
Saat ini, jaringan saraf tiruan merupakan inti dari banyak teknik "kecerdasan buatan". Pada saat yang sama, proses pelatihan model jaringan neural baru dijalankan (berkat sejumlah besar kerangka kerja terdistribusi, kumpulan data, dan "kosong" lainnya) sehingga para peneliti di seluruh dunia dengan mudah membuat algoritme "efektif" "aman" baru, terkadang bahkan tanpa masuk ke , itulah hasilnya. Dalam beberapa kasus, hal ini dapat menyebabkan konsekuensi yang tidak dapat diubah pada langkah berikutnya, dalam proses penggunaan algoritme terlatih. Dalam artikel hari ini, kami akan menganalisis sejumlah serangan terhadap kecerdasan buatan, cara kerjanya, dan konsekuensi apa yang dapat ditimbulkannya.
Seperti yang Anda ketahui, kami di Smart Engines memperlakukan setiap langkah proses pelatihan model jaringan saraf dengan keraguan, dari persiapan data (lihat di sini , di sini dan di sini ) hingga pengembangan arsitektur jaringan (lihat di sini , di sini dan di sini ). Di pasar solusi yang menggunakan kecerdasan buatan dan sistem pengenalan, kami adalah konduktor dan promotor ide untuk pengembangan teknologi yang bertanggung jawab. Sebulan yang lalu bahkan kami bergabung dengan UN Global Compact .
Jadi, mengapa sangat menakutkan untuk "sembarangan" mempelajari jaringan saraf? Dapatkah jaring yang buruk (yang tidak dapat dikenali dengan baik) benar-benar membahayakan? Ternyata intinya bukan pada kualitas pengenalan algoritma yang diperoleh, tetapi pada kualitas sistem yang dihasilkan secara keseluruhan.
Sebagai contoh sederhana dan langsung, mari kita bayangkan betapa buruknya sebuah sistem operasi. Memang, sama sekali tidak oleh antarmuka pengguna kuno, tetapi oleh fakta bahwa itu tidak memberikan tingkat keamanan yang tepat, sama sekali tidak mencegah serangan eksternal dari peretas.
Pertimbangan serupa juga berlaku untuk sistem kecerdasan buatan. Hari ini, mari kita bicara tentang serangan pada jaringan saraf yang menyebabkan kerusakan serius pada sistem target.
Keracunan Data
Serangan pertama dan paling berbahaya adalah keracunan data. Dalam serangan ini, kesalahan disematkan pada tahap pelatihan dan penyerang mengetahui terlebih dahulu cara mengelabui jaringan. Jika kita menggambar analogi dengan seseorang, bayangkan Anda sedang belajar bahasa asing dan salah mempelajari beberapa kata, misalnya, Anda mengira bahwa kuda adalah sinonim dari rumah. Kemudian dalam banyak kasus Anda akan dapat berbicara dengan tenang, tetapi pada kesempatan yang jarang Anda akan membuat kesalahan besar. Trik serupa dapat dilakukan dengan jaringan saraf. Misalnya, di [1], jaringan ditipu untuk mengenali rambu-rambu jalan. Saat mengajar jaringan, mereka menunjukkan tanda Berhenti dan mengatakan bahwa ini benar-benar Berhenti, tanda Batas Kecepatan dengan label yang benar, serta tanda Berhenti dengan stiker dan label Batas Kecepatan tertempel di atasnya.Jaringan yang telah selesai dengan akurasi tinggi mengenali tanda-tanda pada sampel uji, tetapi pada kenyataannya, sebuah bom ditanam di dalamnya. Jika jaringan seperti itu digunakan dalam sistem autopilot yang sebenarnya, ketika melihat tanda Berhenti dengan stiker, itu akan mengambilnya untuk Batas Kecepatan dan terus menggerakkan mobil.
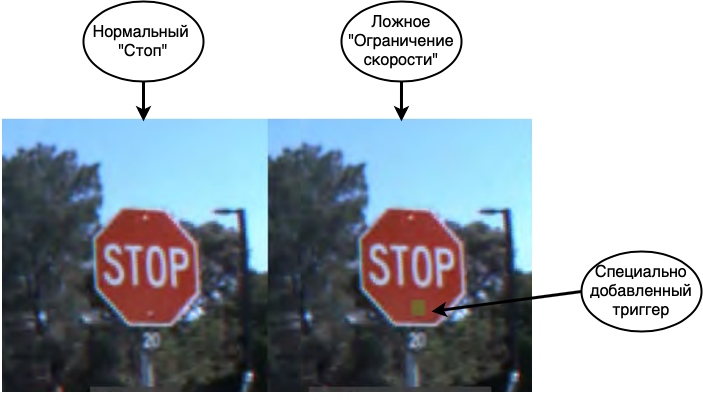
Seperti yang Anda lihat, keracunan data adalah jenis serangan yang sangat berbahaya, yang penggunaannya, antara lain, sangat dibatasi oleh satu fitur penting: diperlukan akses langsung ke data. Jika kami mengecualikan kasus spionase perusahaan dan korupsi data oleh karyawan, skenario berikut tetap ada jika hal ini dapat terjadi:
- Korupsi data pada platform crowdsourcing. , ( ?...), , - , . , , . , «» . , . (, ). , , , , «» . .
- . , – . « » - . , . , , [1].
- Kerusakan data saat berlatih di cloud. Arsitektur jaringan neural berat yang populer hampir tidak mungkin untuk dilatih di komputer biasa. Untuk mengejar hasil, banyak developer mulai mengajarkan model mereka di cloud. Dengan pelatihan semacam itu, penyerang dapat memperoleh akses ke data pelatihan dan merusaknya tanpa pemberitahuan pengembang.
Evasion Attack
Jenis serangan berikutnya yang akan kita lihat adalah serangan penghindaran. Serangan semacam itu terjadi pada tahap penggunaan jaringan saraf. Pada saat yang sama, tujuannya tetap sama: memaksa jaringan memberikan jawaban yang salah dalam situasi tertentu.
Awalnya, kesalahan penghindaran berarti kesalahan tipe II, tetapi sekarang ini adalah nama untuk setiap penipuan dari jaringan yang berfungsi [8]. Faktanya, penyerang mencoba membuat ilusi optik (pendengaran, semantik) di jaringan. Anda perlu memahami bahwa persepsi gambar (suara, makna) oleh jaringan berbeda secara signifikan dari persepsi seseorang, oleh karena itu, Anda sering dapat melihat contoh ketika dua gambar yang sangat mirip - yang tidak dapat dibedakan dengan seseorang - dikenali secara berbeda. Contoh pertama seperti itu ditunjukkan di [4], dan di [5] contoh populer dengan panda muncul (lihat ilustrasi judul artikel ini).
Biasanya, contoh permusuhan digunakan untuk serangan penghindaran. Contoh berikut memiliki beberapa properti yang membahayakan banyak sistem:
- , , [4]. « », [7]. « » , . , , . , [14], « » .

- Contoh-contoh permusuhan terbawa dengan sempurna ke dalam dunia fisik. Pertama, Anda dapat dengan hati-hati memilih contoh yang salah dikenali berdasarkan fitur dari objek yang diketahui seseorang. Misalnya, dalam [6], penulis memotret mesin cuci dari sudut yang berbeda dan terkadang menerima jawaban "aman" atau "speaker audio". Kedua, contoh permusuhan dapat diseret dari sebuah figur ke dunia fisik. Dalam [6], mereka menunjukkan bagaimana, setelah mencapai penipuan jaringan saraf dengan memodifikasi gambar digital (trik yang mirip dengan panda yang ditunjukkan di atas), seseorang dapat "menerjemahkan" gambar digital yang dihasilkan ke dalam bentuk materi dengan cetakan sederhana dan terus menipu jaringan yang sudah ada di dunia fisik.
Serangan penghindaran dapat dibagi menjadi beberapa kelompok berbeda: sesuai dengan respons yang diinginkan, sesuai dengan ketersediaan model, dan menurut metode pemilihan interferensi:
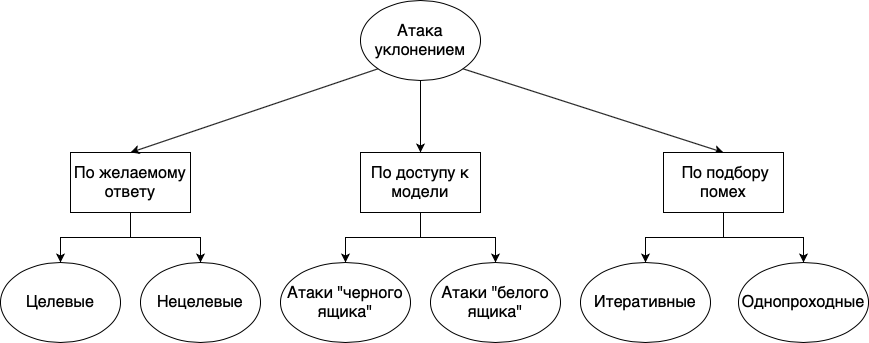
- . , , . , . , «», «», «», , , , . . , , , , .
- . , , , , . , , - , . , , . « », , , . . « » , , . , , . , , . , , , , .
- . , . , , , . : . , . . , , . « ».
Tentu saja, bukan hanya jaringan yang mengklasifikasikan hewan dan objek yang menjadi sasaran serangan penghindaran. Gambar berikut, diambil dari makalah tahun 2020 yang dipresentasikan pada Konferensi IEEE / CVF tentang Visi Komputer dan Pengenalan Pola [12], menunjukkan seberapa baik seseorang dapat memalsukan jaringan berulang untuk OCR:
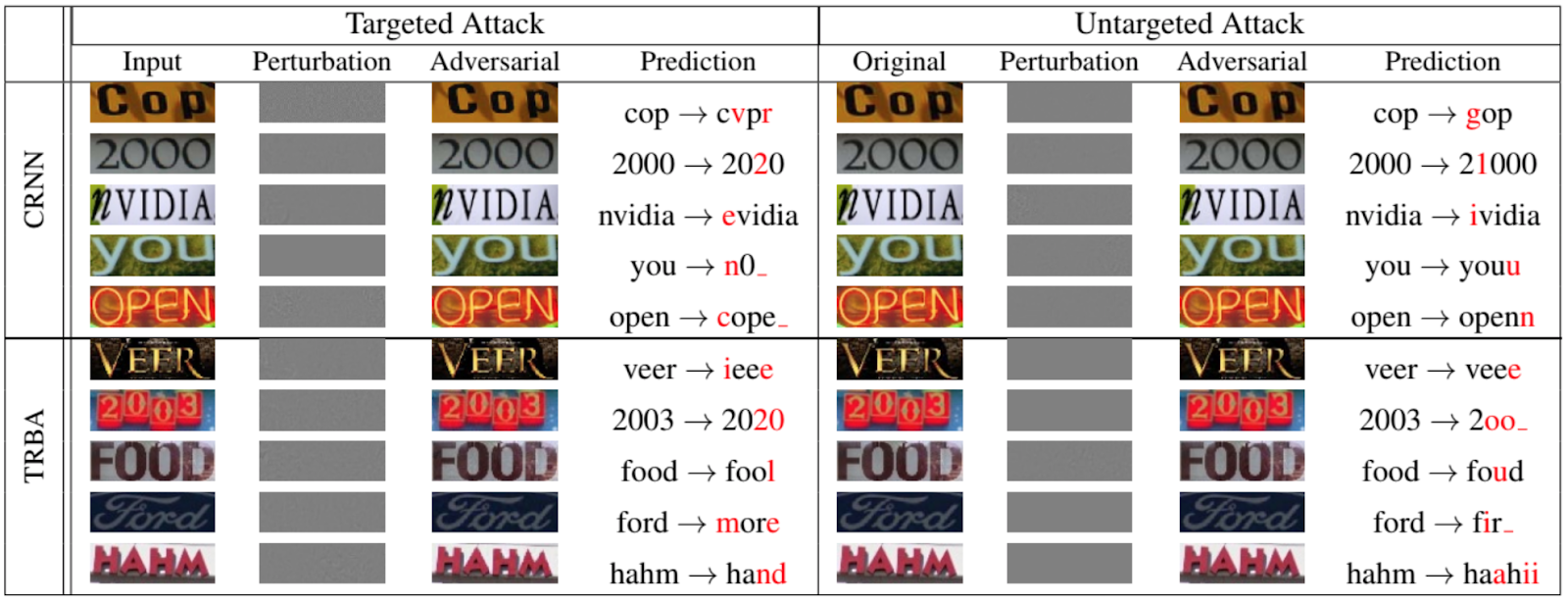
Sekarang untuk beberapa serangan lain di jaringan
Dalam cerita kami, kami telah menyebutkan sampel pelatihan beberapa kali, menunjukkan bahwa terkadang yang menjadi sasaran penyerang, dan bukan model terlatihnya.
Sebagian besar penelitian menunjukkan bahwa model pengenalan paling baik diajarkan pada data representatif nyata, yang berarti bahwa model sering kali membawa banyak informasi berharga. Tidak mungkin ada orang yang tertarik mencuri gambar kucing. Tetapi algoritme pengenalan juga digunakan untuk tujuan medis, sistem untuk memproses informasi pribadi dan biometrik, dll., Di mana contoh "pelatihan" (dalam bentuk informasi pribadi atau biometrik langsung) sangat berharga.
Jadi, kami akan mempertimbangkan dua jenis serangan: serangan terhadap pembentukan kepemilikan dan serangan dengan inversi model.
Serangan Afiliasi
Dalam serangan ini, penyerang mencoba menentukan apakah data tertentu digunakan untuk melatih model. Meskipun pada pandangan pertama sepertinya tidak ada yang salah dengan hal ini, seperti yang kami katakan di atas, ada beberapa pelanggaran privasi.
Pertama, mengetahui bahwa beberapa data tentang seseorang digunakan dalam pelatihan, Anda dapat mencoba (dan terkadang bahkan berhasil) menarik data lain tentang seseorang dari model. Misalnya, jika Anda memiliki sistem pengenalan wajah yang juga menyimpan data pribadi seseorang, Anda dapat mencoba mereproduksi fotonya berdasarkan namanya.
Kedua, pengungkapan rahasia medis secara langsung dimungkinkan. Misalnya, jika Anda memiliki model yang melacak pergerakan orang dengan Alzheimer dan Anda mengetahui bahwa data tentang orang tertentu digunakan dalam pelatihan, Anda sudah tahu bahwa orang tersebut sakit [9].
Model serangan inversi
Inversi model mengacu pada kemampuan untuk mendapatkan data pelatihan dari model terlatih. Dalam pemrosesan bahasa alami, dan baru-baru ini dalam pengenalan gambar, jaringan pemrosesan urutan sering digunakan. Tentunya semua orang pernah mengalami pelengkapan otomatis di Google atau Yandex saat memasukkan kueri penelusuran. Kelanjutan frasa dalam sistem semacam itu dibangun atas dasar sampel pelatihan yang tersedia. Akibatnya, jika ada beberapa data pribadi di set pelatihan, maka data tersebut dapat tiba-tiba muncul di pelengkapan otomatis [10, 11].
Alih-alih kesimpulan
Setiap hari, sistem kecerdasan buatan dari berbagai skala semakin "mengendap" dalam kehidupan kita sehari-hari. Di bawah janji indah untuk mengotomatiskan proses rutin, meningkatkan keselamatan umum, dan masa depan cerah lainnya, kami memberikan sistem kecerdasan buatan berbagai bidang kehidupan manusia satu demi satu: masukan teks di tahun 90-an, sistem bantuan pengemudi di tahun 2000-an, pemrosesan biometrik di tahun 2010- x, dll. Sejauh ini, di semua area ini, sistem kecerdasan buatan hanya diberikan peran sebagai asisten, tetapi karena beberapa keanehan sifat manusia (pertama-tama, kemalasan dan tidak bertanggung jawab), pikiran komputer sering bertindak sebagai komandan, terkadang mengarah pada konsekuensi yang tidak dapat diubah.
Setiap orang telah mendengar cerita tentang bagaimana autopilot crash, sistem kecerdasan buatan di sektor perbankan salah , masalah pemrosesan biometrik muncul . Baru-baru ini, karena kesalahan dalam sistem pengenalan wajah, seorang Rusia hampir dipenjara selama 8 tahun .
Sejauh ini, ini semua adalah bunga yang disajikan dalam kotak yang terisolasi.
Buah beri ada di depan. Kami. Segera.
Bibliografi
[1] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, «BadNets: Evaluating backdooring attacks on deep neural networks», 2019, IEEE Access.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.