Kami melanjutkan topik keamanan informasi dan menerbitkan terjemahan artikel oleh Coussement Bruno.
Tambahkan noise ke data yang ada, tambahkan noise hanya ke hasil manipulasi data, atau buat data sintetis? Mari percaya pada intuisi kita?

Perusahaan tumbuh dan peraturan keamanan siber mereka menjadi lebih ketat, arsitek senior merangkul tren ... Semua ini mengarah pada fakta bahwa kebutuhan (atau kewajiban) untuk mengurangi risiko yang terkait dengan privasi dan kebocoran informasi hanya meningkat untuk subjek data.
Dalam kasus ini, metode penganoniman atau tokenizing data digunakan secara luas, meskipun metode tersebut juga memungkinkan kemungkinan pengungkapan informasi pribadi (lihat artikel ini untuk memahami mengapa hal ini terjadi).
Menghasilkan data sintetis
Data sintetis memiliki perbedaan mendasar. Tujuannya adalah untuk membuat generator data yang menunjukkan statistik global yang sama dengan data asli. Membedakan yang asli dari hasil akhir akan sulit bagi seorang model atau orang.
Mari kita ilustrasikan hal di atas dengan membuat data sintetis pada dataset Covertype menggunakan model TGAN .

Setelah melatih model pada tabel ini, saya membuat 5.000 baris dan memplot histogram kolom Ketinggian set asli dan yang dihasilkan. Tampaknya kedua garis itu bertepatan secara visual.
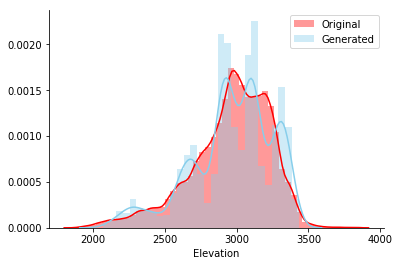
Untuk menguji hubungan antara pasangan batang, grafik berpasangan dari semua batang kontinu ditampilkan. Bentuk titik biru-hijau (dihasilkan) harus cocok secara visual dengan bentuk titik merah (asli). Dan begitulah yang terjadi, keren!

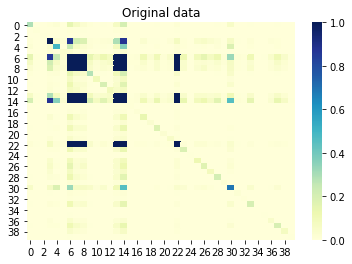
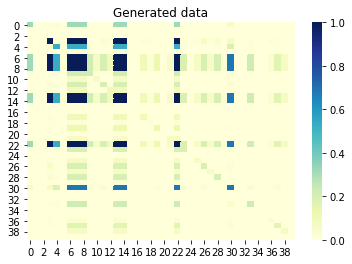
Jika sekarang kita melihat informasi timbal balik (juga dikenal sebagai korelasi tak bertanda tangan) antar kolom, maka kolom yang berkorelasi satu sama lain juga harus berkorelasi dalam kumpulan yang dihasilkan. Sebaliknya, kolom tidak berkorelasi di set asli tidak boleh berkorelasi di set yang dihasilkan. Nilai yang mendekati 0 berarti tidak ada korelasi, dan nilai yang mendekati 1 berarti korelasi sempurna. Hebat, ini!
Saling informasi antar kolom set asli:
Informasi timbal balik antara kolom yang dihasilkan set:
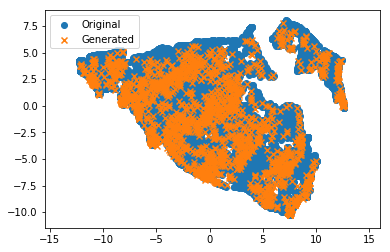
Sebagai tes akhir, saya ingin melatih metode pengurangan dimensi nonlinier ( UMAP ) pada set asli dan memproyeksikan titik asal ke dalam ruang 2D. Saya memasukkan set yang dihasilkan ke dalam proyektor yang sama. Persilangan oranye (dihasilkan) harus berada di awan titik biru dari kumpulan data asli. Dan ada! Luar biasa!
Oke, bereksperimen dengan data itu menyenangkan!
Untuk kasus yang lebih serius, ada 2 pendekatan utama:
- : , . , . .
Perlu diperhatikan inisiatif seperti Synthetic data vault , Gretel.AI , Mostly.ai , MDClone , Hazy .
Hari ini Anda dapat menulis bukti konsep menggunakan data sintetis untuk memecahkan salah satu masalah umum berikut yang dihadapi oleh organisasi TI:
- Tidak ada muatan di lingkungan pengembangan
Katakanlah Anda sedang mengerjakan produk data (bisa apa saja) di mana data yang Anda minati berada dalam lingkungan produksi dengan kebijakan akses yang sangat ketat. Sayangnya, Anda hanya memiliki akses ke lingkungan pengembangan tanpa data yang menarik.
- Mode Dewa - Hak Akses untuk Insinyur dan Ilmuwan Data
Katakanlah Anda seorang ilmuwan data dan tiba-tiba seorang petugas keamanan informasi membatasi hak istimewa Anda yang sangat dibutuhkan untuk mengakses data produksi. Bagaimana Anda bisa terus bekerja dengan baik di lingkungan yang sulit dan terbatas seperti itu?
- Transfer data sensitif ke mitra eksternal yang tidak tepercaya
Anda adalah bagian dari Perusahaan X. Organisasi Y ingin menampilkan produk data keren terbaru mereka (bisa apa saja).
Mereka meminta Anda untuk mengekstrak data untuk menunjukkan produk kepada Anda.
Apa hubungan data sintetis dengan privasi diferensial?
Properti utama pembuatan data sintetik adalah, terlepas dari pasca-pemrosesan atau penambahan informasi pihak ketiga, tidak ada yang akan dapat mengetahui apakah suatu objek terdapat dalam kumpulan asli, dan juga tidak akan bisa mendapatkan properti objek ini. Properti ini adalah bagian dari konsep yang lebih luas yang disebut "privasi diferensial" (DP).
Privasi diferensial global dan lokal
DP dibagi menjadi 2 jenis.
Seringkali, hanya hasil dari tugas tertentu yang menarik (misalnya, melatih model berdasarkan data pasien yang dirahasiakan dari rumah sakit yang berbeda, menghitung jumlah rata-rata orang yang pernah melakukan kejahatan, dll.), Maka perhatian harus diberikan pada privasi diferensial global.
Dalam kasus ini, pengguna yang tidak dipercaya tidak akan pernah melihat data rahasia. Sebaliknya, dia memberi tahu kurator tepercaya (dengan mekanisme privasi diferensial global) yang memiliki akses ke data sensitif operasi apa yang harus dilakukan.
Hanya hasilnya yang dilaporkan ke pengguna yang tidak tepercaya. Saya merekomendasikan Pysyftdan OpenDP jika Anda memerlukan informasi lebih lanjut tentang alat serupa.
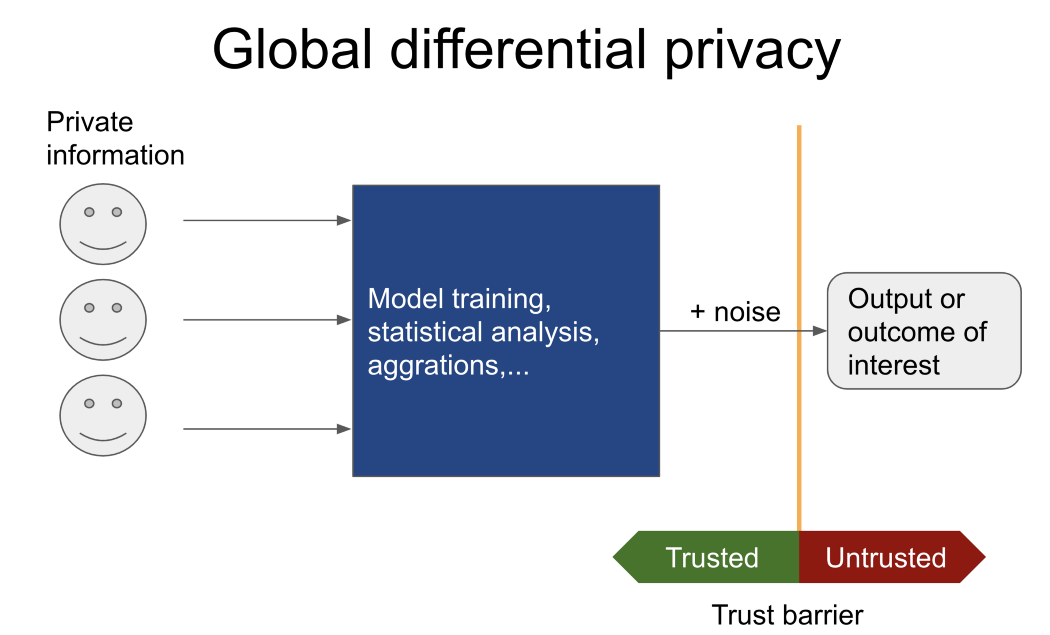
Sebaliknya, jika data akan ditransfer ke pihak yang tidak tepercaya, prinsip kerahasiaan diferensial lokal mulai berlaku. Secara tradisional, ini dilakukan dengan menambahkan noise ke setiap baris dalam tabel atau database. Jumlah kebisingan tambahan tergantung pada:
- tingkat kerahasiaan yang diperlukan (epsilon terkenal dalam literatur DP),
- ukuran kumpulan data (kumpulan data yang lebih besar membutuhkan lebih sedikit noise untuk mencapai tingkat kerahasiaan yang sama),
- tipe data kolom (kuantitatif, kategorikal, ordinal).

Secara teori, untuk tingkat kerahasiaan yang sama, mekanisme DP global (menambahkan derau pada hasil) akan memberikan hasil yang lebih akurat daripada mekanisme lokal (derau tingkat jalur).
Dengan demikian, metode pembuatan data sintetis dapat dianggap sebagai bentuk DP lokal.
Untuk informasi lebih lanjut tentang topik ini, saya menyarankan Anda untuk berkonsultasi dengan sumber berikut:
- www.udacity.com/course/secure-and-private-ai--ud185
- medium.com/@arbidha1412/local-and-global-differential-privacy-249aaa3571
- www.openmined.org
Rekomendasi
Sekarang mari kita lihat contoh yang lebih spesifik. Anda ingin berbagi spreadsheet yang berisi informasi pribadi dengan pihak yang tidak dipercaya.
Saat ini, Anda dapat menambahkan derau ke jalur data yang ada (DP lokal), menyiapkan dan menggunakan sistem yang kuat (DP global), atau membuat data sintetis berdasarkan aslinya.
Kebisingan harus ditambahkan ke jalur data yang ada jika
- Anda tidak tahu operasi apa yang akan dilakukan pada data setelah publikasi,
- Anda perlu membagikan pembaruan ke data asli secara berkala (= memiliki alur kerja ini sebagai bagian dari proses batch yang stabil),
- Anda dan pemilik data mempercayai orang / tim / organisasi untuk menambahkan kebisingan ke data asli.
Di sini saya merekomendasikan memulai dengan alat OpenDP .
Kasus privasi diferensial yang paling terkenal ada di Sensus Amerika Serikat (lihat databricks.com/session_na20/using-apache-spark-and-differential-privacy-for-protecting-the-privacy-of-the-2020-census-respondents ).
Data ini dihitung ulang dan diperbarui setiap tiga tahun. Sebagian besar merupakan data numerik yang dikumpulkan dan dipublikasikan di berbagai tingkat (kabupaten, negara bagian, tingkat nasional).
Instal dan gunakan sistem tepercaya jika
- sistem yang Anda tentukan mendukung tugas dan operasi yang akan dilakukan padanya,
- data dasar disimpan di tempat yang berbeda dan tidak dapat meninggalkannya (misalnya, di rumah sakit yang berbeda),
- Anda dan pemilik data benar-benar mempercayai sistem saat ini dan orang / tim / organisasi yang menyiapkannya.
Sebagai pengguna data sensitif, Anda akan mendapatkan hasil yang lebih akurat daripada pendekatan pertama.
Banyak kerangka kerja saat ini tidak memiliki semua fitur yang diperlukan untuk menerapkan binatang ini dengan cara yang aman, dapat diskalakan, dan dapat diaudit. Masih banyak pekerjaan teknik yang dibutuhkan di sini.
Namun seiring pertumbuhan adopsi mereka, DP dapat menjadi alternatif yang baik untuk organisasi dan bisnis besar.
Saya sarankan memulai di sini dengan OpenMined .
Dimungkinkan untuk menghasilkan data sintetis jika
- (<1 , <100 ),
- ad-hoc ( ),
- / / , .
Seperti percobaan kecil yang dijelaskan di atas, hasilnya menjanjikan. Ini juga tidak membutuhkan pengetahuan yang sangat baik tentang sistem DP. Anda dapat mulai hari ini, jika perlu, biarkan berlatih semalaman dan, boleh dikatakan, persiapkan perangkat sintetis bersama untuk besok pagi.
Kekurangan terbesar adalah model yang kompleks ini dapat menjadi mahal untuk dilatih dan dipelihara jika jumlah datanya meningkat. Setiap tabel juga memerlukan pelatihan model lengkapnya sendiri (pelatihan portabel tidak akan berfungsi di sini). Anda tidak akan dapat menskalakan hingga ratusan tabel bahkan dengan anggaran komputasi yang signifikan.
Jika tidak, Anda kurang beruntung.
Kesimpulan
Karena privasi data lebih penting sekarang daripada sebelumnya, kami memiliki metode yang sangat baik untuk menghasilkan data sintetis atau untuk menambahkan gangguan ke data yang ada. Namun, mereka semua masih memiliki keterbatasan. Terlepas dari beberapa kasus khusus, alat tingkat perusahaan yang dapat diskalakan dan fleksibel belum dibuat yang akan memungkinkan data yang berisi informasi pribadi untuk ditransfer ke pihak yang tidak tepercaya.
Pemilik data masih perlu mempercayai metode atau sistem yang sudah mapan, yang membutuhkan banyak kepercayaan dari mereka. Ini masalah terbesar!
Sementara itu, jika Anda ingin mencobanya (bukti konsep, coba saja), buka salah satu tautan di atas.