Untuk meningkatkan kinerja aplikasi web, gunakan WebAssembly bersama dengan AssemblyScript untuk menulis ulang komponen JavaScript yang penting bagi kinerja dari aplikasi web. “Dan apakah itu benar-benar membantu?” Anda bertanya.
Sayangnya, tidak ada jawaban yang jelas untuk pertanyaan ini. Itu semua tergantung bagaimana Anda menggunakannya. Ada banyak pilihan: dalam beberapa kasus jawabannya negatif, dalam kasus lain positif. Dalam satu situasi, lebih baik memilih JavaScript daripada AssemblyScript, dan di situasi lain, sebaliknya. Ini dipengaruhi oleh banyak kondisi yang berbeda.
Pada artikel ini, kami akan menganalisis kondisi ini, mengusulkan sejumlah solusi, dan mengujinya pada beberapa contoh kode pengujian.
Siapa saya dan mengapa saya melakukan topik ini?
(Anda dapat melewati bagian ini, tidak penting untuk memahami materi lebih lanjut).
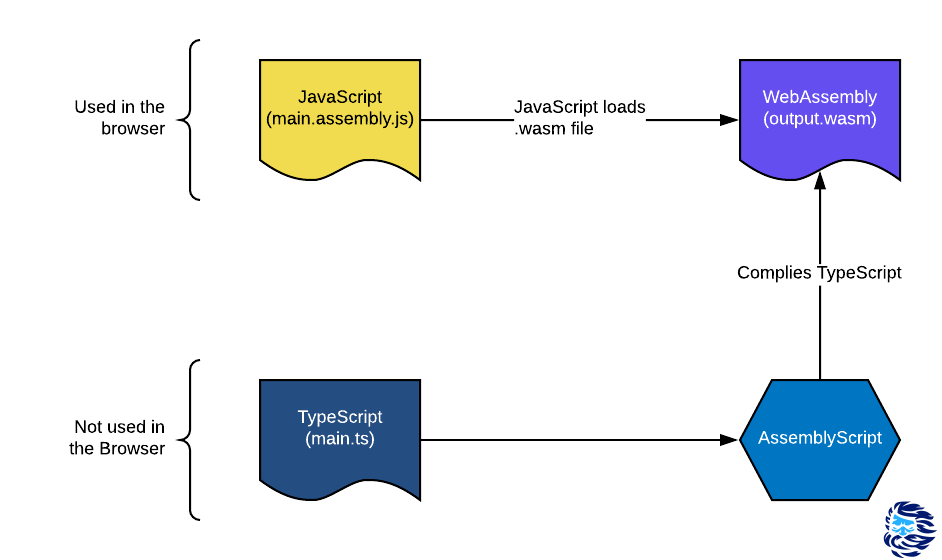
Saya sangat suka bahasa AssemblyScript . Saya bahkan mulai membantu pengembang secara finansial di beberapa titik. Mereka memiliki tim kecil di mana setiap orang sangat menyukai proyek ini. AssemblyScript adalah bahasa mirip TypeScript yang sangat muda yang mampu mengkompilasi ke WebAssembly (Wasm). Inilah salah satu kelebihannya. Sebelumnya, untuk menggunakan Wasm, pengembang web harus belajar bahasa asing seperti C, C ++, C #, Go atau Rust, karena bahasa tingkat tinggi dengan pengetikan statis dapat dikompilasi ke WebAssembly dari sangat awal.
Meskipun AssemblyScript (ASC) mirip dengan TypeScript (TS), ini tidak terkait dengan bahasa itu dan tidak dikompilasi ke JS. Kemiripan sintaks dan semantik diperlukan untuk memudahkan proses "porting" dari TS ke ASC. Porting ini pada dasarnya bermuara pada penambahan anotasi tipe.
Saya selalu tertarik untuk mengambil kode JS, memindahkannya ke ASC, mengompilasinya ke Wasm, dan membandingkan kinerja. Ketika kolega saya Ingvar mengirimi saya cuplikan JavaScript untuk mengaburkan gambar , saya memutuskan untuk menggunakannya. Saya melakukan sedikit eksperimen untuk melihat apakah topik ini perlu ditelusuri lebih dalam. Ternyata itu sangat berharga. Hasilnya, artikel ini muncul.
Untuk mengenal AssemblyScript lebih baik, Anda dapat melihat situs web resmi , bergabung dengan saluran Discord , atau menonton video pengantar di saluran Youtube saya. Dan kami melanjutkan.
Manfaat WebAssembly
Seperti yang saya tulis di atas, untuk waktu yang lama tugas utama Wasm adalah kemampuan untuk mengkompilasi kode yang ditulis dalam bahasa tujuan umum tingkat tinggi. Misalnya, di Squoosh (alat pemrosesan gambar online) kami menggunakan pustaka dari ekosistem C / C ++ dan Rust. Pustaka ini awalnya tidak dirancang untuk digunakan dalam aplikasi web, tetapi WebAssembly memungkinkannya.
Selain itu, menurut kepercayaan populer, menyusun kode sumber di Wasm juga diperlukan karena penggunaan binari Wasm memungkinkan Anda untuk mempercepat kerja aplikasi web. Saya setuju, minimal, bahwa dalam kondisi ideal (laboratorium), binari WebAssembly dan JavaScript dapat melakukannyamemberikan nilai kinerja puncak yang kira-kira sama. Ini hampir tidak mungkin dilakukan pada proyek web pertempuran.
Menurut pendapat saya, lebih masuk akal untuk memikirkan WebAssembly sebagai salah satu alat pengoptimalan untuk rata-rata, nilai kinerja kerja. Meskipun baru-baru ini, Wasm memiliki kemampuan untuk menggunakan instruksi SIMD dan aliran memori bersama. Ini harus meningkatkan daya saingnya. Tetapi bagaimanapun juga, seperti yang saya tulis di atas, semuanya tergantung pada situasi spesifik dan kondisi awal.
Di bawah ini kami akan mempertimbangkan beberapa kondisi seperti itu:
Kurangnya pemanasan
Mesin V8 JS memproses kode sumber dan menyajikannya sebagai pohon sintaks abstrak (AST). Berdasarkan AST yang dibangun, interpreter Pengapian yang dioptimalkan menghasilkan bytecode. Bytecode yang dihasilkan diambil oleh kompiler Sparkplug dan pada keluarannya menghasilkan kode mesin yang belum dioptimalkan, dengan footprint yang besar. Selama eksekusi kode, V8 mengumpulkan informasi tentang bentuk (jenis) objek yang digunakan dan kemudian menjalankan kompilator pengoptimalan TurboFan. Ini menghasilkan instruksi mesin tingkat rendah yang dioptimalkan untuk arsitektur target berdasarkan informasi yang dikumpulkan tentang objek.
Anda dapat memahami cara kerja mesin JS dengan mempelajari terjemahan artikel ini .

Pipa mesin JS. Skema umum
Di sisi lain, WebAssembly menggunakan pengetikan statis, sehingga Anda dapat segera menghasilkan kode mesin darinya. Mesin V8 memiliki kompiler Wasm streaming yang disebut Liftoff. Seperti Pengapian, ini membantu Anda dengan cepat mempersiapkan dan menjalankan kode yang tidak dioptimalkan. Dan setelah itu, TurboFan yang sama akan aktif dan mengoptimalkan kode mesin. Ini akan berjalan lebih cepat daripada setelah mengompilasi Liftoff, tetapi akan membutuhkan waktu lebih lama untuk membuatnya.
Perbedaan mendasar antara pipeline JavaScript dan pipeline WebAssembly: mesin V8 tidak perlu mengumpulkan informasi tentang objek dan jenis, karena Wasm memiliki pengetikan statis dan semuanya diketahui sebelumnya. Ini menghemat waktu.
Kurangnya pengoptimalan
Kode mesin yang dihasilkan TurboFan untuk JavaScript hanya dapat digunakan selama asumsi jenis dipertahankan. Katakanlah TurboFan telah menghasilkan kode mesin, misalnya, untuk fungsi f dengan parameter numerik. Kemudian, setelah menemukan panggilan ke fungsi ini dengan objek, bukan angka, mesin kembali menggunakan Ignition atau Sparkplug. Ini disebut de-optimasi.
Untuk WebAssembly, jenis tidak dapat berubah selama eksekusi program. Oleh karena itu, tidak diperlukan de-optimasi seperti itu. Dan tipe itu sendiri yang didukung Wasm secara organik diterjemahkan ke dalam kode mesin.
Meminimalkan biner untuk proyek besar
Wasm awalnya dirancang dengan format file biner yang ringkas. Oleh karena itu, biner seperti itu dimuat dengan cepat. Tetapi dalam banyak kasus, mereka masih menghasilkan lebih dari yang kami inginkan (setidaknya dalam hal volume yang diterima di jaringan). Namun, dengan gzip atau brotli, file ini akan dikompres dengan baik.
Selama bertahun-tahun, JavaScript telah mempelajari banyak hal di luar kotak: array, objek, kamus, iterator, pemrosesan string, pewarisan prototipe, dan sebagainya. Semua ini dibangun di dalam mesinnya. Dan bahasa C ++, misalnya, dapat membanggakan cakupan yang jauh lebih besar. Dan setiap kali Anda menggunakan salah satu abstraksi bahasa ini saat mengompilasi ke WebAssembly, kode yang sesuai harus disertakan dalam biner Anda. Ini adalah salah satu alasan berkembangnya binari WebAssembly.
Wasm tidak benar-benar tahu apa-apa tentang C ++ (atau bahasa lainnya). Oleh karena itu, runtime Wasm tidak menyediakan pustaka C ++ standar dan kompilator harus menambahkannya ke setiap file biner. Tetapi kode seperti itu hanya perlu dihubungkan satu kali. Oleh karena itu, untuk project yang lebih besar, hal ini tidak terlalu memengaruhi ukuran biner Wasm yang dihasilkan, yang pada akhirnya sering kali lebih kecil daripada biner lainnya.
Jelas bahwa tidak dalam semua kasus dimungkinkan untuk membuat keputusan berdasarkan informasi dengan hanya membandingkan ukuran binari. Jika, misalnya, kode sumber AssemblyScript dikompilasi ke dalam Wasm, maka binernya akan menjadi sangat kompak. Tapi seberapa cepat itu akan berjalan? Saya menetapkan sendiri tugas untuk membandingkan berbagai versi biner JS dan ASC berdasarkan dua kriteria sekaligus - kecepatan dan ukuran.
Porting ke AssemblyScript
Seperti yang sudah saya tulis, TypeScript dan ASC sangat mirip dalam sintaks dan semantik. Sangat mudah untuk mengasumsikan ada kemiripan dengan JS, jadi porting sebagian besar adalah tentang menambahkan anotasi tipe (atau mengganti tipe). Untuk mulai mem-porting Glur , JS-library untuk gambar blur.
Pemetaan tipe data
Jenis AssemblyScript bawaan diimplementasikan mirip dengan jenis mesin virtual Wasm (WebAssembly VM). Jika di TypeScript, misalnya, jenis Nomor diimplementasikan sebagai nomor floating point 64-bit (menurut standar IEEE754), maka di ASC ada sejumlah jenis numerik: u8, u16, u32, i8, i16, i32 , f32, dan f64. Selain itu, Anda dapat menemukan tipe data komposit umum (string, Array, ArrayBuffer, Uint8Array, dan seterusnya) di pustaka standar AssemblyScript, yang, dengan reservasi tertentu, ada di TypeScript dan JavaScript. Saya tidak akan mempertimbangkan di sini tabel pemetaan tipe AssemblyScript, TypeScript dan Wasm VM, ini adalah topik untuk artikel lain. Satu-satunya hal yang ingin saya perhatikan adalah bahwa ASC mengimplementasikan tipe StaticArray, yang saya belum temukan analognya di JS dan VM WebAssembly.
Akhirnya, kami beralih ke kode contoh kami dari pustaka glur.
JavaScript:
function gaussCoef(sigma) {
if (sigma < 0.5)
sigma = 0.5;
var a = Math.exp(0.726 * 0.726) / sigma;
/* ... more math ... */
return new Float32Array([
a0, a1, a2, a3,
b1, b2,
left_corner, right_corner
]);
}
AssemblyScript:
function gaussCoef(sigma: f32): Float32Array {
if (sigma < 0.5)
sigma = 0.5;
let a: f32 = Mathf.exp(0.726 * 0.726) / sigma;
/* ... more math ... */
const r = new Float32Array(8);
const v = [
a0, a1, a2, a3,
b1, b2,
left_corner, right_corner
];
for (let i = 0; i < v.length; i++) {
r[i] = v[i];
}
return r;
}
Fragmen kode AssemblyScript berisi loop tambahan di bagian akhir, karena tidak ada cara untuk menginisialisasi array melalui konstruktor. ASC tidak mengimplementasikan overloading fungsi, jadi dalam kasus ini kita hanya memiliki satu konstruktor Float32Array (lengthOfArray: i32). AssemblyScript memiliki callback, tetapi tidak ada penutupan, jadi tidak ada cara untuk menggunakan .forEach () untuk mengisi array dengan nilai. Jadi saya harus menggunakan loop for biasa untuk menyalin satu elemen pada satu waktu.
Anda mungkin telah memperhatikannya dalam cuplikan kode di AssemblyScript Math, Mathf. , 64- , — 32-. Math . - , , f32. . .
:
Butuh waktu lama bagi saya untuk memahami: pemilihan jenis sangat penting. Memburamkan gambar melibatkan operasi konvolusi, dan itu adalah sejumlah besar loop untuk melewati semua piksel. Sangat naif untuk berpikir bahwa jika semua indeks piksel positif, penghitung loop juga akan positif. Saya seharusnya tidak memilih tipe u32 (32-bit unsigned integer) untuk mereka. Jika salah satu dari loop ini berjalan ke arah yang berlawanan, itu akan menjadi tak terbatas (program akan melakukan loop):
let j: u32;
// ... many many lines of code ...
for (j = width — 1; j >= 0; j--) {
// ...
}
Saya tidak menemukan kesulitan lain dalam porting.
Tolok ukur shell D8
Oke, potongan kode dwibahasa sudah siap. Sekarang Anda dapat mengkompilasi ASC ke Wasm dan menjalankan benchmark pertama.
Beberapa kata tentang d8: ini adalah shell perintah untuk mesin V8 (ia sendiri tidak memiliki antarmuka sendiri), yang memungkinkan Anda untuk melakukan semua tindakan yang diperlukan dengan Wasm dan JS. Pada prinsipnya, d8 dapat dibandingkan dengan Node, yang tiba-tiba memotong pustaka standar dan hanya ECMAScript murni yang tersisa. Jika Anda tidak memiliki versi terkompilasi dari V8 di lokal (cara mengkompilasinya dijelaskan di sini ), Anda tidak dapat menggunakan d8. Untuk menginstal d8 gunakan alat jsvu .
Namun, karena judul bagian ini mengandung kata "Benchmarks", saya merasa penting untuk memberikan semacam penafian di sini: angka dan hasil yang saya terima mengacu pada kode yang saya tulis dalam bahasa pilihan saya yang berjalan di komputer (MacBook Air M1 2020) menggunakan skrip pengujian yang saya buat. Hasil terbaik hanyalah pedoman kasar. Oleh karena itu, akan terburu-buru untuk memberikan perkiraan kuantitatif umum dari kinerja AssemblyScript dengan WebAssembly atau JavaScript dengan V8 berdasarkan padanya.
Anda mungkin memiliki pertanyaan lain: mengapa saya memilih d8 dan tidak menjalankan skrip di browser atau Node? Saya yakin bahwa browser dan Node, boleh dikatakan, tidak cukup steril untuk eksperimen saya. Selain kemandulan yang diperlukan, d8 memungkinkan untuk mengontrol pipa mesin V8. Saya dapat menangkap skenario dan penggunaan optimasi apa pun, misalnya, hanya Pengapian, hanya Sparkplug atau Liftoff sehingga karakteristik kinerja tidak berubah di tengah pengujian.
Teknik eksperimental
Seperti yang saya tulis di atas, kami memiliki kesempatan untuk "memanaskan" mesin JavaScript sebelum menjalankan uji kinerja. Selama proses pemanasan ini, V8 melakukan pengoptimalan yang diperlukan. Jadi saya menjalankan program blur 5 kali sebelum memulai pengukuran, lalu menjalankan 50 kali lari dan mengabaikan 5 lari tercepat dan paling lambat untuk menghilangkan kemungkinan pencilan dan terlalu banyak pencilan.
Lihat apa yang terjadi:

Di satu sisi, saya senang Liftoff menghasilkan kode yang lebih cepat dibandingkan dengan Ignition dan Sparkplug. Tetapi fakta bahwa AssemblyScript, yang dikompilasi di Wasm menggunakan pengoptimalan, ternyata beberapa kali lebih lambat daripada bundel JavaScript - TurboFan, saya bingung.
Meskipun kemudian saya mengakui bahwa kekuatan pada awalnya tidak sama: tim insinyur yang sangat besar telah mengerjakan JS dan mesin V8-nya selama bertahun-tahun, menerapkan pengoptimalan dan hal-hal cerdas lainnya. AssemblyScript adalah proyek yang relatif muda dengan tim kecil. Compiler ASC sendiri adalah single-pass dan menempatkan semua upaya pengoptimalan di library Binaryen... Ini berarti bahwa pengoptimalan dilakukan pada level bytecode VM Wasm setelah sebagian besar semantik level tinggi telah dikompilasi. V8 memiliki keunggulan yang jelas di sini. Namun, kode blur sangat sederhana - ini adalah operasi aritmatika biasa dengan nilai dari memori. Tampaknya ASC dan Wasm seharusnya melakukan tugas ini dengan lebih baik. Ada apa disini?
Mari kita gali lebih dalam
Saya segera berkonsultasi dengan orang pintar di tim V8 dan orang yang sama pintar di tim AssemblyScript (terima kasih kepada Daniel dan Max!). Ternyata saat menyusun ASC, "pemeriksaan batas" (nilai batas) tidak dimulai.
V8 dapat melihat kode JS sumber kapan saja dan memahami semantiknya. Ini menggunakan informasi ini untuk pengoptimalan berulang atau tambahan. Misalnya, Anda memiliki ArrayBuffer yang berisi sekumpulan data biner. Dalam kasus ini, V8 mengharapkan bahwa akan sangat masuk akal untuk tidak hanya menjalankan sel memori secara kacau, tetapi juga menggunakan iterator melalui for ... of loop.
for (<i>variable</i> of <i>iterableObject</i>) {
<i>statement</i>
}
Semantik operator ini memastikan bahwa kami tidak pernah melampaui batas array. Akibatnya, kompilator TurboFan tidak menangani pemeriksaan batas. Tetapi sebelum mengompilasi ASC ke Wasm, semantik AssemblyScript tidak digunakan untuk pengoptimalan tersebut: semua pengoptimalan dilakukan pada level mesin virtual WebAssembly.
Untungnya, ASC masih memiliki kartu truf - anotasi yang tidak dicentang (). Ini menunjukkan nilai mana yang harus diperiksa untuk kemungkinan keluar dari batas.
- prev_prev_out_r = prev_src_r * coeff [6];
- baris [line_index] = prev_out_r;
2 baris sebelumnya perlu ditulis ulang sebagai berikut:
+ prev_prev_out_r = prev_src_r * tidak dicentang (coeff [6]);
+ tidak dicentang (baris [line_index] = prev_out_r);
Ya, masih ada lagi. Di AssemblyScript, array yang diketik (Uint8Array, Float32Array, dan sebagainya) diimplementasikan dalam image dan rupa ArrayBuffer. Namun, karena kurangnya pengoptimalan tingkat tinggi untuk mengakses elemen array dengan indeks i, setiap kali Anda harus mengakses memori dua kali: pertama kali memuat pointer ke elemen array pertama dan kedua kalinya memuat elemen di offset i * sizeOfType. Artinya, Anda harus merujuk ke array sebagai buffer (melalui pointer). Dalam kasus JS, hal ini paling sering tidak terjadi, karena V8 berhasil melakukan pengoptimalan tingkat tinggi dari akses array menggunakan satu akses memori.
Untuk meningkatkan kinerja, AssemblyScript mengimplementasikan array statis (StaticArray). Mereka mirip dengan Array kecuali bahwa mereka memiliki panjang tetap. Dan akibatnya tidak perlu menyimpan pointer ke elemen pertama dari array. Jika memungkinkan, gunakan array ini untuk mempercepat program Anda.
Jadi, saya mengambil kumpulan AssemblyScript - TurboFan (bekerja lebih cepat) dan menyebutnya naif. Kemudian saya menambahkan dua pengoptimalan yang saya bicarakan di bagian ini, dan saya mendapat varian yang disebut dioptimalkan.

Jauh lebih baik! Kami telah membuat kemajuan yang signifikan. AssemblyScript masih lebih lambat dari JavaScript. Apakah hanya ini yang bisa kita lakukan? [spoiler: tidak]
Oh, keheningan ini
Orang-orang di tim AssemblyScript juga memberi tahu saya bahwa flag --optimize setara dengan -O3s. Ini mengoptimalkan kecepatan kerja dengan baik, tetapi tidak membuatnya maksimal, karena pada saat yang sama mencegah pertumbuhan file biner. Bendera -O3 hanya mengoptimalkan kecepatan dan melakukannya sampai akhir. Menggunakan -O3s secara default tampaknya benar, karena dalam pengembangan web adalah kebiasaan untuk mengurangi ukuran binari, tetapi apakah itu sepadan? Setidaknya dalam contoh khusus ini, jawabannya tidak: -O3s menghemat ~ 30 byte, tetapi mengabaikan penurunan kinerja yang signifikan:

Satu bendera pengoptimal tunggal membalik permainan: Akhirnya, AssemblyScript telah mengambil alih JavaScript (dalam kasus uji khusus ini!).
Saya tidak akan lagi menunjukkan bendera O3 di tabel, tetapi yakinlah: mulai sekarang hingga akhir artikel, itu tidak akan terlihat oleh kami.
Semacam gelembung
Untuk memastikan bahwa contoh buram bukan hanya kebetulan, saya memutuskan untuk mengambil contoh lain. Saya mengambil implementasi pengurutan di StackOverflow dan melalui proses yang sama:
- porting kode dengan menambahkan tipe;
- meluncurkan tes;
- dioptimalkan;
- menjalankan tes lagi.
(Saya belum menguji membuat dan mengisi array untuk bubble sort).
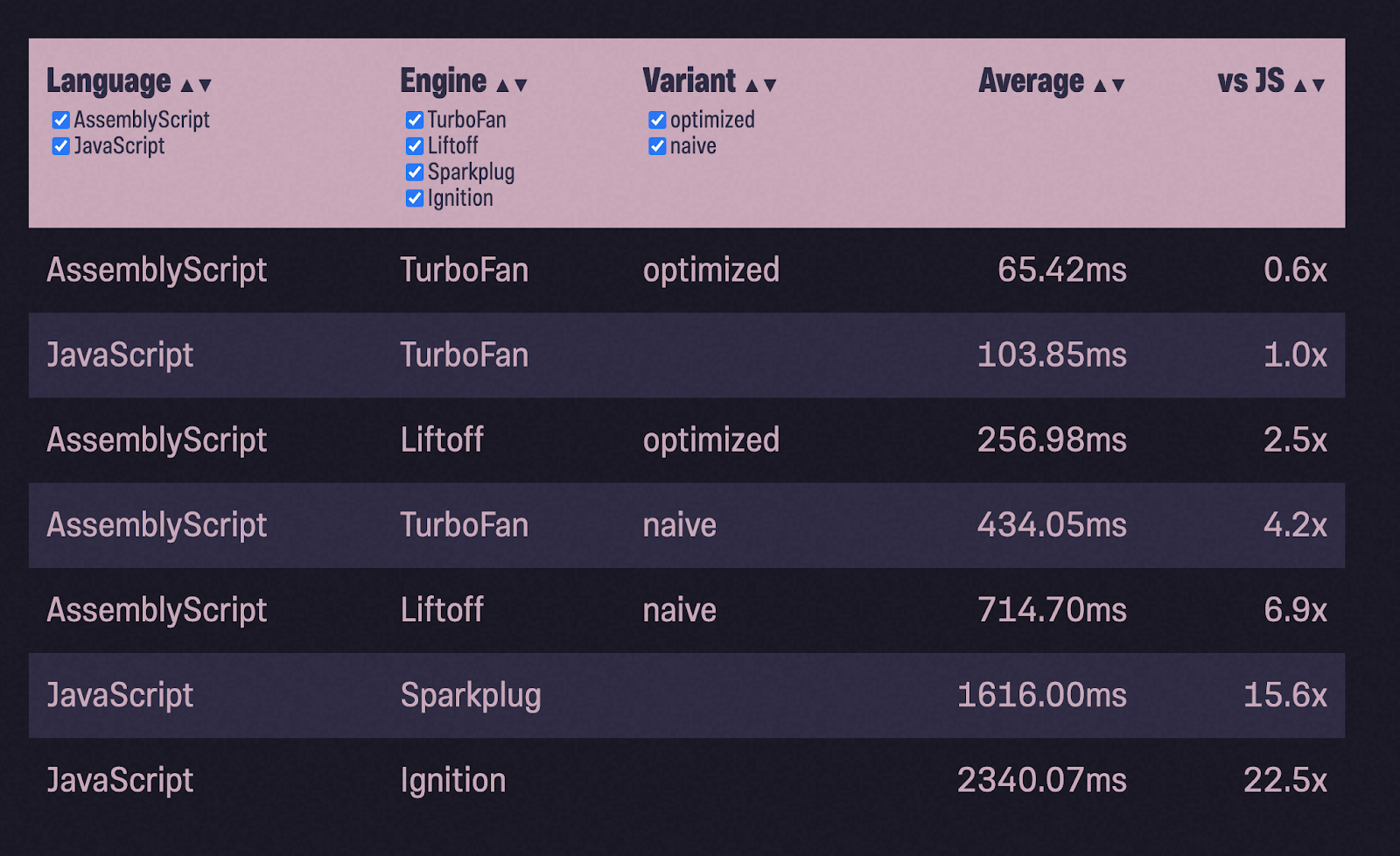
Kami melakukannya lagi! Kali ini dengan peningkatan kecepatan yang lebih besar: AssemblyScript yang dioptimalkan hampir dua kali lebih cepat dari JavaScript. Tapi itu belum semuanya. Naik turun lebih lanjut menunggu saya lagi. Tolong jangan beralih!
Manajemen memori
Beberapa dari Anda mungkin telah memperhatikan bahwa kedua contoh ini tidak benar-benar menunjukkan bagaimana bekerja dengan memori. Dalam JavaScript, V8 menangani semua manajemen memori (dan pengumpulan sampah) untuk Anda. Di WebAssembly, di sisi lain, Anda berakhir dengan sepotong memori linier dan Anda harus memutuskan bagaimana menggunakannya (atau lebih tepatnya Wasm harus memutuskan). Berapa banyak tabel kita akan berubah jika kita menggunakan heap secara intensif?
Saya memutuskan untuk mengambil contoh baru dengan implementasi heap biner... Selama pengujian, saya mengisi tumpukan dengan 1 juta nomor acak (milik Math.random ()) dan pop () mengembalikannya, memeriksa apakah angkanya dalam urutan menaik. Skema umum pekerjaan tetap sama: port kode JS ke ASC, kompilasi dengan konfigurasi naif, jalankan tes, optimalkan dan jalankan tes lagi:
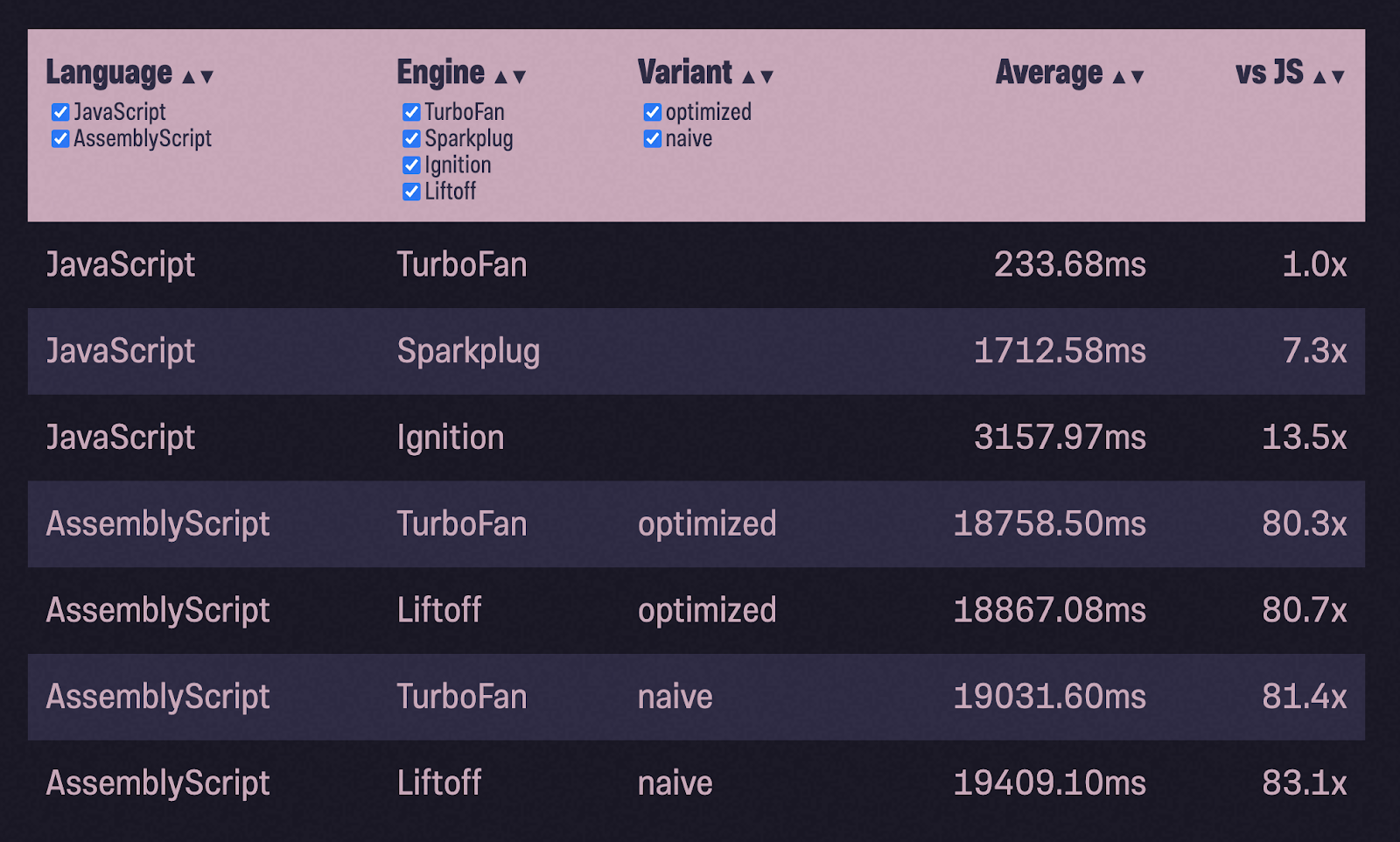
80x lebih lambat dari JavaScript dengan TurboFan?! Dan 6x lebih lambat dari Pengapian! Apa yang salah?
Menyiapkan lingkungan runtime
Semua data yang kami hasilkan di AssemblyScript harus disimpan di memori. Tapi kita perlu memastikan kita tidak menimpa apapun yang sudah ada di sana. Karena AssemblyScript cenderung meniru perilaku JavaScript, ia juga memiliki pengumpul sampah, dan ketika dikompilasi, ia menambahkan kolektor ini ke modul WebAssembly. ASC tidak ingin Anda khawatir tentang kapan harus mengalokasikan dan kapan harus mengosongkan memori.
Dalam mode ini (disebut inkremental) ini berfungsi secara default. Pada saat yang sama, hanya sekitar 2 KB di arsip gzip yang ditambahkan ke modul Wasm. AssemblyScript juga menawarkan mode alternatif, minimal dan stub. Mode dapat dipilih menggunakan tanda --runtime. Minimal menggunakan pengalokasi memori yang sama, tetapi pengumpul sampah berbobot lebih ringan yang tidak dimulai secara otomatis, tetapi harus dipanggil secara manual. Ini berguna saat mengembangkan aplikasi berkinerja tinggi (seperti game) di mana Anda ingin mengontrol saat pengumpul sampah menjeda program Anda. Dalam mode rintisan, sangat sedikit kode yang ditambahkan ke modul Wasm (~ 400B dalam format gzip). Ia bekerja dengan cepat, karena pengalokasi cadangan digunakan (detail lebih lanjut tentang pengalokasi ditulis di sini ).
Pengalokasi redundan sangat cepat, tetapi tidak dapat mengosongkan memori. Ini mungkin terdengar konyol, tetapi dapat berguna untuk contoh modul "satu kali", di mana setelah menyelesaikan tugas, alih-alih mengosongkan memori, Anda menghapus seluruh contoh WebAssembly dan membuat yang baru.
Mari kita lihat bagaimana modul kita akan bekerja dalam berbagai mode:

Baik minimal maupun rintisan membawa kami lebih dekat ke tingkat kinerja JavaScript. Kenapa ya? Seperti disebutkan di atas, minimal dan inkremental menggunakan pengalokasi yang sama. Keduanya juga memiliki pengumpul sampah, tetapi minimal tidak menjalankannya kecuali dipanggil secara eksplisit (yang tidak saya lakukan). Ini berarti bahwa intinya adalah incremental memulai pengumpulan sampah secara otomatis, dan seringkali melakukannya tanpa perlu. Nah, mengapa ini perlu jika hanya perlu melacak satu larik?
Masalah alokasi memori
Setelah menjalankan modul Wasm dalam mode debug (--debug) beberapa kali, saya menemukan bahwa kecepatan kerja melambat karena pustaka libsystem_platform.dylib. Ini berisi primitif tingkat OS untuk threading dan manajemen memori. Panggilan ke perpustakaan ini dibuat dari __new () dan __renew (), yang pada gilirannya dipanggil dari Array # push: Saya mengerti: ada masalah manajemen memori di sini. Tetapi JavaScript entah bagaimana berhasil dengan cepat memproses array yang terus berkembang. Jadi mengapa AssemblyScript tidak bisa melakukan ini? Untungnya, sumber pustaka standar AssemblyScript tersedia untuk umum , jadi mari kita lihat fungsi push () dari kelas Array ini:
[Bottom up (heavy) profile]:
ticks parent name
18670 96.1% /usr/lib/system/libsystem_platform.dylib
13530 72.5% Function: *~lib/rt/itcms/__renew
13530 100.0% Function: *~lib/array/ensureSize
13530 100.0% Function: *~lib/array/Array#push
13530 100.0% Function: *binaryheap_optimized/BinaryHeap#push
13530 100.0% Function: *binaryheap_optimized/push
5119 27.4% Function: *~lib/rt/itcms/__new
5119 100.0% Function: *~lib/rt/itcms/__renew
5119 100.0% Function: *~lib/array/ensureSize
5119 100.0% Function: *~lib/array/Array#push
5119 100.0% Function: *binaryheap_optimized/BinaryHeap#push
export class Array<T> {
// ...
push(value: T): i32 {
var length = this.length_;
var newLength = length + 1;
ensureSize(changetype<usize>(this), newLength, alignof<T>());
// ...
return newLength;
}
// ...
}
Sejauh ini, semuanya sudah benar: panjang baru array sama dengan panjang saat ini, ditambah 1. Selanjutnya, panggilan ke fungsi sureSize () mengikuti untuk memastikan bahwa ada cukup kapasitas dalam buffer (Kapasitas) untuk elemen baru.
function ensureSize(array: usize, minSize: usize, alignLog2: u32): void {
// ...
if (minSize > <usize>oldCapacity >>> alignLog2) {
// ...
let newCapacity = minSize << alignLog2;
let newData = __renew(oldData, newCapacity);
// ...
}
}
Fungsi sureSize (), pada gilirannya, memeriksa: Apakah Kapasitas kurang dari minSize baru? Jika demikian, alokasikan buffer minSize baru menggunakan fungsi _renew (). Ini memerlukan penyalinan semua data dari buffer lama ke buffer baru. Untuk alasan ini, pengujian kami dengan mengisi larik dengan 1 juta nilai (satu elemen demi elemen lainnya) mengarah ke realokasi sejumlah besar memori dan menciptakan banyak sampah.
Di pustaka lain (seperti std :: vec di Rust atau slicesdi Go), buffer baru memiliki kapasitas dua kali lipat dari yang lama, yang membantu membuat proses bekerja dengan memori lebih murah dan lambat. Saya sedang mengatasi masalah ini di ASC, dan sejauh ini satu-satunya solusi adalah membuat CustomArray saya sendiri, dengan pengoptimalan memorinya sendiri.

Sekarang incremental secepat minimal dan stub. Namun JavaScript tetap menjadi yang terdepan dalam kasus uji ini. Saya mungkin dapat membuat lebih banyak pengoptimalan di tingkat bahasa, tetapi ini bukan artikel tentang cara mengoptimalkan AssemblyScript itu sendiri. Aku sudah tenggelam cukup dalam.
Ada banyak pengoptimalan sederhana yang dapat dilakukan oleh compiler AssemblyScript untuk saya. Untuk tujuan ini, tim ASC sedang mengerjakan pengoptimal IR (Perwakilan Menengah) tingkat tinggi yang disebut AIR. Bisakah ini membuat pekerjaan lebih cepat dan menyelamatkan saya dari keharusan mengoptimalkan akses array secara manual setiap saat? Yang paling disukai. Akankah lebih cepat dari JavaScript? Sulit untuk dikatakan. Tapi bagaimanapun, itu menarik bagi saya untuk bersaing untuk ASC, mengevaluasi kemampuan JS dan melihat apa yang dapat dicapai oleh bahasa yang lebih "dewasa" dengan alat kompilasi "sangat cerdas".
Karat & C ++
Saya menulis ulang kode di Rust, sebisa mungkin, dan mengkompilasinya ke WebAssembly. Ternyata lebih cepat dari AssemblyScript (naif), tetapi lebih lambat dari AssemblyScript kami yang dioptimalkan dengan CustomArray. Selanjutnya, saya mengoptimalkan modul yang dikompilasi dari Rust dengan cara yang sama seperti AssemblyScript. Dengan pengoptimalan ini, modul Wasm berbasis Rust lebih cepat daripada AssemblyScript kami yang dioptimalkan, tetapi masih lebih lambat dari JavaScript.
Saya mengambil pendekatan yang sama untuk C ++, menggunakan Emscripten untuk mengkompilasi ke WebAssembly . Yang mengejutkan saya, bahkan opsi pertama tanpa pengoptimalan ternyata tidak lebih buruk dari JavaScript.

Tidak ada URL gambar di sini. Saya mengambil tangkapan layar sendiri.
Versi yang ditandai sebagai idiomatik dipengaruhi oleh kode sumber JS. Saya mencoba menggunakan pengetahuan saya tentang idiom Rust, C ++, tetapi penginstalannya kuat di kepala saya bahwa saya sedang melakukan porting. Saya yakin seseorang dengan lebih banyak pengalaman dalam bahasa ini dapat menerapkan tugas dari awal dan kodenya akan terlihat berbeda.
Saya cukup yakin modul Rust dan C ++ dapat berjalan lebih cepat. Tetapi saya tidak memiliki pengetahuan yang cukup mendalam tentang bahasa-bahasa ini untuk memeras lebih banyak darinya.
Sekali lagi tentang ukuran binari
Mari kita lihat ukuran biner setelah kompresi gzip. Dibandingkan dengan Rust dan C ++, binari AssemblyScript memang jauh lebih ringan.
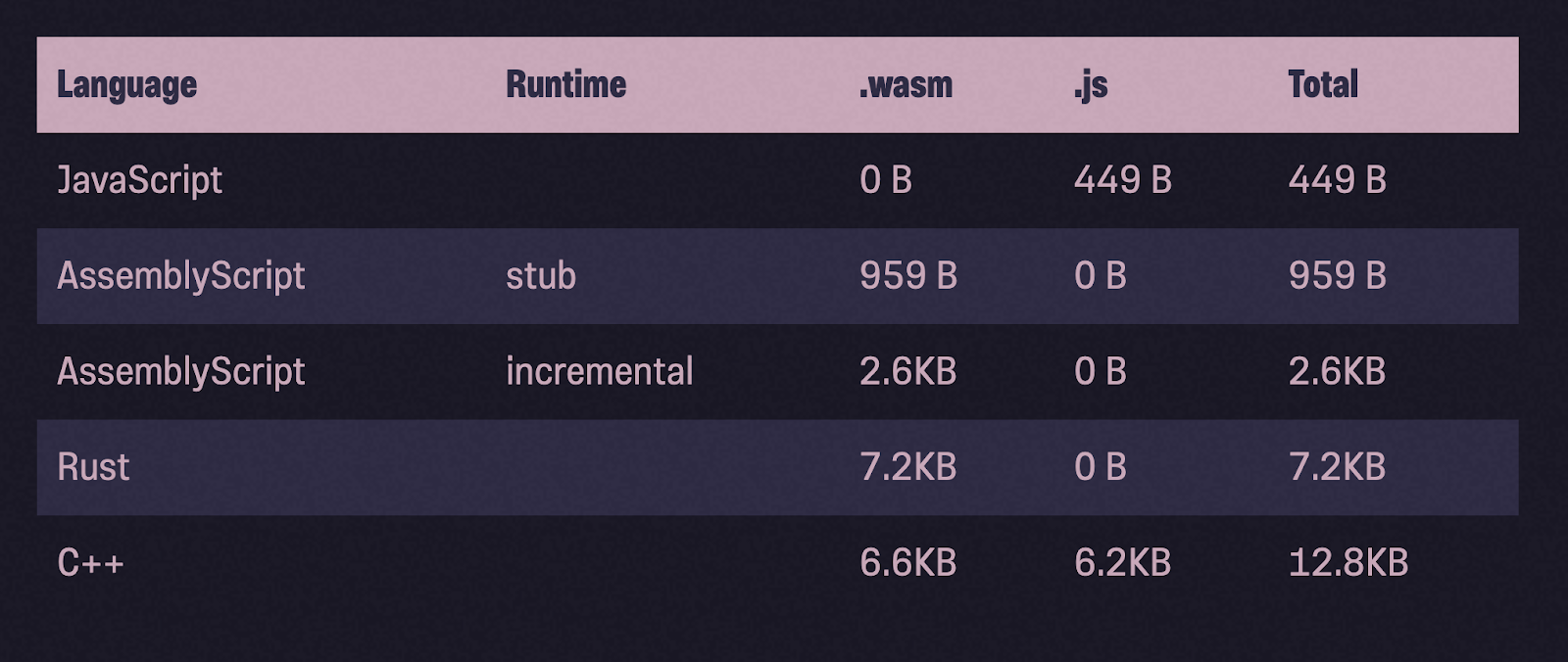
Namun ... rekomendasi
Saya menulis tentang ini di awal artikel, dan saya akan mengulanginya sekarang: hasilnya, paling banter, pedoman perkiraan. Oleh karena itu, akan menjadi terburu-buru untuk memberikan perkiraan kuantitatif umum produktivitas atas dasar mereka. Misalnya, Anda tidak dapat mengatakan bahwa Rust 1,2 kali lebih lambat dari JavaScript dalam semua kasus. Angka-angka ini sangat bergantung pada kode yang saya tulis, pengoptimalan yang saya terapkan, dan mesin yang saya gunakan.
Namun, menurut saya ada beberapa pedoman umum yang dapat kami pelajari untuk membantu Anda lebih memahami topik dan membuat keputusan yang lebih baik:
- Liftoff AssemblyScript Wasm-, , , Ignition SparkPlug JavaScript. JS-, WebAssembly — .
- V8 JavaScript-. WebAssembly , JavaScript, , .
- , , .
- Modul AssemblyScript umumnya jauh lebih ringan daripada modul Wasm yang dikompilasi dari bahasa lain. Dalam artikel ini, biner AssemblyScript tidak lebih kecil dari biner JavaScript, tetapi kebalikannya berlaku untuk modul yang lebih besar, seperti yang dinyatakan oleh tim pengembangan ASC.
Jika Anda tidak mempercayai saya (dan Anda tidak perlu) dan ingin mengetahui sendiri kode kasus pengujian, ini dia .
Server kami dapat digunakan untuk pengembangan WebAssembly.
Daftar menggunakan tautan di atas atau dengan mengklik spanduk dan dapatkan diskon 10% untuk bulan pertama menyewa server dengan konfigurasi apa pun!
