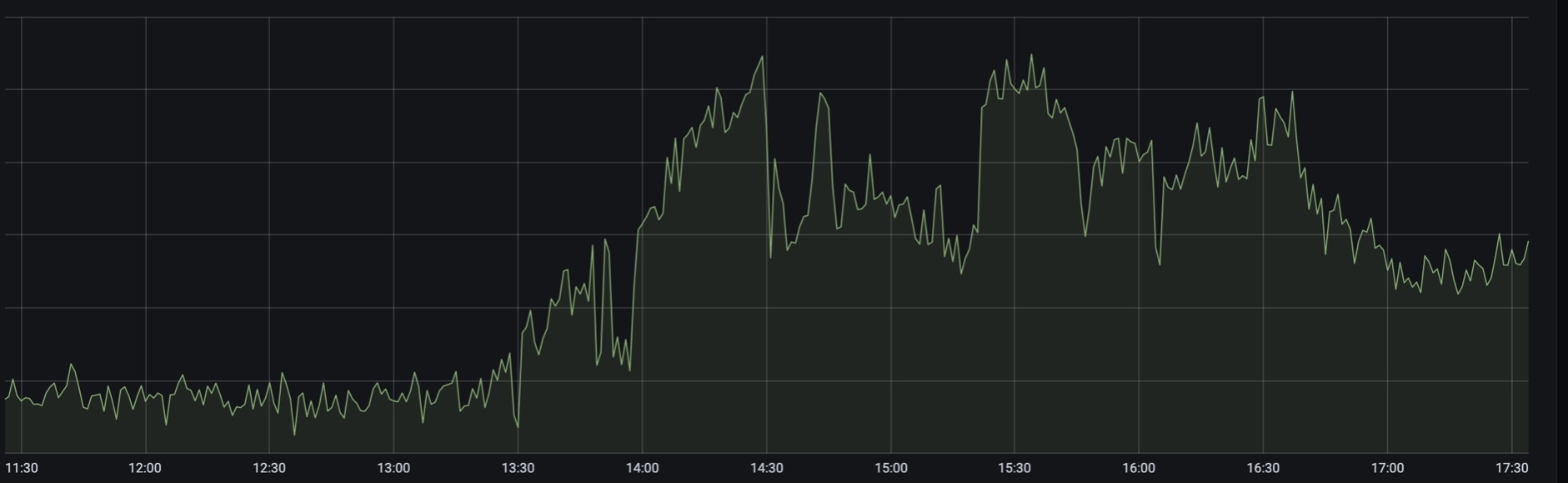
Sekitar pukul 1:30, beban pencarian penerbangan dan tiket kereta api meningkat tajam. Di suatu tempat pada saat ini, Kereta Api Rusia melaporkan gangguan ke situs web dan aplikasi, dan kami mulai segera menuangkan contoh backend tambahan di semua pusat data.
Tapi nyatanya, masalah dimulai lebih awal. Sekitar jam 8 pagi, pemantauan mengirimkan peringatan tentang fakta bahwa di salah satu replika database kami memiliki banyak proses berumur panjang yang mencurigakan. Tapi kami melewatkannya, menganggapnya tidak terlalu penting.
Pengantar
Infrastruktur kami telah tumbuh secara signifikan selama hampir dua puluh tahun pembangunan. Aplikasi ada di tiga platform - kode php lama dalam monolit , versi pertama layanan mikro ada di platform dengan orkestrasi buatan sendiri, yang kedua, benar secara strategis, OKD, tempat layanan go, php dan nodejs aktif. Di sekitar semua ini, lusinan basis mysql dengan pengikat untuk HA - "karangan bunga" utama yang melayani monolit, dan banyak pasangan master-hotstandby untuk layanan mikro. Selain itu, memkesh, kafka, mongas, lobak, elastis, juga jauh dari satu salinan. Nginx dan envoy sebagai frontproxy . Semuanya hidup di tiga lokasi jaringan dan kami melanjutkan dari asumsi bahwa kehilangan salah satu dari mereka tidak memengaruhi pengguna.
-: mysql
Kami memiliki tiga produk yang dimuat. Jadwal kereta api, di mana ada banyak lalu lintas input. Jadwal kereta api untuk kereta jarak jauh dan pembelian serta pemesanan tiket kereta api - ada banyak lalu lintas dan pencarian lebih sulit. Penerbangan dengan pencarian yang sangat sulit, cache multi-tahap, banyak pilihan karena transfer dan garpu "plus atau minus 3 hari". Dahulu kala, ketiga produk hanya hidup dalam satu monolit, lalu kami mulai perlahan-lahan memindahkan masing-masing bagian ke layanan mikro. Yang pertama dibongkar adalah kereta listrik, dan, terlepas dari kenyataan bahwa biasanya puncak di bulan Mei jatuh di atasnya, arsitektur baru ini sangat nyaman dan mudah disesuaikan dengan pertumbuhan beban. Dalam kasus penerbangan, sebagian besar monolit telah dicuri, dan tepat pada saat hari P, pengujian A / B dari geografi sagest telah berlangsung selama seminggu. Kami membandingkan dua versi penerapan - yang baru,di elasticsearch, dan mysql lama. Pada saat peluncurannya, pada 15 April, mereka telah menemukan banyak masalah, tetapi kemudian mereka dengan cepat memahami, memperbaiki kodenya dan memutuskan bahwa itu tidak akan menyala lagi.
Tembakan. Perlu dicatat bahwa versi lama adalah implementasi sendiri dari pencarian teks lengkap dan peringkat di mysql. Bukan solusi terbaik, tetapi telah teruji waktu dan sebagian besar berfungsi. Masalah dimulai ketika salah satu tabel sangat terfragmentasi, kemudian semua kueri dengan partisipasinya mulai melambat dan memuat banyak sistem. Dan, jelas, pada jam 8 pagi kami melewati ambang fragmentasi ini, yang dilaporkan oleh peringatan. Reaksi standar untuk situasi yang jarang terjadi, tetapi masih diharapkan adalah mengambil replika tumpul dari beban (dengan lapisan proxy kami dari proxysql, ini mudah dilakukan), lalu jalankan optimalkan + analisis dan kemudian kembalikan kembali. Mempertimbangkan cadangan daya selama waktu normal di bawah beban normal, hal ini tidak menimbulkan masalah. Tetapi di sini, dalam waktu tenang, kami tidak memproses peringatan ini.
13:20
Sekitar waktu ini, berita tentang liburan Mei dan hari non-kerja terdengar.
Lalu lintas padat sekitar pukul 13:30
Seperti yang kami ketahui kemudian, hanya beberapa menit setelah pengumuman akhir pekan tambahan (yang bukan akhir pekan, tetapi “akhir pekan”), lalu lintas mulai meningkat. Muatannya tiba-tiba saja. Pada puncaknya 2,5 - 3 kali dari normal, dan ini berlanjut selama beberapa jam.
Kami segera dibombardir dengan "peringatan darurat" - peringatan tingkat kekritisan "bangun dan perbaiki". Pertama-tama, itu adalah peringatan tentang pertumbuhan 50 * kesalahan yang kami kirim ke klien dari proxy depan kami. Pada tingkat di bawah ini, peringatan untuk kesalahan koneksi database dipicu dan di log kami melihat sesuatu seperti ini: "DB: Max connect timeout tercapai saat mencapai hostgroup 102 setelah 3162ms". Ditambah peringatan tentang kurangnya kapasitas pada tiga grup server aplikasi dari platform monolitik lama. Waspadai badai dalam bentuknya yang paling murni.
Ide alasan datang hampir seketika, bahkan sebelum memasuki jadwal dengan permintaan yang masuk - berita tentang "liburan" sudah muncul di korespondensi internal di obrolan.
Setelah sedikit sadar dalam situasi Achtung yang hampir sempurna, mereka mulai bereaksi. Skala server aplikasi, menangani kesalahan pada antarmuka antara aplikasi dan basis. Kami dengan cepat mengingat peringatan yang telah "menyala" di pagi hari dan menemukan kenalan lama kami dari pelana geografi dalam daftar proses dari ucapan yang sakit itu. Kami menghubungi tim avia, dan mereka mengonfirmasi bahwa pertumbuhan lalu lintas pada hari-hari terakhir bulan April, yang bahkan belum mendekati selama 15 tahun terakhir, adalah nyata. Dan ini bukan serangan, bukan semacam masalah keseimbangan, tapi pengguna langsung alami. Dan di bawah permintaan mereka yang hidup, replika kami yang sudah kelebihan beban menjadi benar-benar tidak sehat.
Alexey, DBA kami, mengeluarkan replika dari beban, menyelesaikan proses yang tahan lama, dan mengikuti prosedur pengoptimalan tabel standar. Ini semua cepat, beberapa menit, tetapi selama waktu ini, di bawah lalu lintas seperti itu, replika yang tersisa menjadi lebih buruk. Kami memahami ini, tetapi kami memilihnya sebagai kejahatan terkecil.
Hampir secara paralel, sekitar pukul 13:40, server aplikasi baru mulai mengalir, menyadari bahwa beban ini bukanlah sesuatu yang tidak akan hilang dengan cepat dengan sendirinya, melainkan dapat tumbuh, dan proses itu sendiri untuk bagian monolitik tidak sangat cepat.
Manipulasi dasar membantu untuk sementara waktu. Dari sekitar pukul 13.50 hingga 14.30, semuanya tenang.
Puncak kedua - sekitar 14:30
Pada saat itu, pemantauan memberi tahu kami bahwa situs web Kereta Api Rusia sedang tidak aktif. Sebenarnya, dia mengatakan bahwa bagian belakang kereta semakin buruk, dan kami mengetahui tentang Kereta Api Rusia nanti, saat berita itu keluar . Secara realtime terlihat seperti ini bagi kami.

Muatan tersebut tampaknya terkait dengan gangguan di situs web Kereta Api Rusia
. Sayangnya, sebagian besar kereta masih hidup dalam monolit dan hanya dapat diskalakan di tingkat aplikasi dengan menambahkan backend baru. Dan ini, seperti yang saya tulis di atas, adalah prosedur yang lambat dan sulit untuk dipercepat. Oleh karena itu, yang tersisa hanyalah menunggu sampai otomatisasi sudah mulai bekerja. Di layanan mikro, semuanya jauh lebih sederhana, tentu saja, tetapi bergerak sendiri ... meskipun itu cerita yang berbeda.
Penantian itu tidak membosankan. Dalam waktu sekitar 5 menit, kemacetan sistem di beberapa cara masih belum sepenuhnya jelas "didorong" dari lapisan aplikasi ke lapisan database, baik ke basis itu sendiri, atau ke proxysql. Dan pada 14:40, kami benar-benar berhenti menulis ke cluster mysql utama. Apa yang sebenarnya terjadi di sana, kami belum menemukan jawabannya, tetapi mengubah master menjadi cadangan siaga membantu. Dan setelah 10 menit kami mengembalikan rekor itu. Sekitar waktu yang sama, mereka memutuskan untuk memindahkan secara paksa seluruh beban dari sadget ke elastis, mengorbankan hasil kampanye AB. Betapa banyak membantu, mereka juga tidak menyadarinya, tetapi itu pasti tidak bertambah buruk.
15:00
Rekaman menjadi hidup, tampaknya semuanya harus baik-baik saja, dan beban pada replika dan proxysql di depannya normal. Tetapi untuk beberapa alasan, kesalahan selama permintaan baca dari aplikasi ke database tidak berakhir. Dalam waktu sekitar 15-20 menit menempel grafik pada lapisan yang berbeda dan mencari setidaknya beberapa pola, kami menyadari bahwa kesalahan hanya berasal dari satu proxysql. Mulai ulang dan kesalahan hilang. Akar penyebabnya digali lama kemudian, dengan analisis rinci tentang kegagalan tersebut. Ternyata selama keadaan darurat terakhir, seminggu sebelumnya, selama dimulainya kampanye AB tentang sagest, proxysql tidak menutup koneksi dengan benar ke salah satu replika karangan bunga, yang kemudian dimanipulasi. Dan pada contoh proxysql ini, kami dengan bodohnya mengalami kekurangan port untuk lalu lintas keluar. Metrik ini, tentu saja, akan melakukannya, tetapi tidak pernah terpikir oleh kami untuk menutup lansirannya. Sekarang sudah ada.
15:20
Semua produk dipulihkan, kecuali kereta api.
15:50
Bagian belakang kereta terakhir diperpanjang. Biasanya tidak butuh dua jam, tapi satu jam, tapi di sini mereka sendiri sedikit kacau dalam situasi stres.
Seperti yang sering terjadi, itu diperbaiki di satu tempat, rusak di tempat lain. Backend mulai menerima lebih banyak koneksi, front-proxy mulai mengurangi permintaan klien karena overflow upstream, sebagai hasilnya, traffic antar-layanan internal meningkat. Dan ada layanan otorisasi. Ini adalah layanan mikro, tetapi tidak di OKD, tetapi pada platform lama. Ada penskalaan yang lebih sederhana daripada di monolit, tetapi lebih buruk daripada di OKD. Kami mengangkatnya selama sekitar 15 menit, memutar parameter beberapa kali dan menambah kapasitas, tetapi pada akhirnya juga berhasil.
16:10
Hore, semuanya bekerja, Anda bisa pergi makan siang.
Gambar yang cantik
Mereka cantik karena tidak sepenuhnya informatif, tetapi porosnya belum diuji oleh Dewan Keamanan.
Grafik tahun 500-an:

Gambaran umum beban selama 2 hari:
Kesimpulan dari kapten
- Terima kasih untuk tidak malam ini.
- Anda perlu melakukan sesuatu tentang peringatan. Jumlahnya sudah banyak, tapi di satu sisi kadang masih kurang, dan di sisi lain ada yang ludes, termasuk karena kuantitasnya. Dan biaya dukungan meningkat dengan setiap peringatan baru. Secara umum masih ada pemahaman tentang masalah tersebut, namun belum ada solusi strategisnya. Itu bersembunyi di suatu tempat di persimpangan proses dan alat, yang kita cari. Tapi kami telah menangani beberapa peringatan secara taktis.
- . , - proxysql , . , .
- , OKD . .
- . , , , .