Apa itu ucapan manusia? Ini adalah kata-kata, kombinasi yang memungkinkan Anda untuk mengungkapkan informasi ini atau itu. Muncul pertanyaan, bagaimana kita tahu kapan satu kata berakhir dan yang lain dimulai? Pertanyaannya agak aneh, banyak yang akan berpikir, karena sejak lahir kita mendengar ucapan orang-orang di sekitar kita, kita belajar berbicara, menulis, dan membaca. Akumulasi pengetahuan linguistik, tentu saja, memainkan peran penting, tetapi di samping itu ada jaringan saraf di otak yang membagi aliran bicara menjadi kata-kata komponen dan / atau suku kata. Hari ini kita akan berkenalan dengan sebuah studi di mana para ilmuwan dari University of Geneva (Switzerland) menciptakan model neurocomputer dari decoding ucapan dengan memprediksi kata-kata dan suku kata. Proses otak apa yang menjadi dasar dari model, apa yang dimaksud dengan kata besar "prediksi",dan seberapa efektifkah model yang dibuat? Jawaban atas pertanyaan-pertanyaan ini menunggu kita dalam laporan para ilmuwan. Pergilah.
Dasar penelitian
Bagi kita manusia, ucapan manusia cukup bisa dimengerti dan diartikulasikan (paling sering). Tetapi untuk mobil, ini hanya aliran informasi akustik, sinyal kontinu yang harus diterjemahkan sebelum dipahami.
Otak manusia bertindak dengan cara yang sama, itu terjadi sangat cepat dan tanpa terasa bagi kita. Dasar dari ini dan banyak proses otak lainnya, para ilmuwan mempertimbangkan getaran saraf tertentu, serta kombinasi mereka.
Secara khusus, pengenalan ucapan dikaitkan dengan kombinasi osilasi theta dan gamma, karena memungkinkan hirarki mengoordinasikan pengkodean fonem dalam suku kata tanpa pengetahuan sebelumnya tentang durasi dan asal temporal mereka, yaitu. pemrosesan hulu * secara real time.
* (bottom-up) — , .Pengenalan ucapan alami juga sangat bergantung pada sinyal kontekstual, yang memungkinkan Anda untuk memprediksi konten dan struktur temporal dari sinyal ucapan. Studi sebelumnya telah menunjukkan bahwa mekanisme prediksi memainkan peran penting selama persepsi ucapan terus menerus. Proses ini dikaitkan dengan fluktuasi beta.
Komponen penting lainnya dari pengenalan sinyal wicara dapat disebut prediktif coding, ketika otak secara konstan menghasilkan dan memperbarui model mental lingkungan. Model ini digunakan untuk menghasilkan prediksi sentuh yang dibandingkan dengan input sentuh aktual. Perbandingan sinyal yang diprediksi dan aktual mengarah pada identifikasi kesalahan yang berfungsi untuk memperbarui dan merevisi model mental.
Dengan kata lain, otak selalu mempelajari sesuatu yang baru, terus memperbarui model dunia di sekitarnya. Proses ini dianggap penting dalam pemrosesan sinyal ucapan.
Para ilmuwan mencatat bahwa banyak studi teoretis mendukung baik pendekatan ke atas maupun ke bawah dalam pemrosesan pembicaraan.
Pemrosesan top-down * ( top-down ) - analisis sistem ke dalam komponen-komponennya untuk mendapatkan gambaran tentang subsistem komposisinya menggunakan reverse engineering.Model neurokomputer yang dikembangkan sebelumnya, yang melibatkan koneksi jaringan penghambat / penghambat theta dan gamma yang realistis, dapat melakukan pra-proses bicara sehingga kemudian dapat diterjemahkan dengan benar.
Model lain, yang hanya didasarkan pada kode prediksi, dapat secara akurat mengenali elemen bicara individu (seperti kata-kata atau kalimat lengkap jika dilihat sebagai elemen pidato tunggal).
Karena itu, kedua model bekerja, hanya dalam arah yang berbeda. Satu fokus pada aspek analisis wicara real-time, dan lainnya fokus pada pengenalan segmen bicara yang terisolasi (tidak diperlukan analisis).
Tetapi bagaimana jika kita menggabungkan prinsip-prinsip dasar dari model yang sangat berbeda ini menjadi satu? Menurut penulis penelitian yang kami pertimbangkan, ini akan meningkatkan produktivitas dan meningkatkan realisme biologis dari model pemrosesan tutur saraf komputer.
Dalam karya mereka, para ilmuwan memutuskan untuk menguji apakah sistem pengenalan ucapan berbasis kode prediksi dapat memperoleh manfaat dari proses osilasi saraf.
Mereka mengembangkan model komputer neural Precoss (dari pengkodean prediktif dan osilasi untuk bicara ) berdasarkan pada struktur pengkodean prediktif, yang menambahkan fungsi vibrasi theta dan gamma untuk mengatasi sifat alami dari ucapan alami.
Tujuan khusus dari pekerjaan ini adalah untuk menemukan jawaban atas pertanyaan apakah kombinasi coding prediktif dan osilasi saraf dapat bermanfaat untuk identifikasi operasional komponen suku kata dari kalimat alami. Secara khusus, mekanisme dimana gelombang theta dapat berinteraksi dengan aliran informasi hulu dan hilir dipertimbangkan, dan dampak interaksi ini pada efisiensi proses penguraian suku kata dievaluasi.
Arsitektur Model Precoss
Fungsi penting dari model ini adalah bahwa ia harus dapat menggunakan sinyal / informasi temporal yang ada dalam ucapan berkelanjutan untuk menentukan batas-batas suku kata. Para ilmuwan telah menyarankan bahwa model generatif internal, termasuk prediksi temporal, harus mendapat manfaat dari sinyal tersebut. Untuk menjelaskan hipotesis ini, serta proses berulang yang terjadi selama pengenalan ucapan, model pengkodean prediksi kontinu digunakan.
Model yang dikembangkan dengan jelas memisahkan "apa" dan "kapan". "Apa" - mengacu pada identitas suku kata dan representasi spektralnya (bukan sementara, tetapi urutan vektor spektral); "Kapan" mengacu pada memprediksi waktu dan durasi suku kata.
Akibatnya, prakiraan mengambil dua bentuk: awal suku kata, ditandai oleh modul theta; dan durasi suku kata, ditandai oleh osilasi theta eksogen / endogen, yang menentukan durasi urutan unit yang disinkronkan gamma (diagram di bawah).
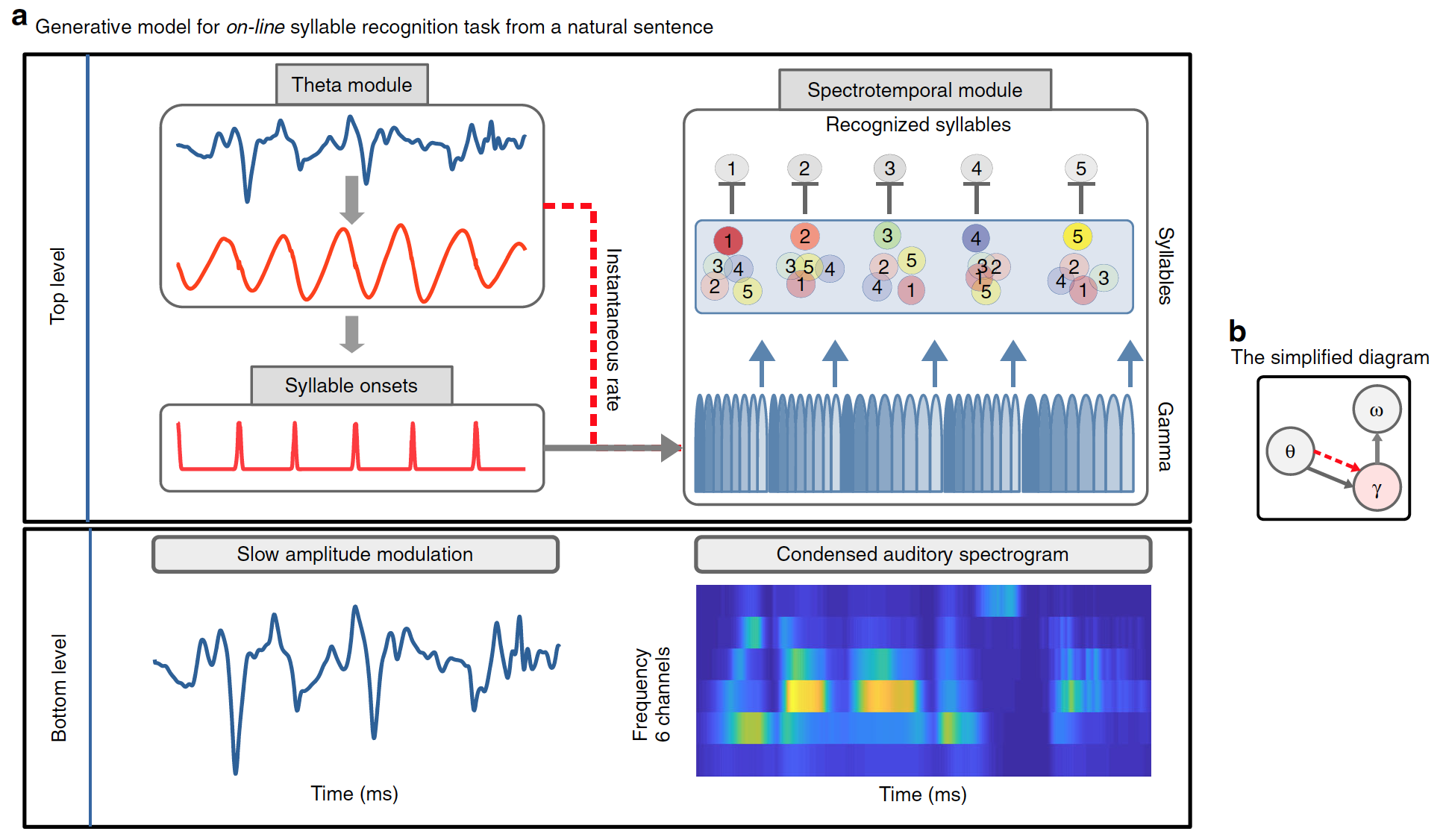
Gambar # 1
Precoss mengekstraksi sinyal sensor dari representasi internal sumbernya dengan merujuk pada model pembangkit. Dalam hal ini, input sensorik berhubungan dengan modulasi amplitudo lambat dari sinyal wicara dan spektrogram pendengaran 6-kanal dari kalimat alami penuh, yang dihasilkan secara internal model dari empat komponen:
- goyangan theta;
- unit modulasi amplitudo lambat dalam modul theta;
- kumpulan unit suku kata (sebanyak suku kata yang ada dalam kalimat pengantar alami, mis. dari 4 hingga 25);
- bank delapan unit gamma dalam modul spektro-temporal.
Bersama-sama, unit suku kata dan bentuk gelombang gamma menghasilkan prediksi top-down tentang spektrogram input. Masing-masing dari delapan unit gamma mewakili fase dalam suku kata; mereka diaktifkan secara berurutan, dan seluruh urutan aktivasi diulang. Oleh karena itu, setiap unit suku kata dikaitkan dengan urutan delapan vektor (satu per unit gamma) dengan masing-masing enam komponen (satu per saluran frekuensi). Spektrogram akustik dari suku kata individu dihasilkan dengan mengaktifkan unit suku kata yang sesuai sepanjang durasi suku kata.
Sementara blok suku kata mengkode pola akustik tertentu, blok gamma untuk sementara menggunakan prediksi spektral yang sesuai untuk durasi suku kata. Informasi tentang panjang suku kata diberikan oleh gelombang theta, karena kecepatan sesaatnya mempengaruhi kecepatan / durasi urutan gamma.
Akhirnya, akumulasi data tentang suku kata yang dimaksudkan harus dihapus sebelum memproses suku kata berikutnya. Untuk melakukan ini, blok gamma (kedelapan) terakhir, yang mengkodekan bagian terakhir dari suku kata, mengatur ulang semua unit suku kata ke tingkat aktivasi rendah secara keseluruhan, yang memungkinkan pengumpulan bukti baru.
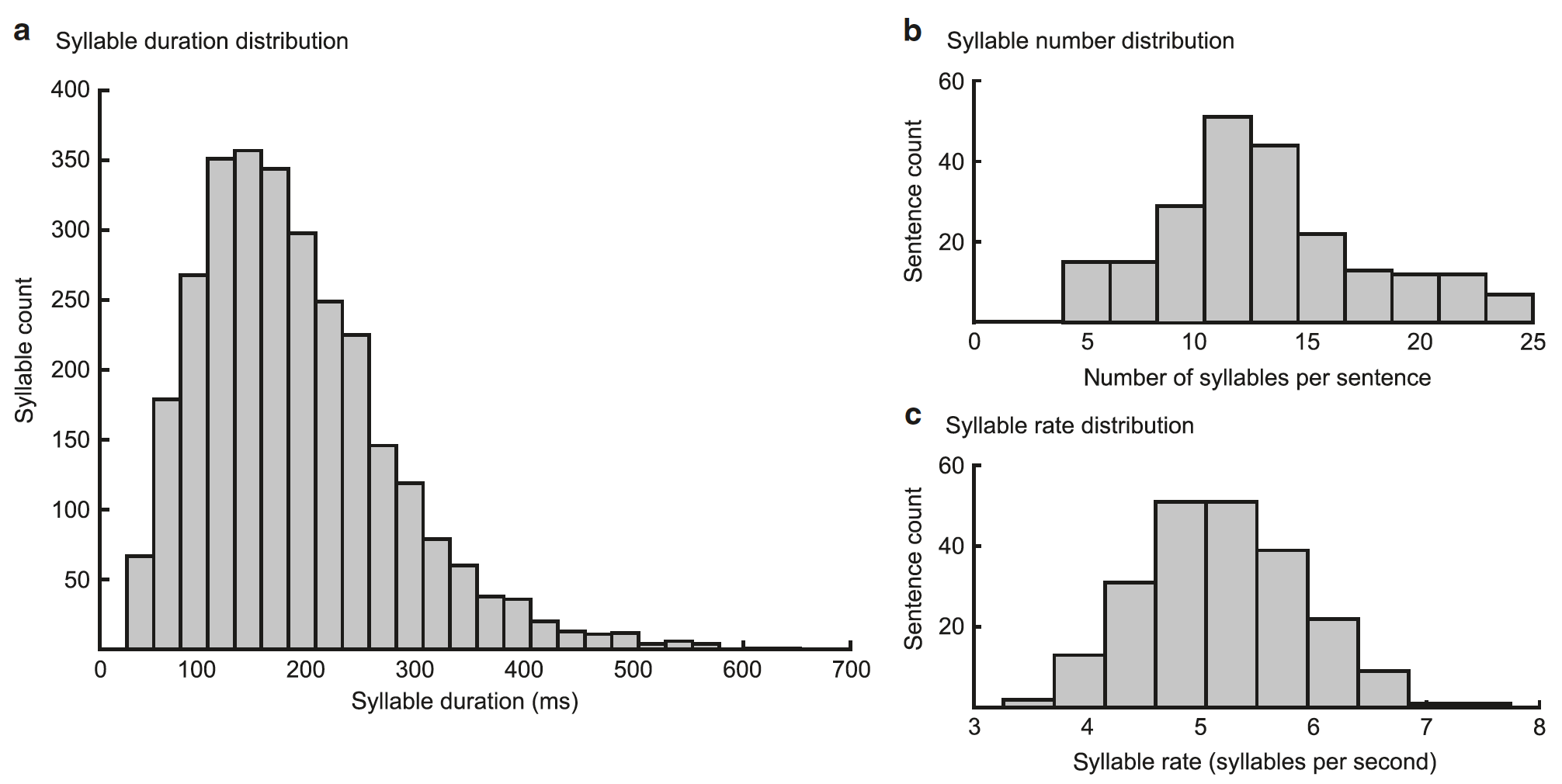
Gambar No. 2
Kinerja model tergantung pada apakah urutan gamma bertepatan dengan awal suku kata dan apakah durasinya cocok dengan durasi suku kata (50-600 ms, rata-rata = 182 ms).
Estimasi model sehubungan dengan urutan suku kata disediakan oleh unit suku kata, yang bersama-sama dengan unit gamma menghasilkan pola spektro temporal yang diharapkan (hasil operasi model), yang dibandingkan dengan spektogram input. Model memperbarui perkiraannya tentang suku kata saat ini untuk meminimalkan perbedaan antara spektogram yang dihasilkan dan aktual. Tingkat aktivitas meningkat dalam unit-unit suku kata, spektogram yang sesuai dengan input sensorik, dan menurun pada yang lain. Dalam kasus yang ideal, meminimalkan kesalahan peramalan real-time menyebabkan peningkatan aktivitas dalam satu unit suku kata terpisah yang sesuai dengan suku kata input.
Hasil simulasi
Model yang disajikan di atas termasuk osilasi theta termotivasi secara fisiologis, yang dikendalikan oleh modulasi amplitudo lambat dari sinyal bicara dan mengirimkan informasi tentang awal dan durasi suku kata ke komponen gamma.
Teta-gamma-link ini memberikan penyelarasan sementara dari prediksi internal yang dihasilkan dengan batas suku kata yang terdeteksi oleh data input (opsi A pada gambar No. 3).
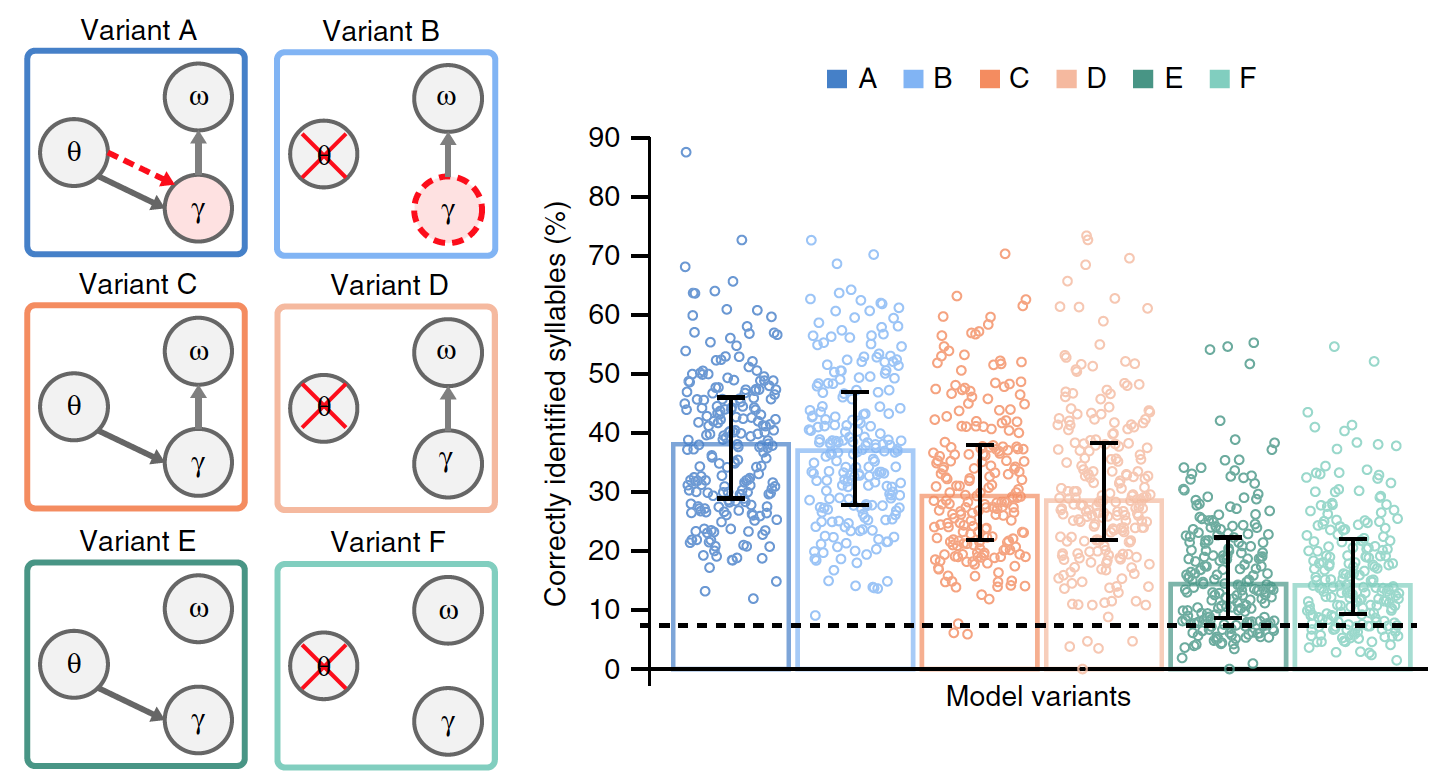
Gambar No. 3
Untuk menilai relevansi sinkronisasi suku kata berdasarkan modulasi amplitudo lambat, perbandingan dibuat model A dengan opsi B, di mana aktivitas theta tidak dimodelkan oleh getaran, tetapi muncul dari pengulangan sendiri dari urutan gamma.
Dalam model B, durasi urutan gamma tidak lagi dikendalikan secara eksogen (karena faktor eksternal) oleh osilasi theta, dan secara endogen (karena faktor internal) ia menggunakan kecepatan gamma yang disukai, yang, ketika urutan diulang, mengarah pada pembentukan ritme theta internal. Seperti halnya osilasi theta, durasi urutan gamma memiliki tingkat yang disukai dalam kisaran theta, yang berpotensi dapat beradaptasi dengan panjang suku kata variabel. Dalam hal ini, adalah mungkin untuk menguji ritme theta yang timbul dari pengulangan urutan gamma.
Untuk lebih akurat mengevaluasi efek spesifik dari gamma theta peracikan dan dumping akumulasi data dalam unit suku kata, versi tambahan dari model A dan B sebelumnya dibuat.
Opsi C dan D tidak memiliki laju gamma pilihan. Varian E dan F juga berbeda dari varian C dan D dengan tidak adanya pengaturan ulang data suku kata yang terakumulasi.
Dari semua varian model, hanya A yang memiliki hubungan theta-gamma sejati, di mana aktivitas gamma ditentukan oleh modul theta, sedangkan dalam model B laju gamma diatur secara endogen.
Penting untuk menentukan varian model mana yang paling efektif, yang hasilnya dibandingkan dengan kehadiran data input umum (kalimat alami). Grafik pada gambar di atas menunjukkan kinerja rata-rata dari masing-masing model.
Ada perbedaan yang signifikan antara opsi. Dibandingkan dengan model A dan B, kinerja secara signifikan lebih rendah pada model E dan F (rata-rata 23%) dan C dan D (15%). Ini menunjukkan bahwa menghapus data yang terakumulasi tentang suku kata sebelumnya sebelum memproses suku kata baru merupakan faktor penting dalam pengkodean aliran suku kata dalam ucapan alami.
Perbandingan opsi A dan B dengan opsi C dan D menunjukkan bahwa hubungan theta-gamma, baik itu stimulus (A) atau endogen (B), secara signifikan meningkatkan kinerja model (rata-rata sebesar 8,6%).
Secara umum, percobaan dengan varian model yang berbeda menunjukkan bahwa itu bekerja paling baik ketika unit suku kata direset setelah setiap urutan unit gamma (berdasarkan informasi internal tentang struktur spektral suku kata), dan ketika laju radiasi gamma ditentukan oleh penggabungan theta-gamma.
Kinerja model dengan kalimat alami, oleh karena itu, tidak tergantung pada pensinyalan yang tepat dari permulaan suku kata oleh osilasi theta yang digerakkan oleh stimulus, atau pada mekanisme yang tepat dari hubungan theta-gamma.
Seperti yang diakui para ilmuwan sendiri, ini adalah penemuan yang agak mengejutkan. Di sisi lain, tidak adanya perbedaan kinerja antara stimulus yang digerakkan oleh stimulus dan penghubungan theta-gamma endogen mencerminkan fakta bahwa durasi suku kata dalam ucapan alami sangat dekat dengan harapan model, dalam hal ini tidak akan ada keuntungan bagi sinyal theta yang didorong langsung oleh data input.
Untuk lebih memahami pergantian peristiwa yang tidak terduga, para ilmuwan melakukan serangkaian percobaan lain, tetapi dengan sinyal ucapan terkompresi (x2 dan x3). Seperti yang ditunjukkan oleh studi perilaku, pemahaman wicara yang dikompresi x2 tidak secara praktis berubah, tetapi menurun secara dramatis ketika dikompresi sebanyak 3 kali.
Dalam hal ini, tautan theta-gamma yang dirangsang dapat sangat berguna untuk mengurai dan mendekode suku kata. Hasil simulasi disajikan di bawah ini.

Gambar # 4
Seperti yang diharapkan, kinerja keseluruhan turun saat rasio kompresi meningkat. Untuk mengkompres x2, masih belum ada perbedaan yang signifikan antara stimulus dan hubungan theta-gamma endogen. Tetapi dalam kasus kompresi x3, ada perbedaan yang signifikan. Ini menunjukkan bahwa osilasi theta yang digerakkan oleh stimulus yang menggerakkan tautan theta-gamma lebih bermanfaat untuk pengkodean suku kata daripada tingkat theta yang ditetapkan secara endogen.
Oleh karena itu ucapan alami dapat diproses menggunakan generator theta endogen yang relatif tetap. Tetapi untuk sinyal-sinyal ucapan input yang lebih kompleks (mis., Ketika laju bicara terus berubah), generator theta yang terkontrol diperlukan, yang menyediakan informasi pengaturan waktu yang akurat kepada gamma encoder tentang suku kata (permulaan suku kata dan durasi suku kata).
Kemampuan model untuk secara akurat mengenali suku kata dalam kalimat input tidak memperhitungkan kompleksitas variabel dari berbagai model yang dibandingkan. Oleh karena itu, Kriteria Informasi Bayesian (BIC) dievaluasi untuk setiap model. Kriteria ini menghitung trade-off antara akurasi dan kompleksitas model (gambar # 5).
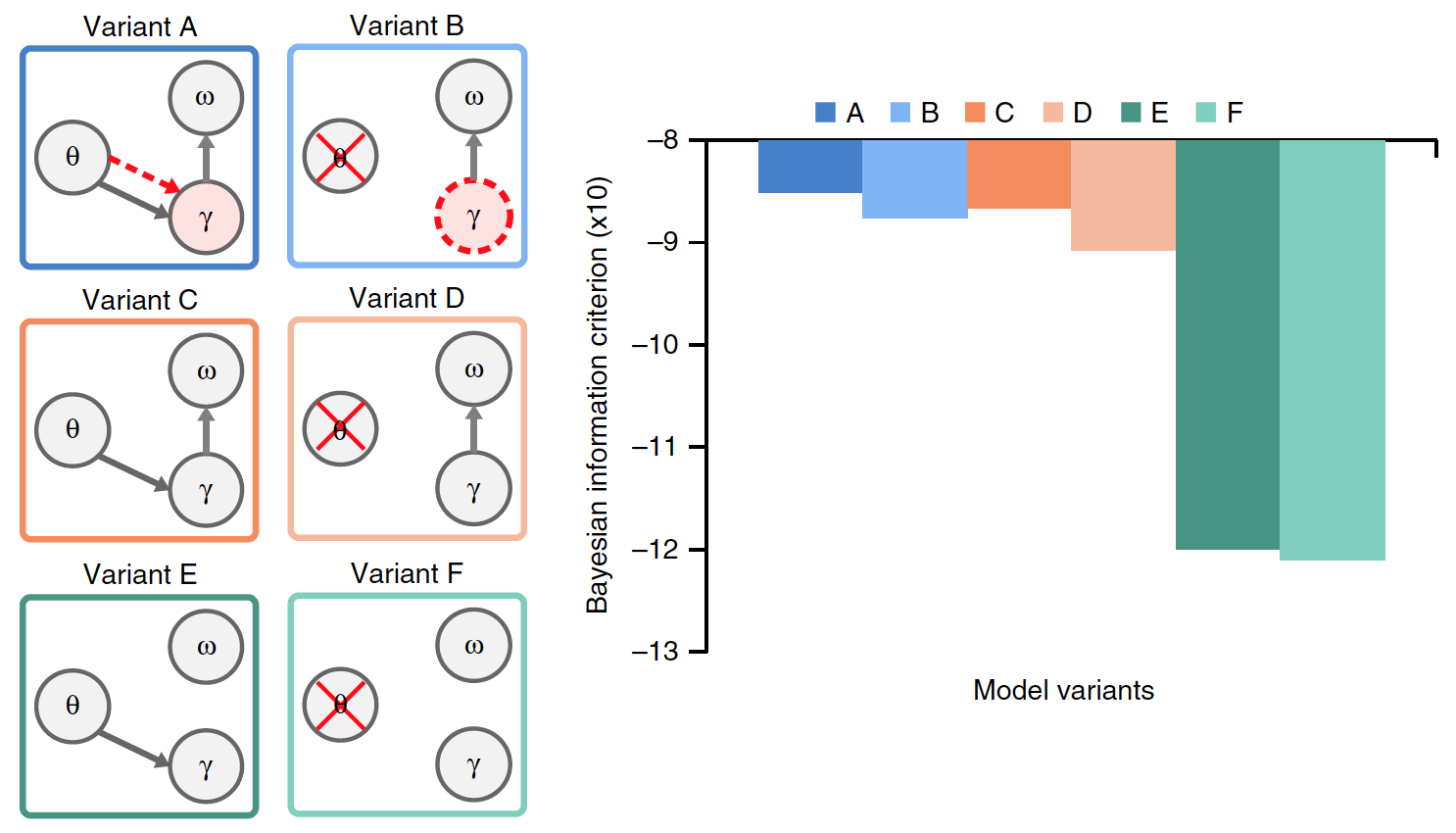
Gambar # 5
Opsi A menunjukkan nilai BIC tertinggi. Perbandingan model A dan B sebelumnya tidak dapat secara akurat membedakan kinerja mereka. Namun, berkat kriteria BIC, menjadi jelas bahwa opsi A memberikan pengakuan suku kata yang lebih percaya diri daripada model tanpa osilasi theta didorong oleh stimulus (model B).
Untuk seorang kenalan yang lebih mendetail dengan nuansa penelitian, saya sarankan untuk melihat laporan para ilmuwan danbahan tambahan untuk itu.
Epilog
Meringkas hasil di atas, kita dapat mengatakan bahwa keberhasilan model tergantung pada dua faktor utama. Yang pertama dan paling penting adalah pengaturan ulang dari data yang terakumulasi berdasarkan informasi model tentang isi suku kata (dalam hal ini, itu adalah struktur spektralnya). Faktor kedua adalah hubungan antara proses theta dan gamma, yang memastikan bahwa aktivitas gamma termasuk dalam siklus theta sesuai dengan durasi suku kata yang diharapkan.
Pada intinya, model yang dikembangkan meniru fungsi otak manusia. Suara yang masuk sistem dimodulasi oleh gelombang theta yang menyerupai aktivitas neuron. Ini memungkinkan Anda untuk menentukan batas suku kata. Selanjutnya, gelombang gamma yang lebih cepat membantu menyandikan suku kata. Dalam prosesnya, sistem menawarkan suku kata yang mungkin dan menyesuaikan pilihan jika perlu. Melompat di antara level pertama dan kedua (theta dan gamma), sistem menemukan versi suku kata yang benar, dan kemudian diatur ulang ke nol untuk memulai proses lagi untuk suku kata berikutnya.
Selama tes praktis, adalah mungkin untuk berhasil menguraikan 2888 suku kata (220 kalimat pidato alami, bahasa Inggris digunakan).
Studi ini tidak hanya menggabungkan dua teori yang berlawanan, mempraktikkannya sebagai satu sistem, tetapi juga memungkinkan untuk lebih memahami bagaimana otak kita memahami sinyal ucapan. Tampaknya bagi kita bahwa kita memahami ucapan "sebagaimana adanya", yaitu. tanpa proses tambahan yang rumit. Namun, mengingat hasil simulasi, ternyata osilasi theta dan gamma saraf memungkinkan otak kita membuat prediksi kecil tentang suku kata mana yang kita dengar, berdasarkan persepsi ujaran yang terbentuk.
Siapa pun yang mengatakan sesuatu, tetapi otak manusia kadang-kadang tampak jauh lebih misterius dan tidak dapat dipahami daripada sudut-sudut Alam Semesta yang tidak dijelajahi atau kedalaman Samudra Dunia yang tanpa harapan.
Terima kasih atas perhatian Anda, tetap ingin tahu dan selamat bekerja, kawan. :)
Sedikit iklan
Terima kasih untuk tetap bersama kami. Apakah Anda suka artikel kami? Ingin melihat konten yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikan kepada teman-teman, cloud VPS untuk pengembang mulai $ 4,99 , analog unik dari server entry-level yang kami buat untuk Anda: Seluruh Kebenaran Tentang VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps mulai dari $ 19 atau cara membagi server dengan benar? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
Dell R730xd 2x lebih murah di pusat data Equinix Tier IV di Amsterdam? Hanya kami yang memiliki 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV dari $ 199 di Belanda!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - mulai dari $ 99! Baca tentang Cara Membangun Infrastruktur Bldg. kelas dengan penggunaan server Dell R730xd E5-2650 v4 seharga € 9000 untuk satu sen?