
Daniel Lemire - profesor di Correspondence University of Quebec (TÉLUQ), yang menemukan cara untuk mengurai dua kali lipat dengan sangat cepat - bersama dengan insinyur John Kaiser dari Microsoft menerbitkan temuan mereka yang lain: validator UTF-8, mengungguli pustaka UTF-8 CPP (2006) sebanyak 48..77 kali, DFA dari Björn Hörmann (2009) - 20..45 kali, dan Google Fuchsia (2020) - 13..35 kali. Berita tentang publikasi ini telah diposting di Habré , tetapi tanpa rincian teknis; jadi kami menebus kekurangan ini.
Persyaratan UTF-8
Untuk memulainya, ingat bahwa Unicode memungkinkan poin kode dari U + 0000 hingga U + 10FFFF, yang dikodekan dalam UTF-8 sebagai urutan 1 hingga 4 byte:
| Jumlah byte dalam pengkodean | Jumlah bit di titik kode | Nilai minimum | Nilai maksimum |
|---|---|---|---|
| satu | 1..7 | U + 0000 = 0 0000000 | U + 007F = 0 1111111 |
| 2 | 8..11 | U + 0080 = 110 00010 10 000 000 | U + 07FF = 110 11111 10 111111 |
| 3 | 12..16 | U + 0800 = 1110 0000 10 100000 10 000000 | U + FFFF = 1110 1111 10 111111 10 111111 |
| empat | 17..21 | U + 010000 = 11110 000 10 010000 10 000000 10 000000 | U + 10FFFF = 11110 100 10 001.111 10 111.111 10 111.111 |
Menurut aturan pengkodean, bit paling signifikan dari byte pertama dari urutan menentukan jumlah total byte dalam urutan; Bit paling signifikan nol hanya bisa dalam karakter byte tunggal (ASCII), dua bit paling signifikan menunjukkan karakter multibyte, 1 dan nol menunjukkan byte lanjutan> karakter multibyte.
Jenis kesalahan apa yang mungkin ada dalam string yang dikodekan dengan cara ini?
- Urutan tidak lengkap : byte utama atau karakter ASCII ditemukan di tempat byte lanjutan diharapkan;
- Urutan tanpa kancing : Sebuah byte utama atau karakter ASCII diharapkan di tempat dimana byte lanjutan ditemukan;
- Urutan terlalu panjang : byte utama
11111xxx
cocok dengan urutan lima byte atau lebih panjang yang tidak diperbolehkan dalam UTF-8; - Melampaui batas Unicode : setelah mendekode urutan empat byte, titik kode lebih tinggi dari U + 10FFFF.
Jika baris tidak berisi satu pun dari empat kesalahan ini, maka baris tersebut dapat diterjemahkan menjadi urutan poin kode yang benar. UTF-8, bagaimanapun, membutuhkan lebih - bahwa setiap urutan poin kode yang benar dikodekan secara unik. Ini menambahkan dua lagi kemungkinan kesalahan:
- : code point ;
- : code points U+D800 U+DFFF UTF-16, code point U+FFFF. UTF-8 , code points , .
Dalam pengkodean CESU-8 yang jarang digunakan, persyaratan terakhir dibatalkan (dan di MUTF-8 juga merupakan yang kedua dari belakang), karena panjang urutan dibatasi hingga tiga byte, tetapi dekripsi dan validasi string rumit. Misalnya, emotikon U + 1F600 GRINNING FACE direpresentasikan dalam UTF-16 sebagai sepasang pengganti
0xD83D 0xDE00
, dan CESU-8 / MUTF-8 menerjemahkannya menjadi sepasang urutan tiga byte
0xED 0xA0 0xBD 0xED 0xB8 0x80
; tetapi di UTF-8 smiley ini dikodekan dalam satu urutan empat byte
0xF0 0x9F 0x98 0x80
.
Untuk setiap jenis kesalahan, berikut ini adalah urutan bit yang mengarah padanya:
| Urutan yang belum selesai | Byte ke-2 hilang | 11xxxxxx 0xxxxxxx
|
11xxxxxx 11xxxxxx
|
||
| Byte ke-3 hilang | 111xxxxx 10xxxxxx 0xxxxxxx
|
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| Byte ke-4 hilang | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| Urutan tidak diambil | Byte ekstra ke-2 | 0xxxxxxx 10xxxxxx
|
| Ekstra byte ke-3 | 110xxxxx 10xxxxxx 10xxxxxx
|
|
| Byte ke-4 ekstra | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Byte ekstra ke-5 | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Urutan terlalu panjang | 11111xxx
|
|
| Melampaui batas Unicode | U + 110000..U + 13FFFF | 11110100 1001xxxx
|
11110100 101xxxxx
|
||
| ≥ U + 140.000 | 11110101
|
|
1111011x
|
||
| Konsistensi yang tidak minimal | 2-byte | 1100000x
|
| 3-byte | 11100000 100xxxxx
|
|
| 4-byte | 11110000 1000xxxx
|
|
| Pengganti | 11101101 101xxxxx
|
|
Memvalidasi UTF-8
Dengan pendekatan naif yang digunakan di perpustakaan UTF-8 CPP Serbia Nemanja Trifunovic, validasi dilakukan dalam rangkaian cabang bertingkat:
const octet_difference_type length = utf8::internal::sequence_length(it);
// Get trail octets and calculate the code point
utf_error err = UTF8_OK;
switch (length) {
case 0:
return INVALID_LEAD;
case 1:
err = utf8::internal::get_sequence_1(it, end, cp);
break;
case 2:
err = utf8::internal::get_sequence_2(it, end, cp);
break;
case 3:
err = utf8::internal::get_sequence_3(it, end, cp);
break;
case 4:
err = utf8::internal::get_sequence_4(it, end, cp);
break;
}
if (err == UTF8_OK) {
// Decoding succeeded. Now, security checks...
if (utf8::internal::is_code_point_valid(cp)) {
if (!utf8::internal::is_overlong_sequence(cp, length)){
// Passed! Return here.
Di dalam
sequence_length()
dan
is_overlong_sequence()
juga percabangan tergantung panjang urutannya. Jika urutan dengan panjang yang berbeda tidak dapat diprediksi interleave dalam string input, maka branch predictor tidak dapat menghindari flushing pipeline beberapa kali pada setiap karakter yang diproses.
Pendekatan yang lebih efisien untuk validasi UTF-8 adalah dengan menggunakan mesin status 9 status: (status kesalahan tidak ditampilkan dalam diagram)
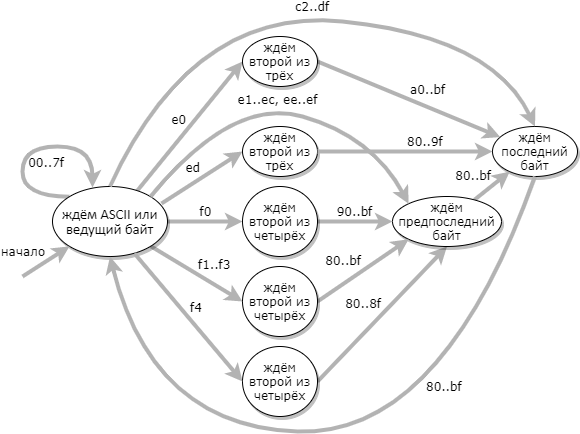
Saat tabel transisi otomatis dibuat, kode validatornya sangat sederhana:
uint32_t type = utf8d[byte];
*codep = (*state != UTF8_ACCEPT) ?
(byte & 0x3fu) | (*codep << 6) :
(0xff >> type) & (byte);
*state = utf8d[256 + *state + type];
Di sini, untuk setiap karakter yang diproses, tindakan yang sama diulangi, tanpa transisi bersyarat - oleh karena itu, penyetelan ulang pipa tidak diperlukan; di sisi lain, pada setiap iterasi, akses memori tambahan (ke tabel lompat
utf8d
) dilakukan selain membaca karakter input.
Lemir dan Kaiser menggunakan DFA yang sama sebagai dasar validator mereka, dan mencapai akselerasi sepuluh kali lipat karena penerapan tiga peningkatan:
- Tabel lompatan dikurangi dari 364 byte menjadi 48, sehingga cocok seluruhnya dalam tiga register vektor (masing-masing 128 bit), dan akses memori diperlukan hanya untuk membaca karakter input;
- Blok 16 byte yang berdekatan diproses secara paralel;
- Jika blok 16-byte seluruhnya terdiri dari karakter ASCII, maka itu diketahui benar, dan tidak perlu pemeriksaan yang lebih menyeluruh. "Bagian jalan" ini mempercepat pemrosesan teks "realistis" yang berisi seluruh kalimat dalam alfabet Latin dua hingga tiga kali; tetapi pada teks acak, di mana alfabet Latin, hieroglif, dan emotikon dicampur secara merata, hal ini tidak dipercepat.
Ada kehalusan halus dalam penerapan masing-masing perbaikan ini, sehingga perlu dipertimbangkan secara mendetail.
Mengurangi tabel lompat
Perbaikan pertama didasarkan pada pengamatan bahwa untuk mendeteksi sebagian besar kesalahan (12 urutan bit tidak valid dari 19 yang tercantum dalam tabel di atas), cukup memeriksa 12 bit pertama dari urutan:
| Urutan yang belum selesai | Byte ke-2 hilang | 11xxxxxx 0xxxxxxx
|
0x02
|
11xxxxxx 11xxxxxx
|
|||
| Urutan tidak diambil | Byte ekstra ke-2 | 0xxxxxxx 10xxxxxx
|
0x01
|
| Urutan terlalu panjang | 11111xxx 1000xxxx
|
0x20
|
|
11111xxx 1001xxxx
|
0x40
|
||
11111xxx 101xxxxx
|
|||
| Melampaui batas Unicode | U + 1 [1235679ABDEF] xxxx | 111101xx 1001xxxx
|
|
111101xx 101xxxxx
|
|||
| U + 1 [48C] xxxx | 11110101 1000xxxx
|
0x20
|
|
1111011x 1000xxxx
|
|||
| Konsistensi yang tidak minimal | 2-byte | 1100000x
|
0x04
|
| 3-byte | 11100000 100xxxxx
|
0x10
|
|
| 4-byte | 11110000 1000xxxx
|
0x20
|
|
| Pengganti | 11101101 101xxxxx
|
0x08
|
|
Untuk setiap potensi kesalahan ini, para peneliti menetapkan satu dari tujuh bit, seperti yang ditunjukkan di kolom paling kanan. (Bit yang ditugaskan berbeda antara artikel yang diterbitkan dan kode GitHub mereka ; berikut adalah nilai dari artikel.) Untuk bertahan dengan tujuh bit, dua subkase unicode out-of-bounds harus dipartisi ulang sehingga yang kedua digabungkan dengan urutan non-minimal 4-byte; dan kasus urutan yang terlalu panjang dibagi menjadi tiga subkase dan digabungkan dengan subkase luar batas Unicode.
Jadi, perubahan berikut dibuat dengan Hörmann DKA:
- Masukan tidak datang dengan byte, tetapi oleh tetrad (nibble);
- Otomat digunakan sebagai non - deterministik - pemrosesan setiap tetrad mentransfer otomat antara subset dari semua kemungkinan keadaan;
- Delapan kondisi yang benar digabungkan menjadi satu, tetapi satu yang salah dibagi menjadi tujuh;
- Tiga tetrad yang berdekatan diproses tidak secara berurutan, tetapi secara independen satu sama lain, dan hasilnya diperoleh sebagai perpotongan dari tiga set keadaan akhir.
Berkat perubahan ini, tiga tabel dengan 16 byte cukup untuk menggambarkan semua kemungkinan transisi: setiap elemen tabel digunakan sebagai bidang bit yang mencantumkan semua kemungkinan status akhir. Tiga dari elemen ini di-AND bersama-sama, dan jika ada bit bukan nol dalam hasilnya, maka kesalahan telah terdeteksi.
| Tetrad | Nilai | Kemungkinan kesalahan | Kode |
|---|---|---|---|
| Tinggi di byte pertama | 0-7 | 2- | 0x01
|
| 8–11 | () | 0x00
|
|
| 12 | 2- ; 2- | 0x06
|
|
| 13 | 2- | 0x02
|
|
| 14 | 2- ; 2- ; | 0x0E
|
|
| 15 | 2- ; ; Unicode; 4- | 0x62
|
|
| 0 | 2- ; 2- ; | 0x37
|
|
| 1 | 2- ; 2- ; 2- | 0x07
|
|
| 2–3 | 2- ; 2- | 0x03
|
|
| 4 | 2- ; 2- ; Unicode | 0x43
|
|
| 5–7 | 0x63
|
||
| 8–10, 12–15 | 2- ; 2- ; | ||
| 11 | 2- ; 2- ; ; | 0x6B
|
|
| 0–7, 12–15 | Byte ke-2 hilang; urutan terlalu panjang; Urutan non-minimal 2-byte | 0x06
|
|
| 8 | Byte ekstra ke-2; urutan terlalu panjang; melampaui batas Unicode; konsistensi non-minimal | 0x35
|
|
| sembilan | 0x55
|
||
| 10-11 | Byte ekstra ke-2; urutan terlalu panjang; melampaui batas Unicode; Urutan non-minimal 2-byte; pengganti | 0x4D
|
Ada 7 urutan bit lagi yang tidak valid yang tidak diproses:
| Urutan yang belum selesai | Byte ke-3 hilang | 111xxxxx 10xxxxxx 0xxxxxxx
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| Byte ke-4 hilang | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| Urutan tidak diambil | Ekstra byte ke-3 | 110xxxxx 10xxxxxx 10xxxxxx
|
| Byte ke-4 ekstra | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Byte ekstra ke-5 | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
Dan di sini bit yang paling signifikan berguna, dengan hati-hati tidak digunakan dalam tabel transisi: itu akan sesuai dengan urutan bit
10xxxxxx 10xxxxxx
, mis. dua byte berturut-turut. Sekarang memeriksa tiga buku catatan dapat mendeteksi kesalahan, atau memberikan hasil
0x00
atau
0x80
. Dan hasil pemeriksaan pertama ini - bersama dengan buku catatan pertama - sudah cukup bagi kita:
| Byte ke-3 hilang | 111xxxxx 10xxxxxx 0xxxxxxx
|
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| Byte ke-4 hilang | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| Ekstra byte ke-3 | 110xxxxx 10xxxxxx 10xxxxxx
|
|
| Byte ke-4 ekstra | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Byte ekstra ke-5 | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Kombinasi yang diizinkan |
|
|
|
||
Ini berarti bahwa untuk menyelesaikan pemeriksaan, cukup dengan memastikan bahwa setiap hasil
0x80
sesuai dengan salah satu dari dua kombinasi yang valid.
Vektorisasi
Bagaimana cara memproses blok 16 byte yang berdekatan secara paralel? Ide utamanya adalah menggunakan instruksi
pshufb
sebagai 16 substitusi bersamaan menurut tabel 16-byte. Untuk pemeriksaan kedua, Anda perlu menemukan di blok semua byte dalam bentuk
111xxxxx
dan
1111xxxx
; karena tidak ada perbandingan vektor unsigned pada Intel, itu diganti dengan pengurangan saturasi (
psubusb
).
Sumber simdjson sulit dibaca karena fakta bahwa semua kode dipecah menjadi fungsi satu baris. Seluruh pseudocode validator terlihat seperti ini:
prev = vector(0)
while !input_exhausted:
input = vector(...)
prev1 = prev<<120 | input>>8
prev2 = prev<<112 | input>>16
prev3 = prev<<104 | input>>24
#
nibble1 = prev1.shr(4).lookup(table1)
nibble2 = prev1.and(15).lookup(table2)
nibble3 = input.shr(4).lookup(table3)
result1 = nibble1 & nibble2 & nibble3
#
test1 = prev2.saturating_sub(0xDF) # 111xxxxx => >0
test2 = prev3.saturating_sub(0xEF) # 1111xxxx => >0
result2 = (test1 | test2).gt(0) & vector(0x80)
# result1 0x80 , result2,
#
if result1 != result2:
return false
prev = input
return true
Jika urutan yang salah terletak di tepi kanan dari blok terakhir, maka itu tidak akan terdeteksi oleh kode ini. Agar tidak repot, Anda dapat menambahkan string input dengan byte nol sehingga pada akhirnya Anda mendapatkan satu blok nol sepenuhnya. Sebagai gantinya, simdjson memilih untuk mengimplementasikan pemeriksaan khusus untuk byte terakhir: agar string benar, byte terakhir harus lebih kecil secara ketat
0xC0
, byte kedua dari belakang lebih sedikit
0xE0
, dan byte ketiga dari akhir lebih sedikit
0xF0
.
Peningkatan terakhir yang dihasilkan Lemierre dan Kaiser adalah cut-off ASCII. Menentukan bahwa hanya ada karakter ASCII di blok saat ini sangat sederhana:
input & vector(0x80) == vector(0)
... Dalam hal ini, cukup untuk memastikan bahwa tidak ada urutan yang salah di perbatasan
prev
dan
input
, - dan Anda dapat pergi ke blok berikutnya. Pemeriksaan ini dilakukan dengan cara yang sama seperti di akhir string input; perbandingan vektor unsigned dengan
[..., 0x0, 0xE0, 0xC0]
, yang tidak tersedia di Intel, diganti dengan kalkulasi vektor maksimum (
pmaxub
) dan perbandingannya dengan vektor yang sama.
Memeriksa ASCII ternyata menjadi satu-satunya cabang di dalam iterasi validator, dan untuk berhasil memprediksi cabang ini, cukup dengan string input tidak menyisipkan seluruhnya blok ASCII dengan blok yang berisi karakter non-ASCII. Para peneliti menemukan bahwa hasil yang lebih baik pada teks nyata dapat dicapai dengan memeriksa penggabungan OR dari empat blok yang berdekatan untuk ASCII, dan melewatkan keempat blok dalam kasus ASCII. Memang, dapat diharapkan bahwa jika penulis teks, pada prinsipnya, menggunakan karakter non-ASCII, maka mereka akan muncul setidaknya sekali setiap 64 karakter, yang cukup untuk memprediksi transisi.
