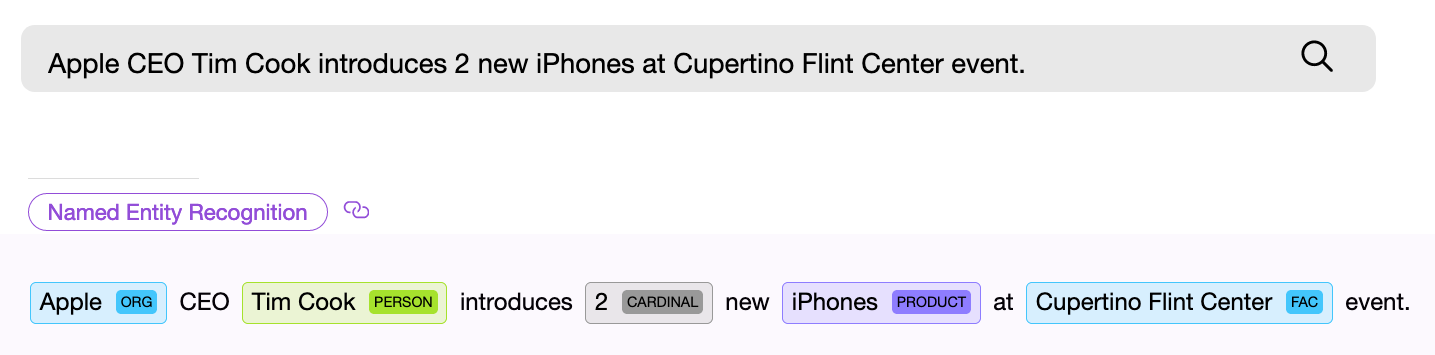
Komponen NER (pengenalan entitas), yaitu komponen perangkat lunak untuk mencari entitas bernama, harus menemukan objek dalam teks dan, jika memungkinkan, mendapatkan beberapa informasi darinya. Contoh - "Beri aku dua puluh dua topeng." Komponen NER numerik menemukan frase "dua puluh dua" dalam teks yang diberikan dan mengekstrak dari kata-kata ini nilai numerik yang dinormalisasi - " 22 ", sekarang nilai ini dapat digunakan.
Komponen NER dapat didasarkan pada jaringan saraf atau bekerja berdasarkan aturan dan model internal apa pun. Komponen NER generik sering menggunakan metode kedua.
Mari pertimbangkan beberapa solusi siap pakai untuk menemukan entitas standar dalam teks. Pada artikel ini, kami akan fokus pada perpustakaan gratis atau gratis dengan batasan, dan juga berbicara tentang apa yang telah dilakukan dalam proyek Apache NlpCraft dalam kerangka masalah ini. Daftar di bawah ini bukanlah gambaran umum yang mendetail dan mendetail, yang jumlahnya sudah mencukupi di jaringan, tetapi lebih merupakan penjelasan singkat tentang fitur utama, pro dan kontra penggunaan library ini.
Penyedia komponen NER
Apache OpenNlp
Apache OpenNlp menyediakan sekumpulan komponen NER yang cukup standar untuk bahasa Inggris, yang berhubungan dengan tanggal, waktu, geografi, organisasi, persentase numerik, dan orang. Satu set kecil juga tersedia untuk bahasa lain (Spanyol, Belanda).
Pengiriman:
perpustakaan Java. Apache OpenNlp tidak mengirimkan model dengan proyek utama. Mereka tersedia untuk diunduh secara terpisah.
Kelebihan:
Lisensi Apache. Model telah diuji dalam banyak implementasi.
Minus:
Rupanya, model tersebut dihapus dari proyek utama karena suatu alasan. Orang mendapat kesan bahwa pengerjaannya dihentikan atau berjalan dengan kecepatan santai yang menyedihkan, karena model baru atau perubahan pada model yang sudah ada belum terlihat selama beberapa waktu. Karena pengguna Apache OpenNlp dapat membuat dan melatih model mereka sendiri, mungkin saja tugas ini sepenuhnya diserahkan kepada mereka.
Stanford Nlp
Stanford NLP adalah produk yang hidup, terus berkembang dengan kualitas luar biasa dan kemungkinan besar. Untuk bahasa Inggris, menambahkan dukungan untuk mengenali entitas berikut: orang, lokasi, organisasi, misc, uang, angka, ordinal, persen, tanggal, waktu, durasi, set. Selain itu, komponen NER Regex bawaan memungkinkan Anda menemukan entitas dengan tingkat akurasi yang tinggi seperti: email, url, kota, negara bagian, negara, kebangsaan, agama, jabatan (pekerjaan), ideologi, biaya_kriminal, penyebab_ kematian, pegangan. Detail lebih lanjut tentang tautan . Dukungan NER terbatas untuk bahasa Jerman, Spanyol, dan China diumumkan. Kualitas pengenalan dapat diuji menggunakan demo online .
Pasokan:
Perpustakaan Java. Model dapat diunduh dari pakar bersama dengan proyek.
Saya belum menemukan di mana pun daftar dan penjelasan rinci tentang komponen NER untuk bahasa selain bahasa Inggris. Tautan 1 , 2 - contoh proses pelatihan komponen NER Anda sendiri untuk bahasa yang berbeda diberikan. Sederhananya, kemampuan untuk menggunakan bahasa lain diumumkan, tetapi Anda harus mengotak-atik.
Kelebihan:
Perasaan dari bekerja dengan proyek secara keseluruhan dan dengan model siap pakai adalah yang paling positif, proyek hidup dan berkembang, kualitas pengakuan baik ("baik" adalah konsep bersyarat, ada metrik yang mencirikan kualitas pengenalan komponen NER, tetapi masalah ini berada di luar cakupan artikel).
Minus:
Terlepas dari beberapa kekacauan dengan dokumen, mereka kecil. Kepada siapa penting, perhatikan lisensi. Lisensi Publik Umum GNU berbeda dengan Apache , jadi, misalnya, Anda tidak dapat menambahkan produk dengan lisensi ini ke produk berlisensi di bawah Apache, dll.
API Bahasa Google
API bahasa Google untuk bahasa Inggris mendukung daftar entitas berikut: orang, lokasi, organisasi, acara, work_of_art, consumer_good, other, phone_number, address, date, number, price.
Platform:
REST API, SaaS. Library klien siap pakai melalui REST tersedia (Java, C #, Python, Go, dll.).
Kelebihan:
Sekumpulan besar komponen, pengembangan, dan kualitas NER disediakan oleh raksasa Internet terkenal.
Kekurangan:
Mulai dari volume tertentu, pakai berbayar .
Spacy
Pustaka ini menyediakan salah satu kumpulan entitas terluas yang didukung untuk pengenalan, lihat tautan untuk daftar yang didukung.
Platform:
Python.
Sayangnya, kurangnya pengalaman pribadi penggunaan industri tidak memungkinkan saya untuk menambahkan gambaran nyata tentang pro dan kontra dari perpustakaan ini. Selain itu, gambaran umum mendetail tentang solusi Python NLP telah dipublikasikan di habr.
Semua pustaka di atas memungkinkan Anda melatih model Anda sendiri. Selain itu, semuanya (kecuali Apache OpenNlp) memungkinkan Anda mengekstrak nilai yang dinormalisasi dari entitas yang ditemukan, yaitu, misalnya, mendapatkan nomor "173" dari entitas numerik "seratus tujuh puluh tiga" yang ditemukan dalam kueri.
Seperti yang dapat kita lihat, ada banyak opsi untuk memecahkan masalah menemukan entitas bernama, arah perkembangannya jelas - memperluas daftar bahasa yang didukung dan sekumpulan entitas yang diakui, meningkatkan kualitas pengenalan.
Di bawah ini adalah ringkasan dari apa yang telah dibawa oleh proyek Apache NlpCraft ke area yang sudah sangat berkembang ini.
Fitur tambahan disediakan oleh NlpCraft
- Komponen NER asli untuk entitas baru, solusi yang lebih baik untuk beberapa yang sudah ada.
- Integrasi komponen NER dari semua pustaka di atas dalam kerangka penggunaan produk.
- Dukungan untuk "entitas gabungan", yang memungkinkan pengguna dengan mudah membuat komponen khusus baru dari yang sudah ada.
Sekarang tentang semua ini dengan sedikit lebih detail.
Komponen NER eksklusif
Komponen NER asli Apache NlpCraft adalah komponen untuk mengenali tanggal, angka, geografi, koordinat, pengurutan, dan pencocokan entitas yang berbeda. Beberapa di antaranya unik, beberapa hanya implementasi yang lebih baik dari solusi yang ada (akurasi pengenalan telah ditingkatkan, bidang nilai tambahan telah ditambahkan, dll.).
Integrasi solusi yang ada
Semua solusi di atas terintegrasi untuk digunakan dengan Apache NlpCraft.
Saat bekerja dengan sebuah proyek, pengguna hanya perlu menghubungkan modul yang diperlukan dan menentukan dalam konfigurasi komponen NER mana yang harus digunakan ketika mencari entitas dari model tertentu.
Di bawah ini adalah contoh konfigurasi yang menggunakan empat komponen NER berbeda dari dua penyedia saat menelusuri teks:
"enabledBuiltInTokens": [
"nlpcraft:num",
"nlpcraft:coordinate",
"google:organization",
"google:phone_number"
]
Baca lebih lanjut tentang menggunakan Apache NlpCraft di sini . Akun pengembang Google yang valid diperlukan untuk menggunakan API Bahasa Google.
Dukungan entitas komposit
Dukungan untuk entitas komposit adalah yang paling menarik dari fitur di atas, mari kita bahas lebih detail.
Entitas gabungan adalah entitas yang ditentukan atas dasar entitas lain. Mari kita lihat contohnya. Misalkan Anda mengembangkan sistem kontrol NLP berbasis maksud (lihat Alexa , Google Dialogflow , Alice , Apache Nlpraft , dll.), Dan model Anda berfungsi dengan geografi, tetapi hanya untuk Amerika Serikat. Anda dapat menggunakan komponen pencarian geografi seperti " nlpcraft: city " dan menggunakannya secara langsung.
Selanjutnya, saat maksud dipicu, dalam fungsi yang sesuai (callback), Anda harus memeriksa nilai bidang " negara ", dan jika tidak memenuhi kondisi yang diperlukan, hentikan fungsinya, mencegah pemicuan salah. Selanjutnya, Anda harus kembali ke pencocokan dan mencoba memilih fungsi lain yang lebih sesuai.
Apa yang salah dengan pendekatan ini:
- Anda membuatnya jauh lebih sulit untuk bekerja dengan fungsi yang dipanggil dengan mentransfer kontrol dari mereka ke thread pekerja utama dan sebaliknya. Selain itu, perlu dipertimbangkan bahwa tidak semua sistem dialog memiliki fungsi transfer kontrol seperti itu.
- Anda mencoreng logika yang cocok antara maksud dan kode metode yang dapat dieksekusi.
Oke ... Anda dapat membuat komponen NER Anda sendiri dari awal untuk menemukan kota-kota di Amerika, tetapi tugas ini tidak diselesaikan dalam lima menit.
Mari kita coba secara berbeda. Anda bisa memperumit maksud (dalam sistem tersebut jika memungkinkan) dan mencari kota yang juga difilter menurut negara. Tapi, saya ulangi, tidak semua sistem memberikan kemungkinan pemfilteran kompleks berdasarkan bidang elemen, selain itu, Anda memperumit maksud, yang harus sejelas dan sesederhana mungkin, terutama jika jumlahnya banyak dalam proyek.
Apache NlpCraft menyediakan mekanisme untuk menentukan komponen NER asli berdasarkan yang sudah ada. Di bawah ini adalah contoh konfigurasi (sintaks DSL lengkap tersedia di sini , contoh pembuatan elemen ada di sini):
"elements": [
{
"id": "custom:city:usa",
"description": "Wrapper for USA cities",
"synonyms": [
"^^id == 'nlpcraft:city' && lowercase(~city:country) == 'usa')^^"
]
}
]
Dalam contoh ini, kami mendeskripsikan entitas bernama baru "kota Amerika" - " custom: city: usa ", berdasarkan " nlpcraft: city " yang ada, difilter menurut kriteria tertentu.
Sekarang Anda dapat membuat maksud berdasarkan elemen baru yang dibuat, dan kota di luar Amerika Serikat yang ditemui dalam teks tidak akan menyebabkan pemicu yang tidak diinginkan pada maksud Anda.
Contoh lain:
"macros": [
{
"name": "<AIRPORT>",
"macro": "{airport|aerodrome|airdrome|air station}"
}
],
"elements": [
{
"id": "custom:airport:usa",
"description": "Wrapper for USA airports",
"synonyms": [
"<AIRPORT> {of|for|*} ^^id == 'nlpcraft:city' &&
lowercase(~city:country) == 'usa')^^"
]
}
]
Dalam contoh ini, kami telah menentukan entitas bernama "bandara kota di AS" - " custom: airport: usa ". Saat mendefinisikan elemen ini, kami tidak hanya menyaring kota-kota menurut afiliasi negara bagian mereka, tetapi juga menetapkan aturan tambahan yang menurutnya nama kota harus diawali dengan sinonim apa pun yang mendefinisikan konsep "bandara". (Baca lebih lanjut tentang membuat sinonim elemen melalui makro - di sini ).
Elemen komposit dapat ditentukan dengan tingkat penumpukan apa pun, yaitu, jika perlu, Anda dapat mendesain elemen baru berdasarkan " custom: airport: usa " yang baru dibuat ". Perhatikan juga bahwa semua nilai entitas induk yang dinormalisasi, dalam hal ini elemen nlpcraft: city dasar , juga tersedia dalam elemen custom: airport: usa , dan bisa digunakan dalam badan fungsi dari maksud yang dipicu.
Tentu saja, "blok penyusun" dapat didefinisikan tidak hanya untuk semua komponen standar yang didukung dari OpenNlp, Stanford, Google, Spacy dan NlpCraft, tetapi juga untuk komponen NER kustom, memperluas kemampuannya dan memungkinkan Anda untuk menggunakan kembali pengembangan perangkat lunak yang ada.
Harap diperhatikan, pada kenyataannya, Anda tidak membuat komponen baru untuk setiap tugas baru, tetapi cukup konfigurasikan atau "gabungkan" fungsinya ke dalam elemen Anda sendiri.
Jadi, dengan menggunakan "entitas gabungan", pengembang dapat:
- Sederhanakan logika untuk membuat maksud secara signifikan dengan mentransfernya sebagian ke blok penyusun yang dapat digunakan kembali.
- Dapatkan komponen NER dengan perilaku baru menggunakan perubahan konfigurasi tanpa pelatihan atau pengkodean model.
- Gunakan kembali solusi yang sudah jadi dengan kualitas yang diharapkan, dengan mengandalkan pengujian atau metrik yang ada.
Kesimpulan
Saya berharap ikhtisar singkat tentang pro dan kontra dari komponen NER yang ada akan berguna bagi pembaca, dan memahami bagaimana Apache NlpCraft dapat secara signifikan memperluas kemampuan mereka dan menyesuaikan solusi yang ada untuk tugas baru akan mempercepat pengembangan proyek Anda.