
Beberapa kata tentang sistem pemberi rekomendasi
Tentunya, semua orang bertemu mereka lebih dari sekali. Sistem pemberi rekomendasi adalah program dan layanan yang mencoba memprediksi apa yang mungkin menarik / dibutuhkan / berguna bagi pengguna tertentu, dan menunjukkan hal ini kepada mereka. “Apakah kamu suka sepatu lari ini? Anda mungkin juga membutuhkan jaket, pemantau detak jantung, dan 15 item olahraga lainnya . " Dalam beberapa tahun terakhir, merek sangat aktif dalam memperkenalkan sistem rekomendasi ke dalam pekerjaan mereka, karena penjual dan pembeli "mendapat manfaat" dari keputusan ini. Konsumen menerima alat yang membantu mereka membuat pilihan dalam variasi barang dan jasa yang tak terbatas dalam waktu singkat, dan bisnis menumbuhkan penjualan dan audiens.
Apa yang telah diberikan kepada kita?
Saya mengerjakan proyek untuk perusahaan global besar yang menyediakan solusi pertukaran pengiriman SaaS atau platform pertukaran pengiriman kepada pelanggannya.
Kedengarannya tidak bisa dimengerti, tetapi bagaimana hal itu sebenarnya terjadi: di satu sisi, pengguna terdaftar di platform yang memiliki barang dan perlu mengirimnya ke suatu tempat. Mereka menempatkan aplikasi seperti "Ada sekumpulan kosmetik dekoratif, perlu dibawa besok dari Amsterdam ke Antwerpen"dan menunggu jawaban. Di sisi lain, kami memiliki orang atau perusahaan dengan truk - pengangkut barang. Katakanlah mereka telah melakukan penerbangan mingguan standar, mengantarkan yoghurt dari Paris ke Brussel. Mereka harus kembali dan, agar tidak pergi dengan truk kosong, cari beberapa jenis kargo untuk diangkut dalam perjalanan pulang. Untuk melakukan ini, operator kargo pergi ke platform pelanggan saya dan melakukan pencarian (dari pencarian dalam bahasa Inggris), menunjukkan arah dan, mungkin, jenis kargo (atau kargo, dari kargo Inggris), yang cocok untuk sebuah truk. Sistem mengumpulkan aplikasi dari pengirim dan menunjukkannya ke operator pengiriman.
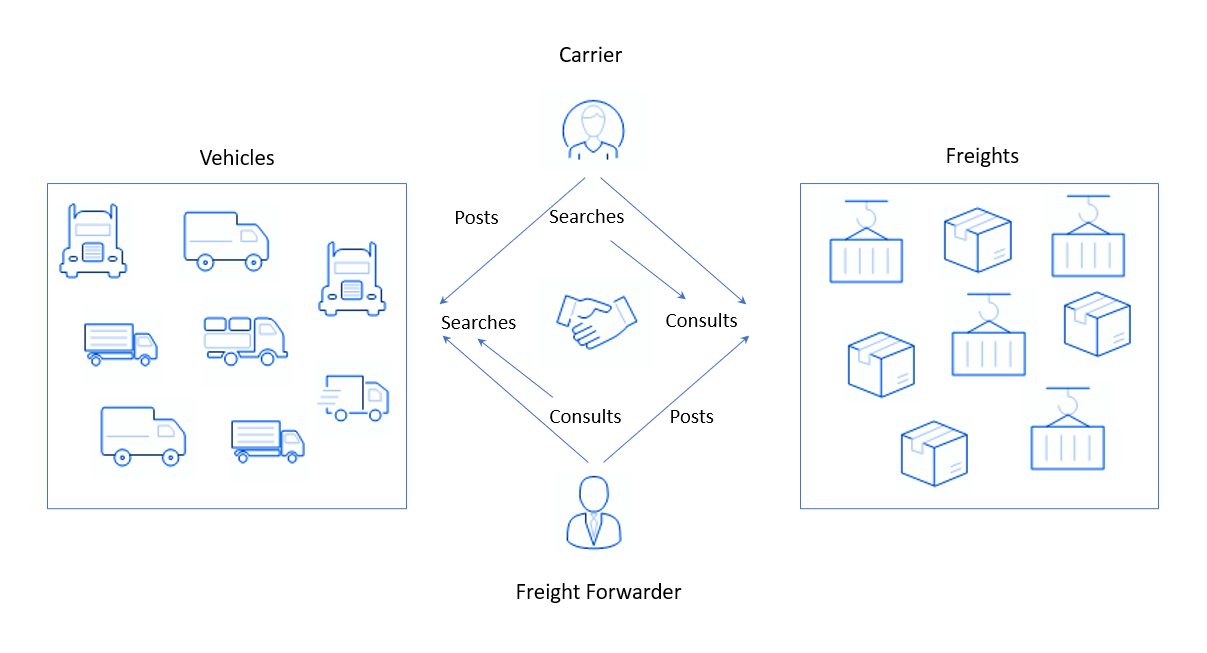
Dalam platform seperti itu, keseimbangan penawaran dan permintaan menjadi penting. Di sini, barang diminta dari pengangkut kargo dan truk dari pengirim barang, dan sebagai tawaran, yang terjadi adalah sebaliknya: mobil dari pengangkut dan barang dari perusahaan. Keseimbangan sulit dipertahankan karena beberapa alasan, misalnya:
- Komunikasi tertutup antara operator dan klien. Ketika seorang pengemudi sering hanya bekerja dengan pelanggan tertentu, itu tidak berfungsi dengan baik di platform. Jika pengirim meninggalkan pasar, maka layanan tersebut juga dapat kehilangan pengangkut, karena ia menjadi klien dari perusahaan logistik lain.
- Adanya barang yang tidak ingin diangkut siapa pun. Ini terjadi ketika perusahaan kecil memesan transportasi, dan kemudian mereka tidak diperbarui dan, karenanya, dengan cepat meninggalkan jumlah yang aktif.
Perusahaan ingin meningkatkan fungsionalitas platform pertukaran pengirimannya dan meningkatkan pengalaman pengguna pengguna sehingga mereka dapat melihat semua kemampuan sistem dan berbagai barang, dan juga tidak kehilangan loyalitas. Hal ini dapat membuat audiens target tidak beralih ke layanan kompetitif dan menunjukkan kepada perusahaan angkutan bahwa pesanan yang sesuai dapat ditemukan tidak hanya dari perusahaan tempat mereka biasa bekerja.
Mempertimbangkan semua keinginan, saya dihadapkan dengan tugas untuk mengembangkan sistem rekomendasi yang segera di pintu masuk ke platform akan menunjukkan kepada operator kargo relevan yang tersedia saat ini dan menebak apa yang ingin mereka angkut dan di mana. Sistem ini akan diintegrasikan ke dalam platform pertukaran barang yang ada.
Bagaimana kita akan "menebak"?
Sistem rekomendasi kami, seperti yang lainnya, bekerja pada analisis data pengguna. Dan ada beberapa sumber yang dapat Anda operasikan:
- Pertama, buka informasi tentang aplikasi pengangkutan barang.
- Kedua, platform menyediakan data tentang operator. Saat pengguna menandatangani kontrak dengan pelanggan kami, dia dapat menunjukkan berapa banyak truk yang dia miliki dan jenisnya. Tapi, sayangnya, setelah itu data tidak diperbarui. Dan satu-satunya hal yang dapat kami andalkan adalah negara pengangkut, karena kemungkinan besar tidak akan berubah.
- Ketiga, sistem menyimpan riwayat pencarian pengguna selama beberapa tahun: permintaan terbaru dan setahun yang lalu.
Dalam aplikasi dimana mereka memutuskan untuk menerapkan sistem rekomendasi, sudah ada mekanisme pencarian barang berdasarkan permintaan sebelumnya. Oleh karena itu, kami memutuskan untuk fokus pada identifikasi pola atau pola yang digunakan pengguna untuk menelusuri barang untuk transportasi. Artinya, kami tidak merekomendasikan pemuatan, tetapi pilih arah yang paling sesuai untuk pengguna ini saat ini. Dan kita sudah akan menemukan barangnya menggunakan mesin pencari standar.
Secara umum, pencarian populer didasarkan pada informasi geografis dan parameter tambahan seperti jenis truk atau barang yang diangkut. Ini cukup mudah untuk dilacak, karena preferensi ini hampir tidak berubah. Di bawah ini saya telah memberikan data permintaan salah satu pengguna selama 3 hari. Urutan pengisian adalah sebagai berikut: 1 kolom - negara keberangkatan, 2 - negara tujuan, 3 - wilayah keberangkatan, 4 - wilayah tujuan.

Anda dapat melihat bahwa pengguna ini memiliki preferensi khusus di negara dan provinsi. Tetapi ini tidak terjadi pada semua orang dan tidak selalu. Seringkali pengangkut hanya menunjukkan negara tujuan atau tidak menunjukkan wilayah keberangkatan, misalnya, ia berlokasi di Belgia dan dapat datang ke provinsi mana pun untuk mengambil kargo. Secara umum, ada berbagai jenis kueri: "country-country", "country-region", "region-country" atau "region-region" (opsi terbaik).
Contoh algoritme
Seperti yang Anda ketahui, strategi untuk membuat sistem pemberi rekomendasi terutama dibagi menjadi pemfilteran berbasis konten dan pemfilteran kolaboratif. Pada klasifikasi ini, saya mulai membangun solusi.
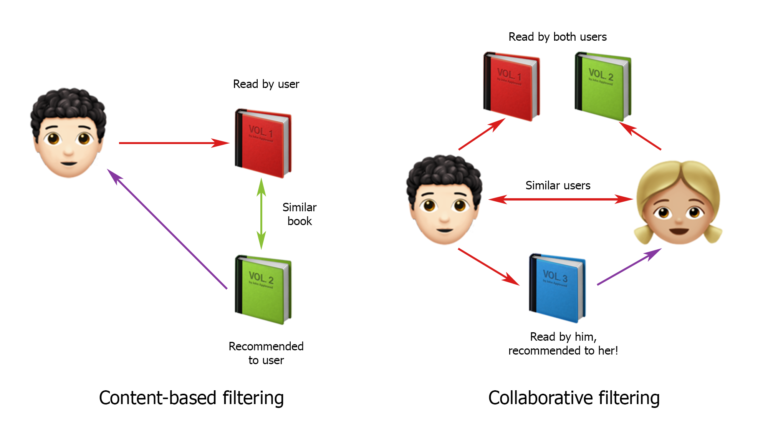
Saya mengambil gambar dari hub.forklog.com
Banyak sumber mengatakan bahwa pemfilteran kolaboratif berfungsi lebih baik. Sederhana saja: kami mencoba mencari pengguna yang mirip dengan kami, dengan pola perilaku yang serupa, dan kami merekomendasikan kepada pengguna kami permintaan yang sama dengan mereka. Secara umum, solusi ini adalah opsi pertama yang saya berikan kepada pelanggan. Tetapi mereka tidak setuju dengannya dan mengatakan itu tidak akan berhasil. Lagi pula, semuanya sangat bergantung pada di mana truk itu sekarang, di mana kargo itu dibawa, tempat tinggalnya, dan tempat yang lebih nyaman untuk dibawa. Kami tidak tahu tentang semua ini, itulah mengapa sangat sulit untuk mengandalkan perilaku pengguna lain, meskipun mereka, pada pandangan pertama, serupa.
Sekarang tentang sistem berbasis konten. Mereka bekerja seperti ini: pertama, profil pengguna ditentukan dan dibuat, dan kemudian pilihan rekomendasi dibuat berdasarkan karakteristiknya. Pilihan yang cukup bagus, tetapi dalam kasus kami ada beberapa nuansa. Pertama, satu pengguna dapat menyembunyikan seluruh kelompok orang yang mencari kargo untuk banyak truk dan masuk dari IP yang berbeda. Kedua, dari data pasti kami hanya memiliki negara pengangkut, dan informasi tentang jumlah truk dan tipenya kira-kira "ditampilkan" hanya dalam permintaan yang dibuat oleh pengguna. Artinya, untuk membangun sistem berbasis konten untuk proyek kami, Anda perlu melihat permintaan setiap pengguna dan mencoba menemukan yang paling populer di antara mereka.
Sistem rekomendasi pertama kami tidak menggunakan algoritme yang rumit. Kami mencoba memberi peringkat pada kueri dan menemukan hati tertinggi untuk merekomendasikannya. Untuk menguji konsep tersebut, tim kami bekerja dengan pengguna yang sebenarnya: mengirimi mereka rekomendasi, dan kemudian mengumpulkan masukan. Pada prinsipnya, operator menyukai hasilnya. Kemudian saya membandingkan rekomendasi kami dengan apa yang dicari oleh operator saat ini, dan melihat bahwa sistem bekerja dengan sangat baik untuk pengguna dengan pola perilaku yang stabil. Namun, sayangnya bagi mereka yang mengajukan lebih banyak permintaan, keakuratan rekomendasinya tidak terlalu tinggi - sistem perlu ditingkatkan.
Saya terus mencari tahu apa yang kita hadapi di sini. Faktanya, ini adalah model Markov tersembunyi di mana sekelompok orang dapat berada di belakang setiap pengguna. Selain itu, pengguna dapat berada dalam berbagai status tersembunyi: tidak ada data di mana mereka saat ini memiliki truk, berapa banyak orang dalam satu akun, dan kapan waktu berikutnya mereka perlu pergi ke suatu tempat. Pada saat itu, saya tidak tahu solusi siap pakai untuk produksi model Markov tersembunyi, jadi saya memutuskan untuk menemukan sesuatu yang lebih sederhana.
Temui PageRank
Jadi saya menarik perhatian pada algoritma PageRank, yang pernah dibuat oleh pendiri Google Sergey Brin dan Larry Page, yang masih digunakan oleh mesin pencari ini untuk merekomendasikan situs kepada pengguna. PageRank mewakili seluruh ruang Internet dalam bentuk grafik, di mana setiap halaman web adalah node-nya. Ini dapat digunakan untuk menghitung "kepentingan" (atau peringkat) untuk setiap node. PageRank pada dasarnya berbeda dari algoritme penelusuran yang ada sebelumnya, karena tidak didasarkan pada konten laman, tetapi pada tautan yang ada di dalamnya. Artinya, peringkat setiap halaman tergantung pada jumlah dan kualitas link yang mengarah ke halaman tersebut. Brin dan Page membuktikan konvergensi algoritma ini, yang berarti bahwa kita selalu dapat menghitung peringkat node mana pun dalam grafik berarah dan sampai pada nilai yang tidak akan berubah.
Mari kita lihat rumusnya:
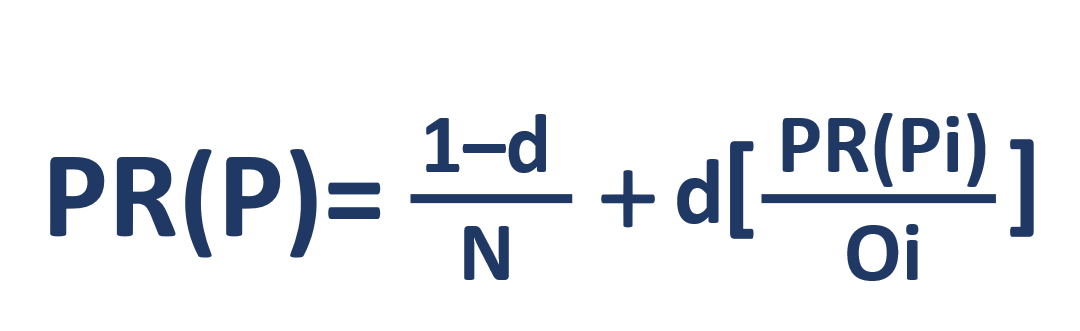
- PR(P) – rank
- N –
- i –
- O –
- d – . -, , - . , . 0 ≤ d ≤ 1 – d 0,85. .
Dan sekarang contoh sederhana penghitungan PageRank untuk grafik sederhana yang terdiri dari tiga node. Penting untuk diingat bahwa pada awalnya semua node diberi bobot yang sama sebesar 1 / jumlah node.
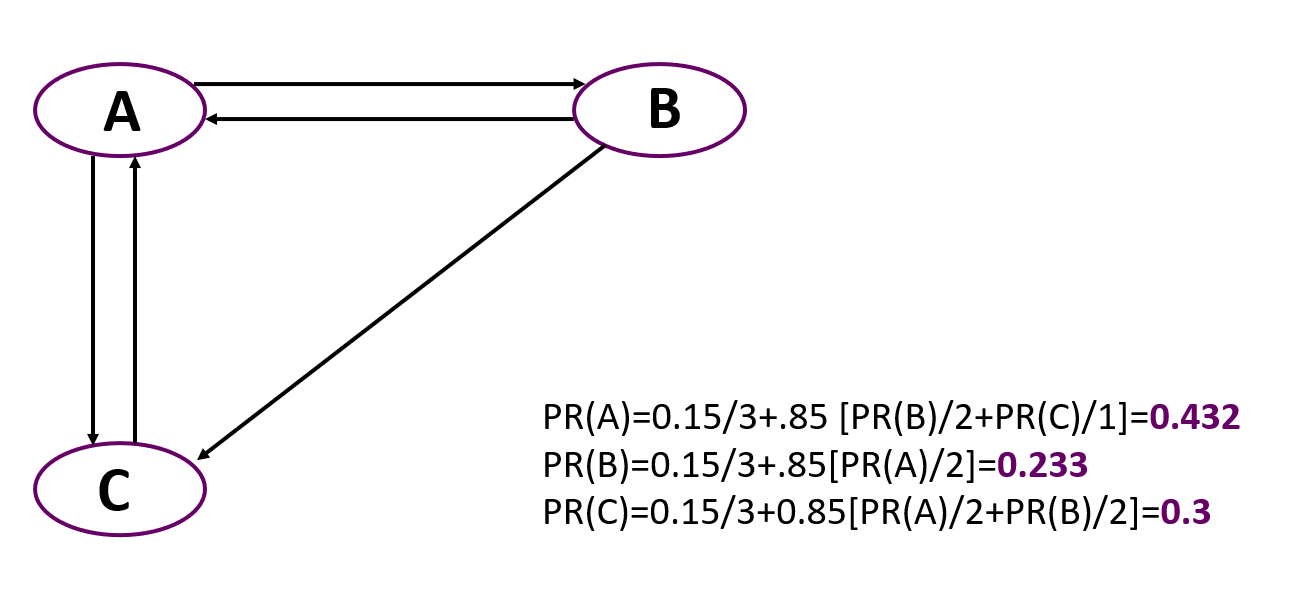
Anda dapat melihat bahwa yang paling penting di sini adalah node A, meskipun hanya ada dua node yang menunjuk ke sana, seperti C. Tetapi peringkat node yang mengarah ke A lebih tinggi daripada node yang mengarah ke C.
Asumsi dan solusi
Jadi PageRank menggambarkan proses Markov tanpa status tersembunyi. Dengan menggunakannya, kami akan selalu menemukan bobot akhir dari setiap node, tetapi kami tidak akan dapat melacak perubahan dalam grafik. Algoritmanya sangat bagus, kami dapat menyesuaikannya dan meningkatkan keakuratan hasilnya. Untuk melakukan ini, kami melakukan modifikasi PageRank - algoritme PageRank yang Dipersonalisasi, yang berbeda dari algoritme dasar karena transisi selalu dilakukan ke sejumlah node terbatas. Artinya, ketika pengguna bosan "berjalan" pada link, dia tidak beralih ke node acak, tetapi ke salah satu set tertentu.
Dalam kasus kami, node grafik akan menjadi permintaan pengguna. Karena algoritme kami seharusnya memberikan rekomendasi untuk hari yang akan datang, saya telah memecah semua permintaan untuk setiap operator berdasarkan hari. Sekarang kita buat grafik: node A terhubung ke node B, jika pencarian untuk tipe B mengikuti pencarian untuk tipe A, yaitu pencarian tipe A dilakukan oleh pengguna sebelum hari ketika mereka mencari rute B. Misalnya: "Paris - Brussels" pada hari Selasa (A), dan pada hari Rabu "Brussels - Cologne" (B). Dan beberapa pengguna membuat banyak permintaan per hari, jadi beberapa node terhubung satu sama lain sekaligus, dan sebagai hasilnya, kami mendapatkan grafik yang agak rumit.
Untuk menambahkan informasi tentang pentingnya berpindah dari satu hati ke hati lainnya, kami menambahkan bobot tepi grafik. Bobot tepi A-B adalah berapa kali pengguna mencari B setelah mencari A. Hal ini juga sangat penting untuk memperhitungkan usia kueri, karena pengguna mengubah templatnya: dia dapat memindahkan atau mengatur ulang jenis transportasi utama, setelah itu dia tidak ingin pergi dengan truk kosong. Oleh karena itu, Anda perlu memantau riwayat rute - kami menambahkan variabel keterkaitan, yang juga akan memengaruhi bobot node.
Perlu mempertimbangkan musim: kita mungkin tahu bahwa, misalnya, pada bulan September pengangkut sering melakukan perjalanan ke Prancis, dan pada bulan Oktober - ke Jerman. Dengan demikian, lebih banyak bobot bisa diberikan kepada hati yang "populer" di bulan tertentu. Selain itu, kami mengandalkan informasi tentang apa yang ditelusuri pengguna terakhir kali. Ini membantu untuk menebak secara tidak langsung di mana truk itu berada.
Hasil
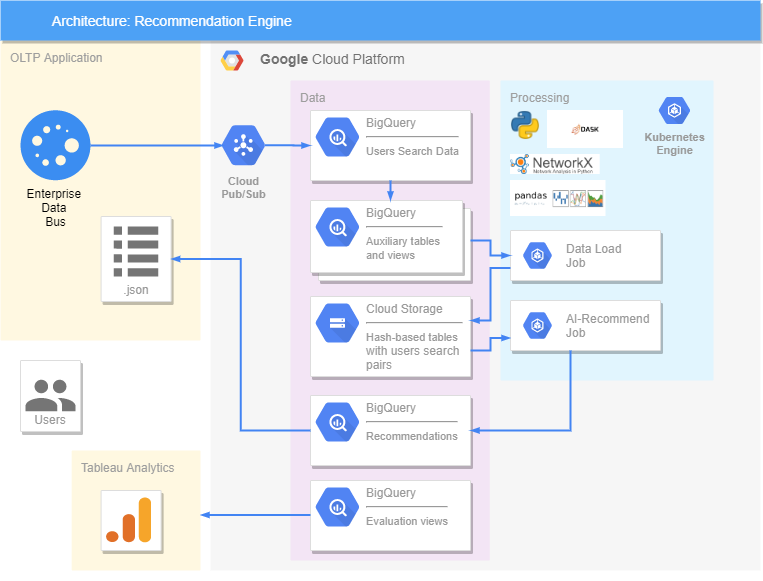
Semuanya diterapkan di platform Google. Kami memiliki aplikasi OLTP, tempat data tentang kueri berasal dan masuk ke BigQuery, tempat tampilan dan tabel tambahan yang berisi informasi yang sudah diproses dibentuk. Pustaka DASK digunakan untuk mempercepat dan memparalelkan pemrosesan data dalam jumlah besar. Dalam solusi kami, semua data ditransfer ke Cloud Storage, karena DASK hanya berfungsi dengannya dan tidak berinteraksi dengan BigQuery. Dua Pekerjaan dibuat di Kubernetes, salah satunya mentransfer data dari BigQuery ke Cloud Storage, dan yang kedua membuat rekomendasi. Cara kerjanya seperti ini: Pekerjaan mengambil data tentang pasangan hati dari Cloud Storage, memprosesnya, menghasilkan rekomendasi untuk hari yang akan datang, dan mengirimkannya kembali ke BigQuery. Dari sana, sudah dalam format .json, kami dapat mengirimkan rekomendasi ke aplikasi OLTP, di mana pengguna akan melihatnya.Keakuratan rekomendasi dievaluasi di Tableau, di mana rekomendasi kami dibandingkan dengan apa yang sebenarnya dicari pengguna di kemudian hari, serta reaksinya (suka atau tidak).
Tentu saja, saya ingin membagikan hasilnya. Misalnya, berikut adalah pengguna yang membuat 14 hati negara-negara setiap hari. Kami juga merekomendasikan jumlah yang sama kepadanya:
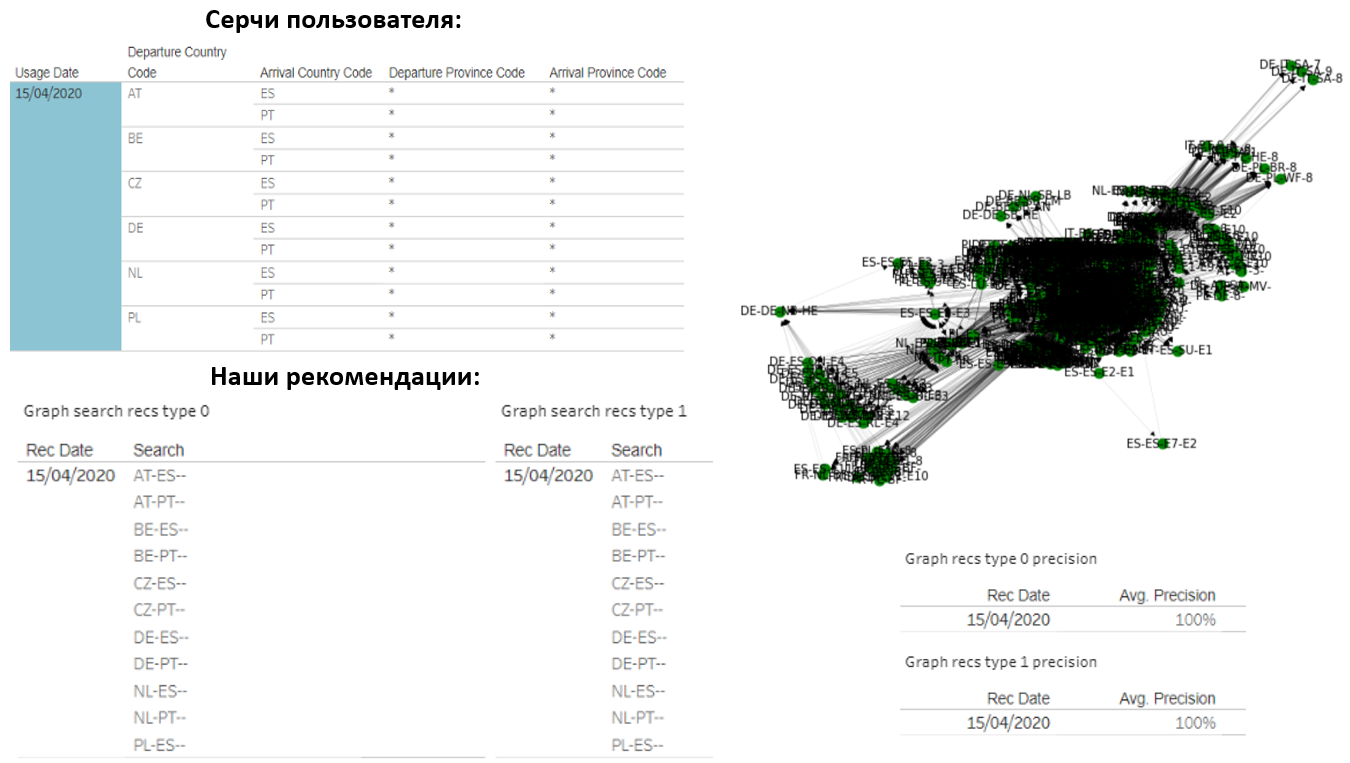
Ternyata pilihan kami benar-benar sesuai dengan apa yang dia cari. Grafik pengguna ini terdiri dari sekitar 1000 kueri berbeda, tetapi kami berhasil menebak dengan sangat akurat apa yang menarik baginya.
Pengguna kedua, rata-rata, membuat 8 permintaan berbeda setiap 2 hari, dan dia menelusuri keduanya dalam format "negara-negara", dan dengan indikasi wilayah keberangkatan tertentu. Selain itu, negara keberangkatan dan pengiriman sangat berbeda. Oleh karena itu, kami tidak dapat "menebak" semuanya dan keakuratan hasilnya ternyata lebih rendah:

Perhatikan bahwa pengguna memiliki 2 grafik dengan bobot berbeda. Dalam satu, akurasinya mencapai 38%, yang berarti bahwa 3 dari 8 opsi yang kami rekomendasikan ternyata relevan. Dan, mungkin, jika kita menemukan muatan ke arah ini, pengguna akan memilihnya.
Contoh terakhir dan paling sederhana. Seseorang melakukan sekitar 2 pencarian setiap hari. Ini memiliki pola yang sangat stabil, tidak terlalu banyak preferensi, dan grafik sederhana. Hasilnya, keakuratan prediksi kami adalah 100%.

Performa dalam fakta
- Algoritme kami berjalan pada 4 CPU standar dan memori 10 GB.
- Volume data hingga 1 miliar catatan.
- Diperlukan waktu 18 menit untuk membuat rekomendasi untuk semua pengguna dari sekitar 20.000.
- Pustaka DASK digunakan untuk paralelisasi dan pustaka NetworkX digunakan untuk algoritme PageRank.
Saya dapat mengatakan bahwa pencarian dan eksperimen kami telah membuahkan hasil yang sangat baik. Penyajian perilaku pengguna platform pertukaran barang dalam bentuk grafik dan penggunaan PageRank memungkinkan kami untuk secara akurat memprediksi preferensi masa depan mereka dan, dengan demikian, membangun sistem rekomendasi yang efektif.