Di antara kerangka kerja yang kami pertimbangkan untuk pemrosesan data kompleks di Java adalah Apache Flink. Kami ingin menawarkan terjemahan artikel bagus dari blog Analytics Vidhya di portal Medium untuk menilai minat pembaca. Jangan ragu untuk memilih!

Dalam artikel ini, kita akan melihat dari bawah ke atas tentang bagaimana merampingkan dengan Flink; di layanan cloud dan di platform lain, solusi streaming disediakan (beberapa di antaranya memiliki Flink terintegrasi di bawah tenda). Jika Anda ingin memahami topik ini dari awal, Anda telah menemukan apa yang Anda cari.
Solusi monolitik kami tidak dapat mengatasi peningkatan volume data yang masuk; Oleh karena itu, perlu dikembangkan. Saatnya beralih ke generasi baru dalam evolusi produk kami. Diputuskan untuk menggunakan pemrosesan streaming. Ini adalah paradigma baru penyerapan data yang lebih unggul dari pemrosesan batch tradisional.
Sekilas tentang Apache Flink
Apache Flink adalah kerangka kerja threading terdistribusi yang skalabel yang dirancang untuk operasi pada aliran data yang berkelanjutan. Dalam kerangka kerja ini, konsep seperti sumber, transformasi aliran, pemrosesan paralel, penjadwalan, penugasan sumber daya digunakan. Berbagai tujuan data didukung. Secara khusus, Apache Flink dapat terhubung ke HDFS, Kafka, Amazon Kinesis, RabbitMQ, dan Cassandra.
Flink dikenal dengan throughput tinggi dan latensi rendah, mendukung pemrosesan yang konsisten dan hanya sekali (semua data diproses sekali, tidak ada duplikasi), dan ketersediaan tinggi. Seperti produk open source yang sukses, Flink memiliki komunitas besar yang memupuk dan memperluas kapabilitas framework ini.
Flink dapat menangani aliran data (ukuran aliran tidak ditentukan) atau kumpulan data (ukuran kumpulan data bersifat spesifik). Artikel ini secara khusus membahas pemrosesan utas (menangani objek
DataStream
).
Streaming dan Panggilan Inheren
Saat ini, dengan keberadaan perangkat Internet of Things dan sensor lainnya di mana-mana, data terus diterima dari berbagai sumber. Aliran data tanpa akhir ini membutuhkan adaptasi komputasi batch tradisional ke kondisi baru.
- Streaming data tidak terbatas; mereka tidak memiliki awal atau akhir.
- Data baru datang dengan cara yang tidak dapat diprediksi, pada interval yang tidak teratur.
- Data dapat tiba dengan cara yang tidak teratur, dengan stempel waktu yang berbeda.
Dengan karakteristik unik seperti itu, pemrosesan data dan tugas kueri tidak mudah dilakukan. Hasil dapat berubah dengan cepat, dan hampir tidak mungkin untuk menarik kesimpulan yang pasti; komputasi terkadang dapat memblokir saat mencoba mendapatkan hasil yang valid. Selain itu, hasil tidak dapat direproduksi, karena data terus berubah selama penghitungan. Akhirnya, penundaan adalah faktor lain yang mempengaruhi keakuratan hasil.
Apache Flink memungkinkan Anda untuk mengatasi masalah pemrosesan tersebut, karena ini berfokus pada stempel waktu dengan mana data yang masuk dipasok kembali ke sumbernya. Flink memiliki mekanisme untuk mengumpulkan peristiwa berdasarkan stempel waktu yang dipasang padanya - dan hanya setelah mengumpulkan, sistem akan melanjutkan ke pemrosesan. Dalam hal ini, dimungkinkan untuk dilakukan tanpa menggunakan paket mikro, dan juga dalam hal ini, keakuratan hasil meningkat.
Flink mengimplementasikan pemrosesan satu kali yang konsisten dan ketat, yang menjamin keakuratan perhitungan, dan pengembang tidak perlu memprogram sesuatu yang khusus untuk ini.
Terbuat dari apa paket Flink
Biasanya, Flink menyerap aliran data dari berbagai sumber. Objek dasar adalah
DataStream<T>
aliran elemen dengan tipe yang sama. Jenis elemen dalam aliran tersebut ditentukan pada waktu kompilasi dengan menyetel jenis generik
T
(Anda dapat membaca lebih lanjut tentang ini di sini ).
Objek
DataStream
berisi banyak metode yang berguna untuk mengubah, memisahkan, dan memfilter data. Sebagai permulaan akan berguna untuk memiliki gagasan tentang apa yang mereka lakukan
map
,
reduce
dan
filter
; ini adalah metode transformasi utama:
Map
:T
R
;MapFunction
DataStream
.
SingleOutputStreamOperator<R> map(MapFunction<T,R> mapper)
Reduce
: , ; , .
T reduce(T value1, T value2)
Filter
:T
T
;DataStream
, ,true
.
SingleOutputStreamOperator<T> filter(FilterFunction<T> filter)
Salah satu tujuan utama Flink, bersama dengan transformasi data, adalah untuk mengontrol aliran dan mengarahkannya ke tujuan tertentu. Tempat-tempat ini disebut “saluran air”. Flink memiliki string bawaan (teks, CSV, soket), serta mekanisme out-of-the-box untuk menghubungkan ke sistem lain, misalnya, Apache Kafka .
Flink Event Tags
Saat memproses aliran data, faktor waktu sangat penting. Ada tiga cara untuk menentukan stempel waktu:
- ( ): , ; , . - . , .
, , . , , , ; , .
// Processing Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
- : , , , Flink. , , Flink .
Flink , , , ; « » (watermark). ; Flink.
// Event Time streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);DataStream<String> dataStream = streamEnv.readFile(auditFormat, dataDir, FileProcessingMode.PROCESS_CONTINUOUSLY, 1000). assignTimestampsAndWatermarks( new TimestampExtractor());// ... ... // public class TimestampExtractor implements AssignerWithPeriodicWatermarks<String>{ @Override public Watermark getCurrentWatermark() { return new Watermark(System.currentTimeMillis()-maxTimeFrame); } @Override public long extractTimestamp(String str, long l) { return InputData.getDataObject(str).timestamp; } }
- Waktu penyerapan: ini adalah titik waktu di mana peristiwa memasuki Flink; ditetapkan saat peristiwa berada di sumbernya dan oleh karena itu dianggap lebih stabil daripada waktu pemrosesan yang ditetapkan saat proses mulai berjalan.
Waktu penyerapan tidak cocok untuk menangani kejadian yang tidak teratur atau data yang terlambat karena stempel waktu adalah saat penyerapan dimulai; dalam hal ini, waktu acara berbeda dari waktu acara, yang memberikan kemampuan untuk mendeteksi acara yang tertunda dan memprosesnya, dengan mengandalkan mekanisme watermarking.
// Ingestion Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
Anda dapat membaca lebih lanjut tentang stempel waktu dan bagaimana pengaruhnya terhadap streaming di tautan berikut .
Kerusakan jendela
Arus menurut definisi tidak ada habisnya; oleh karena itu, mekanisme pemrosesan dikaitkan dengan definisi fragmen (misalnya, periode-jendela). Dengan demikian, aliran dibagi menjadi beberapa batch yang sesuai untuk agregasi dan analisis. Definisi jendela adalah operasi pada objek DataStream atau sesuatu yang lain yang mewarisi darinya.
Ada beberapa jenis jendela yang bergantung pada waktu:
Jendela tumbling (konfigurasi default):
Aliran dibagi menjadi jendela dengan ukuran setara yang tidak tumpang tindih satu sama lain. Saat aliran mengalir, Flink terus menghitung data berdasarkan papan cerita yang ditetapkan waktu ini. Implementasi

tumbling window
dalam kode:
// ,
public AllWindowedStream<T,TimeWindow> timeWindowAll(Time size)
// ,
public WindowedStream<T,KEY,TimeWindow> timeWindow(Time size)
Jendela geser Jendela tersebut
dapat saling tumpang tindih, dan properti jendela geser ditentukan oleh ukuran jendela ini dan margin (kapan memulai jendela berikutnya). Dalam hal ini, acara yang terkait dengan lebih dari satu jendela dapat diproses pada waktu tertentu.

Jendela geser
Dan inilah tampilannya dalam kode:
// 1 30
dataStreamObject.timeWindow(Time.minutes(1), Time.seconds(30))
Jendela Sesi
Mencakup semua acara dalam satu sesi. Sesi berakhir jika tidak ada aktivitas, atau jika tidak ada peristiwa yang direkam setelah jangka waktu tertentu. Periode ini bisa tetap atau dinamis, bergantung pada peristiwa yang sedang diproses. Secara teori, jika interval antar sesi kurang dari ukuran jendela, maka sesi mungkin tidak akan pernah berakhir.
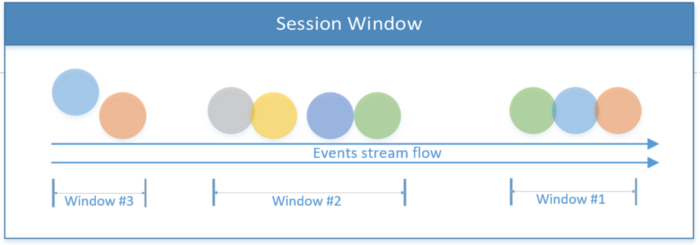
Jendela Sesi
Cuplikan kode pertama di bawah ini menunjukkan sesi dengan nilai waktu tetap (2 detik). Contoh kedua mengimplementasikan jendela sesi dinamis berdasarkan peristiwa thread.
// 2
dataStreamObject.window(ProcessingTimeSessionWindows.withGap(Time.seconds(2)))
// ,
dataStreamObject.window(EventTimeSessionWindows.withDynamicGap((elem) -> {
// ,
}))
Jendela Global
Seluruh sistem diperlakukan sebagai satu jendela.

Jendela global
Flink juga memungkinkan Anda untuk menerapkan jendela Anda sendiri, yang logikanya ditentukan oleh pengguna.
Selain jendela yang bergantung pada waktu, ada jendela lain, misalnya, jendela Akun, di mana batas jumlah acara masuk ditetapkan; ketika ambang X tercapai, Flink memproses peristiwa X.

Jendela penghitungan untuk tiga peristiwa
Setelah pengantar teoritis, mari kita bahas lebih detail apa itu aliran data dari sudut pandang praktis. Untuk informasi lebih lanjut tentang Apache Flink dan threading, lihat situs web resmi .
Deskripsi aliran
Sebagai ringkasan teoritis, diagram blok berikut menunjukkan aliran data utama yang diterapkan dalam cuplikan kode dari artikel ini. Aliran di bawah ini dimulai dari sumber (file ditulis ke direktori) dan berlanjut saat memproses peristiwa yang diubah menjadi objek.
Implementasi yang digambarkan di bawah ini memiliki dua jalur pemrosesan. Yang ditampilkan di bagian atas membagi satu aliran menjadi dua aliran samping, dan kemudian menggabungkannya, mendapatkan aliran tipe ketiga. Skrip yang ditunjukkan di bagian bawah diagram menjelaskan pemrosesan aliran, setelah itu hasil pekerjaan dipindahkan ke bak cuci.

Selanjutnya, kita akan mencoba merasakan dengan tangan kita sendiri implementasi praktis dari teori di atas; semua kode sumber yang dibahas di bawah ini diposting di GitHub .
Pemrosesan Aliran Dasar (Contoh # 1)
Konsep Flink akan lebih mudah dipahami jika Anda memulai dengan aplikasi yang paling sederhana. Dalam aplikasi ini, produser menulis file ke direktori, sehingga mensimulasikan aliran informasi. Flink membaca file dari direktori ini dan menulis informasi ringkasan tentang mereka ke direktori tujuan; ini stoknya.
Selanjutnya, mari kita cermati apa yang terjadi selama pemrosesan:
Mengubah data mentah menjadi objek:
// InputData;
DataStream<InputData> inputDataObjectStream
= dataStream
.map((MapFunction<String, InputData>) inputStr -> {
System.out.println("--- Received Record : " + inputStr);
return InputData.getDataObject(inputStr);
});
Potongan kode di bawah ini
InputData
mengubah objek aliran ( ) menjadi string dan integer tuple. Ini hanya mengekstrak bidang tertentu dari aliran objek, mengelompokkannya dengan satu bidang dalam kuanta dua detik.
//
DataStream<Tuple2<String, Integer>> userCounts
= inputDataObjectStream
.map(new MapFunction<InputData,Tuple2<String,Integer>>() {
@Override
public Tuple2<String,Integer> map(InputData item) {
return new Tuple2<String,Integer>(item.getName() ,item.getScore() );
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0) // KeyedStream<T, Tuple> ( 'name')
//.timeWindowAll(Time.seconds(windowInterval)) // timeWindowAll
.timeWindow(Time.seconds(2)) // WindowedStream<T, KEY, TimeWindow>
.reduce((x,y) -> new Tuple2<String,Integer>( x.f0+"-"+y.f0, x.f1+y.f1));
Membuat tujuan untuk streaming (mengimplementasikan data sink):
//
DataStream<Tuple2<String,Integer>> inputCountSummary
= inputDataObjectStream
.map( item
-> new Tuple2<String,Integer>
(String.valueOf(System.currentTimeMillis()),1))
// (1)
.returns(Types.TUPLE(Types.STRING ,Types.INT))
.timeWindowAll(Time.seconds(windowInterval)) //
.reduce((x,y) -> // ,
(new Tuple2<String, Integer>(x.f0, x.f1 + y.f1)));
//
final StreamingFileSink<Tuple2<String,Integer>> countSink
= StreamingFileSink
.forRowFormat(new Path(outputDir),
new SimpleStringEncoder<Tuple2<String,Integer>>
("UTF-8"))
.build();
// DataStream; inputCountSummary countSink
inputCountSummary.addSink(countSink);
Kode contoh untuk membuat data sink.
Membagi aliran (contoh # 2)
Contoh ini menunjukkan cara membagi aliran utama menggunakan aliran keluaran samping. Flink menyediakan beberapa aliran samping dari aliran utama
DataStream
. Jenis data yang terletak di setiap sisi sungai dapat berbeda dari jenis data aliran utama, serta jenis data dari setiap aliran samping.
Jadi, dengan menggunakan aliran keluaran samping, Anda dapat membunuh dua burung dengan satu batu: membagi aliran dan mengonversi jenis data aliran ke beberapa jenis data (mereka bisa unik untuk setiap aliran keluaran sisi).
Potongan kode di bawah ini memanggil
ProcessFunction
, membagi aliran menjadi dua sisi, bergantung pada properti masukan. Untuk mendapatkan hasil yang sama, kita harus menggunakan fungsi tersebut berulang kali
filter
.
Fungsi ini
ProcessFunction
mengumpulkan objek tertentu (berdasarkan kriteria) dan mengirimkannya ke header outlet utama (terletak di
SingleOutputStreamOperator
), dan sisa acara dikirim ke output samping. Aliran
DataStream
terpecah secara vertikal dan menerbitkan format yang berbeda untuk setiap aliran samping.
Perhatikan bahwa definisi keluaran sidestream didasarkan pada tag keluaran unik (objek
OutputTag
).
//
final OutputTag<Tuple2<String,String>> playerTag
= new OutputTag<Tuple2<String,String>>("player"){};
//
final OutputTag<Tuple2<String,Integer>> singerTag
= new OutputTag<Tuple2<String,Integer>>("singer"){};
// InputData .
SingleOutputStreamOperator<InputData> inputDataMain
= inputStream
.process(new ProcessFunction<String, InputData>() {
@Override
public void processElement(
String inputStr,
Context ctx,
Collector<InputData> collInputData) {
Utils.print(Utils.COLOR_CYAN, "Received record : " + inputStr);
// InputData
InputData inputData = InputData.getDataObject(inputStr);
switch (inputData.getType())
{
case "Singer":
//
ctx.output(singerTag,
new Tuple2<String,Integer>
(inputData.getName(), inputData.getScore()));
break;
case "Player":
// ;
// playerTag, (" ")
ctx.output(playerTag,
new Tuple2<String, String>
(inputData.getName(), inputData.getType()));
break;
default:
// InputData
collInputData.collect(inputData);
break;
}
}
});
Kode contoh yang mendemonstrasikan cara membagi aliran
Menggabungkan aliran (contoh # 3)
Operasi terakhir yang akan dibahas dalam artikel ini adalah rangkaian utas. Idenya adalah untuk menggabungkan dua aliran yang berbeda, yang format datanya mungkin berbeda, untuk mengumpulkan satu aliran dengan struktur data terpadu. Tidak seperti operasi gabungan dari SQL, di mana data digabungkan secara horizontal, aliran digabungkan secara vertikal, karena aliran peristiwa berlanjut dan tidak dibatasi waktu.
Aliran gabungan dilakukan dengan memanggil metode hubungkan, dan kemudian menentukan operasi tampilan untuk setiap item di setiap aliran individu. Hasilnya adalah aliran yang digabungkan.
//
ConnectedStreams<Tuple2<String, Integer>, Tuple2<String, String>> mergedStream
= singerStream
.connect(playerStream);
DataStream<Tuple4<String, String, String, Integer>> combinedStream
= mergedStream.map(new CoMapFunction<
Tuple2<String, Integer>, // 1
Tuple2<String, String>, // 2
Tuple4<String, String, String, Integer> //
>() {
@Override
public Tuple4<String, String, String, Integer> // 1
map1(Tuple2<String, Integer> singer) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: singer stream", singer.f0, "", singer.f1);
}
@Override
public Tuple4<String, String, String, Integer>
// 2
map2(Tuple2<String, String> player) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: player stream", player.f0, player.f1, 0);
}
});
Cantuman yang menunjukkan cara mendapatkan aliran gabungan
Membuat proyek kerja
Jadi, untuk rekap: proyek demo diunggah ke GitHub. Ini menjelaskan bagaimana membangun dan mengkompilasinya. Ini adalah titik awal yang baik untuk berlatih dengan Flink.
kesimpulan
Artikel ini menjelaskan operasi dasar untuk membuat aplikasi threading berbasis Flink yang berfungsi. Tujuan dari aplikasi ini adalah untuk memberikan gambaran umum tentang panggilan penting yang melekat dalam streaming dan untuk meletakkan dasar untuk pembuatan aplikasi Flink yang berfungsi penuh selanjutnya.
Karena streaming memiliki banyak segi dan kerumitan, banyak masalah dalam artikel ini yang masih belum terpecahkan; khususnya, eksekusi Flink dan manajemen tugas, pemberian tanda air saat menyetel waktu untuk streaming acara, memasukkan status ke dalam acara streaming, menjalankan iterasi streaming, menjalankan kueri seperti SQL di streaming, dan banyak lagi.
Semoga artikel ini cukup membuat Anda ingin mencoba Flink.