
Masalah yang diselesaikan oleh machine learning saat ini seringkali rumit dan mencakup banyak fitur (fitur). Karena kerumitan dan keragaman data awal, penggunaan model pembelajaran mesin sederhana sering kali tidak memungkinkan pencapaian hasil yang diperlukan, oleh karena itu, model non-linier yang kompleks digunakan dalam kasus bisnis nyata. Model tersebut memiliki kelemahan yang signifikan: karena kompleksitasnya, hampir tidak mungkin untuk melihat logika yang digunakan model untuk menetapkan kelas khusus ini ke operasi akun. Interpretabilitas model sangat penting ketika hasil pekerjaannya perlu disajikan kepada pelanggan - dia kemungkinan besar ingin tahu berdasarkan keputusan kriteria apa yang dibuat untuk bisnisnya.
, sklearn, xgboost, lightGBM (). , . , , ? ? , . SHAP. SHAP . , .
. , . 213 , .
kaggle .
:
%%time
# LOAD TRAIN
X_train=pd.read_csv('train_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols+['isFraud'])
train_id= pd.read_csv('train_identity.csv',index_col='TransactionID', dtype=dtypes)
X_train = X_train.merge(train_id, how='left', left_index=True, right_index=True)
# LOAD TEST
X_test=pd.read_csv('test_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols)
test_id = pd.read_csv('test_identity.csv',index_col='TransactionID', dtype=dtypes)
fix = {o:n for o, n in zip(test_id.columns, train_id.columns)}
test_id.rename(columns=fix, inplace=True)
X_test = X_test.merge(test_id, how='left', left_index=True, right_index=True)
# TARGET
y_train = X_train['isFraud'].copy()
del train_id, test_id, X_train['isFraud']; x = gc.collect()
# PRINT STATUS
print('Train shape',X_train.shape,'test shape',X_test.shape)
X_train.head()

, , , , .
, () , , . , , , .
.
:
if BUILD95:
feature_imp=pd.DataFrame(sorted(zip(clf.feature_importances_,cols)), columns=['Value','Feature'])
plt.figure(figsize=(20, 10))
sns.barplot(x="Value", y="Feature", data=feature_imp.sort_values(by="Value", ascending=False).iloc[:50])
plt.title('XGB95 Most Important Features')
plt.tight_layout()
plt.show()
del clf, h; x=gc.collect()

, , . : ? . , , . , , SHAP. , , : 20 . 50 .
:
import shap
shap.initjs()
shap_test = shap.TreeExplainer(h).shap_values(X_train.loc[idxT,cols])
shap.summary_plot(shap_test, X_train.loc[idxT,cols],
max_display=25, auto_size_plot=True)
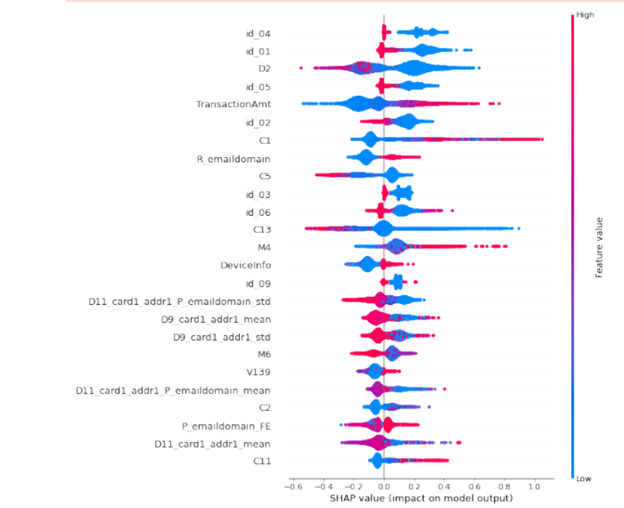
, . 2 . «0», «1». , . , . , , , : , , . , email.
Berdasarkan data yang diperoleh, dimungkinkan untuk meringankan model, yaitu hanya menyisakan parameter yang memiliki pengaruh signifikan terhadap hasil prediksi model kami. Selain itu, menjadi mungkin untuk menilai pentingnya fitur untuk subkelompok data tertentu, misalnya, pelanggan dari berbagai wilayah, transaksi pada waktu yang berbeda dalam sehari, dll. Selain itu, alat ini dapat digunakan untuk menganalisis kasus individu, untuk Misalnya, untuk menganalisis "outlier" dan nilai ekstrim. SHAP juga dapat membantu menemukan zona jatuh saat mengklasifikasikan fenomena negatif. Alat ini, dikombinasikan dengan pendekatan lain, akan membuat model lebih ringan, kualitas lebih baik, dan hasil dapat ditafsirkan.