Sementara bahasa seperti Python dan R menjadi lebih dan lebih populer untuk ilmu data, C dan C ++ bisa menjadi pilihan kuat untuk secara efisien menyelesaikan masalah dalam Ilmu Data. Pada artikel ini, kita akan menggunakan C99 dan C ++ 11 untuk menulis sebuah program yang berfungsi dengan kuartet Anscombe, yang akan saya bahas selanjutnya.
Saya menulis tentang motivasi saya untuk terus belajar bahasa dalam sebuah artikel tentang Python dan GNU Octave yang layak dibaca. Semua program adalah untuk baris perintah, bukan antarmuka pengguna grafis (GUI). Contoh lengkap tersedia di repositori polyglot_fit.
Tantangan pemrograman
Program yang akan Anda tulis dalam seri ini:
- Membaca data dari file CSV
- Interpolasi data dengan garis lurus (mis., F (x) = m ⋅ x + q).
- Menulis hasilnya ke file gambar
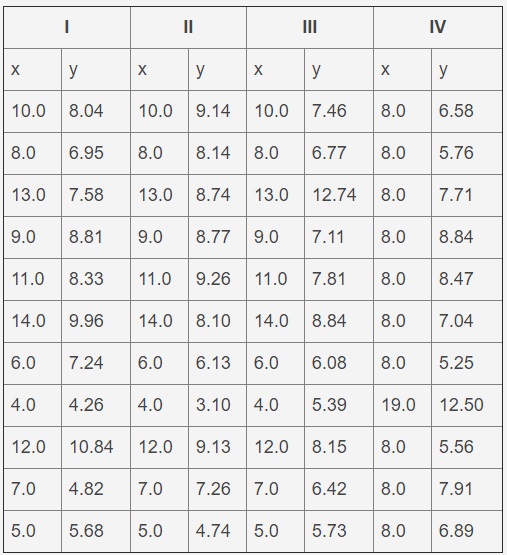
Ini adalah tantangan umum yang dihadapi oleh banyak ilmuwan data. Contoh data adalah set pertama dari kuartet Anscombe, yang disajikan dalam tabel di bawah ini. Ini adalah satu set data yang dibuat secara artifisial yang memberikan hasil yang sama ketika dipasang pada garis lurus, tetapi grafiknya sangat berbeda. File data adalah file teks dengan tab untuk memisahkan kolom dan beberapa baris yang membentuk header. Masalah ini hanya akan menggunakan set pertama (mis. Dua kolom pertama).
Kuartet Anscombe
Solusi dalam C
C adalah bahasa pemrograman tujuan umum yang merupakan salah satu bahasa paling populer yang digunakan saat ini (menurut Indeks TIOBE , Peringkat Bahasa Pemrograman RedMonk , Indeks Popularitas Bahasa Pemrograman , dan penelitian GitHub ). Ini adalah bahasa lama (dibuat sekitar tahun 1973) dan banyak program yang berhasil telah ditulis di dalamnya (misalnya, kernel Linux dan Git). Bahasa ini juga sedekat mungkin dengan cara kerja bagian dalam komputer, karena digunakan untuk manajemen memori langsung. Ini adalah bahasa yang dikompilasi , jadi kode sumber harus diterjemahkan ke dalam kode mesin oleh kompiler . Nyaperpustakaan standar berukuran kecil dan ringan, sehingga perpustakaan lain telah dikembangkan untuk menyediakan fungsionalitas yang hilang.
Ini adalah bahasa yang paling saya gunakan untuk penghancuran angka , terutama karena kinerjanya. Saya merasa cukup membosankan untuk digunakan karena membutuhkan banyak kode boilerplate , tetapi didukung dengan baik di berbagai lingkungan. Standar C99 adalah revisi terbaru yang menambahkan beberapa fitur bagus dan didukung oleh kompiler.
Saya akan membahas prasyarat untuk pemrograman dalam C dan C ++ sehingga pengguna pemula dan berpengalaman dapat menggunakan bahasa ini.
Instalasi
Pengembangan C99 membutuhkan kompiler. Saya biasanya menggunakan Dentang , tetapi GCC , kompilator open source penuh lainnya , akan melakukannya . Agar sesuai dengan data, saya memutuskan untuk menggunakan perpustakaan ilmiah GNU . Untuk merencanakan, saya tidak dapat menemukan perpustakaan yang masuk akal dan karena itu program ini bergantung pada program eksternal: Gnuplot . Contoh ini juga menggunakan struktur data dinamis untuk menyimpan data, yang didefinisikan dalam Berkeley Software Distribution (BSD ).
Instalasi pada Fedora sangat sederhana:
sudo dnf install clang gnuplot gsl gsl-develKomentar Kode
Di C99, komentar diformat dengan menambahkan // ke awal baris, dan sisa baris akan dibuang oleh penerjemah. Apa pun antara / * dan * / juga dibuang.
// .
/* */Perpustakaan yang dibutuhkan
Perpustakaan terdiri dari dua bagian:
- File header berisi deskripsi fungsi
- File sumber yang mengandung definisi fungsi
File header disertakan dalam kode sumber, dan kode sumber perpustakaan terkait dengan yang dapat dieksekusi. Karenanya file header diperlukan untuk contoh ini:
// -
#include <stdio.h>
//
#include <stdlib.h>
//
#include <string.h>
// "" BSD
#include <sys/queue.h>
// GSL
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>Fungsi utama
Di C, program harus berada di dalam fungsi khusus yang disebut main () :
int main(void) {
...
}Di sini Anda dapat melihat perbedaan dari Python, yang telah dibahas dalam tutorial terakhir, karena dalam kasus Python, kode apa pun yang ditemukan dalam file sumber akan dieksekusi.
Mendefinisikan Variabel
Dalam C, variabel harus dideklarasikan sebelum mereka digunakan, dan mereka harus dikaitkan dengan suatu tipe. Kapan pun Anda ingin menggunakan variabel, Anda harus memutuskan data apa yang akan disimpan di dalamnya. Anda juga dapat menunjukkan apakah Anda akan menggunakan variabel sebagai nilai konstan, yang tidak diperlukan, tetapi kompiler dapat mengambil manfaat dari informasi ini. Contoh dari program fitting_C99.c di repositori:
const char *input_file_name = "anscombe.csv";
const char *delimiter = "\t";
const unsigned int skip_header = 3;
const unsigned int column_x = 0;
const unsigned int column_y = 1;
const char *output_file_name = "fit_C99.csv";
const unsigned int N = 100;Array dalam C tidak dinamis dalam arti bahwa panjangnya harus ditentukan terlebih dahulu (mis., Sebelum dikompilasi):
int data_array[1024];Karena Anda biasanya tidak tahu berapa banyak titik data dalam file, gunakan daftar yang terhubung sendiri . Ini adalah struktur data dinamis yang dapat tumbuh tanpa batas. Untungnya BSD menyediakan daftar yang terhubung sendiri . Berikut ini contoh definisi:
struct data_point {
double x;
double y;
SLIST_ENTRY(data_point) entries;
};
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
SLIST_INIT(&head);Contoh ini mendefinisikan daftar data_point , yang terdiri dari nilai terstruktur yang berisi nilai x dan y . Sintaksnya cukup kompleks, tetapi intuitif, dan deskripsi terperinci akan terlalu bertele-tele.
Cetakan
Untuk mencetak ke terminal, Anda dapat menggunakan fungsi printf () , yang berfungsi seperti fungsi printf () dalam Oktaf (dijelaskan dalam artikel pertama):
printf("#### C99 ####\n");Fungsi printf () tidak secara otomatis menambahkan baris baru di akhir baris yang dicetak, jadi Anda perlu menambahkannya sendiri. Argumen pertama adalah string, yang dapat berisi informasi tentang format argumen lain yang dapat diteruskan ke fungsi, misalnya:
printf("Slope: %f\n", slope);Membaca data
Sekarang sampai pada bagian yang rumit ... Ada beberapa perpustakaan untuk mem-parsing file CSV di C, tetapi tidak ada yang terbukti stabil atau cukup populer untuk berada di repositori paket Fedora. Alih-alih menambahkan ketergantungan untuk tutorial ini, saya memutuskan untuk menulis bagian ini sendiri. Sekali lagi, terlalu bertele-tele untuk merinci, jadi saya hanya akan menjelaskan ide umum. Beberapa baris dalam kode sumber akan diabaikan karena singkatnya, tetapi Anda dapat menemukan contoh lengkap dalam repositori.
Pertama buka file input:
FILE* input_file = fopen(input_file_name, "r");Kemudian baca file baris demi baris hingga terjadi kesalahan atau hingga file berakhir:
while (!ferror(input_file) && !feof(input_file)) {
size_t buffer_size = 0;
char *buffer = NULL;
getline(&buffer, &buffer_size, input_file);
...
}Fungsi getline () adalah tambahan yang bagus untuk standar POSIX.1-2008 . Itu dapat membaca seluruh baris dalam file dan mengurus mengalokasikan memori yang diperlukan. Setiap baris kemudian dibagi menjadi token menggunakan fungsi strtok () . Melihat token, pilih kolom yang Anda butuhkan:
char *token = strtok(buffer, delimiter);
while (token != NULL)
{
double value;
sscanf(token, "%lf", &value);
if (column == column_x) {
x = value;
} else if (column == column_y) {
y = value;
}
column += 1;
token = strtok(NULL, delimiter);
}Akhirnya, dengan nilai x dan y dipilih, tambahkan titik baru ke daftar:
struct data_point *datum = malloc(sizeof(struct data_point));
datum->x = x;
datum->y = y;
SLIST_INSERT_HEAD(&head, datum, entries);Fungsi malloc () secara dinamis mengalokasikan (cadangan) sejumlah memori permanen untuk titik baru.
Pas data
Fungsi interpolasi linier GSL, gsl_fit_linear () menerima array reguler sebagai input. Oleh karena itu, karena Anda tidak dapat mengetahui ukuran array yang dibuat sebelumnya, Anda harus mengalokasikan memori secara manual untuk mereka:
const size_t entries_number = row - skip_header - 1;
double *x = malloc(sizeof(double) * entries_number);
double *y = malloc(sizeof(double) * entries_number);Kemudian buka daftar untuk menyimpan data yang relevan dalam array:
SLIST_FOREACH(datum, &head, entries) {
const double current_x = datum->x;
const double current_y = datum->y;
x[i] = current_x;
y[i] = current_y;
i += 1;
}Sekarang setelah Anda selesai dengan daftar, bersihkan pesanan. Selalu bebaskan memori yang dialokasikan secara manual untuk mencegah kebocoran memori . Kebocoran memori buruk, buruk, dan lagi buruk. Setiap kali memori tidak dibebaskan, gnome taman kehilangan kepalanya:
while (!SLIST_EMPTY(&head)) {
struct data_point *datum = SLIST_FIRST(&head);
SLIST_REMOVE_HEAD(&head, entries);
free(datum);
}Akhirnya, akhirnya (!), Anda dapat memuat data Anda:
gsl_fit_linear(x, 1, y, 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);Merencanakan grafik
Program eksternal harus digunakan untuk memplot grafik. Jadi simpan fungsi pemasangan di file eksternal:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
fprintf(output_file, "%f\t%f\n", current_x, current_y);
}Perintah plot Gnuplot terlihat seperti ini:
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'hasil
Sebelum menjalankan program, Anda harus mengompilasinya:
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99Perintah ini memberi tahu kompiler untuk menggunakan standar C99, membaca file fitting_C99.c, memuat pustaka gsl dan gslcblas, dan menyimpan hasilnya ke fitting_C99. Output yang dihasilkan pada baris perintah:
#### C99 ####
: 0.500091
: 3.000091
: 0.816421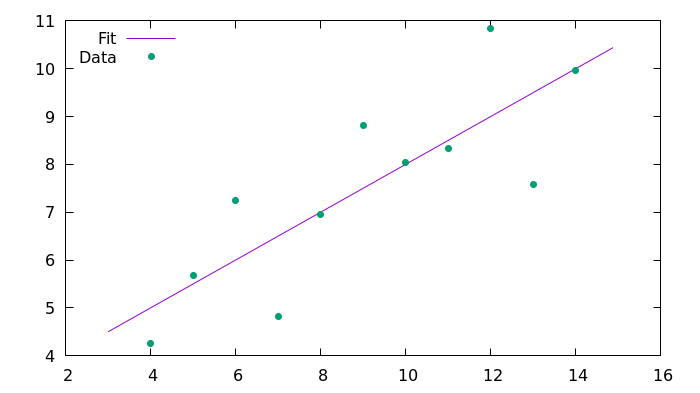
Berikut adalah gambar yang dihasilkan yang dihasilkan menggunakan Gnuplot.
Solusi C ++ 11
C ++ adalah bahasa pemrograman untuk tujuan umum yang juga merupakan salah satu bahasa yang paling populer digunakan saat ini. Itu diciptakan sebagai penerus bahasa C (pada tahun 1983) dengan penekanan pada pemrograman berorientasi objek (OOP). C ++ umumnya dianggap sebagai superset dari C, jadi program C harus dikompilasi dengan kompiler C ++. Ini tidak selalu terjadi, karena ada beberapa kasus tepi di mana mereka berperilaku berbeda. Dalam pengalaman saya, C ++ memerlukan kode boilerplate lebih sedikit daripada C, tetapi sintaksinya lebih kompleks jika Anda ingin mendesain objek. Standar C ++ 11 adalah revisi terbaru yang menambahkan beberapa fitur bagus yang kurang lebih didukung oleh kompiler.
Karena C ++ cukup kompatibel dengan C, saya hanya akan fokus pada perbedaan antara keduanya. Jika saya tidak menjelaskan bagian dalam bagian ini, itu berarti sama dengan C.
Instalasi
Ketergantungan untuk C ++ sama dengan misalnya C. Pada Fedora, jalankan perintah berikut:
sudo dnf install clang gnuplot gsl gsl-develPerpustakaan yang dibutuhkan
Perpustakaan bekerja sama seperti di C, tetapi arahan include sedikit berbeda:
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
extern "C" {
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
}Karena pustaka GSL ditulis dalam C, kompiler perlu diinformasikan tentang fitur ini.
Mendefinisikan Variabel
C ++ mendukung lebih banyak tipe data (kelas) daripada C, misalnya, tipe string, yang memiliki lebih banyak fitur daripada rekan C-nya. Perbarui definisi variabel Anda sesuai:
const std::string input_file_name("anscombe.csv");Untuk objek terstruktur seperti string, Anda dapat mendefinisikan variabel tanpa menggunakan tanda = .
Cetakan
Anda dapat menggunakan fungsi printf () , tetapi lebih umum menggunakan cout . Gunakan operator << untuk menentukan string (atau objek) yang ingin Anda cetak dengan cout :
std::cout << "#### C++11 ####" << std::endl;
...
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;Membaca data
Rangkaiannya sama seperti sebelumnya. File dibuka dan dibaca baris demi baris, tetapi dengan sintaks yang berbeda:
std::ifstream input_file(input_file_name);
while (input_file.good()) {
std::string line;
getline(input_file, line);
...
}Token string diambil dengan fungsi yang sama seperti pada contoh C99. Gunakan dua vektor, bukan array C standar . Vektor adalah ekstensi array C di pustaka standar C ++ untuk mengelola memori secara dinamis tanpa memanggil malloc () :
std::vector<double> x;
std::vector<double> y;
// x y
x.emplace_back(value);
y.emplace_back(value);Pas data
Untuk menyesuaikan data dalam C ++, Anda tidak perlu khawatir tentang daftar, karena vektor dijamin memiliki memori berurutan. Anda dapat langsung meneruskan pointer ke buffer vektor ke fungsi pemasangan:
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;Merencanakan grafik
Plot dilakukan dengan cara yang sama seperti sebelumnya. Menulis ke file:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
output_file << current_x << "\t" << current_y << std::endl;
}
output_file.close();Kemudian gunakan Gnuplot untuk memplot grafik.
hasil
Sebelum menjalankan program, harus dikompilasi dengan perintah serupa:
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11Output yang dihasilkan pada baris perintah:
#### C++11 ####
: 0.500091
: 3.00009
: 0.816421Dan inilah gambar yang dihasilkan, dihasilkan dengan Gnuplot.
Kesimpulan
Artikel ini memberikan contoh pemasangan dan pemipaan data dalam C99 dan C ++ 11. Karena C ++ sebagian besar kompatibel dengan C, artikel ini menggunakan kesamaan untuk menulis contoh kedua. Dalam beberapa aspek, C ++ lebih mudah digunakan, karena sebagian mengurangi beban manajemen memori eksplisit, tetapi sintaksisnya lebih kompleks, karena memperkenalkan kemampuan untuk menulis kelas untuk OOP. Namun, Anda juga dapat menulis dalam C menggunakan teknik OOP, karena OOP adalah gaya pemrograman, ia dapat digunakan dalam bahasa apa pun. Ada beberapa contoh hebat OOP di C, seperti perpustakaan GObject dan Jansson .
Saya lebih suka menggunakan C99 untuk bekerja dengan angka karena sintaksinya yang lebih sederhana dan dukungan yang lebih luas. Sampai saat ini, C ++ 11 tidak didukung secara luas dan saya mencoba untuk menghindari sisi kasar pada versi sebelumnya. Untuk perangkat lunak yang lebih kompleks, C ++ mungkin merupakan pilihan yang baik.
Apakah Anda menggunakan C atau C ++ untuk Ilmu Data? Bagikan pengalaman Anda dalam komentar.

Pelajari detail cara mendapatkan profesi yang dicari dari awal atau Tingkatkan keterampilan dan gaji dengan menyelesaikan kursus online berbayar SkillFactory:
- Kursus Pembelajaran Mesin (12 minggu)
- Belajar Ilmu Data dari awal (12 bulan)
- Profesi analis dengan level awal apa pun (9 bulan)
- Python untuk Kursus Pengembangan Web (9 bulan)