semua elemen di luar dapat digunakan untuk memperbaiki elemen yang dihasilkan di dalam piksel yang hilang. Dibandingkan dengan lapisan join-shear, yang hanya mencari fitur yang paling mirip (mis., Penetapan yang keras dan tidak dapat dibedakan), lapisan CA dalam artikel ini menggunakan penetapan yang lembut dan dapat dibedakan, di mana semua fitur memiliki bobotnya sendiri untuk menunjukkan kontribusinya terhadap setiap tempat di dalam piksel yang hilang. Untuk mempelajari lebih lanjut tentang perhatian kontekstual, silakan baca posting saya sebelumnya [ di sini], di sana Anda akan menemukan contoh yang lebih spesifik.
GMCNN (CNN Multi-Kolom untuk Pemulihan Gambar, 2018)

Angka: 8. Arsitektur jaringan yang diusulkan.
Generative Multicolumn Convolutional Neural Networks (GMCNN, 2018) [10] memperluas pentingnya bidang reseptif yang memadai untuk restorasi gambar dan menawarkan fungsi kerugian baru untuk lebih meningkatkan detail tekstur lokal dari konten yang dihasilkan. Seperti yang ditunjukkan pada Gambar 9, ada tiga cabang / kolom dan setiap cabang menggunakan tiga ukuran filter yang berbeda. Penggunaan beberapa field reseptif (ukuran filter) disebabkan oleh fakta bahwa ukuran field reseptif penting untuk tugas restorasi gambar. Karena tidak ada piksel tetangga lokal, informasi dari lokasi yang jauh secara spasial perlu dipinjam untuk mengisi piksel lokal yang hilang.
Untuk fungsi kerugian yang diusulkan, ide dasar di balik kerugian Implicit Diversified Markov Random Field (ID-MRF) adalah mengarahkan patch elemen yang dihasilkan untuk menemukan tetangga terdekatnya di luar area yang dilewati sebagai referensi, dan tetangga terdekat ini harus cukup beragam untuk memodelkan lebih banyak detail tekstur lokal. Faktanya, kerugian ini adalah versi yang disempurnakan dari kehilangan tekstur yang digunakan dalam MSNPS [3]. Saya sangat menyarankan Anda membaca posting saya [di sini ] untuk penjelasan rinci tentang kerugian ini.
PartialConv (mendorong batasan restorasi melalui pembelajaran mendalam untuk rongga tak beraturan, 2018)

. 9. , .
(PartialConv atau PConv) [11] mendorong batas pembelajaran mendalam dalam pemulihan gambar dengan menawarkan cara untuk menangani gambar laten dengan beberapa lubang tidak beraturan. Jelas, ide utama artikel ini adalah melipat sebagian. Saat menggunakan PConv, hasil konvolusi hanya akan bergantung pada piksel yang diizinkan, jadi kami memiliki kendali atas informasi yang dikirimkan dalam jaringan. Ini adalah pekerjaan pemulihan gambar pertama untuk mengatasi kekosongan yang tidak teratur. Harap dicatat bahwa model restorasi sebelumnya dilatih untuk memperbaiki citra yang rusak, jadi model ini tidak cocok untuk citra restorasi dengan rongga yang salah.
Saya telah memberikan contoh sederhana untuk menjelaskan dengan jelas bagaimana pelipatan parsial dilakukan di posting saya sebelumnya [ di sini]. Kunjungilah tautan untuk info detailnya. Saya harap Anda akan menikmati.
EdgeConnect - Garis Besar Pertama, Warna Kemudian, 2019

Angka: 10. Arsitektur jaringan EdgeConnect. Seperti yang Anda lihat, ada dua generator dan dua diskriminator.
EdgeConnect[12]: Pemulihan Citra Generatif Menggunakan Pembelajaran Tepi Adversarial (EdgeConnect) [12] menyajikan cara yang menarik untuk menyelesaikan masalah restorasi citra. Ide utama artikel ini adalah membagi tugas restorasi menjadi dua langkah yang disederhanakan, yaitu memprediksi tepi dan menyelesaikan gambar berdasarkan peta tepi yang diprediksi. Tepi di area yang hilang diprediksi terlebih dahulu, lalu gambar selesai sesuai dengan prediksi tepi. Sebagian besar metode yang digunakan dalam artikel ini telah dibahas di posting saya sebelumnya. Gambaran yang baik tentang bagaimana berbagai teknik dapat digunakan bersama untuk membentuk pendekatan baru untuk restorasi gambar pembelajaran mendalam. Mungkin Anda akan mengembangkan model restorasi Anda sendiri. Silakan lihat posting saya sebelumnya [di sini ] untuk mempelajari lebih lanjut tentang artikel ini.
DeepFill v2 (Pendekatan Praktis untuk Pemulihan Gambar Generatif, 2019)

Angka: 11. Gambaran umum arsitektur jaringan model untuk pemulihan gratis.
Restorasi bentuk bebas dengan Gated Convolution(DeepFill v2 atau GConv, 2019) [13]. Ini mungkin algoritme pemulihan gambar paling praktis yang dapat digunakan secara langsung dalam aplikasi Anda. Ini dapat dianggap sebagai versi peningkatan dari DeepFill v1 [9], konvolusi parsial [11] dan EdgeConnect [12]. Ide utama dari karya ini adalah Gated Convolution, versi latih dari konvolusi parsial. Dengan menambahkan lapisan konvolusional standar tambahan yang diikuti dengan fungsi sigmoid, validitas setiap lokasi piksel / objek dapat diketahui, dan oleh karena itu masukan sketsa khusus tambahan juga diperbolehkan. Selain Gated Convolution, SN-PatchGAN digunakan untuk lebih menstabilkan pelatihan model GAN. Untuk mempelajari lebih lanjut tentang perbedaan antara Konvolusi Parsial dan Konvolusi Gated, dan caranyabagaimana masukan sketsa pengguna tambahan dapat mempengaruhi hasil restorasi, silakan lihat posting terakhir saya [di sini ].
Kesimpulan
Saya harap Anda sekarang memiliki pemahaman dasar tentang restorasi gambar. Saya percaya bahwa sebagian besar teknik umum yang digunakan dalam pemulihan gambar pembelajaran mendalam telah tercakup dalam posting saya sebelumnya. Jika Anda adalah teman lama saya, saya pikir Anda sekarang berada dalam posisi untuk memahami pekerjaan restorasi lainnya menggunakan pembelajaran mendalam. Jika Anda seorang pemula, saya ingin menyambut Anda. Saya harap posting ini bermanfaat bagi Anda. Faktanya, posting ini memberi Anda kesempatan untuk bergabung dengan kami dan belajar bersama.
Menurut pendapat saya, masih sulit untuk memulihkan gambar dengan struktur pemandangan yang kompleks dan sejumlah besar piksel yang hilang (misalnya, saat 50% piksel hilang). Tentu saja, tantangan lainnya adalah pemulihan gambar beresolusi tinggi. Semua tugas ini bisa disebut ekstrim. Saya pikir pendekatan yang didasarkan pada kemajuan terbaru dalam pemulihan dapat menyelesaikan beberapa masalah ini.
Tautan ke artikel
[1] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros, “Context Encoders: Feature Learning by Inpainting,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.

- Kursus Lanjutan "Machine Learning Pro + Deep Learning"
- Kursus Machine Learning
- Pelatihan profesi Ilmu Data
- Pelatihan Analis Data
- Python untuk Kursus Pengembangan Web
Lebih banyak kursus
Artikel yang direkomendasikan
- Berapa Banyak Data Scientist Hasilkan: Gambaran Umum Gaji dan Pekerjaan di 2020
- Berapa Banyak Penghasilan Analis Data: Gambaran Umum Gaji dan Pekerjaan di 2020
- Bagaimana Menjadi Ilmuwan Data Tanpa Kursus Online
- 450 kursus gratis dari Ivy League
- Machine Learning 5 9
- Machine Learning Computer Vision
- Machine Learning Computer Vision