Saya saat ini bekerja di ManyChat. Sebenarnya, ini adalah startup - baru, ambisius, dan berkembang pesat. Dan ketika saya pertama kali bergabung dengan perusahaan, pertanyaan klasik muncul: "Apa yang harus diambil oleh startup muda dari pasar DBMS dan database sekarang?"
Pada artikel ini, berdasarkan pembicaraan saya di festival online RIT ++ 2020 , saya akan menjawab pertanyaan ini. Versi video dari laporan tersebut tersedia di YouTube .
Database terkenal tahun 2020
Ini tahun 2020, saya melihat sekeliling dan melihat tiga jenis database.
Jenis pertama adalah database OLTP klasik : PostgreSQL, SQL Server, Oracle, MySQL. Itu sudah lama ditulis, tetapi masih relevan karena akrab dengan komunitas pengembang.
Jenis kedua - basis dari "nol" . Mereka mencoba beralih dari pola klasik dengan beralih dari SQL, struktur tradisional, dan ACID, dengan menambahkan sharding sebaris dan fitur menarik lainnya. Misalnya, Cassandra, MongoDB, Redis, atau Tarantool. Semua solusi ini ingin menawarkan pasar sesuatu yang secara fundamental baru dan menempati ceruk mereka, karena dalam tugas-tugas tertentu mereka ternyata sangat nyaman. Basis ini akan dilambangkan dengan istilah payung NOSQL.
Yang "nol" sudah berakhir, mereka terbiasa dengan database NOSQL, dan dunia, dari sudut pandang saya, telah mengambil langkah berikutnya - untuk mengelola database . Database ini memiliki inti yang sama dengan database OLTP klasik atau database NoSQL baru. Tapi mereka tidak membutuhkan DBA dan DevOps dan berjalan pada perangkat keras terkelola di cloud. Untuk pengembang, ini adalah "hanya basis" yang berfungsi di suatu tempat, tetapi bagaimana itu diinstal di server, yang mengkonfigurasi server dan yang memperbaruinya, tidak ada yang peduli.
Contoh basa seperti itu:
- AWS RDS adalah pembungkus terkelola di atas PostgreSQL / MySQL.
- DynamoDB adalah analog AWS dari database berbasis dokumen, mirip dengan Redis dan MongoDB.
- Amazon Redshift adalah basis analitik terkelola.
Pada intinya, ini adalah basis lama, tetapi dibesarkan dalam lingkungan terkelola, tanpa perlu bekerja dengan perangkat keras.
Catatan. Contoh diambil untuk lingkungan AWS, tetapi rekan mereka juga ada di Microsoft Azure, Google Cloud, atau Yandex.Cloud.

Jadi, apa yang baru? Pada tahun 2020, semua ini tidak ada.
Konsep tanpa server
Apa yang benar-benar baru di pasar pada tahun 2020 adalah solusi tanpa server atau tanpa server.
Saya akan mencoba menjelaskan apa artinya ini menggunakan contoh layanan reguler atau aplikasi backend.
Untuk menerapkan aplikasi backend biasa, kami membeli atau menyewa server, menyalin kodenya, menerbitkan endpoint di luar, dan secara teratur membayar sewa, listrik, dan layanan pusat data. Ini adalah tata letak standar.
Apakah ada cara lain? Dengan layanan tanpa server, Anda bisa.
Apa fokus dari pendekatan ini: tidak ada server, bahkan tidak ada sewa instance virtual di cloud. Untuk menerapkan layanan, salin kode (fungsi) ke repositori dan publikasikan titik akhir di luar. Kemudian kami hanya membayar untuk setiap panggilan dari fungsi ini, sepenuhnya mengabaikan perangkat keras tempat ia dijalankan.
Saya akan mencoba mengilustrasikan pendekatan ini dalam gambar.
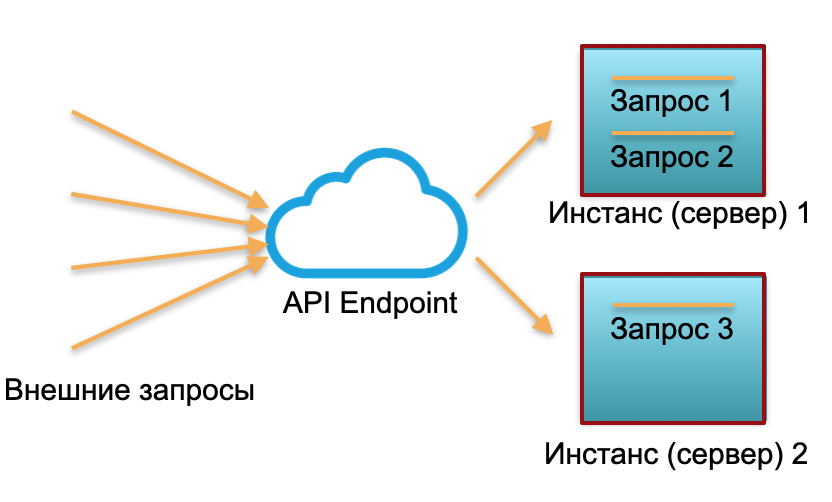
Penerapan klasik . Kami memiliki layanan dengan beban tertentu. Kami mengangkat dua contoh: server fisik atau mesin virtual di AWS. Permintaan eksternal dikirim ke instance ini dan diproses di sana.
Seperti yang Anda lihat pada gambar, server digunakan secara berbeda. Satu digunakan 100%, ada dua permintaan, dan satu hanya 50% menganggur sebagian. Jika bukan tiga permintaan yang datang, tetapi 30, maka seluruh sistem tidak akan menangani beban dan akan mulai melambat.

Penerapan tanpa server... Dalam lingkungan tanpa server, layanan seperti itu tidak memiliki contoh atau server. Ada kumpulan sumber daya yang dihangatkan - wadah Docker kecil yang disiapkan dengan kode fungsi yang diterapkan. Sistem menerima permintaan eksternal dan untuk masing-masing dari mereka, kerangka kerja tanpa server memunculkan wadah kecil dengan kode: ia memproses permintaan khusus ini dan mematikan wadah.
Satu permintaan - satu kontainer terangkat, 1000 permintaan - 1000 kontainer. Dan penerapan pada server besi sudah menjadi pekerjaan penyedia cloud. Itu benar-benar tersembunyi oleh kerangka tanpa server. Dalam konsep ini, kami membayar untuk setiap panggilan. Misalnya, satu panggilan sehari datang - kami membayar untuk satu panggilan, satu juta datang dalam satu menit - kami membayar satu juta. Atau sedetik, ini juga terjadi.
Konsep penerbitan fungsi tanpa server sesuai untuk layanan tanpa negara. Dan jika Anda membutuhkan layanan statefull (status), tambahkan database ke layanan tersebut. Dalam kasus ini, ketika bekerja dengan state, dengan state, setiap fungsi statefull hanya menulis dan membaca dari database. Selain itu, dari database salah satu dari tiga jenis yang dijelaskan di awal artikel.
Apa batasan umum dari semua basis ini? Ini adalah biaya cloud atau server besi yang terus digunakan (atau beberapa server). Tidak masalah apakah kami menggunakan database klasik atau dikelola, apakah kami memiliki Devops dan admin atau tidak, kami tetap membayar 24/7 untuk sewa perangkat keras, listrik, dan pusat data. Jika kami memiliki basis klasik, kami membayar untuk tuan dan budak. Jika basis sharded yang sangat dimuat - kami membayar untuk 10, 20 atau 30 server, dan kami membayar terus-menerus.
Kehadiran server yang dipesan secara permanen dalam struktur biaya sebelumnya dianggap sebagai kejahatan yang diperlukan. Basis data biasa juga memiliki kesulitan lain, seperti batasan jumlah koneksi, batas penskalaan, konsensus terdistribusi geografis - entah bagaimana dapat diselesaikan dalam basis data tertentu, tetapi tidak semuanya sekaligus dan tidak ideal.
Database tanpa server - teori
Pertanyaan 2020: Bisakah database juga dibuat tanpa server? Semua orang pernah mendengar tentang backend tanpa server ... tapi mari kita coba membuat database tanpa server juga?
Ini terdengar aneh karena database adalah layanan statefull, tidak terlalu cocok untuk infrastruktur tanpa server. Pada saat yang sama, status database sangat besar: gigabyte, terabyte, dan bahkan petabyte dalam database analitis. Tidak mudah mengangkatnya dalam wadah Docker yang ringan.
Di sisi lain, hampir semua database modern adalah sejumlah besar logika dan komponen: transaksi, negosiasi integritas, prosedur, ketergantungan relasional, dan banyak logika. Cukup banyak logika database yang merupakan status yang cukup kecil. Gigabyte dan Terabyte secara langsung digunakan hanya oleh sebagian kecil dari logika database yang terkait dengan kueri yang dieksekusi secara langsung.
Dengan demikian, idenya: jika bagian dari logika memungkinkan eksekusi tanpa kewarganegaraan, mengapa tidak memotong basis menjadi bagian-bagian Stateful dan Stateless.
Tanpa server untuk solusi OLAP
Mari kita lihat bagaimana database yang dipotong menjadi bagian-bagian Stateful dan Stateless dengan contoh-contoh praktis.
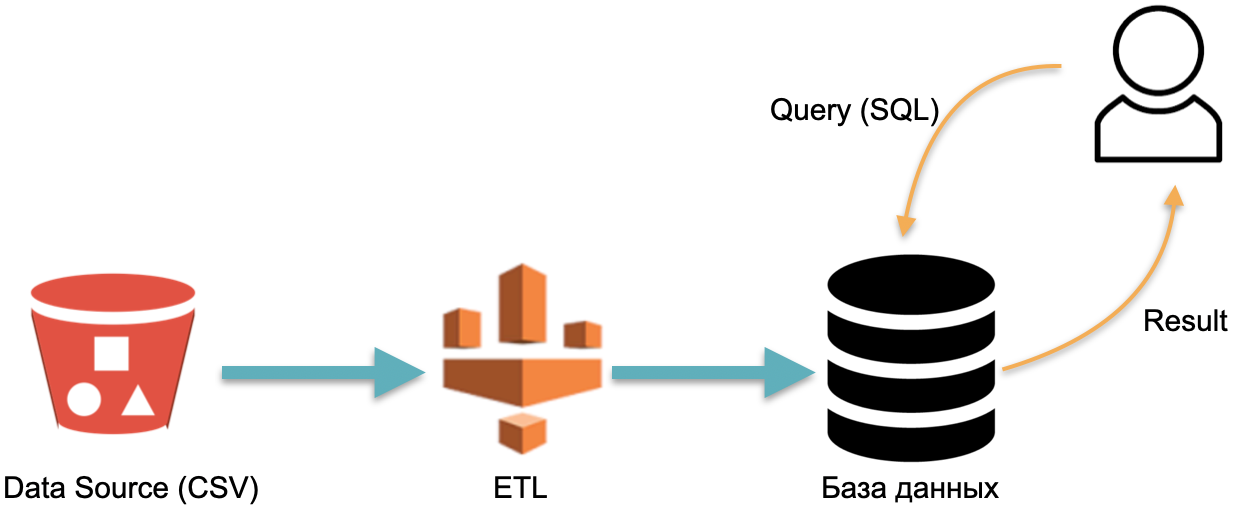
Misalnya, kami memiliki database analitik : data eksternal (silinder merah di sebelah kiri), proses ETL yang memuat data ke database, dan analis yang mengirimkan kueri SQL ke database. Ini adalah cara kerja gudang data klasik.
Dalam skema ini, menurut konvensi, ETL dijalankan satu kali. Maka Anda harus membayar setiap saat untuk server yang menjalankan database dengan data yang dibanjiri ETL, sehingga Anda memiliki sesuatu untuk dilontarkan permintaan.
Pertimbangkan pendekatan alternatif yang diterapkan di AWS Athena Tanpa Server. Tidak ada perangkat keras yang didedikasikan secara permanen untuk menyimpan data yang diunduh. Dari pada ini:
- SQL- Athena. Athena SQL- (Metadata) , .
- , , ( ).
- SQL- , .
- , .
Dalam arsitektur ini, kami hanya membayar untuk proses eksekusi permintaan. Tidak ada permintaan - tanpa biaya.
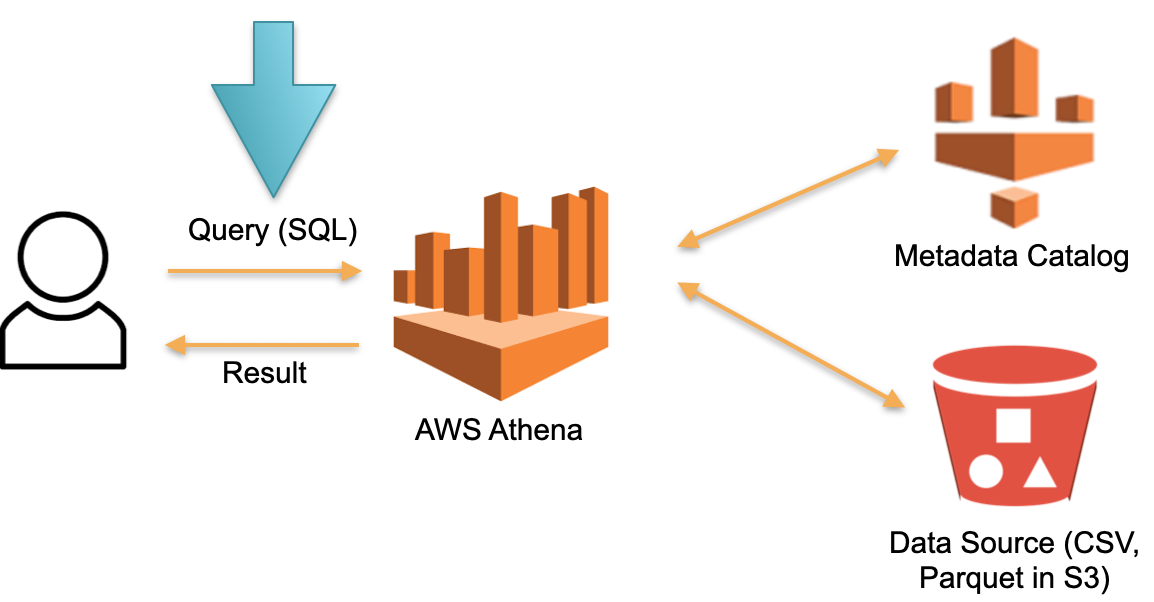
Ini adalah pendekatan yang berfungsi dan diterapkan tidak hanya di Athena Tanpa Server, tetapi juga di Redshift Spectrum (di AWS).
Contoh Athena menunjukkan bahwa database Tanpa Server berfungsi pada kueri nyata dengan puluhan dan ratusan Terabyte data. Ratusan Terabyte akan membutuhkan ratusan server, tetapi kami tidak harus membayarnya - kami membayar untuk permintaan. Kecepatan setiap permintaan (sangat) lambat dibandingkan dengan database analitik khusus seperti Vertica, tetapi kami tidak membayar waktu henti.
Database seperti itu berguna untuk kueri analitik ad-hoc yang jarang. Misalnya, ketika kita secara spontan memutuskan untuk menguji hipotesis pada sejumlah besar data. Athena sangat cocok untuk kasus ini. Untuk pertanyaan reguler, sistem seperti itu mahal. Dalam kasus ini, cache data dalam beberapa solusi khusus.
Tanpa server untuk solusi OLTP
Dalam contoh sebelumnya, tugas OLAP (analitis) dianggap. Sekarang mari kita lihat tugas OLTP.
Bayangkan PostgreSQL atau MySQL yang dapat diskalakan. Mari kita buat instance terkelola biasa PostgreSQL atau MySQL dengan sumber daya minimal. Ketika lebih banyak beban tiba pada instance, kami akan menghubungkan replika tambahan yang akan kami distribusikan sebagian dari beban pembacaan. Jika tidak ada permintaan dan tidak ada beban, kami menonaktifkan replika. Contoh pertama adalah master, dan sisanya adalah replika.
Ide ini diimplementasikan dalam database yang disebut Aurora Tanpa Server AWS. Prinsipnya sederhana: permintaan dari aplikasi eksternal diterima oleh armada proxy. Melihat peningkatan beban, itu mengalokasikan sumber daya komputasi dari instans minimum yang dihangatkan sebelumnya - koneksi secepat mungkin. Instance pemutusan hubungan sama.
Di dalam Aurora, ada konsep Unit Kapasitas Aurora, ACU. Ini adalah (secara kondisional) sebuah instance (server). Setiap ACU tertentu dapat menjadi master atau slave. Setiap Unit Kapasitas memiliki RAM, prosesor, dan disk minimumnya sendiri. Karenanya, satu adalah master, sisanya adalah replika hanya baca.
Jumlah Unit Kapasitas Aurora yang beroperasi dapat dikonfigurasi. Kuantitas minimum bisa satu atau nol (dalam hal ini, basis tidak berfungsi jika tidak ada permintaan).

Ketika basis menerima permintaan, armada proxy meningkatkan Unit Kapasitas Aurora, meningkatkan sumber daya produktif sistem. Kemampuan untuk menambah dan mengurangi resource memungkinkan sistem untuk "menyulap" resource: secara otomatis menampilkan ACU individual (menggantinya dengan yang baru) dan meluncurkan semua pembaruan yang relevan ke resource yang dihapus.
Basis Aurora Tanpa Server dapat menskalakan beban baca. Tapi dokumentasinya tidak mengatakannya secara langsung. Ini mungkin terasa seperti mereka bisa mengambil multi-master. Tidak ada keajaiban.
Basis ini sangat cocok untuk tidak menghabiskan banyak uang pada sistem dengan akses yang tidak dapat diprediksi. Misalnya, saat membangun MVP atau situs pemasaran kartu nama, biasanya kita tidak mengharapkan muat yang stabil. Karenanya, jika tidak ada akses, kami tidak membayar untuk contoh. Saat beban muncul secara tidak terduga, misalnya, setelah konferensi atau kampanye iklan, kerumunan orang mengunjungi situs dan beban meningkat secara dramatis, Aurora Tanpa Server secara otomatis mengambil alih beban ini dan dengan cepat menghubungkan sumber daya yang hilang (ACU). Kemudian konferensi berlanjut, semua orang lupa tentang prototipe, server (ACU) mati, dan biaya turun menjadi nol - itu nyaman.
Solusi ini tidak cocok untuk beban tinggi yang stabil karena tidak dapat menskalakan beban penulisan. Semua koneksi dan pemutusan sumber daya ini terjadi pada saat yang disebut "titik skala" - saat ketika database tidak dipegang oleh transaksi, tabel sementara tidak disimpan. Misalnya, selama seminggu, titik skala mungkin tidak terjadi, dan pangkalan bekerja pada sumber daya yang sama dan tidak dapat meluas atau menyusut.
Tidak ada keajaiban - ini adalah PostgreSQL normal. Tetapi proses penambahan dan pemutusan sambungan mobil sebagian dilakukan secara otomatis.
Tanpa server berdasarkan desain
Aurora Tanpa Server adalah basis lama yang ditulis ulang untuk cloud guna memanfaatkan keuntungan individual Tanpa Server. Dan sekarang saya akan memberi tahu Anda tentang pangkalan, yang awalnya ditulis untuk cloud, untuk pendekatan tanpa server - Tanpa server menurut desain. Itu segera dikembangkan tanpa asumsi bahwa itu berjalan di server fisik.
Basis ini disebut Snowflake. Ini memiliki tiga blok kunci.
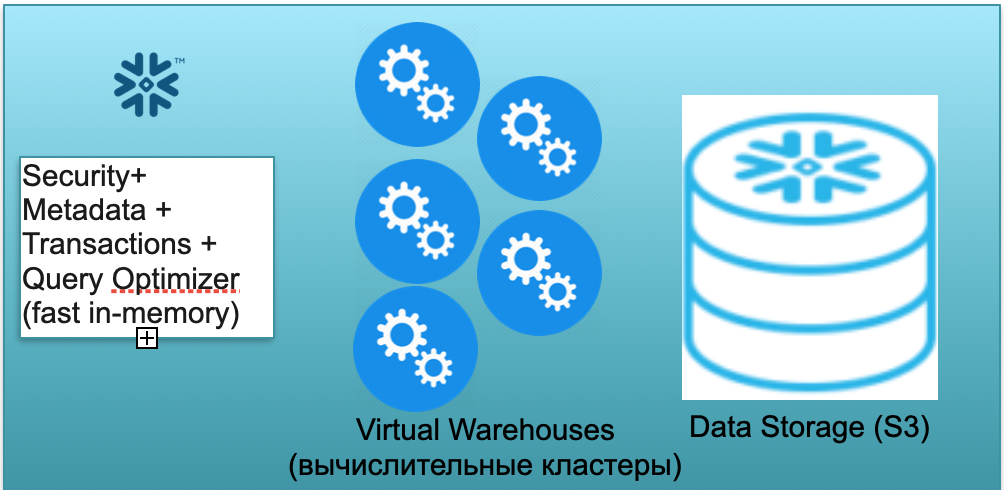
Yang pertama adalah blok metadata. Ini adalah layanan dalam memori cepat yang memecahkan masalah dengan keamanan, metadata, transaksi, pengoptimalan kueri (dalam ilustrasi di sebelah kiri).
Blok kedua adalah satu set cluster komputasi virtual untuk perhitungan (dalam ilustrasi - satu set lingkaran biru).
Blok ketiga adalah sistem penyimpanan berbasis S3. S3 adalah penyimpanan objek tanpa dimensi AWS, serupa dengan Dropbox untuk bisnis tanpa dimensi.
Mari kita lihat cara kerja Kepingan Salju dengan asumsi start dingin. Artinya, database ada di sana, data dimuat ke dalamnya, tidak ada kueri yang berfungsi. Karenanya, jika tidak ada kueri ke database, maka kami telah memunculkan layanan Metadata dalam memori yang cepat (blok pertama). Dan kami memiliki penyimpanan S3, tempat data tabel disimpan, dibagi menjadi apa yang disebut mikropartisi. Untuk kesederhanaan: jika tabel berisi penawaran, maka lot mikro adalah hari-hari penawaran. Setiap hari adalah mikro-batch terpisah, file terpisah. Dan ketika database bekerja dalam mode ini, Anda hanya membayar ruang yang ditempati oleh data. Apalagi tarif per kursi sangat rendah (terutama mengingat kompresi yang signifikan). Layanan metadata juga bekerja secara konstan, tetapi tidak membutuhkan banyak sumber daya untuk mengoptimalkan kueri, dan layanan tersebut dapat dianggap sebagai shareware.
Sekarang mari kita bayangkan bahwa seorang pengguna datang ke database kami dan melemparkan kueri SQL. Kueri SQL segera dikirim ke layanan Metadata untuk diproses. Karenanya, setelah menerima permintaan, layanan ini menganalisis permintaan, data yang tersedia, otoritas pengguna dan, jika semuanya baik-baik saja, menyusun rencana pemrosesan permintaan.
Selanjutnya, layanan memulai peluncuran cluster komputasi. Cluster komputasi adalah sekumpulan server yang melakukan komputasi. Artinya, ini adalah cluster yang dapat berisi 1 server, 2 utara, 4, 8, 16, 32 - sebanyak yang Anda inginkan. Anda melempar permintaan dan peluncuran cluster ini langsung dimulai di bawahnya. Ini benar-benar membutuhkan beberapa detik.
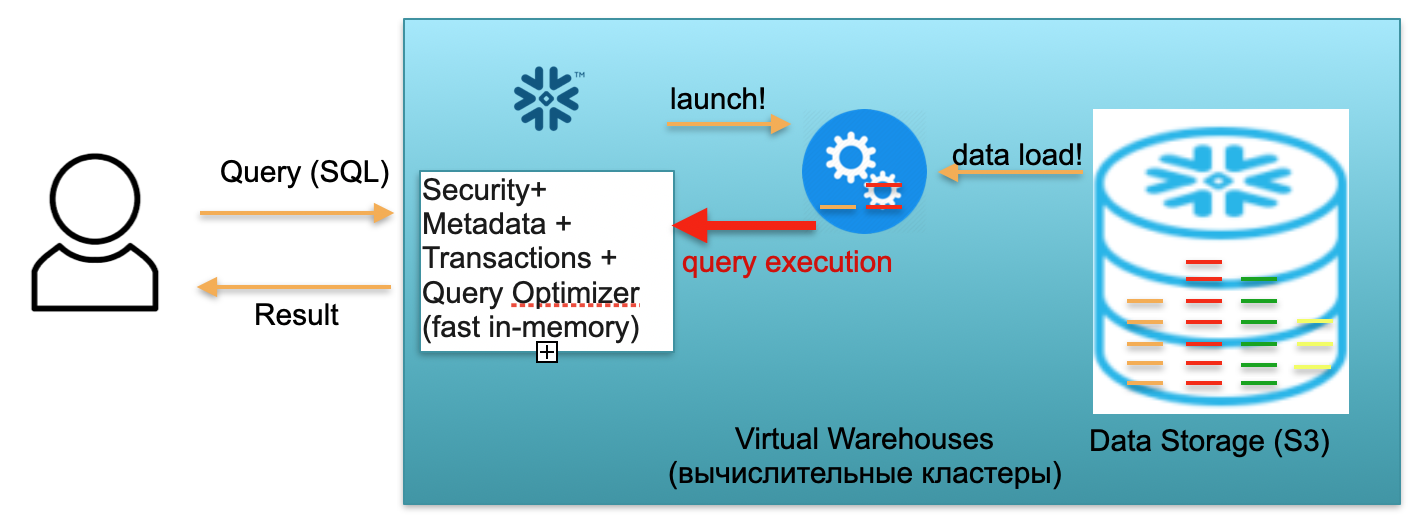
Selanjutnya, setelah cluster dimulai, mikropartisi disalin dari S3 ke cluster, yang diperlukan untuk memproses permintaan Anda. Artinya, bayangkan bahwa untuk menjalankan kueri SQL, Anda memerlukan dua partisi dari satu tabel dan satu dari yang kedua. Dalam hal ini, hanya tiga partisi yang diperlukan yang akan disalin ke cluster, dan tidak semua tabel secara keseluruhan. Itulah mengapa dan tepatnya karena semuanya berada dalam kerangka satu pusat data dan dihubungkan oleh saluran yang sangat cepat, seluruh proses pemompaan berlangsung sangat cepat: dalam hitungan detik, sangat jarang - dalam menit, jika kita tidak membicarakan beberapa permintaan yang mengerikan ... Karenanya, mikropartisi disalin ke cluster komputasi, dan, setelah selesai, kueri SQL dijalankan pada cluster komputasi ini. Hasil dari kueri ini dapat berupa satu baris, beberapa baris, atau tabel - dikirim ke pengguna,sehingga dapat diunduh, ditampilkan di alat BI-nya, atau digunakan dengan cara lain.
Setiap kueri SQL tidak hanya dapat membaca agregat dari data yang dimuat sebelumnya, tetapi juga memuat / membentuk data baru dalam database. Artinya, ini bisa berupa kueri yang, misalnya, memasukkan catatan baru ke dalam tabel lain, yang mengarah ke munculnya partisi baru pada kluster komputasi, yang, pada gilirannya, secara otomatis disimpan dalam satu penyimpanan S3.
Skenario yang dijelaskan di atas, dari kedatangan pengguna untuk meningkatkan cluster, memuat data, menjalankan kueri, mendapatkan hasil, dibayar dengan tarif per menit menggunakan cluster komputasi virtual yang dinaikkan, gudang virtual. Tarifnya bervariasi menurut zona AWS dan ukuran kluster, tetapi rata-rata beberapa dolar per jam. Sekelompok empat mobil dua kali lebih mahal dari sekelompok dua mobil, dan delapan mobil dua kali lebih mahal. Pilihan yang tersedia dari 16, 32 mobil, tergantung pada kompleksitas permintaan. Tetapi Anda hanya membayar untuk menit-menit ketika cluster benar-benar berfungsi, karena ketika tidak ada permintaan, Anda seperti melepaskan tangan Anda, dan setelah 5-10 menit menunggu (parameter yang dapat dikonfigurasi) itu akan keluar dengan sendirinya, membebaskan sumber daya dan menjadi gratis.
Skenario ini cukup nyata ketika Anda mengajukan permintaan, kluster muncul, secara relatif, dalam satu menit, ia menghitung satu menit lagi, kemudian lima menit untuk mematikan, dan Anda membayar sebagai hasilnya selama tujuh menit dari operasi kluster ini, dan bukan selama berbulan-bulan dan bertahun-tahun.
Skenario pertama dijelaskan menggunakan Snowflake dalam skenario pengguna tunggal. Sekarang mari kita bayangkan bahwa ada banyak pengguna, yang mendekati skenario nyata.
Katakanlah kita memiliki banyak analis dan laporan Tableau yang terus-menerus membombardir database kita dengan sejumlah besar kueri SQL analitis sederhana.
Selain itu, katakanlah kita memiliki Ilmuwan Data yang cerdik yang mencoba melakukan hal-hal mengerikan dengan data, beroperasi pada puluhan terabyte, menganalisis miliaran dan triliunan baris data.
Untuk dua jenis beban yang dijelaskan di atas, Kepingan Salju memungkinkan Anda mengangkat beberapa kluster komputasi independen dengan kapasitas berbeda. Selain itu, cluster komputasi ini beroperasi secara independen, tetapi dengan data konsisten yang sama.
Untuk kueri ringan dalam jumlah besar, Anda dapat meningkatkan 2-3 cluster kecil, biasanya berukuran 2 mesin. Perilaku ini dapat direalisasikan, antara lain, dengan menggunakan pengaturan otomatis. Artinya, Anda berkata, “Kepingan salju, buat kelompok kecil. Jika beban di atasnya tumbuh lebih dari parameter tertentu, naikkan yang serupa kedua, ketiga. Saat beban mulai mereda - padamkan yang ekstra. " Sehingga tidak peduli berapa banyak analis yang datang dan mulai melihat laporan, setiap orang memiliki sumber daya yang cukup.
Pada saat yang sama, jika analis tertidur dan tidak ada yang melihat laporan, cluster dapat sepenuhnya keluar, dan Anda berhenti membayarnya.
Pada saat yang sama, untuk kueri berat (dari Ilmuwan Data), Anda dapat menaikkan satu kluster yang sangat besar per 32 mesin bersyarat. Kluster ini juga akan ditagih hanya untuk menit dan jam saat permintaan raksasa Anda berjalan di sana.
Fitur yang dijelaskan di atas memungkinkan untuk membagi menjadi beberapa cluster tidak hanya 2, tetapi juga lebih banyak jenis beban (ETL, pemantauan, materialisasi laporan, ...).
Mari kita rangkum Kepingan Salju. Basisnya menggabungkan ide bagus dan implementasi yang bisa diterapkan. Di ManyChat, kami menggunakan Snowflake untuk menganalisis semua data yang kami miliki. Kami tidak memiliki tiga kelompok, seperti pada contoh, tetapi dari 5 hingga 9, dengan ukuran berbeda. Kami memiliki 16 mesin bersyarat, 2 mesin, ada juga 1 mesin super kecil untuk beberapa tugas. Mereka berhasil mendistribusikan beban dan memungkinkan kami untuk menghemat banyak.
Basis berhasil mengukur beban kerja membaca dan menulis. Ini adalah perbedaan besar dan terobosan besar dibandingkan dengan "Aurora" yang sama, yang hanya menarik beban pembacaan. Snowflake memungkinkan cluster komputasi ini menskalakan dan menulis beban kerja. Artinya, seperti yang saya sebutkan, kami menggunakan beberapa cluster di ManyChat, cluster kecil dan super kecil terutama digunakan untuk ETL, untuk memuat data. Dan analis sudah tinggal di cluster berukuran sedang yang sama sekali tidak terpengaruh oleh beban ETL, sehingga mereka bekerja dengan sangat cepat.
Dengan demikian, pangkalan tersebut sangat cocok untuk tugas OLAP. Sayangnya, pada saat yang sama, ini belum berlaku untuk beban kerja OLTP. Pertama, basis ini berbentuk kolom, dengan semua konsekuensi selanjutnya. Kedua, pendekatan itu sendiri, ketika untuk setiap permintaan, jika perlu, Anda meningkatkan cluster komputasi dan menumpahkannya dengan data, sayangnya, untuk beban kerja OLTP itu tidak cukup cepat. Menunggu beberapa detik untuk tugas OLAP adalah normal, tetapi untuk tugas OLTP itu tidak dapat diterima, 100 ms akan lebih baik, dan bahkan lebih baik - 10 ms.
Hasil
Database tanpa server dimungkinkan dengan memisahkan database menjadi bagian Stateless dan Stateful. Anda pasti telah memperhatikan bahwa di semua contoh yang diberikan, bagian Stateful, secara relatif, menyimpan mikropartisi di S3, dan Stateless adalah pengoptimal, bekerja dengan metadata, menangani masalah keamanan yang dapat diangkat sebagai ringan independen Layanan tanpa negara.
Menjalankan kueri SQL juga dapat dianggap sebagai layanan status ringan yang dapat muncul dalam mode tanpa server, seperti kluster komputasi Snowflake, hanya mengunduh data yang Anda butuhkan, menjalankan kueri, dan "keluar".
Database tingkat produksi tanpa server sudah tersedia untuk digunakan, mereka berfungsi. Database tanpa server ini sudah siap untuk menangani tugas OLAP. Sayangnya, mereka digunakan untuk tugas OLTP ... dengan sedikit perbedaan, karena ada batasan. Di satu sisi, ini adalah minus. Namun di sisi lain, ini adalah peluang. Mungkin beberapa pembaca akan menemukan cara untuk membuat basis OLTP benar-benar tanpa server, tanpa batasan Aurora.
Semoga Anda tertarik. Tanpa server adalah masa depan :)