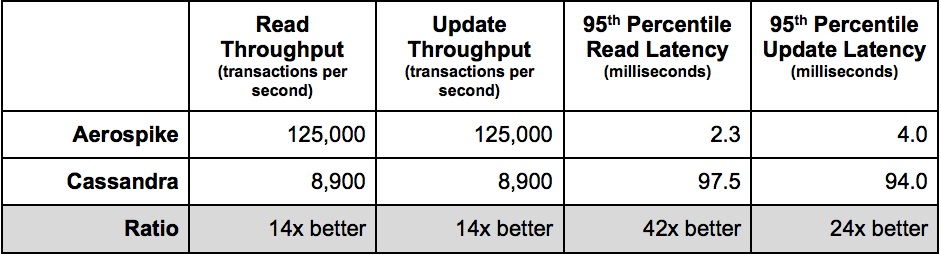
Secara kebetulan yang luar biasa, Scylla (selanjutnya SC) juga mengalahkan CS dengan mudah, yang dengan bangga mengumumkannya langsung di halaman beranda:

Dengan demikian, pertanyaan yang muncul secara alami, siapa yang akan memagari siapa, paus atau gajah?
Dalam pengujian saya , versi HBase yang dioptimalkan (selanjutnya disebut HB) bekerja dengan CS dengan pijakan yang sama, jadi di sini tidak akan menjadi penantang untuk menang, tetapi hanya sejauh semua pemrosesan kami didasarkan pada HB dan saya ingin memahami kemampuannya dibandingkan dengan para pemimpin.
Jelas bahwa HB dan CS tidak dipungut biaya, tetapi di sisi lain, jika Anda membutuhkan perangkat keras X kali lebih banyak untuk mencapai kinerja yang sama, lebih menguntungkan untuk membayar perangkat lunak daripada mengalokasikan lantai di pusat data dengan biaya mahal. bantalan pemanas. Terutama mengingat bahwa jika kita berbicara tentang kinerja, maka karena HDD, pada prinsipnya, tidak dapat memberikan setidaknya beberapa kecepatan pembacaan Akses Acak yang dapat diterima (lihat " Mengapa pembacaan HDD dan Akses Acak cepat tidak kompatibel "), yang pada gilirannya berarti membeli SSD, yang dalam volume yang dibutuhkan untuk BigData asli, merupakan kesenangan yang cukup mahal.
Jadi, berikut ini dilakukan. Saya menyewa 4 server di cloud AWS dalam konfigurasi i3en.6xlarge di mana masing-masing server terpasang:
CPU - 24 vcpu
MEM - 192 GB
SSD - 2 x 7500 GB
Jika seseorang ingin mengulanginya, kami segera mencatat bahwa sangat penting untuk reproduktifitas untuk mengambil konfigurasi di mana volume total disk (7500 GB). Jika tidak, disk harus dibagikan dengan tetangga yang tidak dapat diprediksi, yang pasti akan merusak pengujian Anda, karena mungkin tampaknya menjadi beban yang sangat berharga.
Selanjutnya, saya meluncurkan SC menggunakan konstruktor , yang disediakan dengan ramah oleh pabrikan di situs webnya sendiri. Kemudian saya mengunggah utilitas YCSB (yang hampir merupakan standar untuk pengujian database komparatif) untuk setiap node cluster.
Hanya ada satu nuansa penting, di hampir semua kasus kami menggunakan pola berikut: baca catatan sebelum mengubah + tulis nilai baru.
Jadi saya memodifikasi pembaruan sebagai berikut:
@Override
public Status update(String table, String key,
Map<String, ByteIterator> values) {
read(table, key, null, null); // << added read before write
return write(table, key, updatePolicy, values);
}
Kemudian saya mulai memuat secara bersamaan dari semua 4 host (yang sama di mana server database berada). Ini dilakukan dengan sengaja, karena terkadang klien dari beberapa database menggunakan lebih banyak CPU daripada yang lain. Mengingat ukuran cluster terbatas, saya ingin memahami keseluruhan efisiensi implementasi bagian server dan klien.
Hasil tes akan disajikan di bawah ini, tetapi sebelum kita beralih ke mereka, ada baiknya mempertimbangkan beberapa nuansa yang lebih penting.
Adapun AS, ini adalah database yang sangat menarik, pemimpin dalam kategori kepuasan pelanggan sesuai dengan sumber daya g2.
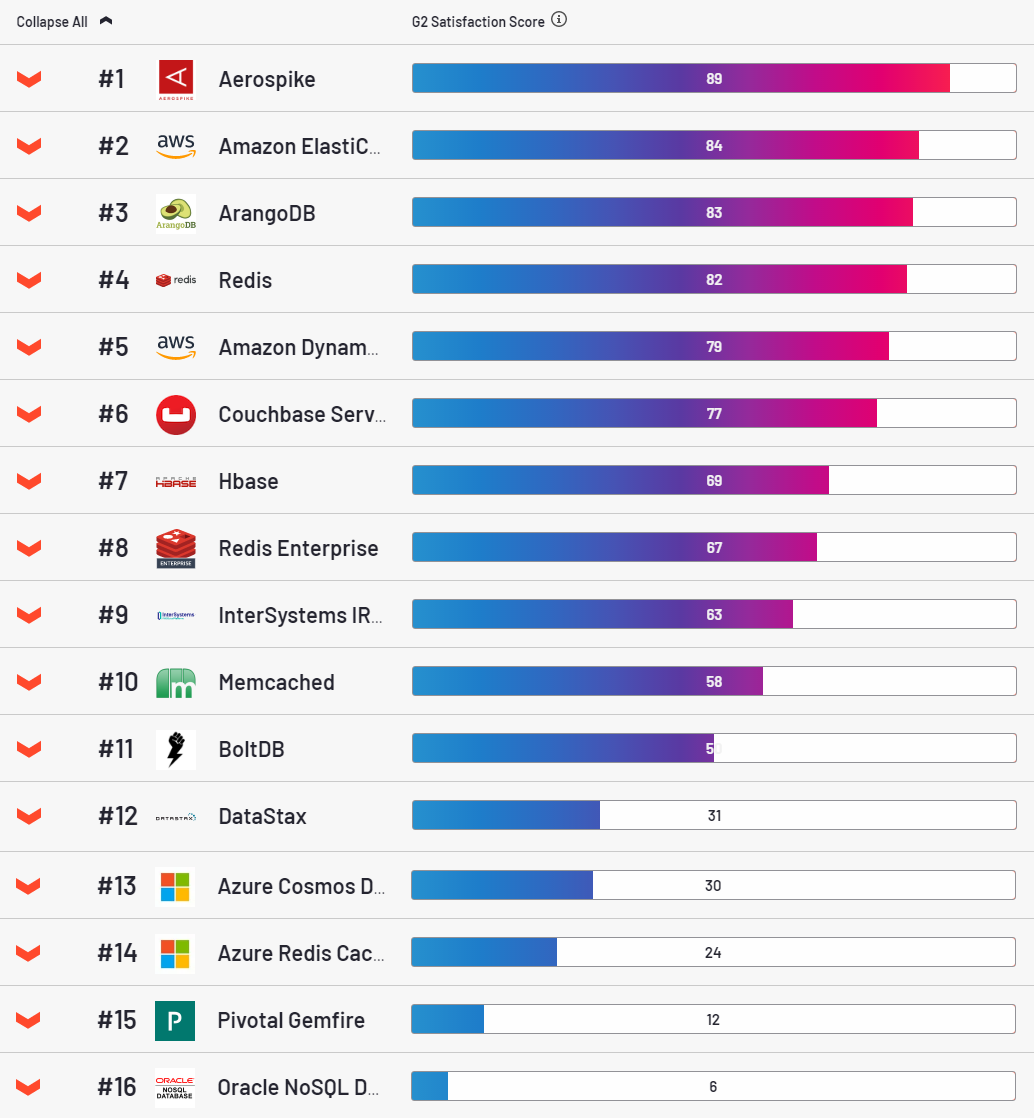
Terus terang, entah bagaimana saya menyukainya juga. Sederhananya, dengan skrip ini diluncurkan ke cloud dengan cukup mudah. Stabil, menyenangkan untuk dikonfigurasi. Namun, ada satu kelemahan yang sangat besar. Untuk setiap kunci, ia mengalokasikan 64 byte RAM. Tampaknya sedikit, tetapi dalam volume industri itu menjadi masalah. Entri tipikal dalam tabel kami adalah 500 byte. Jumlah nilai inilah yang saya gunakan di hampir * semua tes (* mengapa hampir akan dikatakan di bawah).
Karena kita menyimpan 3 salinan dari setiap record, ternyata untuk menyimpan 1 PB data bersih (3 PB data kotor), kita harus mengalokasikan RAM hanya 400 TB. Pindah ... tidak apa ?! Tunggu sebentar, apakah ada yang bisa Anda lakukan? - kami bertanya pada vendornya.
Ha, tentu saja Anda bisa melakukan banyak hal, tekuk jari Anda:
Ok, sekarang mari kita berurusan dengan HB dan kita sudah bisa mempertimbangkan hasil tesnya. Untuk menginstal Hadoop, Amazon menyediakan platform EMR, yang memudahkan untuk meluncurkan klaster yang Anda butuhkan. Saya hanya perlu menaikkan batasan pada jumlah proses dan file yang terbuka, jika tidak maka crash saat memuat dan mengganti hbase-server dengan perakitan saya yang dioptimalkan (lihat detailnya di sini ). Poin kedua, HB tanpa malu-malu melambat saat bekerja dengan permintaan tunggal, ini adalah fakta. Oleh karena itu, kami hanya bekerja secara batch. Dalam pengujian ini, batch = 100. Ada 100 wilayah dalam tabel.
Nah, dan saat terakhir, semua database diuji dalam mode "konsistensi yang kuat". Untuk HB, itu di luar kotak. AS hanya tersedia dalam versi perusahaan (yaitu diaktifkan dalam tes ini). SC berjalan dalam konsistensi tulis = semua mode. Faktor replikasi ada di mana-mana 3.
Jadi, ayo pergi. Masukkan dalam AS:
10 detik: operasi 360554; 36055,4 operasi / detik saat ini;
20 dtk: 698872 operasi; 33831,8 operasi / detik saat ini;
...
230 dtk: 7412626 operasi; 22938,8 operasi / detik saat ini;
240 dtk: 7542091 operasi; 12.946,5 operasi / detik saat ini;
250 dtk: 7589682 operasi; 4759.1 operasi / detik saat ini;
260 dtk: 7599525 operasi; 984,3 operasi / detik saat ini;
270 dtk: 7602150 operasi; 262,5 operasi / detik saat ini;
280 dtk: 7602752 operasi; 60,2 operasi / detik saat ini;
290 dtk: 7602918 operasi; 16,6 operasi / detik saat ini;
300 dtk: 7603269 operasi; 35.1 operasi / detik saat ini;
310 dtk: 7603674 operasi; 40,5 operasi / detik saat ini;
Kesalahan saat menulis kunci user4809083164780879263: com.aerospike.client.AerospikeException $ Timeout: Client timeout: timeout = 10000 iterations = 1 failureNodes = 0 failureConns = 0 lastNode = 5600000A 127.0.0.1:3000
Kesalahan saat memasukkan, tidak mencoba lagi. jumlah percobaan: 1Insertion Retry Limit: 0
Ups, Anda pasti seorang
Oke, ayo lanjutkan. Kami mulai memuat 200 juta catatan (INSERT), lalu UPDATE, lalu GET. Inilah yang terjadi (ops - operasi per detik):

PENTING! Ini adalah kecepatan satu node! Ada total 4 diantaranya, yaitu untuk mendapatkan kecepatan total, Anda harus mengalikannya dengan 4.
Kolom pertama terdiri dari 10 kolom, ini bukan tes yang sepenuhnya adil. Itu. ini adalah saat indeks berada dalam memori, yang tidak dapat dicapai dalam situasi BigData yang sebenarnya.
Kolom kedua mengemas 10 record menjadi 1. sudah ada penghematan memori nyata, tepatnya 10 kali lipat. Seperti yang dapat Anda lihat dengan jelas dari pengujian, trik ini tidak sia-sia, kinerjanya turun secara signifikan. Alasannya jelas, setiap kali memproses satu record, Anda harus berurusan dengan 9 record yang berdekatan. Overhead lebih pendek.
Dan akhirnya all-flush, ini tentang gambar yang sama. Sisipan flush lebih buruk, tetapi operasi Pembaruan kunci lebih cepat, jadi selanjutnya kita hanya akan membandingkan dengan all-flush.
Sebenarnya, jangan langsung menarik kucing itu:

Semuanya secara umum jelas, tetapi apa yang harus ditambahkan di sini.
- AS , .
- SC - , :

Mungkin di suatu tempat ada tiang dengan pengaturan atau bug dengan kernel yang muncul, saya tidak tahu. Tapi saya mengatur semuanya dari dan ke skrip dari vendor, jadi motor bebek itu bukan milik saya, semua pertanyaan untuk dia.
Anda juga perlu memahami bahwa ini adalah jumlah data yang sangat sederhana dan pada volume yang besar situasinya dapat berubah. Selama percobaan, saya menghabiskan beberapa ratus dolar, jadi antusiasme hanya cukup untuk uji pemimpin jangka panjang dan dalam mode terbatas pada satu server.
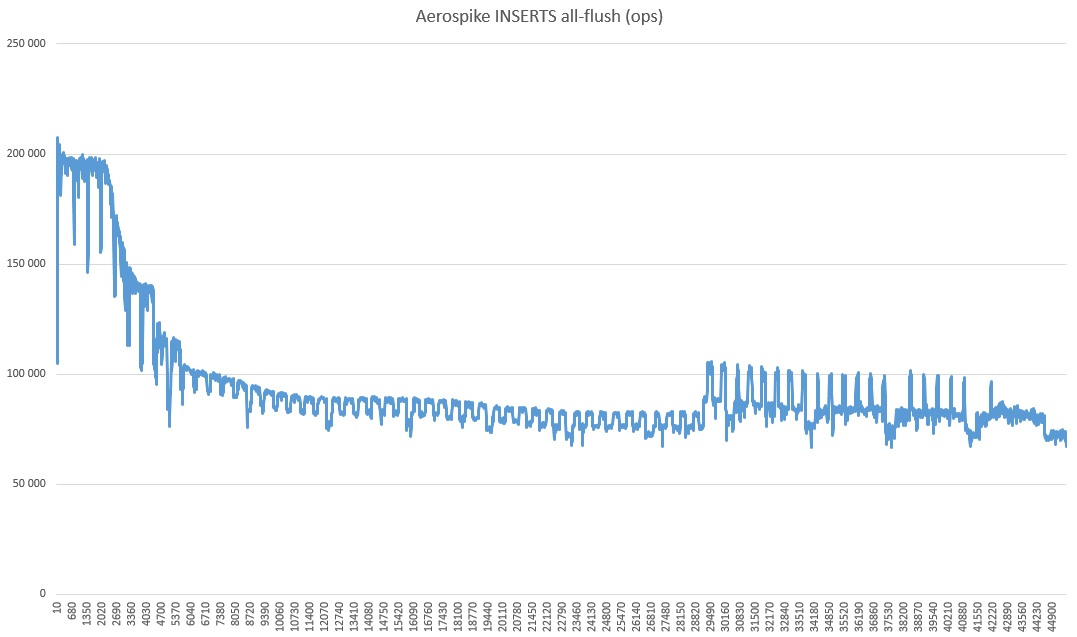
Mengapa itu telah surut begitu banyak dan jenis kebangkitan sepertiga terakhir yang merupakan misteri alam. Anda juga dapat melihat bahwa kecepatannya secara radikal lebih tinggi daripada di pengujian, sedikit lebih tinggi. Saya kira ini karena mode konsistensi yang kuat dimatikan (karena hanya ada satu server).
Dan akhirnya, GET + WRITE (di atas lebih dari tiga miliar rekaman dibanjiri pengujian):
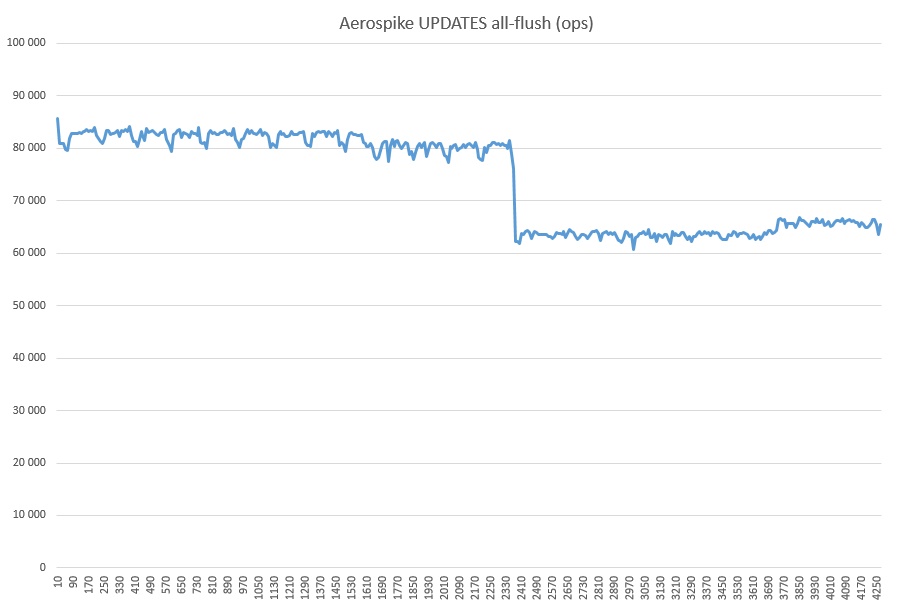
Penarikan macam apa ini, saya tidak menebak di hati saya. Tidak ada proses asing yang dimulai. Mungkin ini ada hubungannya dengan cache SSD, karena pemanfaatan selama pengujian AS secara keseluruhan dalam mode all-flush adalah 100%.

Itu saja. Kesimpulannya secara umum jelas, diperlukan lebih banyak tes. Ini diinginkan untuk semua database paling populer dalam kondisi yang sama. Di internet genre ini entah bagaimana tidak terlalu banyak. Dan alangkah baiknya, kemudian vendor basis akan termotivasi untuk mengoptimalkan, dan kami akan dengan sengaja memilih yang terbaik.