
Salah satu tugas pemeriksaan fonoskopi adalah untuk menetapkan keaslian dan keaslian rekaman audio - dengan kata lain, untuk mengidentifikasi tanda-tanda pengeditan, distorsi, dan perubahan rekaman. Kami memiliki tugas untuk melakukan itu untuk menetapkan keaslian catatan - untuk menentukan bahwa tidak ada pengaruh yang dilakukan pada catatan. Tapi bagaimana menganalisis ribuan, bahkan ratusan ribu rekaman audio?
Metode AI datang untuk menyelamatkan kami, serta utilitas untuk bekerja dengan audio, yang telah kami bicarakan dalam artikel di situs web NewTechAudit "PROCESSING AUDIO WITH FFMPEG" .
Bagaimana perubahan audio muncul? Bagaimana Anda membedakan file yang dimodifikasi dari file yang tidak tersentuh?
Ada beberapa tanda seperti itu, dan yang paling sederhana adalah mengidentifikasi informasi tentang mengedit file dan menganalisis tanggal modifikasinya. Metode ini mudah diimplementasikan melalui OS itu sendiri, jadi kami tidak akan membahas metode ini. Tetapi perubahan dapat dilakukan oleh pengguna yang lebih memenuhi syarat yang dapat menyembunyikan atau mengubah informasi tentang pengeditan, dalam hal ini metode yang lebih kompleks digunakan, misalnya:
- pergeseran kontur;
- mengubah profil spektral dari audio yang direkam;
- munculnya jeda;
- dan banyak lagi.
Dan semua metode bunyi yang rumit ini dilakukan oleh para ahli yang terlatih secara khusus - ahli fonoskopi menggunakan perangkat lunak khusus seperti Praat, Speech Analyzer SIL, ELAN, yang sebagian besar berbayar dan memerlukan kualifikasi yang cukup tinggi untuk menggunakan dan menafsirkan hasilnya.
Para ahli menganalisis audio menggunakan profil spektral, yaitu dengan menganalisis koefisien cepstral-nya. Kami akan menggunakan pengalaman para ahli, dan pada saat yang sama menggunakan kode yang sudah jadi, menyesuaikannya dengan tugas kami.
Jadi banyak sekali perubahan yang bisa dilakukan, bagaimana kita memilihnya?
Dari kemungkinan jenis perubahan yang dapat dilakukan pada file audio, kami tertarik untuk memotong sebagian dari audio, atau memotong sebagian dan kemudian mengganti bagian asli dengan bagian dengan durasi yang sama - yang disebut perubahan potong / salin. mengedit file dalam hal pengurangan noise, mengubah frekuensi nada, dan lain-lain tidak berisiko menyembunyikan informasi.
Dan bagaimana kita mengidentifikasi potongan / salinan yang sama ini? Haruskah mereka dibandingkan dengan sesuatu?
Ini sangat sederhana - dengan bantuan utilitas FFmpeg kami akan memotong sebagian durasi acak dari file dan di tempat acak setelah itu kami akan membandingkan spektrogram cepstral kecil dari file asli dan file "potong".
Kode untuk menampilkannya:
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
def make_spek(audio):
n_fft = 2048
y, sr = librosa.load(audio)
ft = np.abs(librosa.stft(y[:n_fft], hop_length = n_fft+1))
spec = np.abs(librosa.stft(y, hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=np.max)
mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(mel_spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time');
plt.title('Mel Spectrogram');
plt.colorbar(format='%+2.0f dB');
plt.show();
make_spek('./audio/original.wav')# './audio/original.wav' Kami menyiapkan kumpulan data dari sumber dan memotong file menggunakan perintah utilitas FFmpeg:
ffmpeg -i oroginal.wav -ss STARTTIME -to ENDTIME -acodec copy cut.wav di mana STARTTIME dan ENDTIME adalah awal dan akhir fragmen potongan. Dan menggunakan perintah:
ffmpeg -iconcat:"part_0.wav|part_1.wav |part_2.wav" -codeccopyconcat.wavbergabunglah dengan bagian file untuk memasukkan part_1.wav dengan bagian aslinya (untuk membungkus perintah FFmpeg dengan python, lihat artikel kami di FFmpeg).
Berikut adalah file asli spektogram kapur yang telah dipotong dari audio 0,2-2,5 detik, dan spektogram kapur dari file yang telah dipotong dari audio 0,2-2,5 detik, dan kemudian dimasukkan ke dalam fragmen audio dengan durasi yang sama dari file audio ini:
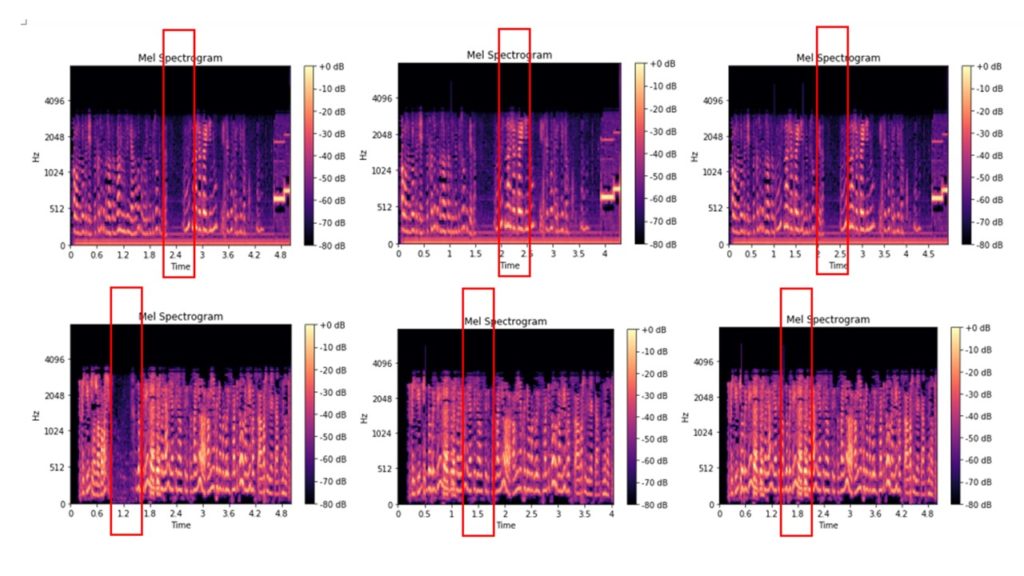
Beberapa gambar dapat dibedakan bahkan secara visual, gambar lainnya terlihat hampir sama. Kami mendistribusikan gambar yang dihasilkan ke dalam folder dan menggunakannya sebagai data input untuk melatih model klasifikasi gambar. Struktur folder:
model.py #
/input/train/original/ #
/input/train/cut_copy/ # Bagi kami, tidak ada bedanya apakah file audio yang dimodifikasi itu ditambah atau disingkat - kami membagi semua hasil menjadi baik, yaitu file tanpa perubahan, dan buruk. Jadi, kami memecahkan masalah klasik klasifikasi biner. Kami akan mengklasifikasikan menggunakan jaringan neural, kami akan mengambil kode untuk bekerja dengan jaringan saraf yang sudah jadi dari contoh bekerja dengan paket Keras.
#
from keras.models import Sequential
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
#
classifier = Sequential()
classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(32, (3, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Flatten())
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 1, activation = 'sigmoid'))
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
#
from keras.preprocessing.image import ImageDataGenerator as img
train_datagen = img(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = img(rescale = 1./255)
training_set = train_datagen.flow_from_directory('input/train',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
test_set = test_datagen.flow_from_directory('input/test',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
classifier.fit_generator(
training_set,
steps_per_epoch = 8000,
epochs = 25,
validation_data = test_set,
validation_steps = 2000)Selanjutnya, setelah model dilatih, kami melakukan klasifikasi dengan bantuannya
import numpy as np
from keras.preprocessing import image
test_image = image.load_img('dataset/prediction/original_or_corrupt.jpg', target_size = (64, 64))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = classifier.predict(test_image)
training_set.class_indices
ifresult[0][0] == 1:
prediction = 'original'
else:
prediction = 'corrupt'Pada output, kami mendapatkan klasifikasi file audio - 'asli' / 'rusak', mis. file tidak berubah dan file tempat perubahan dilakukan.
Kami membuktikan sekali lagi bahwa hal-hal yang tampak rumit dapat dilakukan dengan sederhana - kami tidak menggunakan mekanisme metode AI yang paling sulit, solusi yang sudah jadi dan memeriksa audio untuk perubahan. Nah, kami adalah ahli dari detektif.