
Kesalahan sistematis tidak asing dengan histogram. Faktanya adalah bahwa mereka agak sewenang-wenang dan dapat menyebabkan kesimpulan yang salah tentang data. Jika Anda ingin memvisualisasikan variabel, sebaiknya pilih grafik yang berbeda.
Baik Anda sedang rapat dengan manajemen senior atau ilmuwan data, satu hal yang dapat Anda yakini adalah bahwa diagram batang akan muncul di beberapa titik.
. : . , , ? .
— !
6 , , , :
.
.
.
.
.
, .
«, : . ?» !
, CDP, .
, ?
1. .
![Bagaimana histogram berubah ketika jumlah nampan berubah. [Gambar penulis]](https://habrastorage.org/getpro/habr/upload_files/7f1/71f/f40/7f171ff405334ac351d813ecfe7ca455.png "Bagaimana histogram berubah ketika jumlah nampan berubah. [Gambar penulis]")
( Python R), (). , . .
2. .
, , . , , . , .
, , .
![Bagaimana histogram berubah ketika nilai maksimum berubah. [Gambar penulis]](https://habrastorage.org/getpro/habr/upload_files/29c/73d/22f/29c73d22f14a324968ab201e3bea41cc.png "Bagaimana histogram berubah ketika nilai maksimum berubah. [Gambar penulis]")
, . , : !
3. .
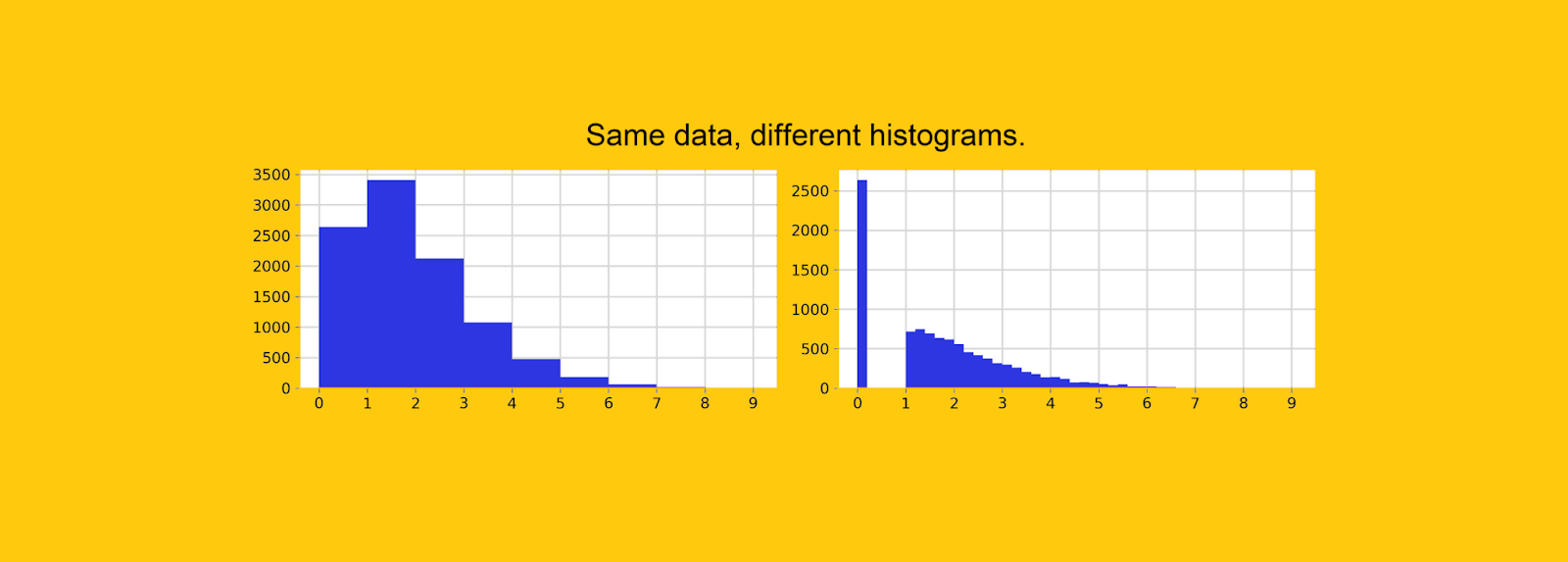
, , . , , «» .
, 0. , 10 , 26% — .
![Data yang sama, lebar bin berbeda. Tidak mungkin menemukan konsentrasi nol yang tinggi pada grafik kiri. [Gambar penulis]](https://habrastorage.org/getpro/habr/upload_files/568/6cc/b23/5686ccb23bbd5f013cc5f50f419bb43b.png "Data yang sama, lebar bin berbeda. Tidak mungkin menemukan konsentrasi nol yang tinggi pada grafik kiri. [Gambar penulis]")
— , Python. , , , «» .
. , , , 0 - .
4. .
, . .
«» (Age). = 49 ( ) = 49,828884325804246 ( , 365,25). — , — .
![Di sebelah kiri adalah variabel kontinu. Di sebelah kanan adalah variabel diskrit. Namun, mereka terlihat sama di plot teratas. [Gambar penulis]](https://habrastorage.org/getpro/habr/upload_files/9b4/66d/054/9b466d0547e9bbd529cab99fd58aba6f.png "Di sebelah kiri adalah variabel kontinu. Di sebelah kanan adalah variabel diskrit. Namun, mereka terlihat sama di plot teratas. [Gambar penulis]")
, , , , , . ( Python) : .
5. .
. , UCI , , :
( )
50
50
60
60 .
:
![Perbandingan histogram. [Gambar penulis]](https://habrastorage.org/getpro/habr/upload_files/460/df1/ed4/460df1ed42f1a890f7b732953586512b.png "Perbandingan histogram. [Gambar penulis]")
, , , , .
6. , .
Excel, R Python, : Excel , R — hist(x), Python — plt.hist().
, . , , ? , , , , . :
| INTERVAL_LEFT | INTERVAL_RIGHT | COUNT |
|---------------|----------------|---------------|
| 75.0 | 87.0 | 31 |
| 87.0 | 99.0 | 52 |
| 99.0 | 111.0 | 76 |
| ... | ... | ... |
SQL- , . , Google Big Query :
WITH
STATS AS (
SELECT
COUNT(*) AS N,
APPROX_QUANTILES(VARIABLE_NAME, 4) AS QUARTILES
FROM
TABLE_NAME
),
BIN_WIDTH AS (
SELECT
-- freedman-diaconis formula for calculating the bin width
(QUARTILES[OFFSET(4)] — QUARTILES[OFFSET(0)]) / ROUND((QUARTILES[OFFSET(4)] — QUARTILES[OFFSET(0)]) / (2 * (QUARTILES[OFFSET(3)] — QUARTILES[OFFSET(1)]) / POW(N, 1/3)) + .5) AS FD
FROM
STATS
),
HIST AS (
SELECT
FLOOR((TABLE_NAME.VARIABLE_NAME — STATS.QUARTILES[OFFSET(0)]) / BIN_WIDTH.FD) AS INTERVAL_ID,
COUNT(*) AS COUNT
FROM
TABLE_NAME,
STATS,
BIN_WIDTH
GROUP BY
1
)
SELECT
STATS.QUARTILES[OFFSET(0)] + BIN_WIDTH.FD * HIST.INTERVAL_ID AS INTERVAL_LEFT,
STATS.QUARTILES[OFFSET(0)] + BIN_WIDTH.FD * (HIST.INTERVAL_ID + 1) AS INTERVAL_RIGHT,
HIST.COUNT
FROM
HIST,
STATS,
BIN_WIDTH
, ?
: .
6 , , : « ?» : , « » (Cumulative Distribution Plot - CDP). , , , .
— . , CDP :
x: ( );
y: .
— .
![Grafik distribusi kumulatif detak jantung maksimum. [Gambar penulis]](https://habrastorage.org/getpro/habr/upload_files/5be/acf/f95/5beacff9594412dff001cd02e1ea2e82.png "Grafik distribusi kumulatif detak jantung maksimum. [Gambar penulis]")
x = 140 y = 90 (30%). : 140 . , 140 ( 90 , 30% ). , 30% 140 .
, , « » ? «»? . , ( , ). , CDP , , .
CDP . , , « 140 160?» « 180?». CDP, . .
CDP , . , :
1. . , CDP.
2. . CDP, .
3. . - , , , .
4. . (.. ), , .
5. . , , . , y 0 100%, . , , :
![Perbandingan distribusi dalam CDP. [Gambar penulis]](https://habrastorage.org/getpro/habr/upload_files/c14/de3/22d/c14de322da1e53ae4455357e8da017b5.png "Perbandingan distribusi dalam CDP. [Gambar penulis]")
6. , . , , , SQL:
SELECT
COUNT(*) AS N,
APPROX_QUANTILES(VARIABLE_NAME, 100) AS PERCENTILES
FROM
TABLE_NAME
Excel, R, Python
Excel . 101 , 0 1. , : =PERCENTILE(DATA, FRAC), DATA - , , FRAC - : 0,00, 0,01, 0,02, 0,03,…, 0,98, 0,99, 1. , x.
R :
plot(ecdf(data))
Python:
from statsmodels.distributions.empirical_distribution import ECDF import matplotlib.pyplot as plt ecdf = ECDF(data) plt.plot(ecdf.x, ecdf.y)
! , .
. , Linkedin.
- "Machine Learning. Basic". , .
- - " "