Apa tujuan dari penelitian ini? Saya ingin tahu:
- Dalam aplikasi apa Python digunakan
- Pengetahuan apa yang dibutuhkan: database, perpustakaan, kerangka kerja
- Berapa banyak spesialis di setiap arah yang dibutuhkan
- Gaji apa yang ditawarkan

Memuat data
Pekerjaan download dari situs hh.ru , menggunakan API: dev.hh.ru . Atas permintaan "Python", lowongan 1994 diunggah (wilayah Moskow), yang dibagi menjadi rangkaian pelatihan dan pengujian, dalam proporsi 80% dan 20% . Ukuran set pelatihan adalah 1595 , ukuran set pengujian adalah 399 . Set pengujian hanya akan digunakan di bagian Skill Top / Antitop dan klasifikasi Job.
Tanda-tanda
Menurut teks lowongan yang diunggah, dua kelompok kata yang paling umum n-gram terbentuk :
- 2 gram dalam bahasa Sirilik dan Latin
- 1 gram dalam bahasa Latin
Dalam lowongan TI, keterampilan dan teknologi utama biasanya ditulis dalam bahasa Inggris, sehingga kelompok kedua hanya memasukkan kata-kata dalam bahasa Latin.
Setelah dilakukan seleksi n-gram, kelompok pertama berisi 81 2-gram dan kelompok kedua 98 1-gram:
| Tidak. | n | n-gram | Bobot | Lowongan |
| 1 | 2 | dengan python | delapan | 258 |
| 2 | 2 | ci cd | delapan | 230 |
| 3 | 2 | pemahaman prinsip | delapan | 221 |
| 4 | 2 | pengetahuan tentang sql | delapan | 178 |
| lima | 2 | pengembangan dan | sembilan | 174 |
| ... | ... | ... | ... | ... |
| 82 | 1 | sql | lima | 490 |
| 83 | 1 | linux | 6 | 462 |
| 84 | 1 | postgresql.dll | lima | 362 |
| 85 | 1 | buruh pelabuhan | 7 | 358 |
| 86 | 1 | Jawa | sembilan | 297 |
| ... | ... | ... | ... | ... |
Diputuskan untuk membagi lowongan menjadi beberapa cluster sesuai dengan kriteria berikut dalam urutan prioritas:
| Sebuah prioritas | Kriteria | Bobot |
| 1 | Bidang (arah terapan), posisi, pengalaman
n-gram: "pembelajaran mesin", "administrasi linux", "pengetahuan luar biasa" |
7-9 |
| 2 | Alat, teknologi, perangkat lunak.
n-gram: "sql", "linux os", "pytest" |
4-6 |
| 3 | Keterampilan
n-gram lainnya: "pendidikan teknis", "Bahasa Inggris", "tugas menarik" |
1-3 |
Penentuan kelompok kriteria mana yang termasuk dalam n-gram, dan bobot apa yang akan diberikan padanya, terjadi pada tingkat intuitif. Berikut ini beberapa contohnya:
- Pada pandangan pertama, "Docker" dapat dikaitkan dengan kelompok kriteria kedua dengan bobot 4 hingga 6. Tetapi penyebutan "Docker" dalam lowongan kemungkinan besar berarti bahwa lowongan tersebut akan untuk posisi "insinyur DevOps". Oleh karena itu, "Docker" masuk ke dalam kelompok pertama dan mendapat bobot 7.
- «Java» , .. «Java» Java- « Python». «-». , , , «Java» 9.
n- — .
Untuk perhitungan, setiap kekosongan diubah menjadi vektor dengan dimensi 179 (jumlah fitur yang dipilih) bilangan bulat dari 0 hingga 9, di mana 0 berarti bahwa ke-i n-gram tidak ada dalam lowongan, dan angka dari 1 hingga 9 berarti adanya ke-i n - gram dan beratnya. Selanjutnya dalam teks, titik dipahami sebagai kekosongan yang direpresentasikan oleh vektor tersebut.
Contoh:
Misalkan daftar n-gram hanya berisi tiga nilai:
Tidak. n n-gram Bobot Lowongan 1 2 dengan python delapan 258 2 2 pemahaman prinsip delapan 221 3 1 sql lima 490
Kemudian untuk lowongan dengan teks.
Persyaratan:
- Pengalaman 3+ tahun dalam pengembangan python .
- Pengetahuan yang baik tentang sql
vektornya adalah [8, 0, 5].
Metrik
Untuk bekerja dengan data, Anda harus memiliki pemahaman tentangnya. Dalam kasus kami, saya ingin melihat apakah ada cluster poin, yang akan kami anggap sebagai cluster. Untuk ini, saya menggunakan algoritma t-SNE untuk menerjemahkan semua vektor ke dalam ruang 2D.
Inti dari metode ini adalah untuk mengurangi dimensi data, sambil menjaga proporsi jarak antara titik-titik himpunan sebanyak mungkin. Cukup sulit untuk memahami cara kerja t-SNE dari rumus. Tetapi saya menyukai satu contoh yang ditemukan di suatu tempat di Internet: katakanlah kita memiliki bola di ruang tiga dimensi. Kami menghubungkan setiap bola dengan semua bola lainnya dengan pegas tak terlihat, yang tidak berpotongan dengan cara apa pun dan tidak saling mengganggu saat menyilang. Pegas bertindak dalam dua arah, yaitu mereka menahan jarak dan pendekatan bola satu sama lain. Sistem dalam keadaan stabil, bola tidak bergerak. Jika kita mengambil salah satu bola dan menariknya kembali, lalu melepaskannya, ia akan kembali ke keadaan semula karena gaya pegas. Selanjutnya, kami mengambil dua piring besar, dan meremas bola menjadi lapisan tipis,sementara tidak mengganggu bola untuk bergerak di bidang antara dua pelat. Kekuatan pegas mulai bekerja, bola bergerak dan akhirnya berhenti ketika kekuatan semua pegas menjadi seimbang. Pegas akan bertindak sehingga bola yang berdekatan tetap relatif dekat dan rata. Juga dengan bola yang dilepas - mereka akan dikeluarkan dari satu sama lain. Dengan bantuan pegas dan pelat, kami mengubah ruang tiga dimensi menjadi dua dimensi, menjaga jarak antar titik dalam beberapa bentuk!Juga dengan bola yang dilepas - mereka akan dikeluarkan dari satu sama lain. Dengan bantuan pegas dan pelat, kami mengubah ruang tiga dimensi menjadi dua dimensi, menjaga jarak antar titik dalam beberapa bentuk!Juga dengan bola yang dilepas - mereka akan dikeluarkan dari satu sama lain. Dengan bantuan pegas dan pelat, kami mengubah ruang tiga dimensi menjadi dua dimensi, menjaga jarak antar titik dalam beberapa bentuk!
Algoritme t-SNE digunakan oleh saya hanya untuk memvisualisasikan sekumpulan poin. Dia membantu memilih metrik, serta memilih bobot untuk fitur.
Jika kita menggunakan metrik Euclidean yang kita gunakan dalam kehidupan sehari-hari, maka lokasi lowongan akan terlihat seperti ini:

Gambar tersebut menunjukkan bahwa sebagian besar titik terkonsentrasi di tengah, dan ada cabang kecil di sampingnya. Dengan pendekatan ini, algoritma pengelompokan yang menggunakan jarak antar titik tidak akan menghasilkan sesuatu yang baik.
Ada banyak metrik (cara untuk menentukan jarak antara dua titik) yang akan berfungsi dengan baik pada data yang Anda jelajahi. Saya memilih jarak Jaccard sebagai ukuran , dengan mempertimbangkan bobot n-gram. Ukuran Jaccard mudah dipahami, tetapi berfungsi dengan baik untuk memecahkan masalah yang sedang dipertimbangkan.
:
1 n-: « python», «sql», «docker»
2 n-: « python», «sql», «php»
:
« python» — 8
«sql» — 5
«docker» — 7
«php» — 9
(n- 1- 2- ): « python», «sql» = 8 + 5 = 13
( n- 1- 2- ): « python», «sql», «docker», «php» = 8 + 5 + 7 + 9 = 29
=1 — ( / ) = 1 — (13 / 29) = 0.55
Matriks jarak antara semua pasangan titik dihitung, ukuran matriksnya adalah 1595 x 1595. Totalnya, 1.271.215 jarak antar pasangan unik. Jarak rata-rata ternyata 0,96, antara 619659 jaraknya adalah 1 (yaitu tidak ada kesamaan sama sekali). Bagan berikut menunjukkan bahwa secara keseluruhan, ada sedikit kesamaan antara pekerjaan:
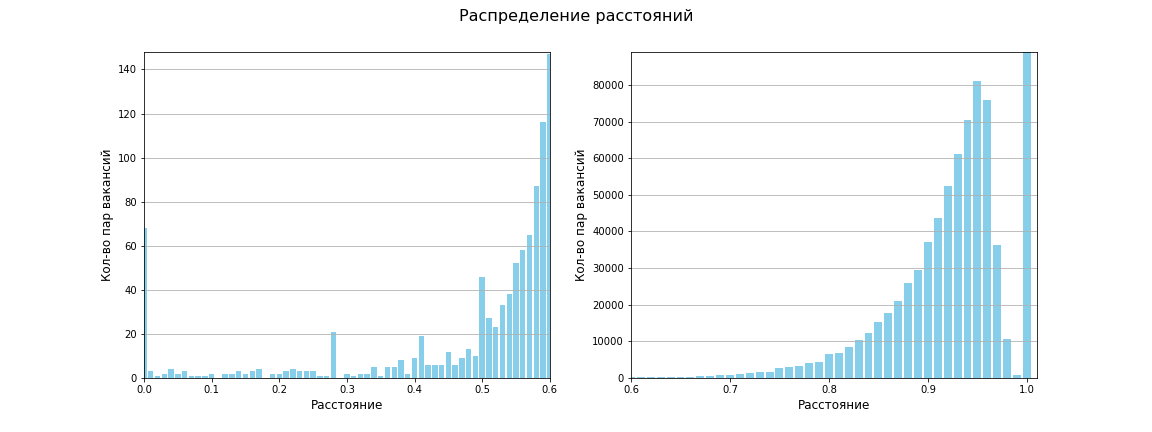
Menggunakan metrik Jaccard, ruang kita sekarang terlihat seperti ini:

Empat area kepadatan yang berbeda muncul, dan dua kelompok kecil dengan kepadatan rendah. Setidaknya begitulah mataku melihat!
Kekelompokan
Gaussian Mixture Model (GMM) dipilih sebagai algoritma clustering . Algoritma menerima data dalam bentuk vektor sebagai input, dan parameter n_components adalah jumlah cluster yang himpunannya harus dipecah. Anda dapat melihat cara kerja algoritme di sini (dalam bahasa Inggris). Saya menggunakan implementasi GMM yang sudah jadi dari pustaka scikit-learn: sklearn.mixture.GaussianMixture .
Perhatikan bahwa GMM tidak menggunakan metrik, tetapi memisahkan data hanya dengan sekumpulan fitur dan bobotnya. Dalam artikel, jarak Jaccard digunakan untuk memvisualisasikan data, menghitung kepadatan cluster (saya mengambil jarak rata-rata antara titik cluster untuk kepadatan), dan menentukantitik pusat cluster (kekosongan khas) - titik dengan jarak rata-rata terkecil ke titik lain dari cluster. Banyak algoritma pengelompokan menggunakan jarak antar titik dengan tepat. Bagian Metode Lain akan membahas jenis pengelompokan lain yang berbasis metrik dan juga memberikan hasil yang baik.
Pada bagian sebelumnya, ditentukan oleh mata bahwa kemungkinan besar akan ada enam kelompok. Beginilah tampilan hasil clustering dengan n_components = 6:

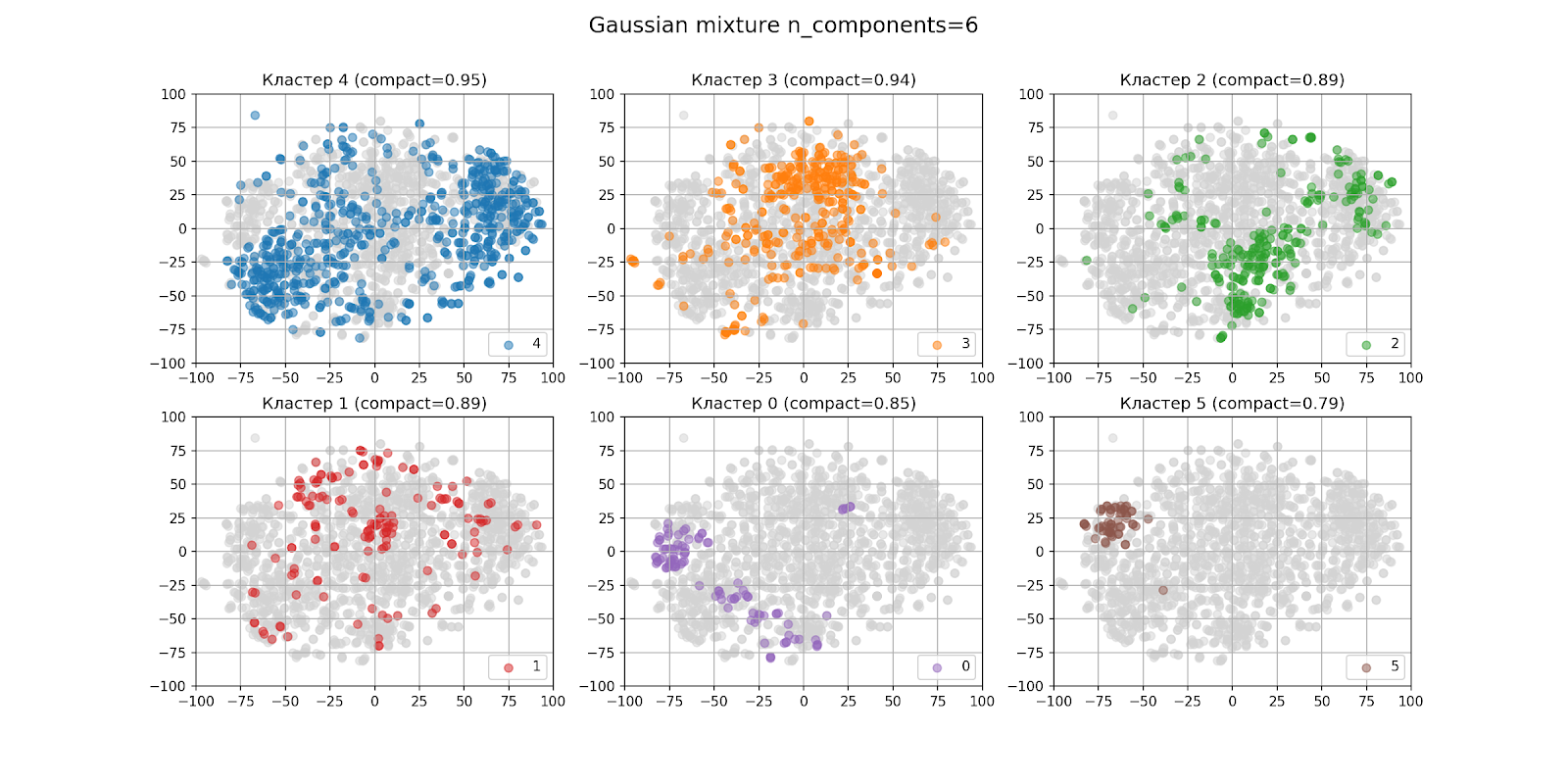
Pada gambar dengan output cluster terpisah, cluster disusun dalam urutan menurun dari jumlah titik dari kiri ke kanan, dari atas ke bawah: cluster 4 adalah yang terbesar, cluster 5 adalah yang terkecil. Kekompakan setiap cluster ditunjukkan dalam tanda kurung.
Secara tampilan, pengelompokannya ternyata tidak terlalu bagus, meskipun kami menganggap bahwa algoritme t-SNE tidak sempurna. Saat menganalisis cluster, hasilnya juga tidak menggembirakan.
Untuk menemukan jumlah cluster n_components yang optimal, kita akan menggunakan kriteria AIC dan BIC, yang dapat Anda baca di sini . Perhitungan kriteria ini dibangun ke dalam metode sklearn.mixture.GaussianMixture . Seperti inilah tampilan grafik kriteria:

Jika n_components = 12, kriteria BIC memiliki nilai terendah (terbaik), kriteria AIC juga memiliki nilai yang mendekati minimum (minimum jika n_components = 23). Kami melakukan pembagian pekerjaan menjadi 12 cluster:


Cluster sekarang lebih kompak, baik secara tampilan maupun numerik. Selama analisis manual, lowongan dibagi menjadi kelompok karakteristik untuk memahami seseorang. Gambar tersebut menunjukkan nama cluster. Cluster bernomor 11 dan 4 ditandai sebagai <Sampah 2>:
- Dalam cluster 11, semua fitur memiliki bobot total yang kira-kira sama.
- Cluster 4 didedikasikan untuk Java. Namun demikian, ada sedikit lowongan untuk posisi Java Developer di cluster, pengetahuan tentang Java sering kali diperlukan karena "akan menjadi nilai tambah tambahan".
Kluster
Setelah menghapus dua cluster yang tidak informatif bernomor 11 dan 4, hasilnya adalah 10 cluster:
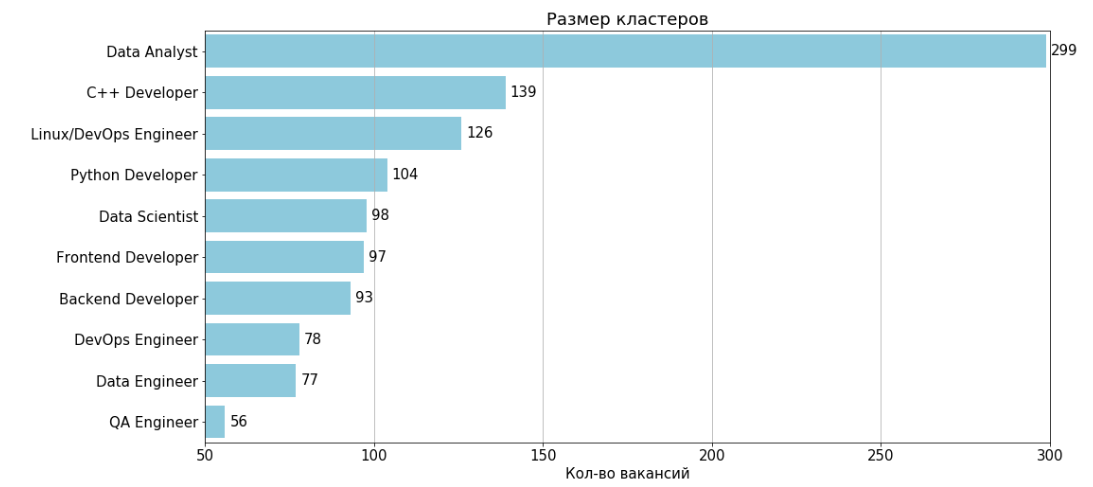
Untuk setiap cluster, terdapat tabel fitur dan 2-gram yang paling sering ditemukan di lowongan cluster.
Legenda:
S - proporsi kekosongan tempat sifat ditemukan, dikalikan dengan bobot sifat
% - persentase kekosongan tempat sifat / 2 gram ditemukan Kekosongan
klaster tipikal - kekosongan, dengan jarak rata-rata terkecil ke titik lain dari klaster
Analis data
Jumlah Pekerjaan: 299 Pekerjaan Umum
: 35.805.914
| Tidak. | Masuk dengan berat | S | Tanda | % | 2 gram | % |
| 1 | unggul | 3.13 | sql | 64.55 | pengetahuan tentang sql | 18.39 |
| 2 | r | 2.59 | unggul | 34.78 | dalam mengembangkan | 14.05 |
| 3 | sql | 2.44 | r | 28.76 | python r | 14.05 |
| 4 | pengetahuan tentang sql | 1.47 | dua | 19.40 | dengan besar | 13.38 |
| lima | analisis data | 1.17 | tablo | 15.38 | pengembangan dan | 13.38 |
| 6 | tablo | 1.08 | 14.38 | analisis data | 13.04 | |
| 7 | dengan besar | 1.07 | vba | 13.04 | pengetahuan tentang python | 12.71 |
| delapan | pengembangan dan | 1.07 | ilmu | 9.70 | gudang analitik | 11.71 |
| sembilan | vba | 1.04 | dwh | 6.35 | pengalaman pengembangan | 11.71 |
| sepuluh | pengetahuan tentang python | 1.02 | peramal | 6.35 | database | 11.37 |
Pengembang C ++
Jumlah Pekerjaan: 139 Pekerjaan Umum
: 39.955.360
| Tidak. | Masuk dengan berat | S | Tanda | % | 2 gram | % |
| 1 | c ++ | 9.00 | c ++ | 100.00 | pengalaman pengembangan | 44.60 |
| 2 | Jawa | 3.30 | linux | 44.60 | c c ++ | 27.34 |
| 3 | linux | 2.55 | Jawa | 36.69 | c ++ python | 17.99 |
| 4 | c # | 1.88 | sql | 23.02 | di c ++ | 16.55 |
| lima | Pergilah | 1.75 | c # | 20.86 | pengembangan pada | 15.83 |
| 6 | pengembangan pada | 1.27 | Pergilah | 19.42 | struktur data | 15.11 |
| 7 | pengetahuan yang baik | 1.15 | unix | 12.23 | pengalaman menulis | 14.39 |
| delapan | struktur data | 1.06 | tensorflow | 11.51 | pemrograman | 13.67 |
| sembilan | tensorflow | 1.04 | pesta | 10.07 | dalam mengembangkan | 13.67 |
| sepuluh | pengalaman pemrograman | 0.98 | postgresql.dll | 9.35 | bahasa pemrograman | 12.95 |
Teknisi Linux / DevOps
Jumlah Lowongan Kerja: 126
Jenis Pekerjaan : 39.533.926
| Tidak. | Masuk dengan berat | S | Tanda | % | 2 gram | % |
| 1 | mungkin | 5.33 | linux | 84.92 | ci cd | 58.73 |
| 2 | buruh pelabuhan | 4.78 | mungkin | 76.19 | pengalaman administrasi | 42.06 |
| 3 | pesta | 4.78 | buruh pelabuhan | 74.60 | bash python | 33.33 |
| 4 | ci cd | 4.70 | pesta | 68.25 | tcp ip | 39.37 |
| lima | linux | 4.43 | prometheus | 58.73 | pengalaman kustomisasi | 28.57 |
| 6 | prometheus | 4.11 | zabbix | 54.76 | pemantauan dan | 26.98 |
| 7 | nginx | 3.67 | nginx | 52.38 | prometheus grafana | 23.81 |
| delapan | pengalaman administrasi | 3.37 | grafana | 52.38 | sistem pemantauan | 22.22 |
| sembilan | zabbix | 3.29 | postgresql.dll | 51.59 | dengan buruh pelabuhan | 16.67 |
| sepuluh | rusa besar | 3.22 | kubernetes | 51.59 | manajemen konfigurasi | 16.67 |
Pengembang Python
Jumlah pekerjaan: 104
Lowongan umum: 39705484
| Tidak. | Masuk dengan berat | S | Tanda | % | 2 gram | % |
| 1 | dengan python | 6.00 | buruh pelabuhan | 65.38 | dengan python | 75.00 |
| 2 | django | 5.62 | django | 62.50 | pengembangan pada | 51.92 |
| 3 | labu | 4.59 | postgresql.dll | 58.65 | pengalaman pengembangan | 43.27 |
| 4 | buruh pelabuhan | 4.24 | labu | 50.96 | labu django | 04.24 |
| lima | pengembangan pada | 4.15 | redis | 38.46 | api istirahat | 23.08 |
| 6 | postgresql.dll | 2.93 | linux | 35.58 | python dari | 21.15 |
| 7 | aiohttp | 1.99 | kelincimq | 33.65 | database | 18.27 |
| delapan | redis | 1.92 | sql | 30.77 | pengalaman menulis | 18.27 |
| sembilan | linux | 1.73 | mongodb | 25.00 | dengan buruh pelabuhan | 17.31 |
| sepuluh | kelincimq | 1.68 | aiohttp | 22.12 | dengan postgresql | 16.35 |
Ilmuwan data
Jumlah lowongan: 98
Lowongan umum: 38071218
| Tidak. | Masuk dengan berat | S | Tanda | % | 2 gram | % |
| 1 | panda | 7.35 | panda | 81.63 | pembelajaran mesin | 63.27 |
| 2 | numpy | 6.04 | numpy | 75.51 | panda numpy | 43.88 |
| 3 | pembelajaran mesin | 5.69 | sql | 62.24 | analisis data | 29.59 |
| 4 | pytorch.dll | 3.77 | pytorch.dll | 41.84 | ilmu data | 26.53 |
| lima | ml | 3.49 | ml | 38.78 | pengetahuan tentang python | 25.51 |
| 6 | tensorflow | 3.31 | tensorflow | 36.73 | scipy numpy | 24.49 |
| 7 | analisis data | 2.66 | percikan | 32.65 | panda python | 23.47 |
| delapan | scikitlearn | 2.57 | scikitlearn | 28.57 | dengan python | 21.43 |
| sembilan | ilmu data | 2.39 | buruh pelabuhan | 27.55 | statistik matematika | 20.41 |
| sepuluh | percikan | 2.29 | hadoop | 27.55 | algoritma mesin | 20.41 |
Pengembang Frontend
Jumlah Pekerjaan: 97 Pekerjaan Umum
: 39.681.044
| Tidak. | Masuk dengan berat | S | Tanda | % | 2 gram | % |
| 1 | javascript | 9.00 | javascript | 100 | html css | 27.84 |
| 2 | django | 2.60 | html | 42.27 | pengalaman pengembangan | 25.77 |
| 3 | reaksi | 2.32 | postgresql.dll | 38.14 | dalam mengembangkan | 17.53 |
| 4 | nodejs | 2.13 | buruh pelabuhan | 37.11 | pengetahuan tentang javascript | 15.46 |
| lima | paling depan | 2.13 | css | 37.11 | dan dukungan | 15.46 |
| 6 | buruh pelabuhan | 2.09 | linux | 32.99 | python dan | 14.43 |
| 7 | postgresql.dll | 1.91 | sql | 31.96 | css javascript | 13.40 |
| delapan | linux | 1.79 | django | 28.87 | database | 12.37 |
| sembilan | html css | 1.67 | reaksi | 25.77 | dengan python | 12.37 |
| sepuluh | php | 1.58 | nodejs | 23.71 | desain dan | 11.34 |
Pengembang Backend
Jumlah Pekerjaan: 93 Pekerjaan Umum
: 40.226.808
| Tidak. | Masuk dengan berat | S | Tanda | % | 2 gram | % |
| 1 | django | 5.90 | django | 65.59 | python django | 26.88 |
| 2 | js | 4.74 | js | 52.69 | pengalaman pengembangan | 25.81 |
| 3 | reaksi | 2.52 | postgresql.dll | 40.86 | pengetahuan tentang python | 20.43 |
| 4 | buruh pelabuhan | 2.26 | buruh pelabuhan | 35.48 | dalam mengembangkan | 18.28 |
| lima | postgresql.dll | 2.04 | reaksi | 27.96 | ci cd | 17.20 |
| 6 | pemahaman prinsip | 1.89 | linux | 27.96 | pengetahuan percaya diri | 16.13 |
| 7 | pengetahuan tentang python | 1.63 | backend | 22.58 | api istirahat | 15.05 |
| delapan | backend | 1.58 | redis | 22.58 | html css | 13.98 |
| sembilan | ci cd | 1.38 | sql | 20.43 | kemampuan untuk memahami | 10.75 |
| sepuluh | paling depan | 1.35 | mysql.dll | 19.35 | pada orang asing | 10.75 |
Insinyur DevOps
Jumlah Pekerjaan: 78 Pekerjaan Umum
: 39634258
| Tidak. | Masuk dengan berat | S | Tanda | % | 2 gram | % |
| 1 | devops | 8.54 | devops | 94.87 | ci cd | 51.28 |
| 2 | mungkin | 5.38 | mungkin | 76.92 | bash python | 30.77 |
| 3 | pesta | 4.76 | linux | 74.36 | pengalaman administrasi | 24.36 |
| 4 | jenkins | 4.49 | pesta | 67.95 | dan dukungan | 23.08 |
| lima | ci cd | 4.10 | jenkins | 64.10 | buruh pelabuhan kubernetes | 20.51 |
| 6 | linux | 3.54 | buruh pelabuhan | 50.00 | pengembangan dan | 17.95 |
| 7 | buruh pelabuhan | 2.60 | kubernetes | 41.03 | pengalaman menulis | 17.95 |
| delapan | Jawa | 2.08 | sql | 29.49 | dan kustomisasi | 17.95 |
| sembilan | pengalaman administrasi | 1.95 | peramal | 25.64 | pengembangan dan | 16.67 |
| sepuluh | dan dukungan | 1.85 | openshift | 24.36 | pembuatan skrip | 14.10 |
Insinyur Data
Jumlah Pekerjaan: 77 Pekerjaan Umum
: 40.008.757
| Tidak. | Masuk dengan berat | S | Tanda | % | 2 gram | % |
| 1 | percikan | 6.00 | hadoop | 89.61 | pengolahan data | 38.96 |
| 2 | hadoop | 5.38 | percikan | 85.71 | data besar | 37.66 |
| 3 | Jawa | 4.68 | sql | 68.83 | pengalaman pengembangan | 23.38 |
| 4 | sarang lebah | 4.27 | sarang lebah | 61.04 | pengetahuan tentang sql | 22.08 |
| lima | skala | 3.64 | Jawa | 51.95 | pengembangan dan | 19.48 |
| 6 | data besar | 3.39 | skala | 51.95 | percikan hadoop | 19.48 |
| 7 | etl | 3.36 | etl | 48.05 | java scala | 19.48 |
| delapan | sql | 2.79 | aliran udara | 44.16 | kualitas data | 18.18 |
| sembilan | pengolahan data | 2.73 | kafka | 42.86 | dan pemrosesan | 18.18 |
| sepuluh | kafka | 2.57 | peramal | 35.06 | sarang hadoop | 18.18 |
Insinyur QA
Jumlah Pekerjaan: 56 Pekerjaan Umum
: 39630489
| Tidak. | Masuk dengan berat | S | Tanda | % | 2 gram | % |
| 1 | otomatisasi uji | 5.46 | sql | 46.43 | otomatisasi uji | 60.71 |
| 2 | pengalaman pengujian | 4.29 | qa | 42.86 | pengalaman pengujian | 53.57 |
| 3 | qa | 3.86 | linux | 35.71 | dengan python | 41.07 |
| 4 | dengan python | 3.29 | selenium | 32.14 | pengalaman otomatisasi | 35.71 |
| lima | pengembangan dan | 2.57 | web | 32.14 | pengembangan dan | 32.14 |
| 6 | sql | 2.05 | buruh pelabuhan | 30.36 | pengalaman pengujian | 30.36 |
| 7 | linux | 2.04 | jenkins | 26.79 | pengalaman menulis | 28.57 |
| delapan | selenium | 1.93 | backend | 26.79 | menguji | 23.21 |
| sembilan | web | 1.93 | pesta | 21.43 | pengujian otomatis | 21.43 |
| sepuluh | backend | 1.88 | ui | 19.64 | ci cd | 21.43 |
Gaji
Gaji ditunjukkan hanya di 261 (22%) lowongan dari 1.167 di cluster.
Saat menghitung gaji:
- Jika rentang "dari ... hingga ..." ditentukan, maka nilai rata-rata digunakan
- Jika hanya "dari ..." atau hanya "ke ..." yang diindikasikan, maka nilai ini diambil
- Perhitungan digunakan (atau diberikan) gaji setelah pajak (NET)
Di grafik:
- Cluster diberi peringkat dalam urutan menurun dari gaji median
- Bilah vertikal dalam kotak - median
- Kotak - rentang [Q1, Q3], di mana Q1 (25%) dan Q3 (75%) adalah persentil. Itu. 50% dari gaji jatuh ke dalam kotak
- "Kumis" termasuk gaji dari kisaran [Q1 - 1,5 * IQR, Q3 + 1,5 * IQR], di mana IQR = Q3 - Q1 - kisaran interkuartil
- Poin individu adalah anomali yang tidak jatuh ke kumis. (Ada anomali yang tidak termasuk dalam diagram)

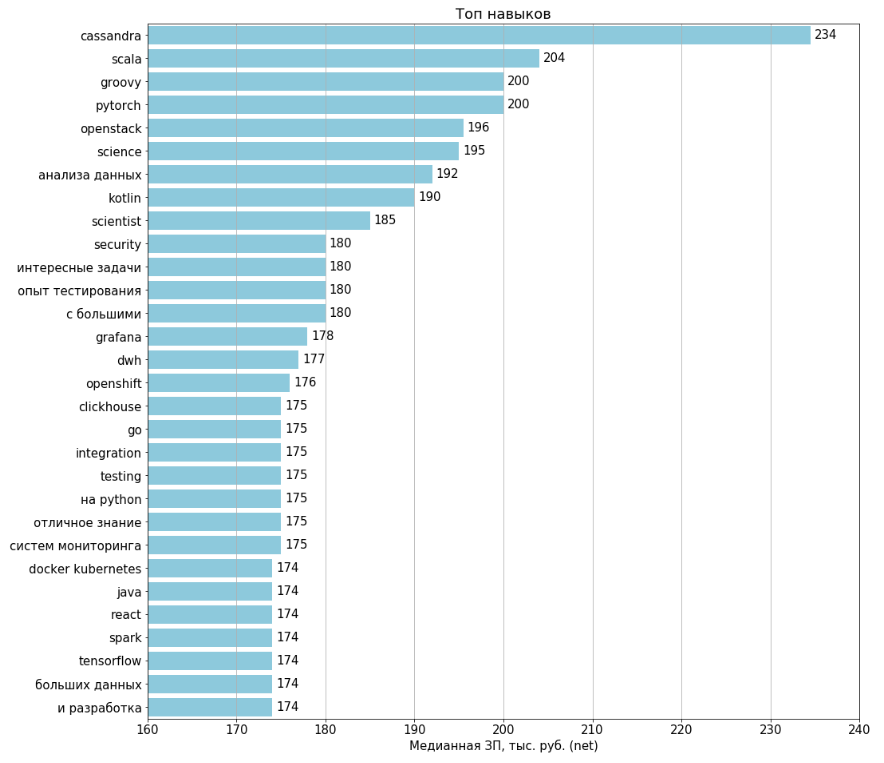
Keterampilan Top / Antitop
Grafik dibuat untuk semua lowongan yang diupload tahun 1994. Gaji ditunjukkan dalam 443 (22%) lowongan. Untuk kalkulasi untuk setiap fitur, lowongan dipilih di mana fitur ini ada, dan berdasarkan gaji rata-rata dihitung.

Klasifikasi pekerjaan
Pengelompokan dapat dibuat lebih mudah tanpa menggunakan model matematika yang rumit: untuk mengumpulkan nama-nama teratas dari lowongan, dan membaginya menjadi beberapa kelompok. Selanjutnya, analisis setiap kelompok untuk n-gram teratas dan gaji rata-rata. Tidak perlu menyoroti fitur dan menetapkan bobot padanya.
Pendekatan ini akan bekerja dengan baik (sampai batas tertentu) untuk kueri "Python". Tetapi untuk permintaan "1C Programmer" pendekatan ini tidak akan berhasil, karena untuk programmer 1C, nama lowongan jarang menunjukkan konfigurasi 1C atau area terapan. Dan ada banyak area di mana 1C digunakan: akuntansi, penghitungan gaji, penghitungan pajak, penghitungan biaya di perusahaan industri, akuntansi gudang, penganggaran, sistem ERP, ritel, akuntansi manajemen, dll.
Bagi saya sendiri, saya melihat dua tugas untuk menganalisis lowongan:
- Pahami di mana bahasa pemrograman yang saya tahu sedikit tentang digunakan (seperti dalam artikel ini).
- Filter pekerjaan baru yang diposting.
Pengelompokan cocok untuk memecahkan masalah pertama, untuk memecahkan masalah kedua - berbagai pengklasifikasi, hutan acak, pohon keputusan, jaringan saraf. Namun demikian, saya ingin mengevaluasi kesesuaian model yang dipilih untuk masalah klasifikasi pekerjaan.
Jika Anda menggunakan metode predict () yang ada di sklearn.mixture.GaussianMixture , maka tidak ada hal baik yang terjadi. Dia mengaitkan sebagian besar lowongan dengan cluster besar, dan dua dari tiga cluster pertama tidak informatif. Saya menggunakan pendekatan yang berbeda:
- Kami mengambil lowongan yang ingin kami klasifikasikan. Kami memvektorkannya dan mendapatkan titik di ruang kami.
- Kami menghitung jarak dari titik ini ke semua cluster. Di bawah jarak antara titik dan cluster, saya mengambil jarak rata-rata dari titik ini ke semua titik di cluster.
- Cluster dengan jarak terkecil merupakan kelas prediksi untuk lowongan yang dipilih. Jarak ke cluster menunjukkan keandalan prediksi semacam itu.
- Untuk meningkatkan akurasi model, saya memilih 0,87 sebagai jarak ambang, yaitu. Jika jarak ke cluster terdekat lebih dari 0.87, maka model tidak mengklasifikasikan kekosongan tersebut.
Untuk mengevaluasi model, 30 lowongan dipilih secara acak dari set pengujian. Pada kolom putusan:
T / a: model tidak mengklasifikasikan pekerjaan (jarak> 0.87)
+: klasifikasi benar
-: klasifikasi salah
| Lowongan | Kluster terdekat | Jarak | Putusan |
| 37637989 | Teknisi Linux / DevOps | 0,9464 | T / a |
| 37833719 | Pengembang C ++ | 0.8772 | T / a |
| 38324558 | Insinyur Data | 0.8056 | + |
| 38517047 | Pengembang C ++ | 0.8652 | + |
| 39053305 | Sampah | 0,9914 | T / a |
| 39210270 | Insinyur Data | 0.8530 | + |
| 39349530 | Pengembang Frontend | 0.8593 | + |
| 39402677 | Insinyur Data | 0.8396 | + |
| 39415267 | Pengembang C ++ | 0.8701 | T / a |
| 39734664 | Insinyur Data | 0.8492 | + |
| 39770444 | Pengembang Backend | 0.8960 | T / a |
| 39770752 | Ilmuwan data | 0.7826 | + |
| 39795880 | Analis data | 0,9202 | T / a |
| 39947735 | Pengembang Python | 0.8657 | + |
| 39954279 | Teknisi Linux / DevOps | 0.8398 | - |
| 40008770 | Insinyur DevOps | 0.8634 | - |
| 40015219 | Pengembang C ++ | 0.8405 | + |
| 40031023 | Pengembang Python | 0.7794 | + |
| 40072052 | Analis data | 0,9302 | T / a |
| 40112637 | Teknisi Linux / DevOps | 0.8285 | + |
| 40164815 | Insinyur Data | 0.8019 | + |
| 40186145 | Pengembang Python | 0.7865 | + |
| 40201231 | Ilmuwan data | 0.7589 | + |
| 40211477 | Insinyur DevOps | 0.8680 | + |
| 40224552 | Ilmuwan data | 0,9473 | T / a |
| 40230011 | Teknisi Linux / DevOps | 0,9298 | T / a |
| 40241704 | Sampah 2 | 0,9093 | T / a |
| 40245997 | Analis data | 0,9800 | T / a |
| 40246898 | Ilmuwan data | 0,9584 | T / a |
| 40267920 | Pengembang Frontend | 0.8664 | + |
Total: 12 lowongan tidak ada hasil, 2 lowongan - klasifikasi salah, 16 lowongan - klasifikasi benar. Kelengkapan model - 60%, akurasi model - 89%.
Sisi lemah
Masalah pertama - mari kita ambil dua lowongan:
Lowongan 1 - "Lead C ++ Programmer"
"Persyaratan:
- 5+ tahun pengalaman pengembangan C ++.
- Pengetahuan tentang Python akan menjadi nilai tambah tambahan. "
Lowongan 2 - "Lead Python Programmer"Dari sudut pandang model, lowongan ini identik. Saya mencoba menyesuaikan bobot fitur dengan urutan kemunculannya dalam teks. Ini tidak menghasilkan sesuatu yang baik.
"Persyaratan:
- 5+ tahun pengalaman pengembangan Python.
- Pengetahuan tentang C ++ akan menjadi nilai tambah tambahan "
Masalah kedua adalah GMM mengelompokkan semua titik dalam satu set, seperti banyak algoritme pengelompokan. Cluster non-informatif tidak menjadi masalah dengan sendirinya. Tetapi cluster informatif juga mengandung pencilan. Namun, hal ini dapat dengan mudah diselesaikan dengan membersihkan cluster, misalnya, dengan menghapus titik paling atipikal yang memiliki jarak rata-rata terbesar ke titik cluster lainnya.
Metode lain
Halaman perbandingan cluster mendemonstrasikan berbagai algoritma clustering dengan baik. GMM satu-satunya yang memberikan hasil bagus.
Algoritme lainnya tidak berfungsi atau memberikan hasil yang sangat sederhana.
Dari yang saya terapkan, hasil yang baik ada dalam dua kasus:
- Titik dengan kepadatan tinggi dipilih di beberapa lingkungan, terletak pada jarak yang jauh satu sama lain. Poin menjadi pusat cluster. Kemudian, berdasarkan pusat-pusat tersebut, proses pembentukan cluster dimulai - penggabungan titik-titik tetangga.
- Pengelompokan aglomeratif adalah penggabungan titik dan cluster berulang-ulang. Library scikit-learn menyajikan pengelompokan semacam ini, tetapi tidak berfungsi dengan baik. Dalam implementasinya, saya mengubah matriks gabungan setelah setiap iterasi penggabungan. Proses berhenti ketika beberapa parameter batas tercapai - pada kenyataannya, dendrogram tidak membantu untuk memahami proses penggabungan jika 1500 elemen dikelompokkan.
Kesimpulan
Riset yang saya lakukan memberi saya jawaban atas semua pertanyaan di awal artikel. Saya mendapat pengalaman langsung dengan pengelompokan sambil menerapkan variasi algoritme yang dikenal. Saya sangat berharap artikel ini akan memotivasi pembaca untuk melakukan penelitian analitisnya, dan entah bagaimana akan membantu dalam pelajaran yang menarik ini.