
Seperti apa datanya?
Pertama, mari kita lihat data pengujian dan pelatihan yang tersedia (data dari tantangan klasifikasi komentar Beracun di platform kaggle.com). Dalam data pelatihan, berbeda dengan data pengujian, terdapat label untuk klasifikasi:
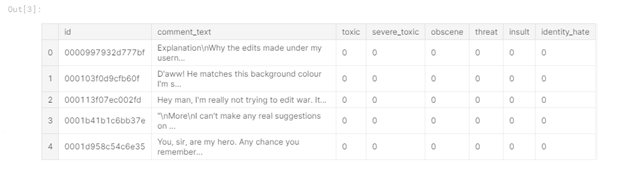
Gambar 1 - Melatih kepala data
Dari tabel Anda dapat melihat bahwa dalam data pelatihan kami memiliki 6 kolom label ("toxic", "sever_toxic", "obscene", "ancaman" , "Insult", "identity_hate"), dengan nilai "1" menunjukkan bahwa komentar tersebut termasuk dalam kelas, ada juga kolom "comment_text" yang berisi komentar dan kolom "id" - pengenal komentar.
Data pengujian tidak mengandung label kelas, seperti yang digunakan untuk mengirimkan solusi:

Gambar 2 - Kepala data uji
Ekstraksi fitur
Langkah selanjutnya adalah mengekstrak fitur dari komentar dan melakukan analisis data eksplorasi (EDA). Pertama, mari kita lihat distribusi jenis komentar dalam set data pelatihan. Untuk ini, kolom baru "toxic_type" telah dibuat, berisi semua kelas yang memiliki komentar tersebut:

Gambar 3 - 10 jenis komentar beracun teratas
Dari tabel Anda dapat melihat bahwa jenis yang berlaku adalah tidak adanya tag kelas, dan banyak komentar milik lebih dari satu kelas.
Mari kita lihat juga bagaimana jumlah tipe untuk setiap komentar didistribusikan:

Gambar 4 - Jumlah tipe yang ditemukan
Perhatikan bahwa situasi yang berlaku adalah ketika sebuah komentar hanya ditandai dengan satu jenis toksisitas, dan komentar tersebut cukup sering dicirikan oleh tiga jenis toksisitas, dan komentar tersebut lebih jarang dikaitkan ke semua jenis.
Sekarang mari beralih ke tahap mengekstraksi fitur dari teks, yang sering disebut ekstraksi fitur. Saya mengekstrak atribut berikut:
Panjang komentar. Saya rasa komentar marah tersebut kemungkinan besar pendek;
Huruf besar. Dalam komentar emosional-agresif, ada kemungkinan bahwa huruf besar lebih umum dalam kata-kata;
Emotikon. Saat menulis komentar beracun, emotikon berwarna positif (:), dll.) Kemungkinan tidak akan digunakan, pertimbangkan juga keberadaan emotikon sedih (:(, dll.);
Tanda baca. Mungkin, penulis komentar negatif tidak mematuhi aturan tanda baca, lebih luas lagi mereka menggunakan "!";
Jumlah karakter pihak ketiga. Beberapa orang sering menggunakan simbol @, $, dll saat menulis kata-kata yang menyinggung.
Fitur ditambahkan sebagai berikut:
train_data[‘total_length’] = train_data[‘comment_text’].apply(len)
train_data[‘uppercase’] = train_data[‘comment_text’].apply(lambda comment: sum(1 for c in comment if c.isupper()))
train_data[‘exclamation_punction’] = train_data[‘comment_text’].apply(lambda comment: comment.count(‘!’))
train_data[‘num_punctuation’] = train_data[‘comment_text’].apply(lambda comment: comment.count(w) for w in ‘.,;:?’))
train_data[‘num_symbols’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in ‘*&$%’))
train_data[‘num_words’] = train_data[‘comment_text’].apply(lambda comment: len(comment.split()))
train_data[‘num_happy_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-)’, ‘:)’, ‘;)’, ‘;-)’)))
train_data[‘num_sad_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-(’, ‘:(’, ‘;(’, ‘;-(’)))Analisis data eksplorasi
Sekarang mari kita jelajahi data menggunakan fitur yang baru saja kita dapatkan. Pertama-tama, mari kita lihat korelasi fitur satu sama lain, korelasi antara fitur dan label kelas, korelasi antara label kelas:

Gambar 5 - Korelasi
Korelasi menunjukkan adanya hubungan linier antara fitur. Semakin dekat nilai korelasi dalam modulus dengan 1, semakin jelas ketergantungan linier antar elemen.
Misalnya, Anda dapat melihat bahwa jumlah kata dan panjang teks sangat berkorelasi satu sama lain (nilai 0.99), yang berarti bahwa beberapa fitur dapat dihilangkan, saya menghapus jumlah kata. Kita juga dapat menarik beberapa kesimpulan lagi: praktis tidak ada korelasi antara fitur yang dipilih dan label kelas, fitur yang paling tidak berkorelasi adalah jumlah karakter, dan panjang teks berkorelasi dengan jumlah karakter tanda baca dan jumlah karakter huruf besar.
Selanjutnya, kita akan membangun beberapa visualisasi untuk pemahaman yang lebih detail tentang pengaruh fitur pada label kelas. Pertama, mari kita lihat bagaimana panjang komentar didistribusikan:

Gambar 6 - Distribusi panjang komentar (grafiknya interaktif, tetapi berikut adalah tangkapan layarnya)
Seperti yang diharapkan, komentar yang belum dikategorikan (yaitu normal) lebih panjang dari komentar yang diberi tag. Dari komentar negatif, yang terpendek adalah ancaman, dan yang terpanjang beracun.
Sekarang mari kita periksa komentar dalam kaitannya dengan tanda baca. Kami akan membuat representasi grafis untuk nilai rata-rata agar grafik lebih dapat ditafsirkan:

Gambar 7 - Nilai tanda baca rata-rata (grafik bersifat interaktif, tetapi ini adalah tangkapan layar)
Dari gambar, Anda dapat melihat bahwa kami mendapat tiga cluster.
Komentar pertama - normal, ditandai dengan ketaatan pada aturan tanda baca (penempatan tanda baca, ":", misalnya) dan sejumlah kecil tanda seru.
Yang kedua terdiri dari ancaman (ancaman) dan komentar yang sangat toksik (toksik berat), kelompok ini ditandai dengan penggunaan tanda seru yang melimpah dan tanda baca lainnya digunakan di tingkat menengah.
Cluster ketiga - toksik (beracun), cabul (cabul), penghinaan (penghinaan) dan kebencian terhadap orang tertentu (identitas benci) memiliki sedikit tanda baca dan tanda seru.
Mari tambahkan sumbu ketiga untuk kejelasan - huruf besar:

Gambar 8 -Gambar tiga dimensi (interaktif, tapi berikut tangkapan layarnya)
Di sini kita melihat situasi yang sama - tiga cluster disorot. Perlu diketahui juga bahwa jarak antar elemen cluster kedua lebih besar dari jarak antar elemen cluster ketiga. Ini juga dapat dilihat pada grafik 2D:

Gambar 9 - Huruf besar dan tanda baca (interaktif, berikut tangkapan layarnya)
Sekarang mari kita lihat jenis komentar dalam konteks huruf besar / jumlah karakter pihak ketiga:

Gambar 10 - Huruf besar dan jumlah karakter pihak ketiga (interaktif, berikut adalah tangkapan layar)
Seperti yang Anda lihat, komentar yang sangat beracun dengan jelas disorot - memiliki banyak karakter huruf besar dan banyak karakter pihak ketiga. Selain itu, simbol pihak ketiga secara aktif digunakan oleh penulis komentar yang menimbulkan kebencian bagi sebagian orang.
Dengan demikian, menyoroti fitur baru dan memvisualisasikannya memungkinkan interpretasi yang lebih baik dari data yang tersedia, dan visualisasi di atas dapat diringkas sebagai berikut:
Komentar yang sangat beracun dipisahkan dari yang lain;
Komentar biasa juga menonjol;
Komentar yang bersifat toksik, cabul, dan menyinggung sangat mirip satu sama lain dalam hal karakteristik yang dipertimbangkan.
Menggunakan DataFrameMapper untuk Menggabungkan Fitur Teks dan Numerik
Sekarang, mari kita lihat bagaimana Anda dapat menggunakan fitur teks dan numerik secara bersamaan dalam regresi logistik.
Pertama, Anda perlu memilih model untuk mewakili teks dalam bentuk yang sesuai untuk algoritme pembelajaran mesin. Saya menggunakan model tf-idf, karena dapat menyorot kata-kata tertentu dan membuat kata-kata yang sering menjadi kurang signifikan (misalnya, preposisi):
tvec = TfidfVectorizer(
sublinear_tf=True,
strip_accents=’unicode’,
analyzer=’word’,
token_pattern=r’\w{1,}’,
stop_words=’english’,
ngram_range=(1, 1),
max_features=10000
)Jadi, jika kita ingin bekerja dengan kerangka data yang disediakan oleh pustaka Pandas dan algoritme pembelajaran mesin pustaka Sklearn, kita bisa menggunakan modul Sklearn-pandas, yang berfungsi sebagai semacam pengikat antara kerangka data dan metode Sklearn.
mapper = DataFrameMapper([
([‘uppercase’], StandardScaler()),
([‘exclamation_punctuation’], StandardScaler()),
([‘num_punctuation’], StandardScaler()),
([‘num_symbols’], StandardScaler()),
([‘num_happy_smilies’], StandardScaler()),
([‘num_sad_smilies’], StandardScaler()),
([‘total_length’], StandardScaler())
], df_out=True)Pertama, Anda perlu membuat DataFrameMapper seperti yang ditunjukkan di atas, itu harus berisi nama kolom dengan fitur numerik. Selanjutnya, kami membuat matriks fitur, yang kemudian akan kami transfer ke regresi logistik untuk pelatihan:
x_train = np.round(mapper.fit_transform(numeric_features_train.copy()), 2).values
x_train_features = sparse.hstack((csr_matrix(x_train), train_texts))Urutan tindakan serupa juga dilakukan pada kumpulan data pengujian.
Eksperimen komputasi
Untuk melakukan klasifikasi multi-label, kita akan membuat loop yang akan melalui semua kategori dan mengevaluasi kualitas klasifikasi dengan validasi silang dengan parameter cv = 3 dan scoring = 'roc_auc':
scores = []
class_names = [‘toxic’, ‘severe_toxic’, ‘obscene’, ‘threat’, ‘identity_hate’]
for class_name in class_names:
train_target = train_data[class_name]
classifier = LogisticRegression(C=0.1, solver= ‘sag’)
cv_score = np.mean(cross_val_score(classifier, x_train_features, train_target, cv=3, scoring= ‘auc_roc’))
scores.append(cv_score)
print(‘CV score for class {} is {}’.format(class_name, cv_score))
classifier.fit(train_features, train_target)
print(‘Total CV score is {}’.format(np.mean(scores)))</source
<b> :</b>
<img src="https://habrastorage.org/webt/kt/a4/v6/kta4v6sqnr-tar_auhd6bxzo4dw.png" />
<i> 11 — </i>
, , , , , . , , , . - , “toxic”, , , ( 3). , , , .