
Saya selalu tertarik dengan kegagalan sistem dan keanehan perilaku mereka, terutama ketika mereka bekerja dalam kondisi normal. Baru-baru ini saya melihat salah satu slide dalam presentasi Ian Goodfellow, yang menurut saya sangat lucu. Gangguan visual acak diumpankan ke jaringan saraf terlatih, dan dia mengenalinya sebagai salah satu objek yang dia ketahui. Banyak pertanyaan langsung muncul di sini. Akankah jaringan saraf terlatih yang berbeda melihat objek yang sama? Berapa tingkat keyakinan maksimum dalam jaringan saraf bahwa derau acak ini memang merupakan objek yang dikenali? Dan apa yang sebenarnya "dilihat" oleh jaringan saraf di sana?
Karena penasaran saya tentang ini, entri ini lahir. Untungnya, eksperimen seperti ini sangat mudah dilakukan dengan PyTorch.... Untuk memvisualisasikan mengapa jaringan saraf mengklasifikasikan objek dengan cara tertentu, saya menggunakan kerangka kerja interpretabilitas model Captum . Kode dapat diunduh dari Github .
Pentingnya pertanyaan
Anda mungkin bertanya mengapa pertanyaan-pertanyaan ini penting. Dalam banyak kasus, developer tidak membuat model dari awal. Mereka memilih platform dan jaringan terlatih dari kebun binatang model sebagai titik awal. Ini menghemat waktu - tidak perlu mengumpulkan data dan melakukan pelatihan awal jaringan neural. Namun, ini juga berarti bahwa masalah yang tidak terduga dapat muncul di tempat yang tidak terduga. Bergantung pada bagaimana model ini digunakan, masalah keamanan dapat muncul dalam prosesnya.
Model terlatih
Model yang telah dilatih sebelumnya mudah digunakan dan dapat dengan cepat mengirimkan data untuk klasifikasi. Dalam kasus ini, Anda tidak perlu menentukan model dan melatihnya - semua ini telah dilakukan sebelum Anda, dan model tersebut siap digunakan segera setelah penerapan. Model yang dilatih sebelumnya dari perpustakaan Torchvision dilatih pada satu set gambar dari database Imagenet , dibagi menjadi 1000 kategori... Penting untuk diingat bahwa pelatihan ini melibatkan pengidentifikasian satu objek dalam gambar, bukan penguraian gambar kompleks yang berisi berbagai objek. Dalam kasus kedua, Anda juga bisa mendapatkan hasil yang menarik, tetapi ini adalah topik yang sama sekali berbeda. Mengunduh model yang telah dilatih sebelumnya dari perpustakaan Torchvision sangatlah mudah. Anda hanya perlu mengimpor model yang dipilih dengan menyetel parameter yang telah dilatih sebelumnya ke True. Saya juga menyertakan mode evaluasi dalam model, karena tidak ada kurva pembelajaran selama tes.
Pertama, saya memiliki sebaris kode yang memilih untuk menggunakan cuda atau cpu, tergantung pada apakah GPU tersedia. Untuk tes sederhana seperti itu, GPU tidak diperlukan, tetapi karena saya punya, saya menggunakannya.
device = "cuda" if torch.cuda.is_available() else "cpu"
import torchvision.models as models
vgg16 = models.vgg16(pretrained=True)
vgg16.eval()
vgg16.to(device)
Daftar model terlatih dari Torchvision dapat ditemukan di sini . Saya tidak ingin menggunakan semua jaringan saraf terlatih, ini sudah terlalu berlebihan. Saya memilih lima berikut:
- vgg16
- resnet18
- alexnet.dll
- densenet
- lahirnya
Saya tidak menggunakan metodologi khusus untuk memilih jaringan saraf. Misalnya, Vgg16 dan Inception sering digunakan dalam contoh yang berbeda, dan semuanya berbeda.
Cara membuat gambar dengan noise
Kami membutuhkan cara untuk secara otomatis menghasilkan gambar yang berisi noise yang dapat dimasukkan ke jaringan saraf. Untuk melakukan ini, saya menggunakan kombinasi pustaka Numpy dan PIL, dan menulis fungsi kecil yang mengembalikan gambar yang diisi dengan noise acak.
import numpy as np
from PIL import Image
def gen_image():
image = (np.random.standard_normal([256, 256, 3]) * 255).astype(np.uint8)
im = Image.fromarray(image)
return im
Anda berakhir dengan sesuatu seperti berikut:

Mengonversi gambar
Setelah itu, kita perlu mengubah gambar kita menjadi tensor dan menormalkannya. Kode berikut dapat digunakan tidak hanya pada gangguan acak, tetapi juga pada gambar apa pun yang ingin kita berikan ke jaringan saraf terlatih (itulah mengapa kode menggunakan nilai Resize dan CenterCrop).
def xform_image(image):
transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
new_image = transform(image).to(device)
new_image = new_image.unsqueeze_(0)
return new_imageKami mendapatkan prediksi
Setelah menyiapkan gambar yang diubah, mudah untuk mendapatkan prediksi dari model yang tidak dilipat. Dalam kasus ini, fungsi xform_image diasumsikan mengembalikan image_xform. Dalam kode yang saya gunakan untuk pengujian, saya membagi pekerjaan antara dua fungsi ini, tetapi di sini saya menggabungkannya untuk kemudahan referensi. Kita pada dasarnya perlu memberi makan gambar yang diubah ke jaringan, menjalankan fungsi softmax, menggunakan fungsi topk untuk mendapatkan skor, dan ID label yang diprediksi untuk hasil terbaik.
with torch.no_grad():
vgg16_res = vgg16(image_xform)
vgg16_output = F.softmax(vgg16_res, dim=1)
vgg16score, pred_label_idx = torch.topk(vgg16_output, 1)
hasil
Nah, sekarang kita melihat bagaimana menghasilkan gambar yang berisik dan memasukkannya ke jaringan yang sudah dilatih sebelumnya. Lalu apa hasilnya? Untuk pengujian ini, saya memutuskan untuk menghasilkan 1000 gambar berisik, menjalankannya melalui 5 jaringan terlatih yang dipilih, dan memasukkannya ke dalam bingkai data Pandas untuk analisis cepat. Hasilnya menarik dan agak tidak terduga.
| vgg16 | resnet18 | alexnet.dll | densenet | lahirnya | |
|---|---|---|---|---|---|
| menghitung | 1000,000000 | 1000,000000 | 1000,000000 | 1000,000000 | 1000,000000 |
| berarti | 0,226978 | 0,328249 | 0.147289 | 0.409413 | 0,020204 |
| std | 0,067972 | 0,071808 | 0,038628 | 0.148315 | 0,016490 |
| min | 0,074922 | 0,127953 | 0,061019 | 0.139161 | 0,005963 |
| 25% | 0.178240 | 0,278830 | 0.120568 | 0,291042 | 0,011641 |
| 50% | 0,223623 | 0,324111 | 0,143090 | 0,387705 | 0,015880 |
| 75% | 0,270547 | 0,373325 | 0.171139 | 0,511357 | 0,022519 |
| maks | 0.438011 | 0,580559 | 0,328568 | 0.868025 | 0.198698 |
Seperti yang Anda lihat, beberapa jaringan saraf telah memutuskan bahwa derau ini sebenarnya mewakili sesuatu yang spesifik dengan tingkat keyakinan yang cukup tinggi. Resnet18 dan densenet telah mencapai puncaknya pada 50%. Itu semua bagus dan bagus, tetapi apa sebenarnya yang "dilihat" jaringan ini dalam kebisingan? Menariknya, berbagai jaringan "menemukan" objek yang berbeda di sana. Setiap jaringan melihat sesuatu yang berbeda. Resnet18 100% yakin bahwa itu adalah ubur-ubur, sedangkan Inception, sebaliknya, memiliki keyakinan yang sangat kecil pada prediksi, meskipun ia melihat lebih banyak objek daripada jaringan lain.
Vgg16:
978
14
7
1
Resnet18:
1000
Alexnet:
942
58
Densenet:
893
37
33
20
16
1
Inception:
155
123
102
85
83
81
69
32
26
25
24
18
16
16
12
12
11
9
9
8
7
5
5
5
- 5
4
4
4
4
3
3
3
3
3
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
Hanya untuk bersenang-senang, saya memutuskan untuk melihat jenis tanda tangan apa yang akan diletakkan Microsoft di bawah gambar noise, yang saya bawa lebih dekat ke awal entri ini. Untuk pengujian, saya memutuskan untuk menggunakan cara yang paling sederhana dan menggunakan PowerPoint dari Office 365. Hasilnya menarik karena tidak seperti model imagenet yang mencoba mengenali satu objek, PowerPoint mencoba mengenali beberapa objek untuk membuat deskripsi gambar yang akurat.
Gambar menunjukkan gajah, orang, besar, bola.
Hasilnya tidak mengecewakan saya. Dari sudut pandang saya, gambar noise dikenali sebagai sirkus.
Perspektif
Ini membawa kita ke pertanyaan lain - apa yang dilihat oleh jaringan saraf yang membuatnya berpikir bahwa kebisingan adalah sebuah objek? Dalam pencarian kami untuk sebuah jawaban, kami dapat menggunakan alat interpretasi model yang akan memungkinkan kami untuk memahami secara kasar apa yang "dilihat" jaringan. Captum adalah kerangka kerja interpretasi model untuk PyTorch. Saya tidak melakukan sesuatu yang istimewa di sini, saya hanya menggunakan kode dari tutorial di situs web mereka. Saya baru saja menambahkan parameter internal_batch_size dengan nilai 50, karena tanpa itu GPU saya kehabisan memori dengan sangat cepat.
Untuk rendering, saya menggunakan dua atribusi berbasis gradien dan atribusi berbasis oklusi. Dengan visualisasi ini, kami mencoba memahami apa yang penting bagi pengklasifikasi dan karena itu "melihat" apa yang dilihat jaringan. Saya juga menggunakan model resnet terlatih saya, namun Anda dapat mengubah kode dan menggunakan model terlatih lainnya.
Sebelum beralih ke noise, saya mengambil gambar chamomile sebagai demonstrasi proses rendering, karena tandanya mudah dikenali.
result = resnet18(image_xform)
result = F.softmax(result, dim=1)
score, pred_label_idx = torch.topk(result, 1)
integrated_gradients = IntegratedGradients(resnet18)
attributions_ig = integrated_gradients.attribute(image_xform, target=pred_label_idx,
internal_batch_size=50, n_steps=200)
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(image_xform, n_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx, internal_batch_size=50)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)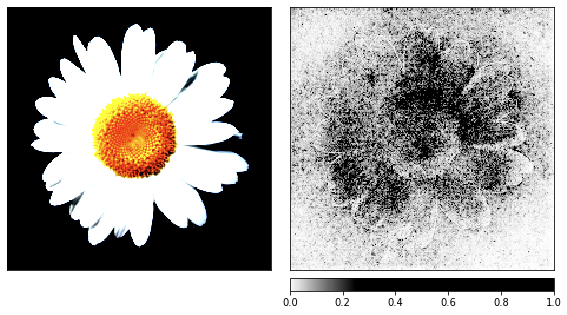
occlusion = Occlusion(resnet18)
attributions_occ = occlusion.attribute(image_xform,
strides = (3, 8, 8),
target=pred_label_idx,
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
show_colorbar=True,
outlier_perc=2,
)

Visualisasi kebisingan
Kami membuat gambar sebelumnya berdasarkan chamomile, dan sekarang saatnya untuk melihat bagaimana segala sesuatunya bekerja dengan noise acak.
Saya menggunakan jaringan resnet18 yang sudah dilatih sebelumnya dan dengan gambar ini dia yakin 40% dia melihat ubur-ubur. Saya tidak akan mengulang kodenya, kode untuk rendering sama dengan yang diberikan di atas.


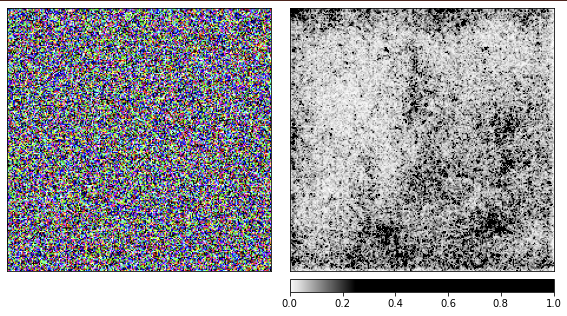

Dari visualisasinya terlihat jelas bahwa kita manusia tidak akan pernah bisa mengerti mengapa jaringan melihat ubur-ubur di sini. Beberapa area gambar ditandai sebagai lebih penting, tetapi sama sekali tidak didefinisikan seperti yang kita lihat pada contoh chamomile. Tidak seperti kamomil, ubur-ubur bersifat amorf dan berbeda dalam tingkat transparansinya.
Anda mungkin bertanya-tanya seperti apa rendering pemrosesan gambar ubur-ubur yang sebenarnya? Kode saya diposting di Github, dan akan mudah untuk mendapatkan jawaban atas pertanyaan ini dengan bantuannya.
Kesimpulan
Berdasarkan rekaman ini, mudah untuk melihat betapa mudahnya menipu jaringan saraf dengan memberi mereka masukan yang tidak terduga. Untuk pujian mereka, kami akan mengatakan bahwa mereka melakukan pekerjaan mereka dan memberikan hasil terbaik yang mereka bisa. Dapat juga dilihat dari hasil pekerjaan bahwa dalam kasus seperti itu tidak cukup hanya dengan menyaring opsi dengan keyakinan rendah, karena beberapa opsi memiliki keyakinan yang agak tinggi. Kita perlu waspada terhadap situasi di mana sistem dunia nyata gagal begitu mudah. Kita tidak perlu terkejut dengan data tak terduga yang memasuki sistem - dan inilah yang telah dilakukan oleh pakar keamanan selama beberapa waktu.