
Menulis jurnal adalah salah satu hal yang hanya diingat ketika mereka rusak. Dan ini sama sekali bukan kritik. Intinya adalah bahwa log tidak menghasilkan uang seperti itu. Mereka memberikan wawasan tentang program apa yang sedang (atau telah dilakukan), membantu menjaga hal-hal yang menghasilkan uang. Dalam skala kecil (atau selama pengembangan), informasi yang diperlukan dapat diperoleh hanya dengan menampilkan pesan di
stdout... Tetapi segera setelah Anda masuk ke sistem terdistribusi, dan segera ada kebutuhan untuk menggabungkan pesan-pesan ini dan mengirimkannya ke beberapa repositori pusat, di mana pesan tersebut akan membawa manfaat terbesar. Kebutuhan ini menjadi lebih relevan jika Anda berurusan dengan container di platform seperti Kubernetes, di mana proses dan penyimpanan lokal bersifat sementara.
Pendekatan yang familiar untuk memproses log
Sejak hari-hari awal penampung dan penerbitan manifes Dua Belas Faktor , pola umum tertentu telah terbentuk dalam pemrosesan log yang dihasilkan oleh penampung:
- memproses pesan keluaran ke
stdoutataustderr, -
containerd(Docker) mengalihkan aliran standar ke file di luar kontainer, - dan ekor log forwarder membaca file-file tersebut (yaitu mendapatkan baris terakhir dari mereka) dan mengirimkan data ke database.
Log forwarder populer fluentd adalah proyek CNCF (seperti containerd). Seiring waktu, ini menjadi standar de facto untuk membaca, mengubah, mentransfer, dan mengindeks log. Saat Anda membuat cluster Kubernetes di GKE dengan Cloud Logging (sebelumnya Stackdriver) terhubung, Anda akan mendapatkan pola yang hampir sama - hanya dengan flentd flavor Google .
Pola inilah yang muncul ketika Olark (perusahaan tempat penulis artikel bekerja - kira-kira. Terjemahan)pertama kali memulai migrasi layanan ke K8 sebagai GKE empat tahun lalu. Dan saat kami meningkatkan logging-as-a-service, pola ini diikuti, membuat sistem agregasi log kami sendiri yang mampu memproses 15-20 ribu baris per detik pada beban puncak.
Ada alasan mengapa pendekatan ini bekerja dengan baik dan mengapa prinsip 12-Faktor secara langsung merekomendasikan keluaran log ke aliran standar . Faktanya adalah memungkinkan aplikasi untuk tidak mengkhawatirkan perutean log dan membuat container mudah "dapat diamati" (kita berbicara tentang observabilitas) selama pengembangan atau produksi. Dan jika sistem logging Anda kacau, setidaknya ada beberapa kemungkinan bahwa log akan tetap berada di disk host node cluster.
Kerugian dari pendekatan ini adalah tailing log relatif mahal dalam hal penggunaan CPU . Kami mulai memperhatikan hal ini setelah, selama pengoptimalan sistem logging berikutnya, ternyata fluentd menggunakan 1/8 dari seluruh kuota permintaan CPU dalam produksi:
- Ini sebagian karena topologi cluster: fluentd di-host di setiap node untuk tailing file lokal (seperti DaemonSet , dalam bahasa K8s), Anda memiliki node quad-core dan Anda harus mencadangkan 50% dari inti untuk memproses log, dan ... yah, Anda mengerti.
- Bagian lain dari sumber daya dihabiskan untuk pengolah kata, yang juga kami tetapkan ke fluentd. Memang, siapa yang akan melewatkan kesempatan untuk membersihkan entri log yang dikaburkan?
- Sisanya masuk ke inotifywait , yang memonitor file pada disk, memproses pembacaan, dan melacak.
Kami ingin tahu berapa biayanya: ada cara lain untuk mengirim log ke fluentd. Misalnya, Anda dapat menggunakan port forward (ini tentang penggunaan jenis
forwardin source-. Ca. Perevi.). Akankah lebih murah?
Eksperimen praktis
Untuk mengisolasi biaya pengambilan garis batang kayu dengan menggunakan tailing, saya membuat tempat tidur percobaan kecil . Ini mencakup komponen-komponen berikut:
- Program Python untuk membuat sejumlah penulis log dengan frekuensi dan ukuran pesan yang dapat dikonfigurasi;
- file untuk docker compose berjalan:
- fasih untuk memproses log,
- cAdvisor untuk memantau wadah fluentd,
- Prometheus untuk mengumpulkan metrik cAdvisor,
- Grafana untuk visualisasi data di Prometheus.
Catatan tentang diagram ini:
- Penulis log menghasilkan pesan dalam format JSON yang seragam (yang juga digunakan oleh containerd) dan dapat menuliskannya ke file atau merutekannya ke port penerusan fluentd.
- Saat menulis ke file, kelas digunakan
RotatingFileHandleruntuk mensimulasikan kondisi cluster dengan lebih baik. - Fluentd dikonfigurasi untuk "membuang" semua catatan
nulldan tidak memproses ekspresi reguler atau memeriksa catatan terhadap tag. Jadi, pekerjaan utamanya adalah mendapatkan garis log. - , Prometheus cAdvisor, fluentd.
Pemilihan parameter untuk perbandingan dilakukan dengan agak subyektif. Saya menulis utilitas lain untuk memperkirakan volume log yang dihasilkan oleh node dari cluster kami. Tidak mengherankan, ini sangat bervariasi: dari beberapa puluh baris per detik hingga 500 atau lebih pada node tersibuk.
Ini adalah sumber masalah lain: jika menggunakan DaemonSet, fluentd harus dikonfigurasi untuk menangani node tersibuk di cluster. Pada prinsipnya, ketidakseimbangan dapat dihindari dengan menetapkan label yang sesuai ke pembuat log utama dan menggunakan aturan anti-afinitas lunak untuk mendistribusikannya secara merata, tetapi hal ini di luar cakupan artikel ini. Awalnya, saya berencana untuk membandingkan berbagai mekanisme "pengiriman" logdengan beban 500/1000 baris per detik menggunakan 1 hingga 10 penulis log.
Hasil tes
Pengujian awal menunjukkan bahwa baris per detik adalah kontributor utama penggunaan CPU dalam tailing , terlepas dari berapa banyak file log yang kami amati. Dua grafik di bawah ini membandingkan beban pada 1000 p / dtk dari satu penulis log dan dari 10. Dapat dilihat bahwa keduanya hampir sama:
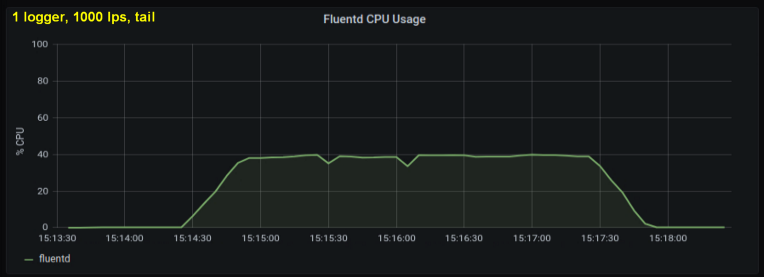
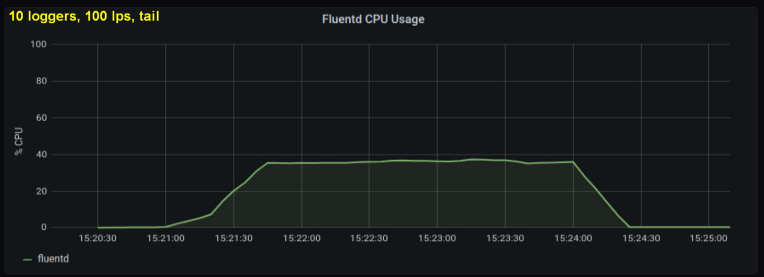
Penyimpangan kecil: Saya tidak menyertakan grafik yang sesuai di sini, tetapi di mesin saya ternyata sepuluh proses log penulisan 100 baris per detik memiliki throughput agregat yang lebih tinggi daripada proses tunggal yang menulis 1000 baris per detik. Ini mungkin karena spesifikasi kode saya - saya tidak sengaja menyelidiki masalah ini.
Bagaimanapun, saya mengharapkan jumlah file log yang terbuka menjadi faktor penting, tetapi ternyata itu tidak terlalu memengaruhi hasil. Variabel tidak signifikan lainnya adalah panjang string. Tes di atas menggunakan panjang string standar 100 karakter. Saya menjalankan dengan garis sepuluh kali lebih lama, tetapi ini tidak memiliki efek yang nyata pada beban prosesor selama pengujian, yang dalam semua kasus adalah 180 detik.
Mempertimbangkan hal di atas, saya memutuskan untuk menguji 2 penulis, karena menurut saya satu proses mencapai batas internal. Di sisi lain, lebih banyak proses juga tidak diperlukan. Melakukan tes dengan 500 dan 1000 baris per detik. Kumpulan plot berikut menunjukkan hasil untuk file tailing dan port penerusan:

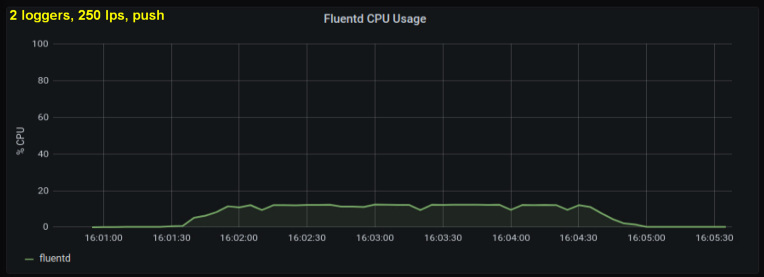
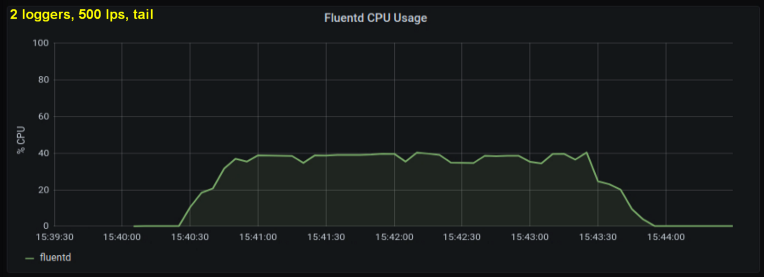

kesimpulan
Selama seminggu, saya menjalankan tes ini dengan berbagai cara dan berakhir dengan dua kesimpulan utama:
- Metode dengan soket maju secara konsisten mengkonsumsi daya pemrosesan 30-50% lebih sedikit daripada membaca baris dari file log dengan ukuran yang sama. Satu penjelasan yang mungkin (untuk setidaknya sebagian dari perbedaan yang dapat diamati) adalah bahwa dengan membuat serial data dalam paket pesan - fluentd. fluentd , messagepack. , Python- forward-, . , : , fluentd, .
- , CPU , . tailing', forward-. , (1000 writer' 10 writer'), forward-:


Apakah hasil ini berarti bahwa kita semua harus menulis log ke soket alih-alih file? Jelas, tidak sesederhana itu ...
Jika kita bisa mengubah cara kita mengumpulkan log dengan mudah, maka sebagian besar masalah yang ada tidak akan menjadi masalah. Mengeluarkan log
stdoutmembuatnya lebih mudah untuk memantau dan bekerja dengan container selama pengembangan. Mengeluarkan log dengan kedua cara, bergantung pada konteksnya, akan sangat meningkatkan kompleksitas - demikian pula, mengonfigurasi fluentd untuk merender log selama pengembangan (misalnya, menggunakan plugin keluaran stdout) akan meningkatkannya .
Mungkin interpretasi yang lebih praktis dari hasil ini akan menjadi rekomendasi untuk memperbesar node... Karena fluentd harus dikonfigurasi untuk bekerja dengan node tersibuk (paling berisik), logis untuk mengurangi jumlahnya. Dikombinasikan dengan mekanisme anti-afinitas yang akan mendistribusikan generator log utama secara merata, ini akan menjadi strategi yang bagus. Sayangnya, mengubah ukuran node melibatkan banyak nuansa dan kompromi yang jauh melampaui kebutuhan sistem logging.
Skala jelas penting juga... Dalam skala kecil, ketidaknyamanan dan kompleksitas tambahan mungkin tidak praktis. Selain itu, biasanya ada masalah yang lebih mendesak. Jika Anda baru saja memulai dan bau "cat baru" belum memudar dari proses rekayasa, Anda dapat membakukan format pencatatan sebelumnya dan memotong biaya dengan menggunakan metode soket tanpa terlalu banyak pengembang.
Bagi mereka yang bekerja dengan proyek skala besar, kesimpulan dari artikel ini tidak tepat, karena perusahaan seperti Google telah melakukan analisis masalah yang jauh lebih menyeluruh dan intensif pengetahuan (dibandingkan dengan saya). Pada skala ini, jelas Anda menerapkan cluster Anda sendiri dan dapat melakukan apa pun yang Anda inginkan dengan pipeline logging (dengan kata lain, manfaatkan kedua pendekatan tersebut).
Sebagai kesimpulan, izinkan saya mengantisipasi beberapa pertanyaan dan menjawabnya sebelumnya. Pertama, “Bukankah artikel tentang fluentd ini benar-benar? Dan apa hubungannya dengan Kubernetes secara umum ? " ... Jawaban untuk kedua sisi pertanyaan ini adalah: "Yah, mungkin ."
- Dalam pengetahuan dan pengalaman umum saya, alat ini adalah kejadian umum saat tailing file di Linux dalam situasi di mana Anda memiliki banyak disk I / O. Saya belum melakukan tes dengan log forwarder lain seperti Logstash , tetapi akan menarik untuk melihat hasilnya.
- Kubernetes, CPU, , . , , . , Kubernetes, tailing' Kubernetes-as-a-Service.
Akhirnya, beberapa kata tentang sumber daya habis pakai lainnya - memori . Awalnya, saya akan memasukkannya ke dalam artikel: dasbor yang disiapkan khusus untuk itu menunjukkan penggunaan memori fluentd. Namun pada akhirnya ternyata faktor ini tidak penting. Menurut hasil pengujian, jumlah maksimum memori yang digunakan tidak melebihi 85 MB, dengan perbedaan antara masing-masing pengujian jarang melebihi 10 MB. Konsumsi memori yang agak rendah ini jelas karena fakta bahwa saya belum menggunakan plugin keluaran yang di- buffer. Lebih penting lagi, ternyata hampir sama untuk kedua metode tersebut. Dan artikel itu sudah menjadi terlalu banyak ...
Perlu dicatat bahwa masih banyak lagi "sudut" yang dapat Anda perhatikan jika Anda ingin melakukan pengujian yang lebih mendalam. Misalnya, Anda dapat mengetahui status prosesor dan panggilan sistem mana yang paling banyak digunakan oleh fluentd, tetapi untuk melakukan ini Anda harus membuat pembungkus yang sesuai untuk itu.
PS dari penerjemah
Baca juga di blog kami: