Ulangi, tetapi setiap kali dengan cara baru - bukankah ini seni?
Stanislav Jerzy Lec, dari buku "Uncombed Thoughts"
Kamus mendefinisikan replikasi sebagai proses mempertahankan dua (atau lebih) set data dalam keadaan yang konsisten. Apa yang dimaksud dengan "status kumpulan data yang konsisten" adalah pertanyaan besar yang terpisah, jadi mari kita merumuskan ulang definisi dengan cara yang lebih sederhana: proses mengubah satu kumpulan data, yang disebut replika, sebagai respons terhadap perubahan dalam kumpulan data lain, yang disebut master. Set tersebut belum tentu sama.

Dukungan replikasi database adalah salah satu tugas terpenting administrator: hampir setiap database yang memiliki kepentingan apa pun memiliki replika, atau bahkan lebih dari satu.
Tugas replikasi mencakup setidaknya
- dukungan database cadangan jika kehilangan yang utama;
- mengurangi beban pada database dengan mentransfer sebagian permintaan ke replika;
- transfer data ke sistem arsip atau analitik.
Pada artikel ini saya akan berbicara tentang jenis replikasi dan tugas apa yang diselesaikan setiap jenis replikasi.
Ada tiga pendekatan untuk replikasi:
- Blokir replikasi di tingkat sistem penyimpanan;
- Replikasi fisik di tingkat DBMS;
- Replikasi logis di tingkat DBMS.
Blokir replikasi
Dengan replikasi blok, setiap operasi tulis dilakukan tidak hanya pada disk utama, tetapi juga pada cadangan. Dengan demikian, volume pada satu larik sesuai dengan volume yang dicerminkan di larik lain, mengulangi volume utama dengan presisi byte:
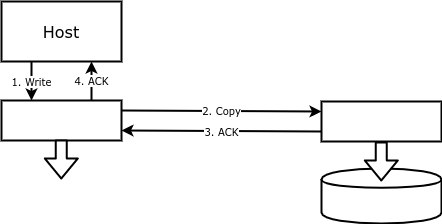
Keuntungan dari replikasi seperti itu termasuk kemudahan penyetelan dan keandalan. Entah array disk atau sesuatu (perangkat atau perangkat lunak) antara host dan disk dapat menulis data ke disk jarak jauh.
Larik disk dapat dilengkapi dengan opsi untuk mengaktifkan replikasi. Nama opsi tergantung pada pabrikan array:
| Pabrikan | Merek dagang
|
|---|---|
| EMC | SRDF (Symmetrix Remote Data Facility) |
| IBM | Metro Mirror - replikasi sinkronis
Global Mirror - replikasi asinkron |
| Hitachi | TrueCopy |
| Hewlett Packard | Akses Berkelanjutan |
| Huawei | HyperReplication |
Jika array disk tidak mampu mereplikasi data, agen dapat diinstal antara host dan array, yang menulis ke dua array sekaligus. Agen dapat berupa perangkat mandiri (EMC VPLEX) atau komponen perangkat lunak (HPE PeerPersistence, Windows Server Storage Replica, DRBD). Tidak seperti array disk, yang hanya dapat bekerja dengan array yang sama, atau setidaknya dengan array dari pabrikan yang sama, agen dapat bekerja dengan perangkat disk yang sama sekali berbeda.
Tujuan utama replikasi blok adalah untuk memberikan toleransi kesalahan. Jika database hilang, Anda dapat memulai ulang menggunakan volume cermin.
Replikasi blok bagus untuk keserbagunaannya, tetapi keserbagunaan ada harganya.
Pertama, tidak ada server yang dapat menangani volume cermin, karena sistem operasinya tidak dapat mengontrol penulisan padanya; Dari sudut pandang pengamat, data pada volume cermin muncul secara spontan. Jika terjadi bencana (kegagalan server utama atau seluruh pusat data tempat server utama berada), Anda harus menghentikan replikasi, melepas volume utama, dan memasang volume cermin. Secepatnya Anda harus memulai ulang replikasi ke arah yang berlawanan.
Dalam kasus menggunakan agen, semua tindakan ini akan dilakukan oleh agen, yang menyederhanakan konfigurasi, tetapi tidak mengurangi waktu pengalihan.
Kedua, DBMS itu sendiri pada server siaga dapat dijalankan hanya setelah disk dipasang. Di beberapa sistem operasi, misalnya, di Solaris, memori untuk cache ditandai selama alokasi, dan waktu penandaan sebanding dengan jumlah memori yang dialokasikan, yaitu, permulaan instance tidak akan instan. Ditambah, cache akan kosong setelah restart.
Ketiga, setelah memulai di server cadangan, DBMS akan mengetahui bahwa data pada disk tidak konsisten, dan Anda perlu menghabiskan banyak waktu untuk memulihkan menggunakan log ulang: pertama, ulangi transaksi tersebut, yang hasilnya disimpan dalam log, tetapi tidak punya waktu untuk disimpan ke file data, dan kemudian memutar kembali transaksi yang tidak sempat diselesaikan pada saat kegagalan.
Replikasi blok tidak dapat digunakan untuk penyeimbangan beban, dan skema serupa digunakan untuk memutakhirkan datastore dengan volume cermin pada larik yang sama sebagai primer. EMC dan HP menyebut skema ini BCV, hanya EMC singkatan dari Business Continuance Volume, dan HP adalah singkatan dari Business Copy Volume. IBM tidak memiliki merek dagang khusus untuk kasus ini, skema ini disebut "volume cermin".

Dua volume dibuat dalam larik dan operasi tulis dilakukan secara sinkron pada keduanya (A). Pada waktu tertentu, cermin pecah (B), yaitu volume menjadi independen. Volume cermin dipasang ke server yang didedikasikan untuk peningkatan penyimpanan dan instance database dimunculkan di server itu. Instance akan mengambil jumlah waktu yang sama untuk digunakan seperti yang dilakukan selama pemulihan replikasi blok, tetapi waktu ini dapat dikurangi secara signifikan dengan memecahkan cermin selama periode di luar puncak. Intinya adalah bahwa memecahkan cermin dalam konsekuensinya setara dengan penghentian DBMS yang abnormal, dan waktu pemulihan jika terjadi penghentian yang tidak normal sangat bergantung pada jumlah transaksi aktif pada saat crash. Basis data yang dimaksudkan untuk pembongkaran tersedia untuk membaca dan menulis. Semua pengenal blok,cermin berubah setelah jeda, baik pada volume utama dan cermin, disimpan di area khusus Pelacakan Perubahan Blok - BCT.
Setelah akhir pengunggahan, volume yang dicerminkan dilepaskan (C), cermin dipulihkan, dan setelah beberapa saat volume yang dicerminkan kembali menyusul yang utama dan menjadi salinannya.
Replikasi fisik
Log (redo log atau write-ahead log) berisi semua perubahan yang dibuat ke file database. Ide di balik replikasi fisik adalah bahwa perubahan dari log dikomit ulang ke database lain (replika), dan dengan demikian data dalam replika mereplikasi data dalam database utama byte-by-byte.
Kemampuan untuk menggunakan log database untuk memperbarui replika muncul di rilis Oracle 7.3, yang dirilis pada tahun 1996, dan sudah di rilis Oracle 8i, pengiriman log dari database utama ke replika secara otomatis dan dinamai DataGuard. Teknologi tersebut ternyata sangat diminati sehingga saat ini mekanisme replikasi fisik hadir di hampir semua DBMS modern.
| DBMS | Opsi replikasi
|
|---|---|
| Peramal | DataGuard aktif |
| IBM DB2 | HADR |
| Microsoft SQL Server | Pengiriman log / Selalu Aktif |
| PostgreSQL | Pengiriman log / Replikasi streaming |
| MySQL | Replikasi InnoDB fisik Alibaba |
Pengalaman menunjukkan bahwa jika server digunakan hanya untuk menjaga replika tetap up-to-date, maka sekitar 10% dari kekuatan pemrosesan server yang menjalankan basis utama sudah cukup untuk itu.
Log DBMS tidak dimaksudkan untuk digunakan di luar platform ini, formatnya tidak didokumentasikan dan dapat berubah tanpa pemberitahuan. Oleh karena itu, persyaratan yang cukup alami bahwa replikasi fisik hanya mungkin dilakukan antara contoh versi yang sama dari DBMS yang sama. Oleh karena itu, kemungkinan batasan pada sistem operasi dan arsitektur prosesor, yang juga dapat memengaruhi format log.
Secara alami, replikasi fisik tidak memaksakan batasan apa pun pada model penyimpanan. Selain itu, file di basis replika dapat ditempatkan dengan cara yang sama sekali berbeda dari pada basis sumber - Anda hanya perlu menjelaskan korespondensi antara volume tempat file-file ini berada.
Oracle DataGuard memungkinkan Anda untuk menghapus beberapa file dari database replika - dalam hal ini, perubahan dalam log yang terkait dengan file ini akan diabaikan.
Replikasi database fisik memiliki banyak keunggulan dibandingkan replikasi penyimpanan:
- jumlah data yang ditransfer lebih sedikit karena fakta bahwa hanya log yang ditransfer, tetapi bukan file data; percobaan menunjukkan penurunan lalu lintas 5-7 kali;
- : - , ; , ;
- , . , .
Kemampuan untuk membaca data dari replika diperkenalkan pada tahun 2007 dengan dirilisnya Oracle 11g, seperti yang ditunjukkan oleh julukan "aktif" yang ditambahkan ke nama teknologi DataGuard. DBMS lain juga memiliki kemampuan untuk membaca dari replika, tetapi ini tidak tercermin dalam namanya.
Menulis data ke replika tidak mungkin, karena perubahan datang padanya byte-by-byte, dan replika tidak dapat menyediakan eksekusi kompetitif dari permintaannya. Oracle Active DataGuard dalam rilis terbaru memungkinkan penulisan ke replika, tetapi ini tidak lebih dari "gula": pada kenyataannya, perubahan dibuat pada basis utama, dan klien menunggu mereka untuk bergulir ke replika.
Jika file dalam database utama rusak, Anda cukup menyalin file yang sesuai dari replika (baca dengan cermat manual administrator sebelum melakukan ini dengan database Anda!). File di replika mungkin tidak sama dengan file di database utama: faktanya adalah saat file diperluas, blok baru tidak diisi dengan apa pun untuk mempercepat, dan isinya tidak disengaja. Basis tidak boleh menggunakan semua ruang di blok (misalnya, mungkin ada ruang kosong di blok), tetapi isi ruang yang digunakan cocok dengan byte.
Replikasi fisik bisa sinkron atau asinkron. Dengan replikasi asinkron, selalu ada sekumpulan transaksi tertentu yang telah diselesaikan di basis utama, tetapi belum mencapai basis siaga, dan jika terjadi transisi ke basis siaga jika basis utama gagal, transaksi ini akan hilang. Dalam replikasi sinkronis, penyelesaian operasi komit berarti bahwa semua catatan log yang terkait dengan transaksi ini telah dimasukkan ke replika. Penting untuk dipahami bahwa mendapatkan replika log tidak berarti bahwa perubahan diterapkan ke data. Jika database utama hilang, transaksi tidak akan hilang, tetapi jika aplikasi menulis data ke database utama dan membacanya dari replika, maka ia memiliki kesempatan untuk mendapatkan versi lama dari data ini.
Di PostgreSQL, dimungkinkan untuk mengonfigurasi replikasi sehingga komit selesai hanya setelah perubahan diterapkan ke data replika (opsi
synchronous_commit = remote_apply), sedangkan di Oracle, Anda dapat mengonfigurasi seluruh replika atau sesi individu sehingga kueri dijalankan hanya jika replika tidak tertinggal di belakang database utama ( STANDBY_MAX_DATA_DELAY=0). Namun, masih lebih baik untuk merancang aplikasi sehingga penulisan ke database utama dan pembacaan dari replika dilakukan dalam modul yang berbeda.
Saat mencari jawaban untuk pertanyaan mode mana yang harus dipilih, sinkron atau asinkron, pemasar Oracle datang membantu kami. DataGuard menyediakan tiga mode, yang masing-masing memaksimalkan salah satu parameter - keamanan data, kinerja, ketersediaan - dengan mengorbankan yang lain:
- Performa maksimal: replikasi selalu asynchronous;
- Maximum protection: ; , commit ;
- Maximum availability: ; , , , .
Terlepas dari keuntungan yang tak terbantahkan dari replikasi database dibandingkan replikasi blok, administrator di banyak perusahaan, terutama yang memiliki tradisi reliabilitas lama, masih sangat enggan untuk meninggalkan replikasi blok. Ada dua alasan untuk ini.
Pertama, dalam kasus replikasi larik disk, lalu lintas tidak melalui jaringan transmisi data (LAN), tetapi melalui jaringan area penyimpanan. Seringkali, dalam infrastruktur yang dibangun sejak lama, SAN jauh lebih andal dan berkinerja daripada jaringan data.
Kedua, replikasi sinkronis melalui DBMS menjadi relatif dapat diandalkan baru-baru ini. Di Oracle, terobosan terjadi pada rilis 11g, yang keluar pada tahun 2007, dan di DBMS lainnya, replikasi sinkronis muncul bahkan kemudian. Tentu saja, 10 tahun menurut standar lingkungan teknologi informasi tidaklah sesingkat itu, tetapi dalam hal keamanan data, beberapa administrator masih berpedoman pada prinsip "apapun yang terjadi" ...
Replikasi logis
Semua perubahan dalam database terjadi sebagai akibat dari panggilan ke API-nya - misalnya, sebagai hasil dari eksekusi kueri SQL. Ide menjalankan urutan kueri yang sama pada dua basis yang berbeda tampaknya sangat menggoda. Ada dua aturan yang harus diikuti untuk replikasi:
- , , . D, A B.
- , , . B , , C.
Replikasi perintah (replikasi berbasis pernyataan) diimplementasikan, misalnya di MySQL. Sayangnya, skema sederhana ini tidak menghasilkan kumpulan data yang identik karena dua alasan.
Pertama, tidak semua API bersifat deterministik. Misalnya, jika kueri SQL berisi fungsi now () atau sysdate () yang mengembalikan waktu saat ini, maka itu akan mengembalikan hasil yang berbeda di server yang berbeda karena kueri tidak dijalankan secara bersamaan. Selain itu, status pemicu dan fungsi tersimpan yang berbeda, lokal yang berbeda memengaruhi tata urutan, dan banyak lagi dapat menyebabkan perbedaan.
Kedua, replikasi berbasis perintah paralel tidak dapat dihentikan sementara dan dimulai ulang dengan baik.
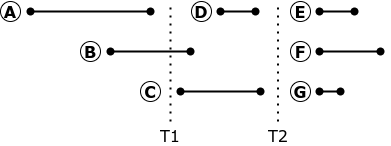
Jika replikasi dihentikan pada waktu T1, transaksi B harus dibatalkan dan dibatalkan. Saat Anda memulai ulang replikasi, eksekusi transaksi B dapat membawa replika ke status yang berbeda dari status database sumber: di sumber, transaksi B dimulai sebelum transaksi A berakhir, yang berarti tidak melihat perubahan yang dibuat oleh transaksi A.
Replikasi permintaan dapat dihentikan dan restart hanya pada saat T2, ketika tidak ada transaksi aktif dalam database. Tentu saja, tidak ada momen seperti itu di pangkalan industri yang sarat muatan.
Biasanya, replikasi logis menggunakan kueri deterministik. Determinisme permintaan disediakan oleh dua properti:
- kueri memperbarui (atau menyisipkan, atau menghapus) satu catatan, mengidentifikasinya dengan kunci utama (atau unik);
- semua parameter permintaan secara eksplisit diatur dalam permintaan itu sendiri.
Tidak seperti replikasi berbasis pernyataan, pendekatan ini disebut replikasi berbasis baris.
Misalkan kita memiliki tabel karyawan dengan data berikut:
| Indo | Nama | Dept | Gaji
|
|---|---|---|---|
| 3817 | Ivanov Ivan Ivanovich | 36 | 1800 |
| 2274 | Petrov Petr Petrovich | 36 | 1600 |
| 4415 | Kuznetsov Semyon Andreevich | 41 | 21.00 |
Operasi berikut dilakukan pada tabel ini:
update employee set salary = salary*1.2 where dept=36;Untuk mereplikasi data dengan benar, kueri berikut akan dijalankan di replika:
update employee set salary = 2160 where id=3817;
update employee set salary = 1920 where id=2274;Kueri menghasilkan hasil yang sama seperti pada basis aslinya, tetapi tidak setara dengan kueri yang dieksekusi.
Basis replika terbuka dan tersedia tidak hanya untuk membaca, tetapi juga untuk menulis. Ini memungkinkan replika digunakan untuk mengeksekusi bagian kueri, termasuk untuk membuat laporan yang memerlukan pembuatan tabel atau indeks tambahan.
Penting untuk dipahami bahwa replika logis akan setara dengan basis aslinya hanya jika tidak ada perubahan tambahan yang dibuat padanya. Misalnya, jika dalam contoh di atas di replika departemen Sidorov ditambahkan ke 36, dia tidak akan menerima promosi, dan jika Ivanov dipindahkan dari departemen 36, dia akan menerima promosi, apa pun yang terjadi.
Replikasi logis memberikan sejumlah kemampuan yang tidak ditemukan di jenis replikasi lainnya:
- menyiapkan satu set data yang direplikasi di tingkat tabel (untuk replikasi fisik - di tingkat ruang file dan tabel, untuk replikasi blok - di tingkat volume);
- membangun topologi replikasi yang kompleks - misalnya, menggabungkan beberapa database menjadi satu atau replikasi dua arah;
- penurunan jumlah data yang dikirim;
- replikasi antara berbagai versi DBMS atau bahkan antara DBMS dari produsen yang berbeda;
- pemrosesan data selama replikasi, termasuk restrukturisasi, pengayaan, pelestarian sejarah.
Ada juga kerugian yang tidak memungkinkan replikasi logis menggantikan replikasi fisik:
- semua data yang direplikasi harus memiliki kunci utama;
- replikasi logis tidak mendukung semua tipe data - misalnya, mungkin ada masalah dengan BLOB.
- : , ;
- ;
- , , – , .
Dua kelemahan terakhir secara signifikan membatasi penggunaan replika logis sebagai alat toleransi kesalahan. Jika satu kueri dalam database utama mengubah banyak baris sekaligus, replika dapat tertinggal secara signifikan. Dan kemampuan untuk mengubah peran membutuhkan upaya luar biasa dari pengembang dan administrator.
Ada beberapa cara untuk mengimplementasikan replikasi logis, dan masing-masing metode ini mengimplementasikan satu bagian dari kapabilitas dan tidak mengimplementasikan yang lain:
- replikasi oleh pemicu;
- menggunakan log DBMS;
- penggunaan perangkat lunak CDC (ubah pengambilan data);
- replikasi yang diterapkan.
Picu replikasi
Pemicu adalah prosedur tersimpan yang secara otomatis dijalankan pada tindakan apa pun untuk mengubah data. Pemicu, yang dipanggil saat setiap record berubah, memiliki akses ke kunci record tersebut, serta nilai kolom lama dan baru. Jika perlu, pemicu dapat menyimpan nilai baris baru ke tabel khusus, dari mana proses khusus di sisi replika akan membacanya. Jumlah kode dalam pemicu sangat besar, jadi ada perangkat lunak khusus yang menghasilkan pemicu tersebut, misalnya, "menggabungkan replikasi" - komponen Microsoft SQL Server atau Slony-I - produk terpisah untuk replikasi PostgreSQL.
Kekuatan Replikasi Pemicu:
- kemerdekaan dari versi pangkalan utama dan replika;
- kemampuan konversi data yang luas.
Kekurangan:
- memuat di pangkalan utama;
- latensi replikasi tinggi.
Menggunakan Log DBMS
DBMS sendiri juga dapat menyediakan kemampuan replikasi logis. Log adalah sumber data, seperti replikasi fisik. Informasi tentang perubahan byte juga ditambahkan ke informasi tentang bidang yang diubah (logging tambahan di Oracle,
wal_level = logicaldi PostgreSQL), serta nilai kunci unik, bahkan jika tidak berubah. Akibatnya, volume log database meningkat - menurut berbagai perkiraan, dari 10 menjadi 15%.
Kemampuan replikasi bergantung pada implementasi dalam DBMS tertentu - jika Anda dapat membangun standby logis di Oracle, maka di PostgreSQL atau Microsoft SQL Server Anda dapat menerapkan sistem kompleks langganan dan publikasi bersama menggunakan alat platform bawaan. Selain itu, DBMS menyediakan pemantauan dan kontrol replikasi bawaan.
Kerugian dari pendekatan ini termasuk peningkatan volume log dan kemungkinan peningkatan lalu lintas antar node.
Menggunakan CDC
Ada seluruh kelas perangkat lunak yang dirancang untuk mengatur replikasi logis. Perangkat lunak ini disebut CDC, mengubah pengambilan data. Berikut adalah daftar platform paling terkenal di kelas ini:
- Oracle GoldenGate (diakuisisi oleh GoldenGate pada tahun 2009);
- IBM InfoSphere Data Replication (sebelumnya InfoSphere CDC; bahkan sebelumnya, DataMirror Transformation Server, diakuisisi oleh DataMirror pada tahun 2007);
- VisionSolutions DoubleTake / MIMIX (sebelumnya Vision Replicate1);
- Platform Integrasi Data Qlik (sebelumnya Attunity);
- Informatica PowerExchange CDC;
- Debezium;
- Pengumpul Data StreamSets ...
Tugas platform adalah membaca log database, mengubah informasi, mentransfer informasi ke replika, dan menerapkan. Seperti dalam kasus replikasi melalui DBMS itu sendiri, log harus berisi informasi tentang bidang yang diubah. Menggunakan aplikasi tambahan memungkinkan Anda untuk melakukan transformasi kompleks dari data yang direplikasi dengan cepat dan membangun topologi replikasi yang cukup kompleks.
Kekuatan:
- kemampuan untuk mereplikasi antara DBMS yang berbeda, termasuk memuat data ke dalam sistem pelaporan;
- kemungkinan terluas dari pemrosesan dan transformasi data;
- lalu lintas minimal antar node - platform memotong data yang tidak perlu dan dapat memampatkan lalu lintas;
- kemampuan bawaan untuk memantau status replikasi.
Tidak banyak kerugian:
- peningkatan volume log, seperti replikasi logis melalui DBMS;
- perangkat lunak baru sulit dikonfigurasi dan / atau dengan lisensi yang mahal.
Ini adalah platform CDC yang secara tradisional digunakan untuk memperbarui gudang data perusahaan hampir secara real time.
Replikasi yang diterapkan
Terakhir, cara replikasi lainnya adalah dengan membentuk vektor perubahan secara langsung di sisi klien. Klien harus mengeluarkan kueri deterministik yang memengaruhi satu rekaman. Ini dapat dicapai dengan menggunakan pustaka database khusus, misalnya, Borland Database Engine (BDE) atau Hibernate ORM.
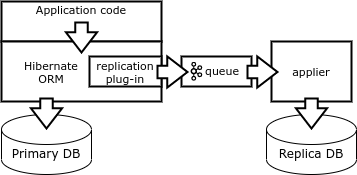
Ketika aplikasi menyelesaikan transaksi, plugin Hibernate ORM menulis vektor perubahan ke antrian dan menjalankan transaksi di database. Proses replikator khusus mengurangi vektor dari antrian dan melakukan transaksi di basis replika.
Mekanisme ini bagus untuk memperbarui sistem pelaporan. Ini juga dapat digunakan untuk memberikan toleransi kesalahan, tetapi dalam kasus ini, aplikasi harus menerapkan kontrol status replikasi.
Secara tradisional - kekuatan dan kelemahan dari pendekatan ini:
- kemampuan untuk mereplikasi antara DBMS yang berbeda, termasuk memuat data ke dalam sistem pelaporan;
- kemampuan untuk memproses dan mengubah data, pemantauan kondisi, dll .;
- lalu lintas minimal antar node - platform memotong data yang tidak perlu dan dapat memampatkan lalu lintas;
- kebebasan penuh dari database - baik dari format maupun dari mekanisme internal.
Keuntungan dari metode ini tidak dapat disangkal, tetapi ada dua kerugian yang sangat serius:
- pembatasan arsitektur aplikasi;
- sejumlah besar kode replikasi asli.
Jadi mana yang lebih baik?
Tidak ada jawaban tegas untuk pertanyaan ini, seperti banyak jawaban lainnya. Namun saya harap tabel di bawah ini akan membantu Anda membuat pilihan yang tepat untuk setiap tugas tertentu:
| Replikasi blok penyimpanan | Blokir replikasi oleh agen | Replikasi fisik | Replikasi DBMS logis | CDC |
|
||
|---|---|---|---|---|---|---|---|
| X | X | X/7..X/5 | X/7..X/5 | ≤X/10 | ≤X/10 | ≤X/10 | |
| 5 … | 5 … | 1..10 | 1..10 | 1..2 | 1..2 | 1..2 | |
| + | + | +++ | + | ∅ | ∅ | ∅ | |
| ∅ | ∅ | RO | R/W | R/W | R/W | R/W | |
| - | -
broadcast |
-
broadcast |
-
broadcast * p2p* |
-
broadcast * p2p* |
-
broadcast * p2p* |
-
broadcast * p2p* |
|
| ∅ | ∅ | – | – – | – – – | – – | ∅ | |
| + + + | + + | + + | + + | – | + | – – – | |
| – – | – – | – | – | ∅ | – – – | ∅ | |
| ∅ | + | + + | + + | + + | + + + | + + + |
- , ; .
- , .
- , .
- .
- , , .
- CDC , / .
- .