- Ayo mulai. Saya akan berbicara tentang pembuatan log yang nyaman dan infrastruktur di sekitar logging yang dapat Anda terapkan untuk membuatnya nyaman bagi Anda untuk hidup dengan aplikasi Anda dan siklus hidupnya.

Apa yang kita lakukan? Kami akan membangun aplikasi kecil, startup kami. Kemudian kami akan menerapkan logging dasar ke dalamnya, ini adalah bagian kecil dari laporan, yang disediakan Python di luar kotak. Dan bagian terbesar - kami akan menganalisis masalah umum yang kami temui selama proses debug, peluncuran, dan alat untuk mengatasinya.
Penafian kecil: Saya akan menggunakan kata-kata seperti pena dan bahasa lokal. Biar saya jelaskan. "Pena" mungkin adalah bahasa gaul yandex, ini menunjukkan API Anda, API http atau gRPC atau kombinasi huruf lainnya sebelum APU. "Lokal" adalah saat saya mengembangkan di laptop. Sepertinya saya telah menceritakan tentang semua kata yang tidak saya kendalikan.
Aplikasi toko buku
Ayo mulai. Startup kami adalah "Toko Buku". Fitur utama dari aplikasi ini adalah penjualan buku, hanya itu yang ingin kami lakukan. Lalu sedikit isian. Aplikasi akan ditulis dalam Flask. Semua cuplikan kode, semua alat bersifat umum dan diabstraksi dari Python, sehingga dapat diintegrasikan ke sebagian besar aplikasi Anda. Tapi dalam pembicaraan kita itu adalah Flask.
Karakter: saya, pengembang, manajer, dan kolega saya tercinta, Erast. Setiap pertandingan tidak disengaja.
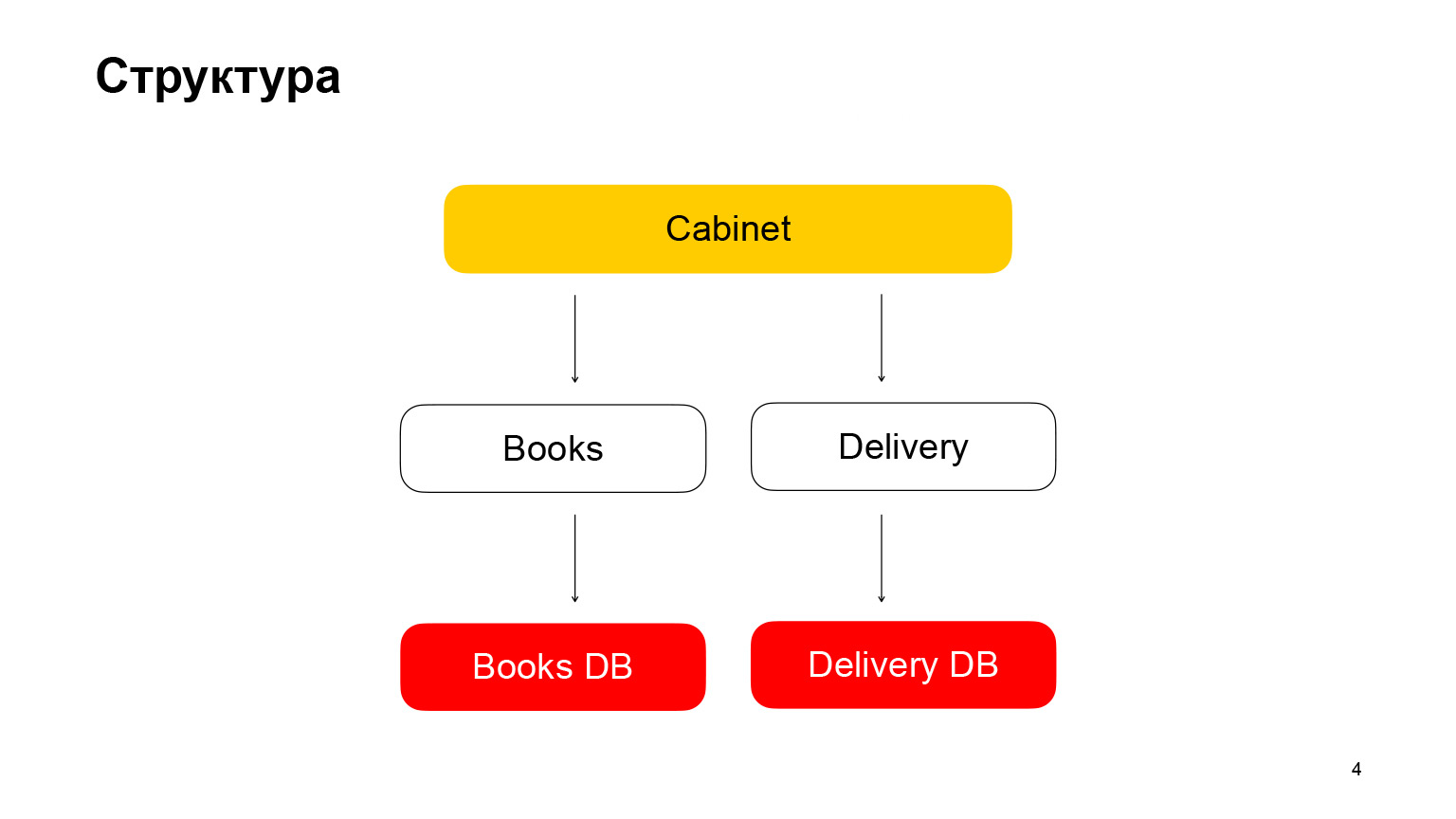
Mari kita bicara sedikit tentang strukturnya. Ini adalah aplikasi arsitektur layanan mikro. Layanan pertama adalah Books, tempat penyimpanan buku dengan metadata buku. Ini menggunakan database PostgreSQL. Layanan mikro kedua adalah layanan mikro pengiriman yang menyimpan metadata tentang pesanan pengguna. Kabinet adalah backend kabinet. Kami tidak memiliki frontend, itu tidak diperlukan dalam laporan kami. Kabinet mengumpulkan permintaan, data dari layanan buku dan layanan pengiriman.

Saya akan menunjukkan kepada Anda kode untuk pegangan layanan ini, Buku API. Pegangan ini mengambil data dari database, menserialisasinya, mengubahnya menjadi JSON dan mengembalikannya.

Mari melangkah lebih jauh. Jasa pengiriman. Pegangannya persis sama. Kami mengambil data dari database, membuat serial dan mengirimkannya.

Dan kenop terakhir adalah kenop kabinet. Ini memiliki kode yang sedikit berbeda. Kabinet menangani data permintaan dari layanan pengiriman dan dari layanan buku, mengumpulkan tanggapan dan memberikan perintah kepada pengguna. Segala sesuatu. Kami dengan cepat menemukan struktur aplikasinya.
Masuk dasar dalam aplikasi
Sekarang mari kita bicara tentang logging dasar, yang telah kita lihat. Mari kita mulai dengan terminologi.

Apa yang diberikan Python kepada kita? Empat entitas dasar, utama:
- Logger, titik masuk untuk masuk ke kode Anda. Anda akan menggunakan beberapa jenis Logger, menulis logging.INFO, dan hanya itu. Kode Anda tidak akan lagi mengetahui ke mana pesan tersebut terbang dan apa yang terjadi selanjutnya. Entitas Penangan sudah bertanggung jawab untuk ini.
- Handler memproses pesan Anda, memutuskan ke mana akan mengirimkannya: ke keluaran standar, ke file, atau ke email orang lain.
- Filter adalah salah satu dari dua entitas tambahan. Menghapus pesan dari log. Kasus penggunaan umum lainnya adalah penjejalan data. Misalnya, di postingan Anda, Anda perlu menambahkan atribut. Untuk ini juga, Filter dapat membantu.
- Formatter membawa pesan Anda ke formulir yang diinginkan.

Di sinilah kita menyelesaikan terminologi, kita tidak akan kembali ke logging langsung dengan Python, dengan kelas dasar. Namun berikut adalah contoh konfigurasi aplikasi kita, yang diluncurkan pada ketiga layanan tersebut. Ada dua blok utama dan penting bagi kami: pemformat dan penangan. Untuk pemformat, ada contoh, yang dapat Anda lihat di sini, templat tentang bagaimana pesan akan ditampilkan.
Di handler, Anda dapat melihat logging.StreamHandler digunakan. Artinya, kami membuang semua log kami ke keluaran standar. Itu saja, kita sudah selesai.
Masalah 1. Log tersebar
Pindah ke masalah. Pertama-tama, masalah pertama: log tersebar.
Sedikit konteks. Kami telah menulis aplikasi kami, permen sudah siap. Kita bisa menghasilkan uang darinya. Kami meluncurkannya ke dalam produksi. Tentu saja, ada lebih dari satu server. Menurut perkiraan konservatif kami, aplikasi kami yang paling kompleks membutuhkan sekitar tiga atau empat mobil, dan seterusnya untuk setiap layanan.
Sekarang pertanyaannya. Manajer datang berlari ke arah kami dan bertanya: "Itu rusak, tolong!" Kamu sedang berlari. Semuanya dicatat untuk Anda, itu bagus. Anda pergi ke mesin tik pertama, lihat - tidak ada apa-apa di sana untuk permintaan Anda. Pergi ke mobil kedua - tidak ada. Dan seterusnya. Ini buruk, bagaimanapun juga harus diselesaikan.

Mari meresmikan hasil yang ingin kita lihat. Saya ingin log berada di satu tempat. Ini adalah persyaratan sederhana. Sedikit lebih keren adalah saya ingin mencari log. Artinya, ya, itu terletak di satu tempat dan saya tahu cara merobeknya, tetapi alangkah baiknya jika ada beberapa alat, fitur keren selain grap sederhana.
Dan saya tidak ingin menulis. Ini adalah Erast yang suka menulis kode. Saya tidak berbicara tentang itu, saya langsung membuat produk. Artinya, Anda menginginkan lebih sedikit kode tambahan, bertahan dengan satu atau dua file, baris, dan hanya itu.

Solusi yang bisa digunakan adalah Elasticsearch. Mari kita coba meningkatkannya. Apa manfaat Elasticsearch? Ini adalah antarmuka pencarian log. Ada antarmuka di luar kotak, ini bukan konsol untuk Anda, tetapi satu-satunya tempat penyimpanan. Artinya, kami telah memenuhi syarat utama. Kami tidak perlu pergi ke server.
Dalam kasus kami, ini akan menjadi integrasi yang cukup sederhana, dan dengan rilis terbaru, Elasticsearch memiliki agen baru yang bertanggung jawab untuk sebagian besar integrasi. Mereka melihat integrasi di sana sendiri. Sangat keren. Saya menulis ceramah sebelumnya dan menggunakan filebeat, sama mudahnya. Sederhana untuk log.
Sedikit tentang Elasticsearch. Saya tidak ingin beriklan, tetapi ada banyak fitur tambahan. Misalnya, hal kerennya adalah pencarian log teks lengkap di luar kotak. Kedengarannya sangat keren. Untuk saat ini, kelebihan tersebut sudah cukup bagi kami. Kami kencangkan.
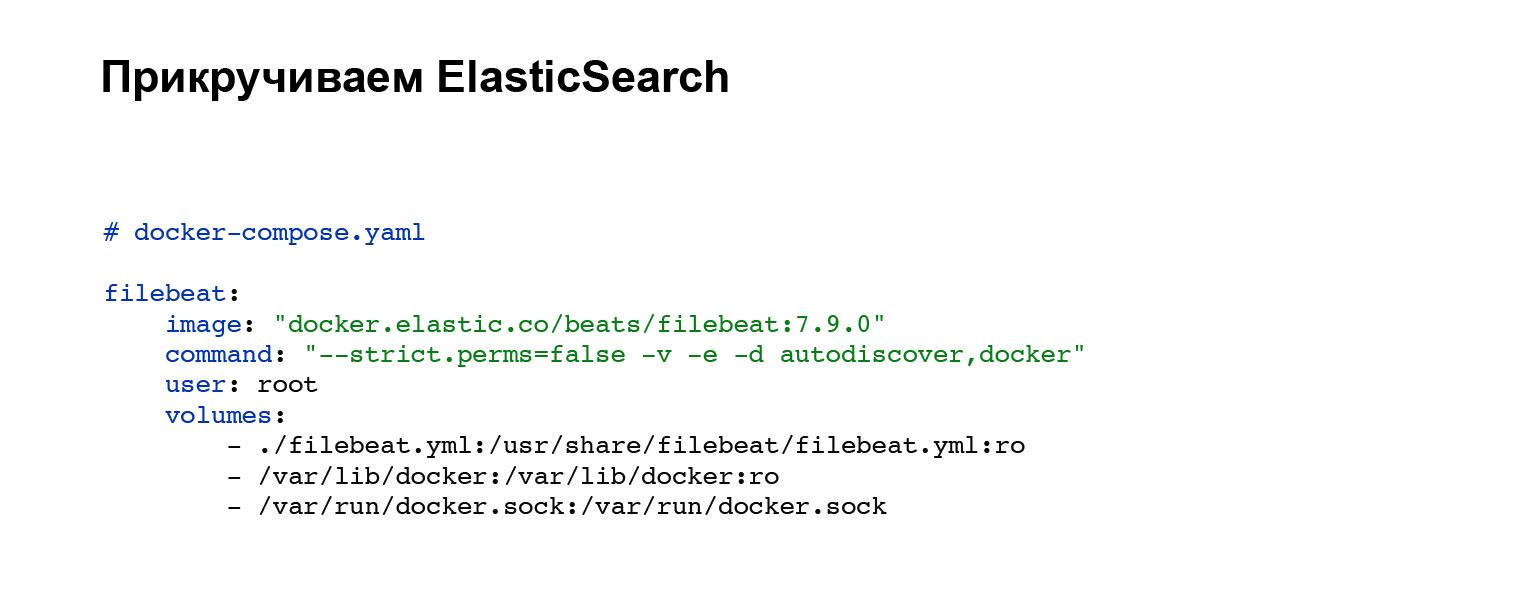
Pertama-tama, kita perlu menerapkan agen yang akan mengirim log kita ke Elasticsearch. Anda mendaftarkan akun dengan Elasticsearch dan kemudian menambahkannya ke docker-compose Anda. Jika Anda tidak memiliki buruh pelabuhan-menulis, Anda dapat mengangkat dengan pegangan atau pada sistem Anda. Dalam kasus kami, blok kode berikut ditambahkan, integrasi ke dalam pembuatan-galangan. Itu saja, layanan sudah dikonfigurasi. Dan Anda dapat melihat file konfigurasi filebeat.yml di blok volume.

Berikut adalah contoh filebeat.yml. Di sini kami telah menyiapkan pencarian otomatis untuk log kontainer buruh pelabuhan yang berputar di dekatnya. Pilihan log ini telah disesuaikan. Berdasarkan kondisi, Anda dapat mengatur, menggantung label pada penampung Anda, dan bergantung pada ini, log Anda hanya akan dikirim ke penampung tertentu. Prosesor: blok add_docker_metadata sederhana. Kami menambahkan lebih banyak informasi tentang log Anda dalam konteks buruh pelabuhan ke log. Opsional, tapi keren.
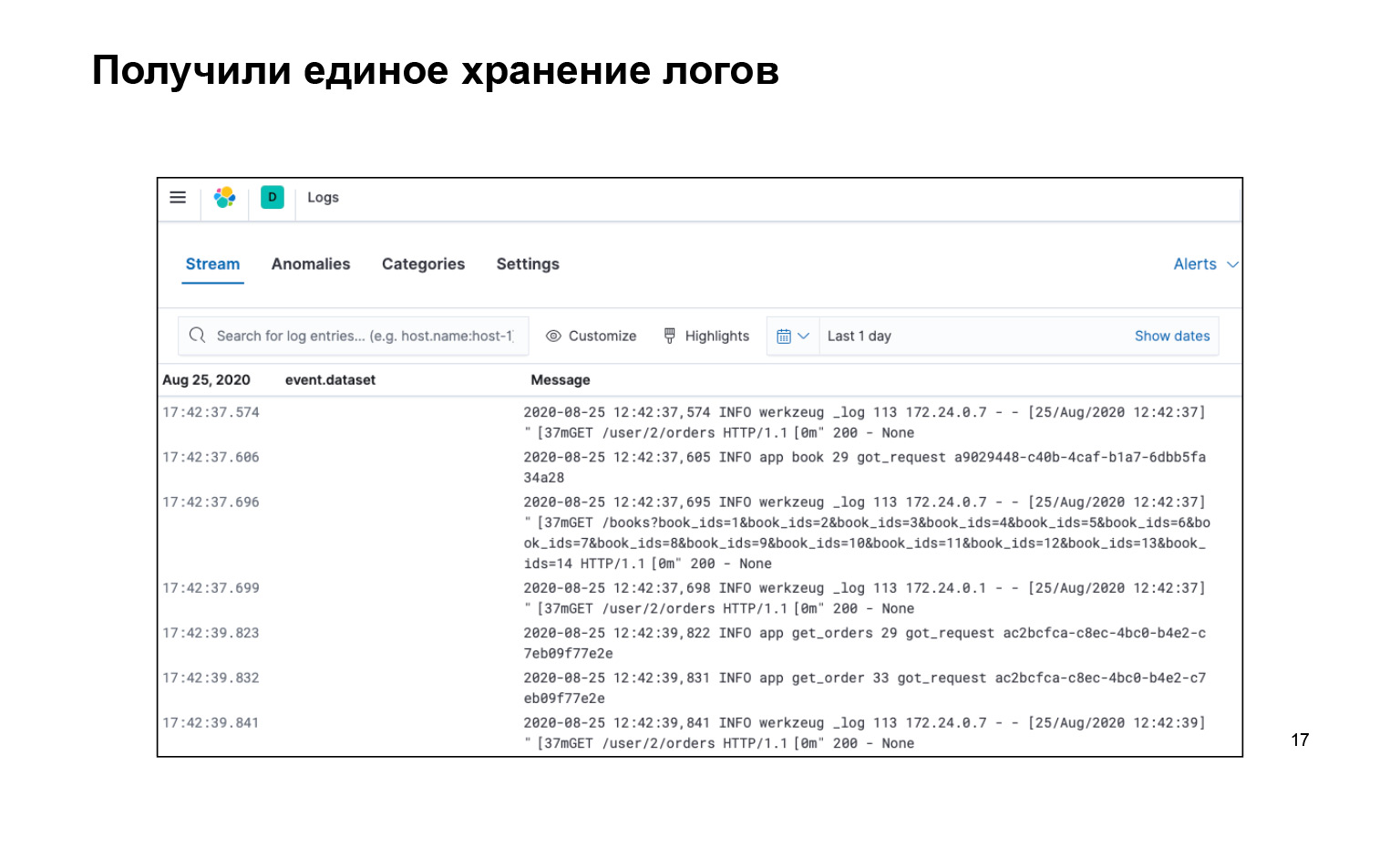
Apa yang kita punya? Itu saja yang kami tulis, semua kodenya, sangat keren. Pada saat yang sama, kami mendapatkan semua log di satu tempat dan ada antarmuka. Kami dapat mencari log kami, ini adalah bilah pencarian. Mereka dikirim. Dan Anda bahkan dapat menyalakannya secara langsung sehingga aliran mengalir ke log kami di antarmuka, dan kami melihatnya.

Di sini saya sendiri akan bertanya: mengapa, bagaimana cara mengikatkan sesuatu? Apa itu pencarian log, apa yang bisa dilakukan di sana?
Ya, di luar kotak dalam pendekatan ini, ketika kita memiliki log teks, ada lelucon kecil: kita dapat mengatur permintaan melalui teks, misalnya message: pengguna. Ini akan mencetak kepada kita semua log yang memiliki substring pengguna. Anda dapat menggunakan tanda bintang, sebagian besar kartu liar unix lainnya. Tapi sepertinya ini belum cukup, saya ingin membuatnya lebih keras agar Anda bisa melakukan pemanasan di Nginx lebih awal, semampu kami.

Mari kita mundur sedikit dari Elasticsearch dan mencoba melakukannya bukan dengan Elasticsearch, tetapi dengan pendekatan yang berbeda. Mari pertimbangkan log struktural. Ini adalah saat setiap entri log Anda bukan hanya baris teks, tetapi objek serial dengan atribut yang dapat diserialisasi oleh sistem pihak ketiga Anda untuk mendapatkan objek siap pakai.
Apa keuntungannya? Ini adalah format data yang seragam. Ya, objek dapat memiliki atribut yang berbeda, tetapi sistem eksternal apa pun dapat membaca JSON dan mendapatkan beberapa jenis objek.
Semacam mengetik. Ini menyederhanakan integrasi dengan sistem lain: tidak perlu menulis deserializers. Dan hanya deserializers adalah poin lain. Anda tidak perlu menulis teks biasa dalam aplikasi. Contoh: "Pengguna datang dengan spesialis ID ini dan itu, dengan pesanan ini dan itu." Dan semua ini perlu ditulis setiap saat.
Itu menggangguku. Saya ingin menulis: "Permintaan telah tiba." Lebih lanjut: “Ini-dan-itu, ini-dan-itu, ini-dan-itu”, sangat sederhana, sangat bergaya IT.

Ayo lanjutkan. Setuju: kami akan masuk dalam format JSON, ini adalah format sederhana. Elasticsearch segera didukung, filebeat, yang kami buat bersambung dan coba arsipkan. Itu tidak terlalu sulit. Pertama, Anda menambahkan file pengaturan dari pustaka pythonjsonlogger ke blok pemformatan JSONFormatter, tempat kami menyimpan konfigurasi. Ini mungkin tempat yang berbeda di sistem Anda. Dan kemudian di atribut format Anda meneruskan atribut mana yang ingin Anda tambahkan ke objek Anda.
Blok di bawah ini adalah blok konfigurasi yang ditambahkan ke filebeat.yml. Di sini, di luar kotak, ada antarmuka pemukul file untuk mengurai log JSON. Sangat keren. Semuanya. Anda tidak perlu menulis apa pun untuk ini. Dan sekarang log Anda terlihat seperti objek.
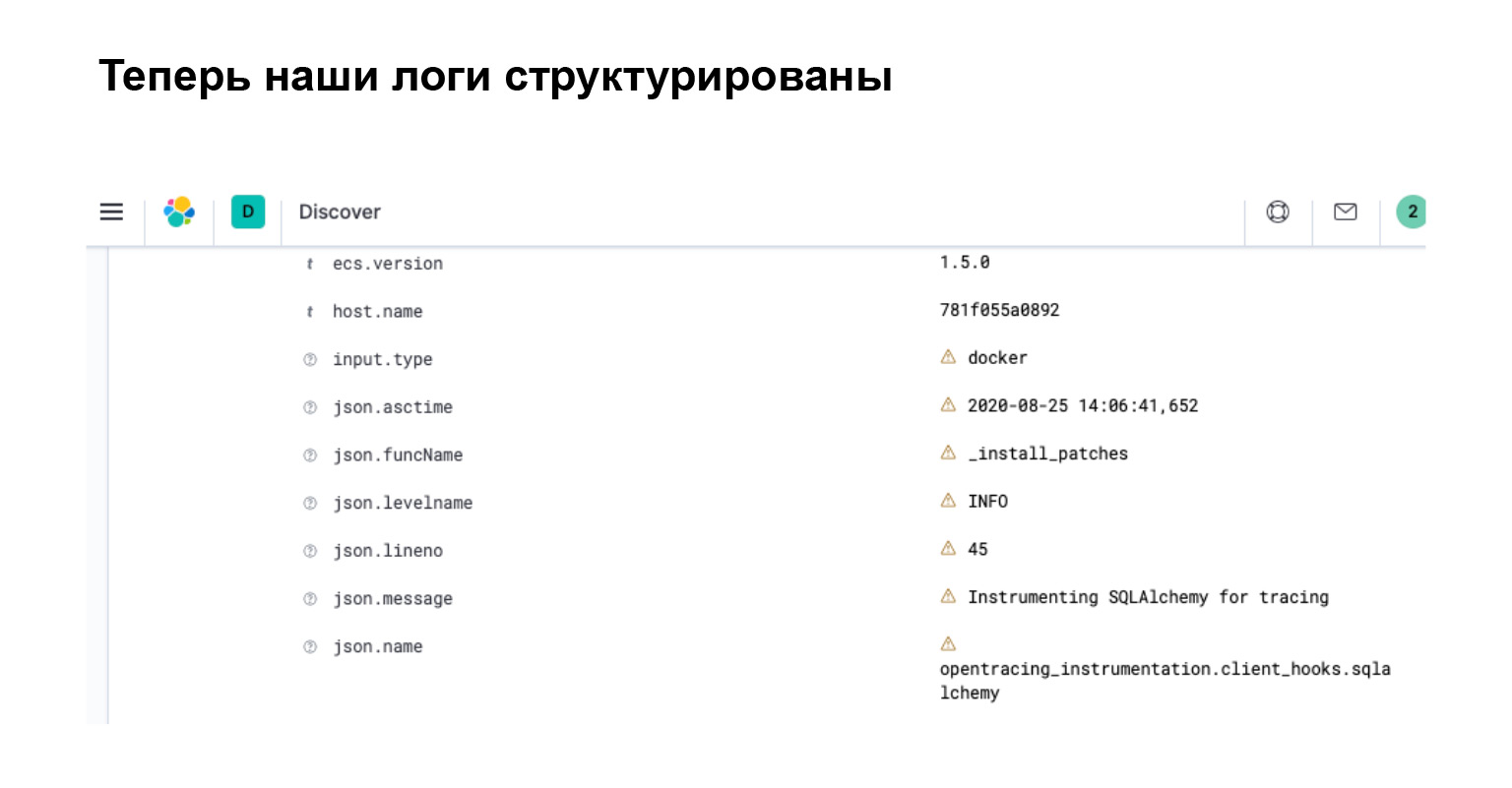
Apa yang kami dapatkan di Elasticsearch? Di antarmuka, Anda dapat langsung melihat bahwa log Anda telah menjadi objek dengan atribut terpisah, yang dengannya Anda dapat menelusuri, membuat filter, dan membuat kueri yang kompleks.

Mari kita rangkum. Sekarang log kami memiliki struktur. Mereka mudah digunakan dan Anda dapat menulis kueri yang cerdas. Elasticsearch mengetahui struktur ini karena mengurai semua atribut ini. Dan di kibana, yang merupakan antarmuka untuk Elasticsearch, Anda dapat memfilter log tersebut menggunakan bahasa kueri khusus yang disediakan Elasticsearch.
Dan itu lebih mudah daripada mendayung. Grep memiliki bahasa yang agak rumit dan keren. Ada banyak hal untuk ditulis. Banyak hal yang bisa dipermudah di kibana. Dengan ini diselesaikan.
Masalah 2. Rem
Masalah selanjutnya adalah rem. Dalam arsitektur layanan mikro, rem selalu ada dan di mana-mana.

Berikut sedikit konteksnya, saya akan menceritakan sebuah kisah. Manajer, karakter utama dari proyek kami, berlari ke arah saya dan berkata: “Hei, hei, kantor sedang melambat! Danya, simpan, tolong! "
Kami belum tahu apa-apa, kami masuk ke log kami di Elasticsearch. Tapi izinkan saya memberi tahu Anda apa yang sebenarnya terjadi.

Erast menambahkan fitur. Di buku, sekarang kami tidak menampilkan ID penulis, tetapi namanya tepat di antarmuka. Sangat keren. Dia melakukannya dengan kode berikut. Sepotong kecil kode, tidak rumit. Apa yang salah?
Anda dapat mengatakan dengan mata terlatih bahwa Anda tidak dapat melakukan ini dengan SQLAlchemy, dan dengan ORM lain juga. Anda perlu melakukan pra-cache atau sesuatu yang lain sehingga Anda tidak pergi ke database dengan subkueri kecil dalam satu putaran. Masalah yang tidak menyenangkan. Tampaknya kesalahan seperti itu tidak boleh dibiarkan sama sekali.
Biarkan aku memberitahu Anda. Saya memiliki pengalaman: kami bekerja dengan Django, dan kami memiliki cache awal kustom yang diimplementasikan dalam proyek kami. Semuanya berjalan dengan baik selama bertahun-tahun. Pada titik tertentu, Erast dan saya memutuskan: mari kita ikuti waktu, perbarui Django. Biasanya, Django tidak mengetahui apapun tentang tembolok khusus kita, dan antarmukanya telah berubah. Prikash jatuh diam-diam. Ini tidak tertangkap dalam pengujian. Masalah yang sama, hanya saja lebih sulit untuk ditangkap.
Apa masalahnya? Bagaimana saya bisa membantu Anda memecahkan masalah?

Mari beri tahu Anda apa yang saya lakukan sebelum saya mulai memecahkan masalah menemukan rem.
Hal pertama yang saya lakukan adalah membuka Elasticsearch, kami sudah memilikinya, ini membantu, tidak perlu berjalan di sekitar server. Saya pergi ke log, mencari log kabinet. Saya menemukan pertanyaan yang panjang. Saya memainkannya di laptop dan melihat bahwa bukan kantor yang menahan. Memperlambat Buku.
Saya menemukan log Buku, menemukan kueri bermasalah - sebenarnya, kami sudah memilikinya. Saya mereproduksi Buku dengan cara yang sama di laptop. Kode yang sangat kompleks - Saya tidak mengerti apa-apa. Saya mulai men-debug. Pengaturan waktu cukup sulit untuk ditangkap. Mengapa? Cukup sulit untuk menentukan ini secara internal di SQLAlchemy. Saya menulis pencatat waktu khusus, melokalkan dan memperbaiki masalah.
Itu menyakiti saya. Sulit, tidak menyenangkan. Saya menangis. Saya ingin proses menemukan masalah ini menjadi lebih cepat dan nyaman.
Mari kita formalisasi masalah kita. Sulit untuk mencari log untuk apa yang melambat, karena log kami adalah log peristiwa yang tidak terkait. Kami harus menulis pengatur waktu khusus yang menunjukkan kepada kami berapa banyak blok kode yang telah dieksekusi. Selain itu, tidak jelas cara mencatat waktu sistem eksternal: misalnya, ORM atau perpustakaan permintaan. Kami perlu menyematkan pengatur waktu kami di dalam atau dengan semacam Pembungkus, tetapi kami tidak akan mengetahui mengapa itu melambat di dalam. Rumit.

Solusi bagus yang saya temukan adalah Jaeger. Ini adalah implementasi dari protokol opentracing, jadi mari kita terapkan pelacakan.
Apa yang diberikan Jaeger? Ini adalah antarmuka yang ramah pengguna dengan permintaan pencarian. Anda dapat memfilter kueri yang panjang atau melakukannya dengan tag. Representasi visual dari aliran permintaan, gambar yang sangat indah, akan saya tunjukkan nanti.
Pengaturan waktu sudah dikeluarkan dari kotaknya. Anda tidak perlu melakukan apapun dengan mereka. Jika Anda perlu memeriksa berapa banyak blok khusus yang sedang dieksekusi, Anda dapat membungkusnya dalam pengatur waktu yang disediakan oleh Jaeger. Sangat nyaman.
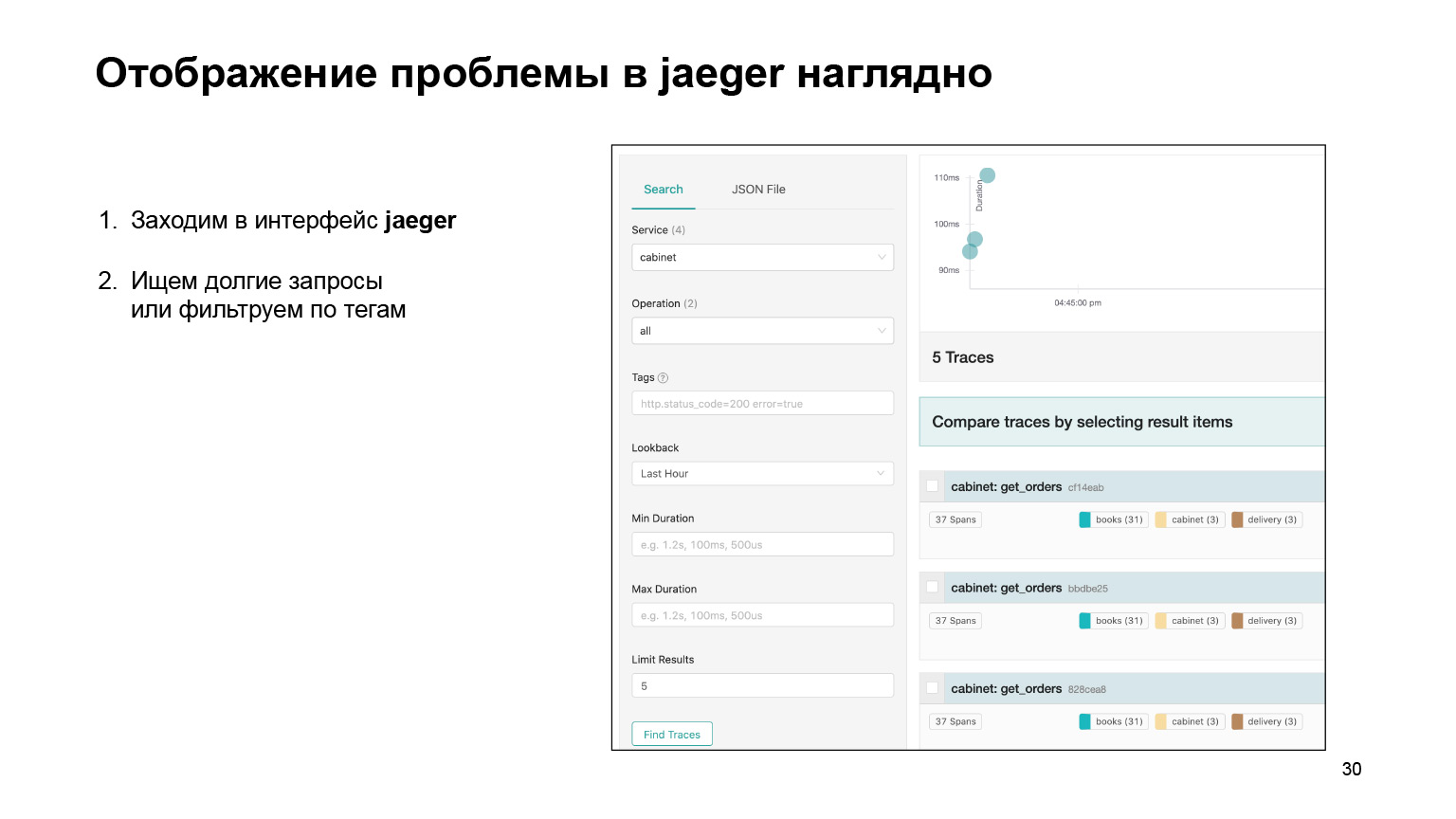
Mari kita lihat bagaimana mungkin menemukan masalah di antarmuka dan melokalkannya di sana. Kami masuk ke antarmuka Jaeger. Seperti inilah tampilan permintaan kami. Kami dapat mencari permintaan untuk akun atau layanan lain. Kami segera memfilter kueri yang panjang. Kami tertarik pada yang panjang, mereka cukup sulit ditemukan di log. Kami mendapatkan daftar mereka.
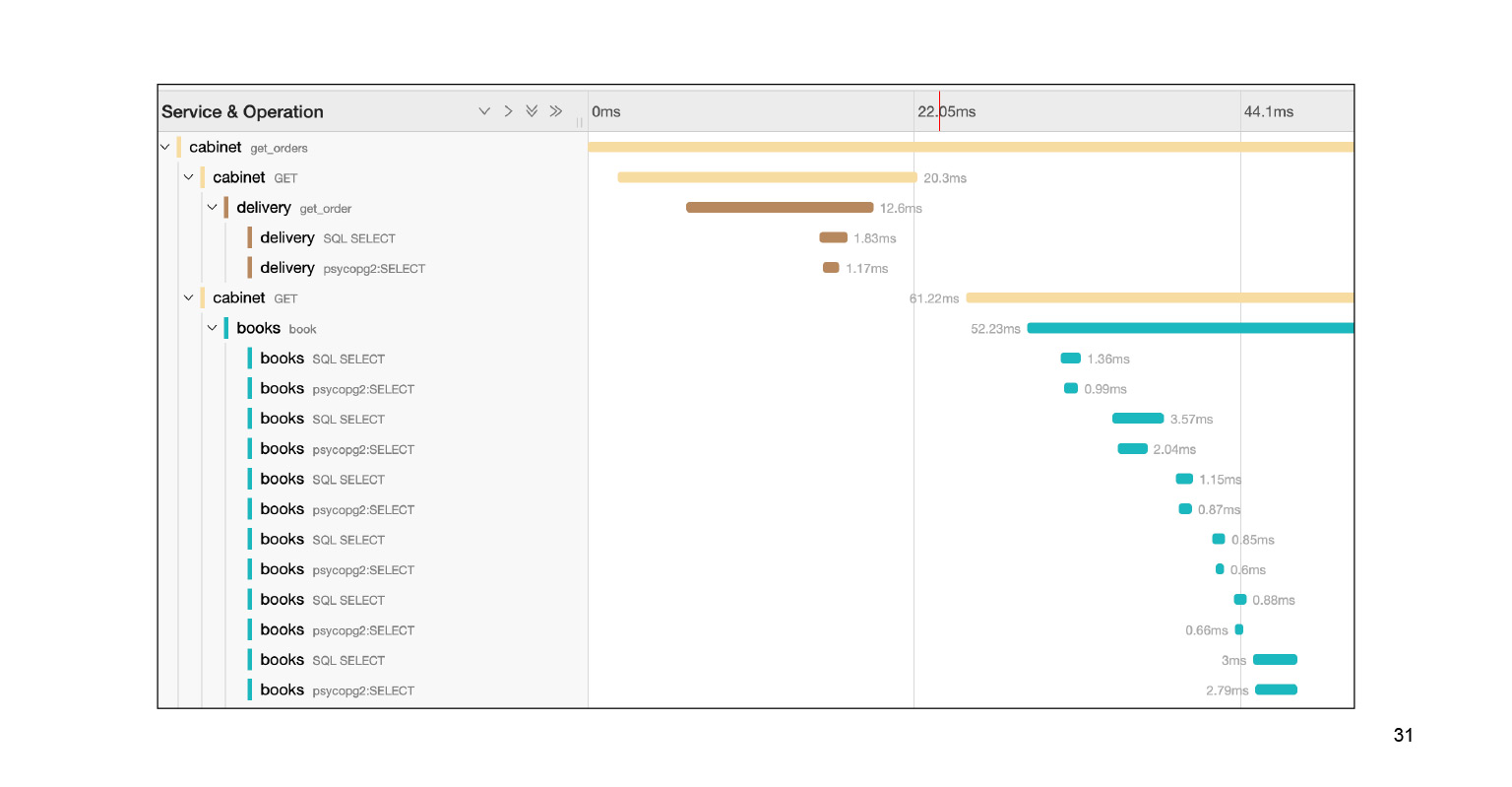
Kami termasuk dalam kueri ini, dan kami melihat footcloth besar dari subkueri SQL. Kami dapat dengan jelas melihat bagaimana mereka dieksekusi tepat waktu, blok kode mana yang bertanggung jawab atas apa. Sangat keren. Selain itu, dalam konteks masalah kami, ini bukan keseluruhan log. Ada alas kaki besar lainnya dua atau tiga slide ke bawah. Kami melokalkan masalah dengan cukup cepat di Jaeger. Setelah menyelesaikan masalah, konteks apa yang diberikan Jaeger dapat membantu kita?
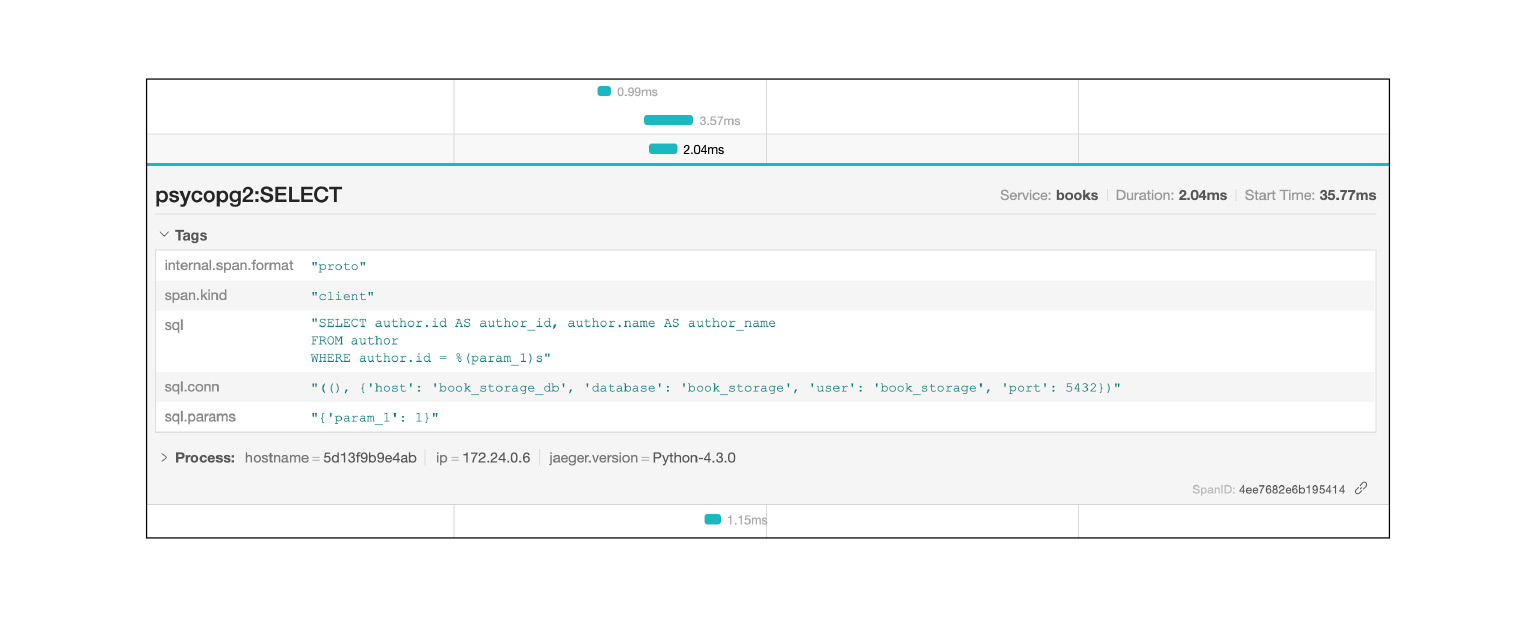
Log Jaeger, misalnya, kueri SQL: Anda dapat melihat kueri mana yang berulang. Sangat cepat dan keren.
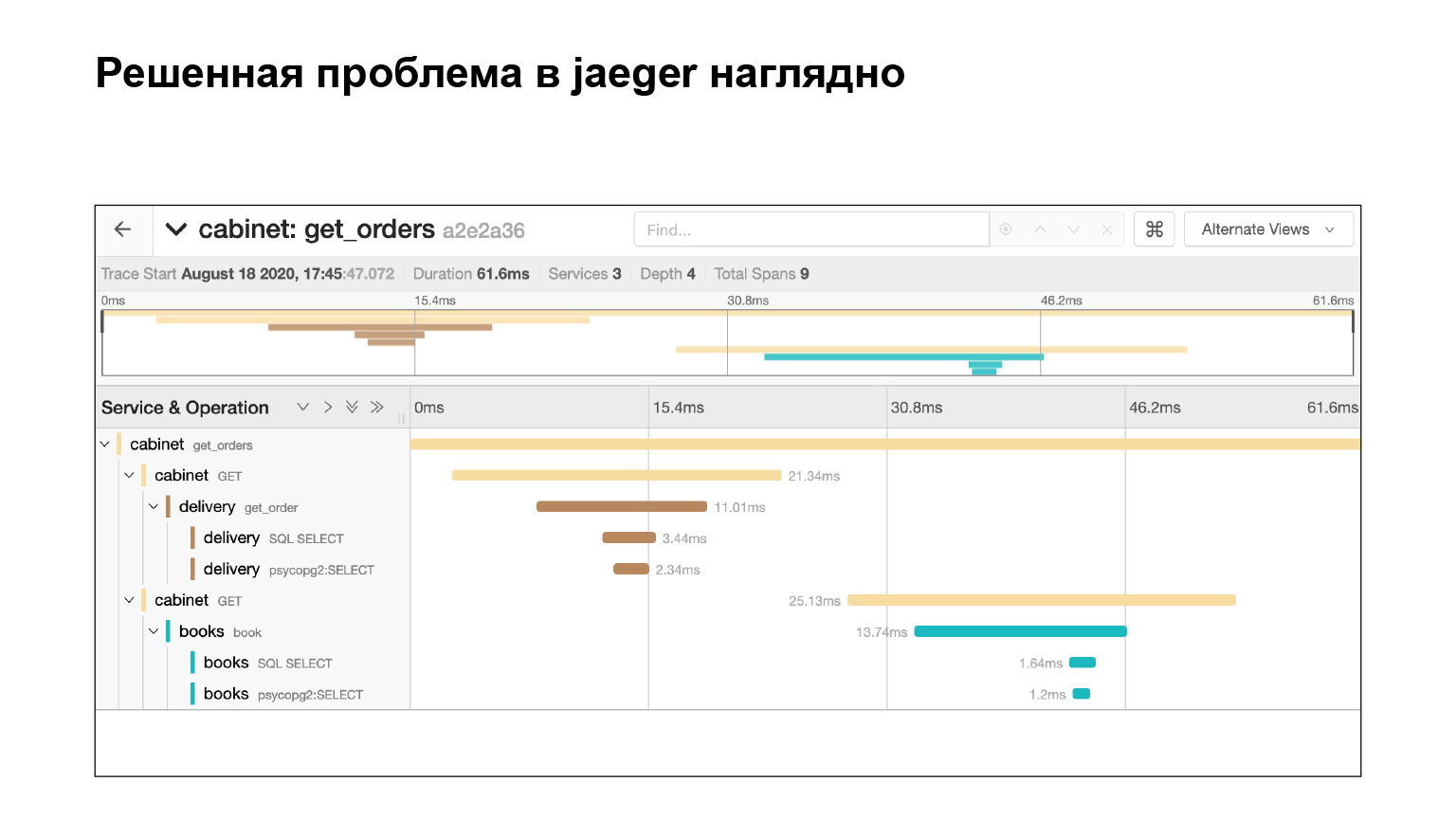
Kami menyelesaikan masalah dan segera melihat di Jaeger bahwa semuanya baik-baik saja. Kami memeriksa dengan kueri yang sama bahwa kami sekarang tidak memiliki subkueri. Mengapa? Misalkan kita memeriksa request yang sama, mencari tahu waktunya - lihat di Elasticsearch berapa lama permintaan tersebut dijalankan. Kemudian kita akan melihat waktunya. Tetapi ini tidak menjamin bahwa tidak ada subkueri. Dan di sini kita melihatnya, keren.

Mari terapkan Jaeger. Anda tidak membutuhkan banyak kode. Anda menambahkan dependensi untuk opentracing, untuk Flask. Sekarang tentang kode apa yang kita lakukan.
Blok kode pertama adalah penyiapan klien Jaeger.
Kemudian kami menyiapkan integrasi dengan Flask, Django, atau kerangka kerja lainnya yang memiliki integrasi.
install_all_patches adalah baris kode terakhir dan yang paling menarik. Kami menambal sebagian besar integrasi eksternal dengan berinteraksi dengan MySQL, Postgres, perpustakaan permintaan. Kami menambal semua ini dan itulah sebabnya di antarmuka Jaeger kami segera melihat semua kueri dengan SQL dan layanan mana yang kami tuju. Sangat keren. Dan Anda tidak perlu banyak menulis. Kami baru saja menulis install_all_patches. Sihir!
Apa yang kita punya? Sekarang Anda tidak perlu mengumpulkan acara dari log. Seperti yang saya katakan, log adalah peristiwa yang berbeda. Di Jaeger, ini adalah salah satu acara besar yang Anda lihat strukturnya. Jaeger memungkinkan Anda menangkap kemacetan dalam aplikasi Anda. Anda hanya perlu mencari kueri yang panjang, dan Anda dapat menganalisis apa yang salah.
Masalah 3. Kesalahan
Masalah terakhir adalah kesalahan. Ya, saya licik. Saya tidak akan membantu Anda menghilangkan kesalahan dalam aplikasi, tetapi saya akan memberi tahu Anda apa yang dapat Anda lakukan selanjutnya.

Konteks. Anda dapat mengatakan: “Danya, kami mencatat kesalahan, kami memiliki peringatan untuk lima ratus, kami telah mengkonfigurasinya. Apa yang kamu inginkan? Kami masuk, kami masuk dan kami akan masuk dan debug.
Anda tidak tahu pentingnya kesalahan dari log. Apa pentingnya? Di sini Anda memiliki satu kesalahan keren, dan kesalahan saat menghubungkan ke database. Basis baru saja gagal. Saya ingin segera melihat bahwa kesalahan ini tidak begitu penting, dan jika tidak ada waktu, abaikan saja, tetapi perbaiki yang lebih penting.
Tingkat kesalahan adalah konteks yang dapat membantu kami men-debugnya. Bagaimana cara melacak kesalahan? Mari lanjutkan, kami mengalami kesalahan sebulan yang lalu, dan sekarang kesalahan itu muncul lagi. Saya ingin segera mencari solusi dan memperbaikinya atau membandingkan penampilannya dengan salah satu rilis.
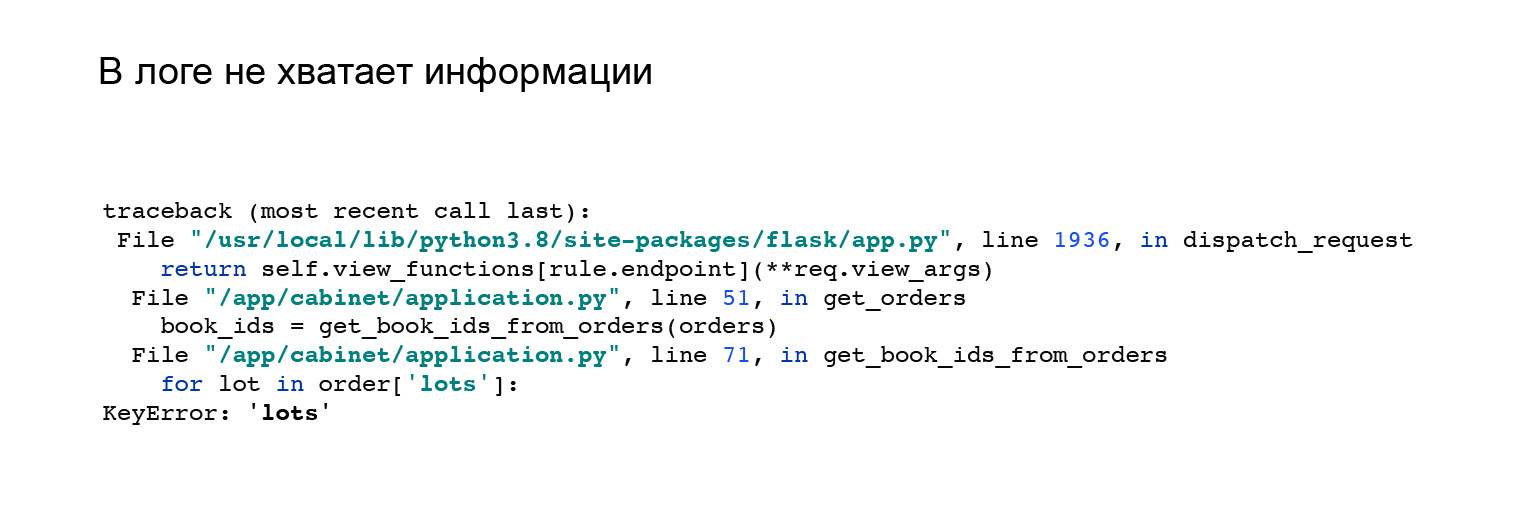
Inilah contoh yang bagus. Ketika saya melihat integrasi dengan Jaeger, saya mengubah API saya sedikit. Saya telah mengubah format tanggapan aplikasi. Saya mendapat kesalahan ini. Tetapi tidak jelas mengapa saya tidak memiliki kunci, banyak objek pesanan, dan tidak ada yang akan membantu saya. Seperti, lihat kesalahan di sini, perbanyak dan tangkap sendiri.

Mari terapkan penjaga. Ini adalah pelacak bug yang akan membantu kami memecahkan masalah serupa dan menemukan konteks kesalahan. Ambil perpustakaan standar yang dikelola oleh para pengembang penjaga. Dalam empat baris kode, kami menambahkannya ke aplikasi kami. Segala sesuatu.
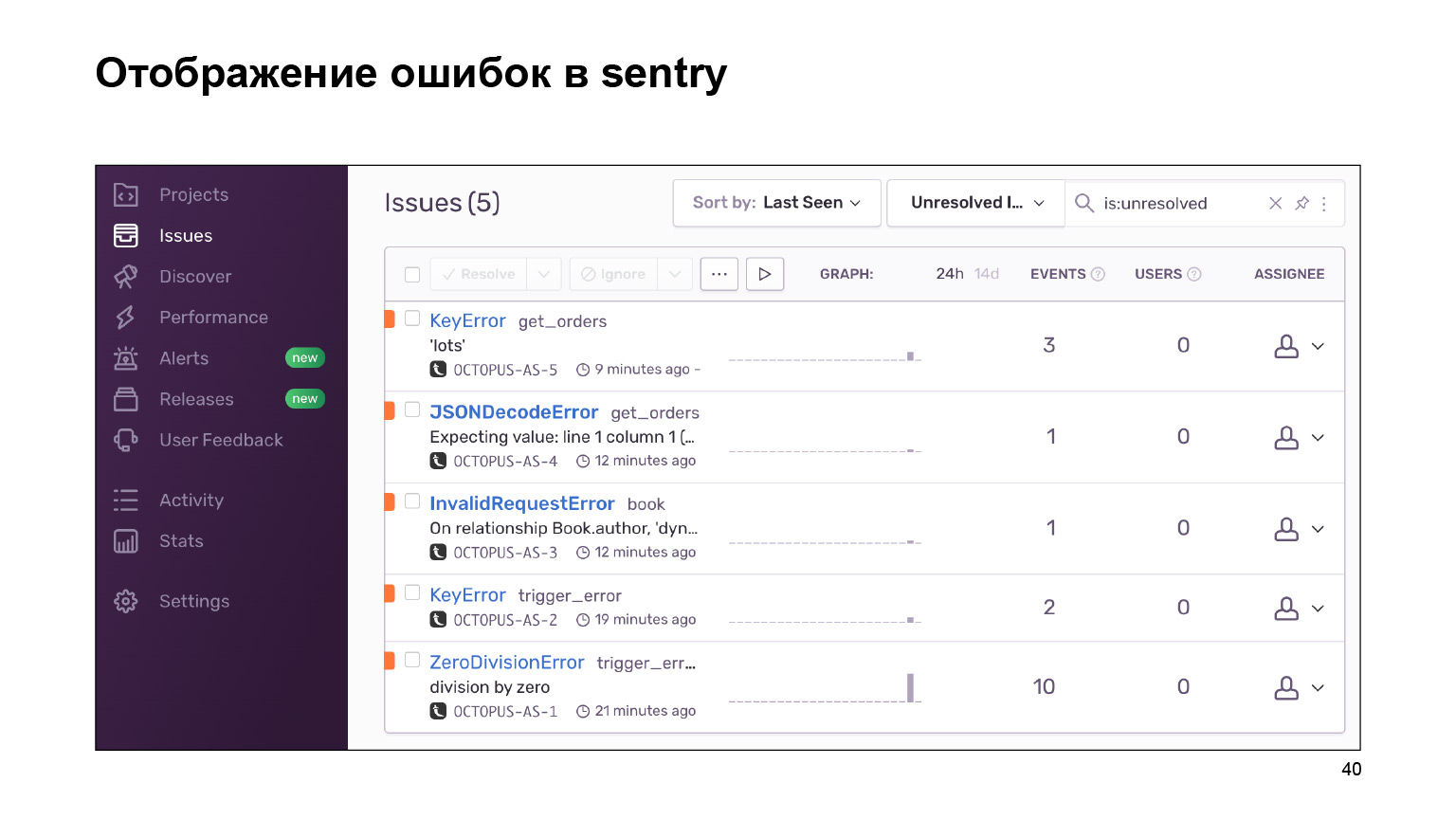
Apa yang kita dapatkan saat keluar? Berikut adalah dasbor dengan kesalahan yang dapat dikelompokkan berdasarkan proyek dan Anda dapat mengikuti. Sebuah footcloth besar dari log error dikelompokkan menjadi log yang identik dan serupa. Statistik disediakan pada mereka. Dan Anda juga dapat menangani kesalahan ini menggunakan antarmuka.
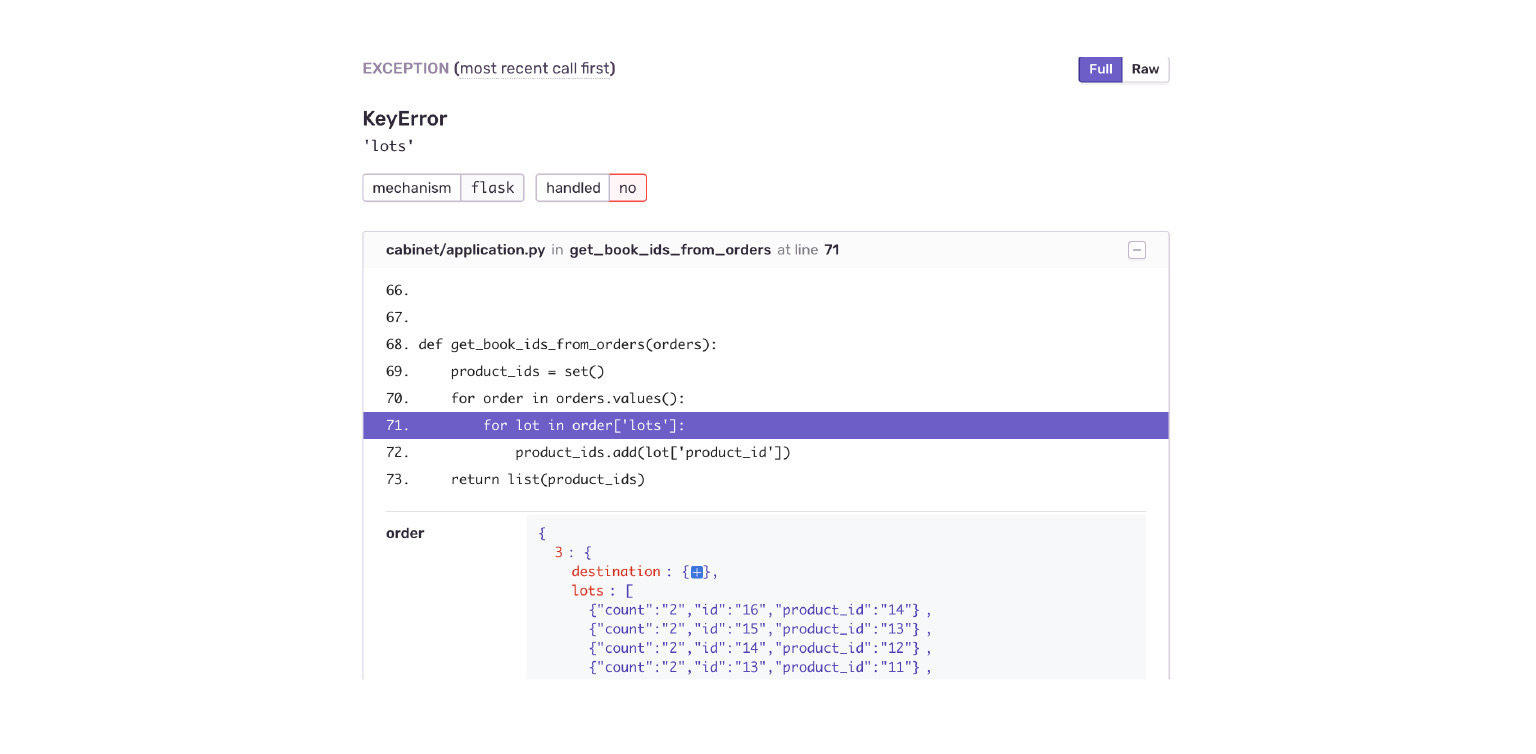
Mari kita lihat contoh kita. Jatuh ke dalam KeyError. Kami langsung melihat konteks kesalahan, apa yang ada di objek pesanan, apa yang tidak ada. Saya langsung melihat secara tidak sengaja bahwa aplikasi Pengiriman telah memberi saya struktur data baru. Kabinet belum siap untuk ini.

Apa yang diberikan penjaga selain apa yang telah saya daftarkan? Mari meresmikan.
Ini adalah penyimpanan kesalahan tempat Anda dapat mencarinya. Ada alat praktis untuk ini. Ada pengelompokan kesalahan - berdasarkan proyek, berdasarkan kesamaan. Sentry menyediakan integrasi dengan pelacak yang berbeda. Artinya, Anda dapat melacak kesalahan Anda, mengatasinya. Anda bisa menambahkan tugas ke konteks Anda dan hanya itu. Ini membantu dalam pembangunan.
Statistik kesalahan. Sekali lagi, ini mudah dibandingkan dengan meluncurkan rilis. Sentry akan membantu Anda dengan ini. Peristiwa serupa yang terjadi di samping kesalahan juga dapat membantu Anda menemukan dan memahami penyebabnya.

Mari kita rangkum. Kami telah menulis aplikasi yang sederhana tetapi memenuhi kebutuhan. Ini membantu Anda mengembangkan dan mempertahankannya dalam siklus hidupnya. Apa yang telah kita lakukan? Kami telah mengumpulkan log dalam satu repositori. Ini memberi kami kesempatan untuk tidak mencarinya di tempat yang berbeda. Plus, kami sekarang memiliki pencarian berdasarkan log dan fitur pihak ketiga, alat kami.
Pelacakan terintegrasi. Sekarang kita dapat memantau aliran data secara visual dalam aplikasi kita.
Dan menambahkan alat praktis untuk menangani kesalahan. Mereka akan ada di aplikasi kita, tidak peduli seberapa keras kita berusaha. Tapi kami akan memperbaikinya lebih cepat dan lebih baik.
Apa lagi yang bisa Anda tambahkan? Aplikasinya sendiri sudah siap, ada tautan, Anda dapat melihat bagaimana itu dilakukan. Semua integrasi dimunculkan di sana. Misalnya, integrasi dengan Elasticsearch atau tracing. Masuk dan lihat.
Hal keren lainnya yang tidak sempat saya bahas adalah request_id. Hampir tidak berbeda dengan trace_id, yang digunakan di traces. Tetapi kami bertanggung jawab atas request_id, ini adalah fitur terpentingnya. Manajer dapat langsung mendatangi kami dengan request_id, kami tidak perlu mencarinya. Kami akan segera mulai menyelesaikan masalah kami. Sangat keren.
Dan jangan lupa bahwa alat yang kami terapkan bersifat overhead. Ini adalah masalah yang perlu ditangani untuk setiap aplikasi. Anda tidak dapat menerapkan semua integrasi kami secara sembarangan, membuat hidup Anda lebih mudah, dan kemudian memikirkan tentang apa yang harus dilakukan dengan aplikasi penghambat.
Saksikan berikut ini. Jika itu tidak memengaruhi Anda, keren. Anda hanya mendapat plus dan tidak menyelesaikan masalah dengan rem. Jangan lupakan ini. Terima kasih sudah mendengarkan.