Artikel ini muncul karena beberapa alasan.
Pertama, di sebagian besar buku, sumber daya Internet dan pelajaran tentang Ilmu Data, nuansa, kekurangan dari berbagai jenis normalisasi data dan alasannya tidak dipertimbangkan sama sekali, atau hanya disebutkan secara sepintas dan tanpa mengungkapkan esensinya.
Kedua, ada penggunaan "buta", misalnya, standarisasi untuk set dengan sejumlah besar fitur - "sehingga sama untuk semua orang." Apalagi untuk pemula (dia sendiri juga sama). Sekilas tidak apa-apa. Tetapi setelah diteliti lebih dekat, mungkin ternyata beberapa tanda secara tidak sadar ditempatkan pada posisi istimewa dan mulai mempengaruhi hasilnya jauh lebih kuat daripada yang seharusnya.
Dan, ketiga, saya selalu ingin mendapatkan metode universal yang memperhitungkan area masalah.
Pengulangan adalah ibu dari pembelajaran
Normalisasi adalah konversi data ke unit tanpa dimensi tertentu. Terkadang - dalam rentang tertentu, misalnya, [0..1] atau [-1..1]. Terkadang - dengan beberapa properti tertentu, seperti, misalnya, deviasi standar 1.
Tujuan utama normalisasi adalah membawa data yang berbeda dalam berbagai unit dan rentang nilai ke satu bentuk yang memungkinkan Anda membandingkannya satu sama lain atau menggunakannya untuk menghitung kemiripan objek. Dalam praktiknya, ini diperlukan, misalnya untuk pengelompokan dan dalam beberapa algoritme pembelajaran mesin.
Secara analitis, normalisasi apapun direduksi menjadi rumus
Dimana - nilai saat ini,
- nilai nilai offset,
- nilai interval yang akan diubah menjadi "satu"
Faktanya, itu semua bermuara pada fakta bahwa kumpulan nilai asli pertama-tama digeser dan kemudian diskalakan.
Contoh:
Minimax (MinMax) . Tujuannya adalah untuk mengonversi kumpulan asli ke kisaran [0..1]. Untuk dia:
= , nilai minimum data awal.
= - , yaitu interval "unit" diambil dari kisaran nilai aslinya.
. — 0 1.
= , .
— .
, .
, , “” . .
, - . , . , , . , . , — . , , , , *
* — , , ( ), , .
, — .
1 —
— .. , , 0 “” .
? « » . .
№ 1 — , .
, “ ” , , — , . ( ). ( ) .
, , .
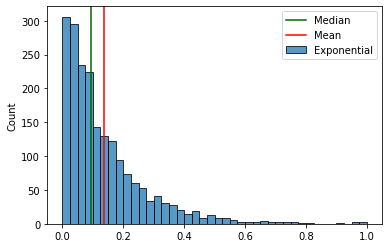
:
. “” .
, , , . .
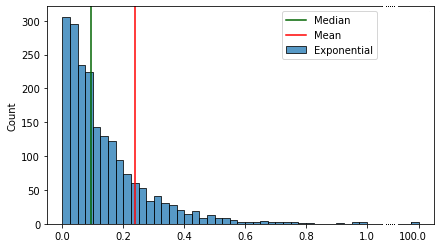
2 —
. .
. , , [-1..1], . [-1..1], — [-1..100], , . .
. . , “”.
( ):

( ) , .
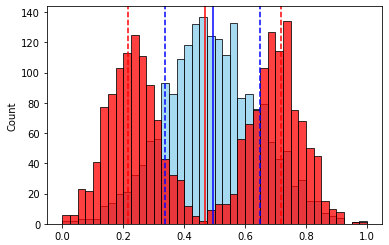
, () “”, .

— ( ). , “” .
75- 25- — . .. , “” 50% . “” / .
— “”, “” .
№ 2 — “” .
— .
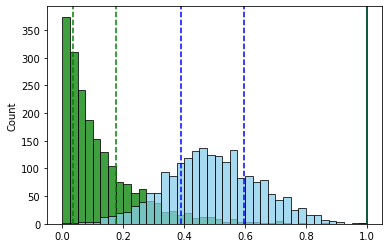
( ).

- “” . , , “”.
. .. . — 1.
, , , № 3 — . ( ) .
, , . 2-
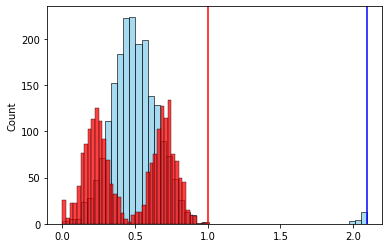
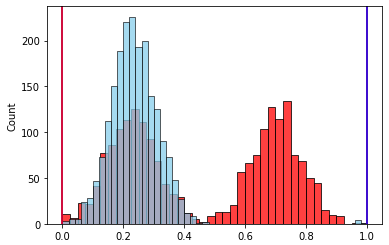
, , . .
, “-”. — .
— , . , . , , , , ? .
, . , “” , 1,5 (IQR) .*
* — ( .) 1,5 3 — .
.
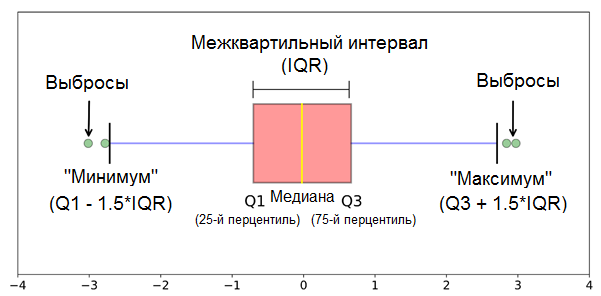
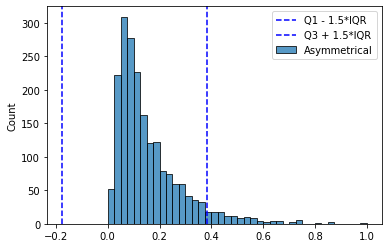
— - , .
. (, , ) “” — 7%. (3 * IQR) — . . .. .
, . “ ” (1,5 * IQR) , . , - “” .
(Mia Hubert and Ellen Vandervieren) 2007 . “An Adjusted Boxplot for Skewed Distributions”.
“ ” , 1,5 * IQR.
“ ” medcouple (MC), :
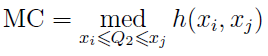
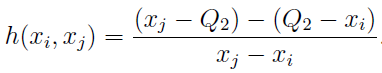
“ ” , , , 1,5 * IQR — 0,7%
:
:

:
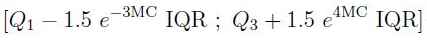
. .
, , :
- , , .
- .
- () — , , [0..1]
… — Mia Hubert Ellen Vandervieren
. .
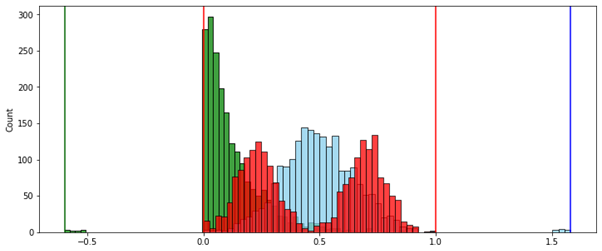
, ( ) (MinMax — ).
№ 1 — . . , “” .
:
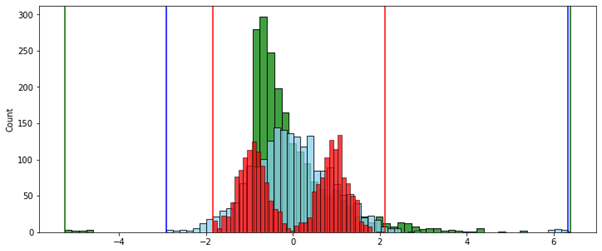
( ):

:

, — , , .
№ 2 — . [0..1]. , , .
MinMax ( ):
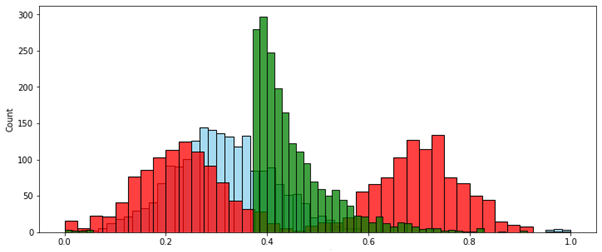
:
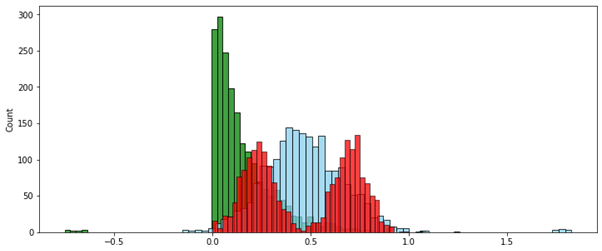
. -, , — .. 0 1.
, “” [0..1], , — , , , . .
* * *
Akhirnya, untuk kesempatan merasakan metode ini dengan tangan Anda, Anda dapat mencoba kelas demo saya AdjustedScaler dari sini .
Ini tidak dioptimalkan untuk bekerja dengan jumlah data yang sangat besar dan hanya bekerja dengan DataFrame panda, tetapi untuk percobaan, eksperimen, atau bahkan blank untuk sesuatu yang lebih serius, ini sangat cocok. Cobalah.