Salah satu aspek sisi pengembangan perangkat lunak ini adalah lisensi kode. Bagi beberapa pengembang, perizinan tampak seperti hutan yang agak gelap, mereka mencoba untuk tidak masuk ke dalamnya dan tidak memahami perbedaan dan aturan lisensi secara umum, atau mereka tahu tentang mereka secara dangkal, itulah sebabnya mereka dapat melakukan berbagai jenis pelanggaran. Pelanggaran yang paling umum terjadi adalah penyalinan (penggunaan kembali) dan modifikasi kode yang melanggar hak pembuatnya.
Bantuan apa pun kepada orang-orang dimulai dengan meneliti situasi saat ini - pertama, pengumpulan data diperlukan untuk kemungkinan otomatisasi lebih lanjut, dan kedua, analisis mereka akan memungkinkan kita untuk mengetahui apa sebenarnya kesalahan yang dilakukan orang. Pada artikel ini, saya akan menjelaskan studi seperti itu: Saya akan memperkenalkan Anda pada jenis-jenis utama lisensi perangkat lunak (serta beberapa yang langka, tetapi penting), saya akan berbicara tentang menganalisis kode dan menemukan pinjaman dalam sejumlah besar data, dan memberikan saran tentang cara menangani lisensi dengan benar dalam kode. dan hindari kesalahan umum.
Pengantar lisensi kode
Di Internet, dan bahkan di Habré , sudah ada deskripsi rinci tentang lisensi, jadi kami akan membatasi diri kami hanya pada tinjauan singkat tentang topik yang diperlukan untuk memahami esensi penelitian.
Kami hanya akan berbicara tentang pelisensian perangkat lunak sumber terbuka . Pertama, ini disebabkan oleh fakta bahwa dalam paradigma inilah kita dapat dengan mudah menemukan banyak data yang tersedia, dan kedua, istilah "perangkat lunak open source"bisa menyesatkan. Saat Anda mengunduh dan menginstal program kepemilikan umum dari situs web perusahaan, Anda akan diminta untuk menyetujui persyaratan lisensinya. Tentu saja biasanya Anda tidak membacanya, tetapi secara umum Anda paham bahwa ini adalah kekayaan intelektual seseorang. Pada saat yang sama, ketika pengembang membuka sebuah proyek di GitHub dan melihat semua file sumber, sikap terhadapnya sangat berbeda: ya, ada semacam lisensi di sana, tetapi ini adalah sumber terbuka , dan perangkat lunaknya adalah sumber terbuka , yang berarti Anda dapat mengambil dan lakukan apa yang kamu inginkan, bukan? Sayangnya, tidak semuanya sesederhana itu.
Bagaimana cara kerja lisensi? Mari kita mulai dengan pembagian hak yang paling umum:
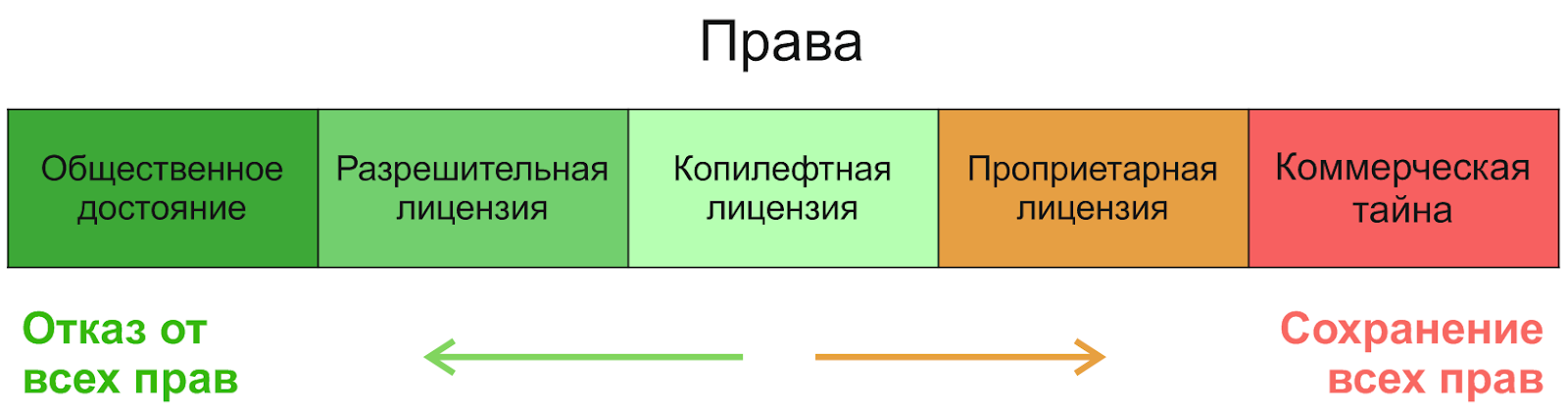
Jika Anda pergi dari kanan ke kiri, maka yang pertama akan menjadi rahasia komersial, diikuti oleh lisensi kepemilikan - kami tidak akan mempertimbangkannya. Dalam bidang perangkat lunak open source, tiga kategori dapat dibedakan (menurut derajat peningkatan kebebasan): lisensi restriktif ( copyleft ), lisensi non-restriktif ( permisif , permisif) dan domain publik.(yang bukan merupakan lisensi, tetapi cara memberikan hak). Untuk memahami perbedaan di antara mereka, akan sangat membantu untuk mengetahui mengapa mereka bahkan muncul. Konsep domain publik sama tuanya dengan dunia - pencipta sepenuhnya menolak hak apa pun dan mengizinkannya melakukan apa pun yang dia inginkan dengan produknya. Namun, anehnya, dari kebebasan inilah lahir ketidakbebasan - lagipula, orang lain bisa mengambil ciptaan seperti itu, sedikit mengubahnya dan melakukan “apa saja” dengannya - termasuk menutup dan menjualnya. Lisensi copyleft open source dibuat secara tepat untuk melindungi kebebasan - dari posisinya dalam gambar, Anda dapat melihat bahwa lisensi tersebut dimaksudkan untuk menjaga keseimbangan: untuk memungkinkan penggunaan, perubahan, dan distribusi produk, tetapi tidak untuk menguncinya, untuk membiarkannya gratis. Selain itu, meskipun penulis tidak keberatan dengan skenario tutup dan jual,konsep domain publik berbeda dari satu negara ke negara lain dan oleh karena itu dapat menimbulkan komplikasi hukum. Untuk menghindarinya, lisensi permisif sederhana digunakan.
Jadi apa perbedaan antara lisensi permisif dan copyleft? Seperti semua hal lain dalam topik kita, pertanyaan ini cukup spesifik, dan ada pengecualian, tetapi jika Anda menyederhanakan, maka lisensi permisif tidak memberlakukan pembatasan pada lisensi produk yang dimodifikasi. Artinya, Anda dapat mengambil produk seperti itu, mengubahnya, dan memasukkannya ke dalam proyek di bawah lisensi yang berbeda - bahkan yang berpemilik. Perbedaan utama dari domain publik di sini paling sering adalah kewajiban untuk mempertahankan kepenulisan dan menyebutkan penulis asli. Lisensi permisif yang paling terkenal adalah lisensi MIT, BSD, dan Apache .... Banyak penelitian menunjuk MIT sebagai lisensi open source yang paling banyak digunakan secara umum, dan juga mencatat pertumbuhan yang signifikan dalam popularitas lisensi Apache-2.0 sejak dimulainya pada tahun 2004 (misalnya, studi untuk Java ).
Lisensi Copyleft paling sering memberlakukan pembatasan pada distribusi dan modifikasi produk sampingan - Anda menerima produk dengan hak tertentu, dan Anda harus "menjalankannya lebih jauh", memberikan hak yang sama kepada semua pengguna. Ini biasanya berarti kewajiban untuk mendistribusikan ulang perangkat lunak di bawah lisensi yang sama dan memberikan akses ke kode sumber. Berdasarkan filosofi ini, Richard Stallman menciptakan lisensi copyleft pertama dan paling populer, GNU General Public License (GPL). Dialah yang memberikan perlindungan kebebasan maksimum untuk pengguna dan pengembang di masa depan. Saya merekomendasikan membaca sejarah gerakan Richard Stallman untuk perangkat lunak gratis, itu sangat menarik.
Ada satu kesulitan dengan lisensi copyleft - lisensi secara tradisional dibagi menjadi copyleft yang kuat dan yang lemah . Copyleft yang kuat persis seperti yang dijelaskan di atas, sementara copyleft yang lemah memberikan berbagai konsesi dan pengecualian untuk pengembang. Contoh paling terkenal dari lisensi semacam itu adalah GNU Lesser General Public License (LGPL): seperti versi sebelumnya, Anda dapat mengubah dan mendistribusikan kembali kode hanya jika Anda tetap menggunakan lisensi ini, tetapi saat menautkan secara dinamis (menggunakannya sebagai pustaka dalam aplikasi), persyaratan ini dapat dihilangkan. Dengan kata lain, jika Anda ingin meminjam kode sumber dari sini atau mengubah sesuatu, amati copyleft, tetapi jika Anda hanya ingin menggunakannya sebagai pustaka tautan dinamis, Anda dapat melakukannya di mana saja.
Sekarang kita telah menemukan lisensi itu sendiri, kita harus berbicara tentang kompatibilitasnya , karena di dalamnya (atau lebih tepatnya, ketidakhadirannya) bahwa pelanggaran yang ingin kita cegah adalah kebohongan. Siapapun yang pernah tertarik dengan topik ini seharusnya menemukan skema kompatibilitas lisensi yang mirip dengan ini:

Dari sekilas skema semacam itu, keinginan untuk memahami lisensi bisa hilang. Memang ada banyak lisensi open source , daftar yang cukup lengkap bisa ditemukan, misalnya di sini . Pada saat yang sama, seperti yang akan Anda lihat di bawah dalam hasil studi kami, Anda perlu mengetahui jumlah yang sangat terbatas (karena distribusinya yang sangat tidak merata), dan bahkan lebih sedikit aturan yang perlu diingat untuk mematuhi semua ketentuannya. Vektor umum dari skema ini cukup sederhana: sumber semuanya adalah domain publik, di belakangnya adalah lisensi permisif, lalu copyleft yang lemah, dan terakhir, copyleft yang kuat, dan lisensinya kompatibel "benar": dalam proyek copyleft, Anda dapat menggunakan kembali kode di bawah lisensi permisif, tetapi tidak sebaliknya - semuanya logis.
Di sini mungkin timbul pertanyaan: bagaimana jika kode tersebut tidak memiliki lisensi? Aturan apa yang harus diikuti? Bisakah kode ini disalin? Ini sebenarnya pertanyaan yang sangat penting. Mungkin, jika kode itu ditulis di pagar, maka itu bisa dianggap domain publik, dan jika ditulis di atas kertas dalam botol, yang dipaku di pulau terpencil (tanpa hak cipta), maka kode itu bisa diambil dan digunakan begitu saja. Ketika datang ke platform besar dan mapan seperti GitHub atau StackOverflow, semuanya tidak sesederhana itu, karena hanya dengan menggunakannya, Anda secara otomatis menyetujui persyaratan penggunaannya. Untuk saat ini, mari kita tinggalkan catatan tentang ini di kepala kita dan kembali lagi nanti - pada akhirnya, mungkin ini jarang terjadi dan praktis tidak ada kode tanpa lisensi?
Pernyataan masalah dan metodologi
Jadi, sekarang setelah kita mengetahui arti semua istilah, mari kita perjelas tentang apa yang ingin kita ketahui.
- Seberapa umum penyalinan kode di perangkat lunak open source? Apakah ada banyak klon dalam kode di antara proyek sumber terbuka ?
- Lisensi apa yang ada di bawah? Lisensi apa yang paling umum? Apakah file berisi banyak lisensi sekaligus?
- Apa kemungkinan pinjaman yang paling umum, yaitu transfer kode dari satu lisensi ke lisensi lainnya?
- Apa kemungkinan pelanggaran yang paling umum, yaitu, transisi kode yang dilarang oleh persyaratan asli atau lisensi penerima?
- Apa kemungkinan asal dari setiap fragmen kode? Seberapa besar kemungkinan potongan kode ini disalin dengan melanggar?
Untuk melakukan analisis seperti itu, kami membutuhkan:
- Buat kumpulan data dari sejumlah besar proyek sumber terbuka.
- Temukan klon potongan kode di antara mereka.
- Identifikasi klon yang benar-benar dapat dipinjam.
- Untuk setiap fragmen kode, tentukan dua parameter - lisensinya dan waktu modifikasi terakhirnya, yang diperlukan untuk mengetahui fragmen mana dalam sepasang klon yang lebih tua dan mana yang lebih muda, dan karenanya - siapa yang berpotensi menyalin dari siapa.
- Tentukan kemungkinan transisi antara lisensi yang diizinkan dan mana yang tidak.
- Analisis semua data yang diperoleh untuk menjawab pertanyaan di atas.
Sekarang mari kita lihat lebih dekat setiap langkah.
Pengumpulan data
Sangat nyaman bagi kami karena saat ini mudah untuk mengakses banyak open source menggunakan GitHub. Ini tidak hanya berisi kode itu sendiri, tetapi juga sejarah perubahannya, yang sangat penting untuk studi ini: untuk mengetahui siapa yang dapat menyalin kode dari siapa, Anda perlu tahu kapan setiap fragmen ditambahkan ke proyek.
Untuk mengumpulkan data, Anda perlu memutuskan bahasa pemrograman yang dipelajari. Faktanya adalah bahwa klon dicari dalam kerangka satu bahasa pemrograman: berbicara tentang pelanggaran lisensi, lebih sulit untuk menilai penulisan ulang algoritma yang ada ke bahasa lain. Konsep rumit seperti itu dilindungi oleh paten, sementara dalam penelitian kami, kami berbicara tentang penyalinan dan modifikasi yang lebih umum. Kami memilih Java karena ini adalah salah satu bahasa yang paling banyak digunakan dan terutama populer dalam pengembangan perangkat lunak komersial - dalam hal ini potensi pelanggaran lisensi sangat penting.
Kami mengambil Public Git Archive yang ada sebagai dasar, yang pada awal tahun 2018 mempertemukan semua project di GitHub yang memiliki lebih dari 50 bintang. Kami telah memilih semua proyek yang memiliki setidaknya satu baris di Java dan mengunduhnya dengan riwayat perubahan yang lengkap. Setelah memfilter proyek yang telah dipindahkan atau tidak lagi tersedia, ada 23.378 proyek yang menghabiskan sekitar 1,25 TB ruang hard disk.
Selain itu, untuk setiap proyek, kami membuang daftar garpu dan menemukan pasangan garpu di dalam kumpulan data kami - ini diperlukan untuk pemfilteran lebih lanjut, karena kami tidak tertarik pada klon antar-fork. Ada total 324 proyek dengan garpu di dalam kumpulan data.
Menemukan klon
Untuk menemukan klon, yaitu potongan kode yang serupa, Anda juga perlu membuat beberapa keputusan. Pertama, kita perlu memutuskan berapa banyak dan dalam kapasitas apa kita tertarik dengan kode serupa. Secara tradisional, ada 4 jenis klon (dari yang paling akurat hingga yang paling tidak akurat):
- Klon identik adalah potongan kode yang persis sama yang hanya dapat berbeda dalam keputusan gaya, seperti indentasi, baris kosong, dan komentar.
- Klon yang diganti namanya mencakup tipe pertama, tetapi mungkin juga berbeda dalam nama variabel dan objek.
- Tutup klon mencakup semua hal di atas, namun dapat berisi perubahan yang lebih signifikan, seperti menambah, menghapus atau ekspresi, di mana fragmen masih sama bergerak.
- , — , ( ), ().
Kami tertarik untuk menyalin dan memodifikasi, jadi kami hanya mempertimbangkan klon dari tiga jenis pertama.
Keputusan penting kedua adalah ukuran klon apa yang harus dicari. Fragmen kode identik dapat dicari di antara file, kelas, metode, ekspresi individu ... Dalam pekerjaan kami, kami mengambil metode sebagai dasar , karena ini adalah perincian pencarian yang paling seimbang: seringkali orang menyalin kode tidak di seluruh file, tetapi dalam fragmen kecil, tetapi pada saat yang sama metode - itu masih merupakan unit logis yang lengkap.
Berdasarkan solusi yang dipilih, untuk menemukan klon, kami menggunakan SourcererCC - alat yang mencari klon menggunakan metode bag of words: setiap metode direpresentasikan sebagai daftar frekuensi token (kata kunci, nama, dan literal), setelah itu set tersebut dibandingkan, dan jika lebih dari proporsi token tertentu dalam dua metode bertepatan (proporsi ini disebut ambang kesamaan), maka pasangan semacam itu dianggap klon. Terlepas dari kesederhanaan metode ini (ada metode yang jauh lebih kompleks berdasarkan analisis pohon sintaks metode dan bahkan grafik ketergantungan programnya), keuntungan utamanya adalah skalabilitas : dengan kode dalam jumlah besar, seperti milik kami, pencarian klon harus dilakukan dengan sangat cepat. ...
Kami menggunakan ambang kesamaan yang berbeda untuk menemukan klon yang berbeda, dan juga secara terpisah melakukan pencarian dengan ambang kesamaan 100%, di mana hanya klon identik yang diidentifikasi. Selain itu, ukuran metode minimum yang diselidiki ditetapkan untuk membuang potongan kode yang sepele dan umum yang mungkin tidak dapat dipinjam.
Pencarian ini memakan waktu 66 hari perhitungan terus menerus, 38,6 juta metode diidentifikasi, di mana hanya 11,7 juta yang melewati ambang batas ukuran minimum, dan 7,6 juta di antaranya mengambil bagian dalam kloning. Sebanyak 1,2 miliar pasang klon ditemukan.
Waktu modifikasi terakhir
Untuk analisis lebih lanjut, kami hanya memilih pasangan klon lintas proyek , yaitu, pasangan fragmen kode serupa yang ditemukan di proyek berbeda. Dari sudut pandang pemberian lisensi, kami tidak terlalu tertarik pada fragmen kode dalam proyek yang sama: mengulangi kode Anda sendiri dianggap praktik yang buruk, tetapi tidak dilarang. Secara total, ada sekitar 561 juta pasangan antar proyek, atau kira-kira setengah dari semua pasangan. Pasangan ini termasuk 3,8 juta metode, yang mana perlu untuk menentukan waktu modifikasi terakhir. Untuk melakukan ini, perintah git menyalahkan diterapkan ke setiap file (yang ternyata 898 ribu, karena mungkin ada lebih dari satu metode dalam file) , yang memberikan waktu modifikasi terakhir untuk setiap baris dalam file.
Jadi kami memiliki waktu modifikasi terakhir untuk setiap baris dalam metode, tetapi bagaimana kami menentukan waktu modifikasi terakhir dari seluruh metode? Ini tampaknya jelas - Anda mengambil waktu terbaru dan menggunakannya: lagipula, ini benar-benar menunjukkan kapan metode terakhir diubah. Namun, untuk tugas kita, definisi seperti itu tidaklah ideal. Mari pertimbangkan sebuah contoh:
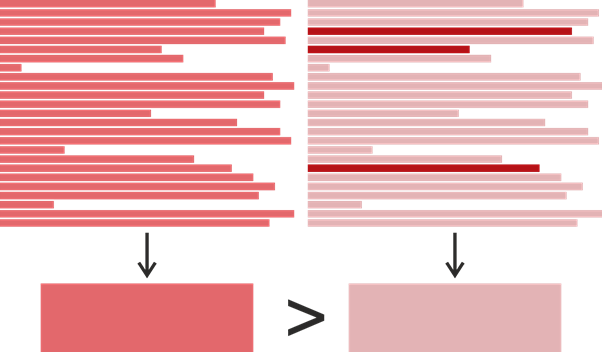
Misalkan kita menemukan klon berupa sepasang fragmen, masing-masing dengan 25 baris. Warna yang lebih jenuh di sini berarti waktu modifikasi nanti. Katakanlah fragmen di sebelah kiri ditulis sekaligus pada tahun 2017, dan di fragmen di kanan 22 baris ditulis pada tahun 2015, dan tiga diubah pada tahun 2019. Ternyata fragmen di sebelah kanan itu diubah kemudian, tetapi jika kita ingin menentukan siapa yang dapat menyalin dari siapa, akan lebih logis untuk mengasumsikan sebaliknya: fragmen kiri meminjam yang kanan, dan yang kanan kemudian berubah sedikit. Berdasarkan hal ini, kami mendefinisikan waktu modifikasi terakhir potongan kode sebagai waktu yang paling sering terjadi dari modifikasi terakhir baris individualnya. Jika tiba-tiba ada beberapa waktu seperti itu, yang kemudian dipilih.
Menariknya, potongan kode tertua dalam kumpulan data kami ditulis kembali pada April 1997, di awal Java, dan dia menemukan tiruan yang dibuat pada 2019!
Mendefinisikan lisensi
Langkah kedua dan terpenting adalah menentukan lisensi untuk setiap potongan. Untuk ini, kami menggunakan skema berikut. Untuk memulainya, dengan menggunakan alat Ninka , lisensi yang ditunjukkan langsung di header file telah ditentukan. Jika ada, maka itu dianggap sebagai lisensi untuk setiap metode di dalamnya (Ninka dapat mengenali beberapa lisensi pada saat yang bersamaan). Jika tidak ada yang ditentukan dalam file, atau ada informasi yang tidak mencukupi (misalnya, hanya hak cipta), maka lisensi dari seluruh proyek yang memiliki file tersebut digunakan. Data tentangnya terdapat dalam Arsip Git Publik asli, yang menjadi basis kami mengumpulkan kumpulan data, dan ditentukan menggunakan alat lain - Go License Detector . Jika lisensi tidak ada dalam file atau dalam proyek, maka metode seperti itu ditandai sebagaiGitHub , karena itu tunduk pada Persyaratan Layanan GitHub (di mana semua data kami diunduh).
Setelah mendefinisikan semua lisensi dengan cara ini, kami akhirnya dapat menjawab pertanyaan tentang lisensi mana yang paling populer. Kami menemukan 94 lisensi berbeda secara total . Kami akan memberikan statistik untuk file di sini untuk mengkompensasi kemungkinan kekusutan karena file yang sangat besar dengan banyak metode.
Fitur utama dari jadwal ini adalah distribusi lisensi yang paling tidak merata. Tiga area dapat dilihat pada grafik: dua "lisensi" dengan lebih dari 100 ribu file, sepuluh lainnya dengan 10-100 ribu file, dan satu ekor panjang lisensi dengan kurang dari 10 ribu file.
Pertama-tama mari kita pertimbangkan yang paling populer, di mana kami menyajikan dua area pertama dalam skala linier:
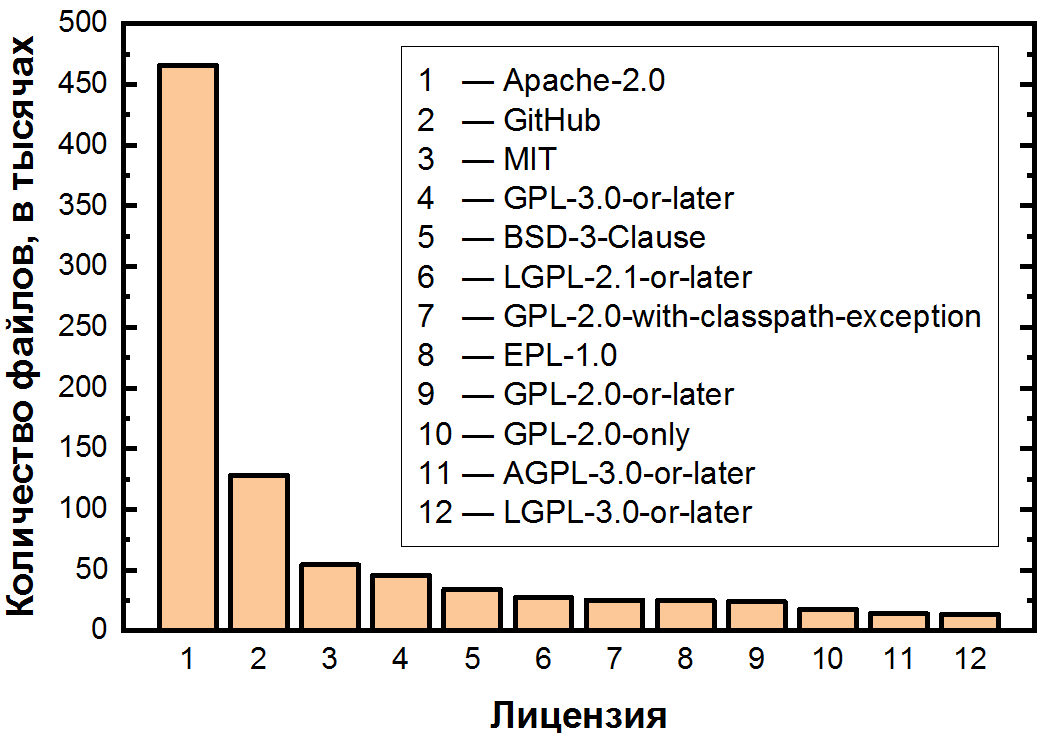
Seseorang dapat melihat ketidakrataan bahkan di antara lisensi yang paling populer. Apache-2.0 berada di tempat pertama dengan margin yang besar - yang paling seimbang dari semua lisensi permisif, ini mencakup lebih dari setengah dari semua file.
Ini diikuti oleh kurangnya lisensi, dan kami masih harus menganalisisnya lebih detail, karena situasi ini sangat umum bahkan di antara repositori sedang dan besar (lebih dari 50 bintang). Keadaan ini sangat penting, karena hanya mengunggah kode ke GitHub tidak membuatnya terbuka.- dan jika ada sesuatu yang praktis dan Anda perlu mengingat dari artikel ini, maka ini dia. Dengan mengunggah kode Anda ke GitHub, Anda menyetujui persyaratan penggunaan, yang menyatakan bahwa kode Anda dapat dilihat dan dicabang. Namun, dengan pengecualian ini, semua hak atas kode tetap ada pada pembuatnya, sehingga distribusi, modifikasi, dan bahkan penggunaan memerlukan izin eksplisit. Ternyata tidak hanya tidak semua open source sepenuhnya gratis, bahkan tidak semua kode di GitHub sepenuhnya open source! Dan karena ada banyak kode seperti itu (14% file, dan di antara proyek yang kurang populer yang tidak termasuk dalam kumpulan data, kemungkinan besar bahkan lebih), ini bisa menjadi penyebab sejumlah besar pelanggaran.
Di lima besar, kami juga melihat lisensi permisif MIT dan BSD yang telah disebutkan, serta copyleft GPL-3.0-atau-lebih baru. Lisensi dari keluarga GPL berbeda tidak hanya dalam sejumlah besar versi (tidak terlalu buruk), tetapi juga dalam postscript "atau yang lebih baru", yang memungkinkan pengguna untuk menggunakan persyaratan dari lisensi ini atau versi yang lebih baru. Hal ini menimbulkan pertanyaan lain: di antara 94 lisensi ini, ada "keluarga" yang jelas-jelas mirip - mana di antara mereka yang terbesar?
Di tempat ketiga adalah lisensi GPL - ada 8 jenis di antaranya dalam daftar. Keluarga ini adalah yang paling signifikan, karena bersama-sama mereka menutupi 12,6% file, kedua setelah Apache-2.0 dan kurangnya lisensi. Di posisi kedua, di luar dugaan, BSD. Selain versi 3 paragraf tradisional dan bahkan versi 2 dan 4 paragraf, ada sangat banyaklisensi khusus - hanya 11 buah. Ini termasuk, misalnya, BSD 3-Clause No Nuclear License , yang merupakan BSD biasa dengan 3 klausul, yang menyatakan di bawah ini bahwa perangkat lunak ini tidak boleh digunakan untuk membuat atau mengoperasikan apa pun yang bersifat nuklir:
Anda mengetahui bahwa perangkat lunak ini tidak dirancang, berlisensi atau dimaksudkan untuk digunakan dalam desain, konstruksi, operasi atau pemeliharaan fasilitas nuklir apa pun.
Yang paling beragam adalah keluarga lisensi Creative Commons, yang dapat Anda baca di sini . Ada sebanyak 13 di antaranya, dan paling tidak layak dibaca karena satu alasan penting: semua kode di StackOverflow dilisensikan di bawah CC-BY-SA.
Di antara lisensi yang lebih langka, ada beberapa yang terkenal, misalnya,Do What The F * ck You Want To Public License (WTFPL) , yang mencakup 529 file dan memungkinkan Anda untuk melakukan persis seperti yang disebutkan namanya dengan kode. Ada juga, misalnya, Lisensi Peralatan Bir , yang juga memungkinkan Anda melakukan apa saja dan mendorong penulis untuk membeli bir saat rapat. Dalam kumpulan data kami, kami juga menemukan variasi dari lisensi ini, yang tidak kami temukan di tempat lain - Lisensi Sushiware . Karena itu, dia mendorong penulis untuk membeli sushi.
Situasi aneh lainnya adalah ketika beberapa lisensi ditemukan dalam satu file (yaitu di dalam file). Dalam dataset kami, hanya ada 0,9% dari file seperti itu. 7,4 ribu file dilindungi oleh dua lisensi sekaligus, dan total 74 pasangan lisensi yang berbeda ditemukan. 419 file dilindungi oleh tiga lisensi, dan ada 8 kembar tiga seperti itu. Dan, terakhir,satu file dalam kumpulan data kami menyebutkan empat lisensi berbeda di header.
Pinjaman yang memungkinkan
Sekarang kita telah membicarakan tentang lisensi, kita dapat mendiskusikan hubungan di antara mereka. Hal pertama yang harus dilakukan adalah menghapus klon yang tidak memungkinkan untuk dipinjam . Izinkan saya mengingatkan Anda bahwa saat ini kami mencoba mempertimbangkan hal ini dengan dua cara - ukuran minimum fragmen kode dan pengecualian klon dalam satu proyek. Kami sekarang akan memfilter tiga jenis pasangan lagi:
- Kami tidak tertarik pada pasangan antara garpu dan yang asli (serta, misalnya, antara dua garpu dari proyek yang sama) - untuk ini kami mengumpulkannya.
- Kami juga tidak tertarik pada klon antara berbagai proyek yang dimiliki oleh organisasi atau pengguna yang sama (karena kami berasumsi bahwa hak cipta dimiliki bersama dalam organisasi yang sama).
- Terakhir, dengan memeriksa secara manual sejumlah besar klon yang tidak normal antara dua proyek, kami menemukan mirror yang signifikan (mereka juga merupakan garpu tidak langsung), yaitu, proyek identik yang diunggah ke repositori yang tidak terkait.
Anehnya, sebanyak 11,7% dari pasangan yang tersisa adalah klon identik dengan ambang kesamaan 100% - mungkin secara intuitif tampaknya ada kode yang kurang benar-benar identik di GitHub.
Kami memproses semua pasangan yang tersisa setelah pemfilteran ini sebagai berikut:
- Kami membandingkan waktu modifikasi terakhir dari dua metode berpasangan.
- , : .
- , «» «» . , 2015 MIT, 2018 — Apache-2.0, MIT → Apache-2.0.
Pada akhirnya, kami menjumlahkan jumlah pasangan untuk setiap potensi peminjaman dan mengurutkannya dalam urutan menurun:
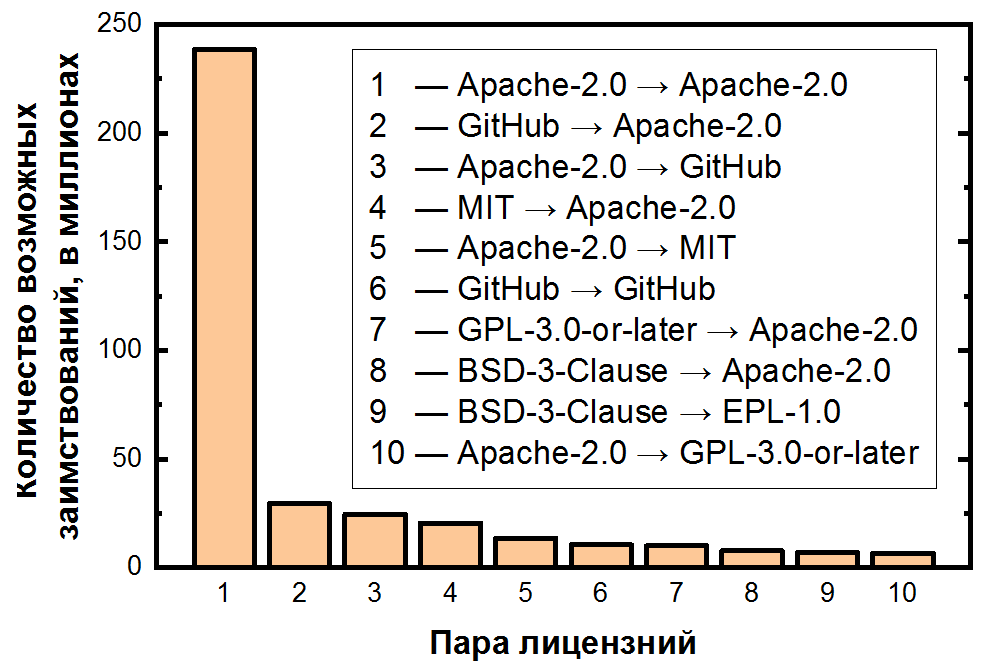
Di sini ketergantungan bahkan lebih ekstrem: kemungkinan peminjaman kode di dalam akun Apache-2.0 untuk lebih dari setengah dari semua pasangan klon, dan 10 pasang lisensi pertama sudah mencakup lebih dari 80% klon. Penting juga untuk dicatat bahwa pasangan kedua dan ketiga yang paling sering berurusan dengan file yang tidak berlisensi - juga konsekuensi yang jelas dari frekuensinya. Untuk lima lisensi paling populer, Anda dapat menampilkan transisi sebagai peta panas:
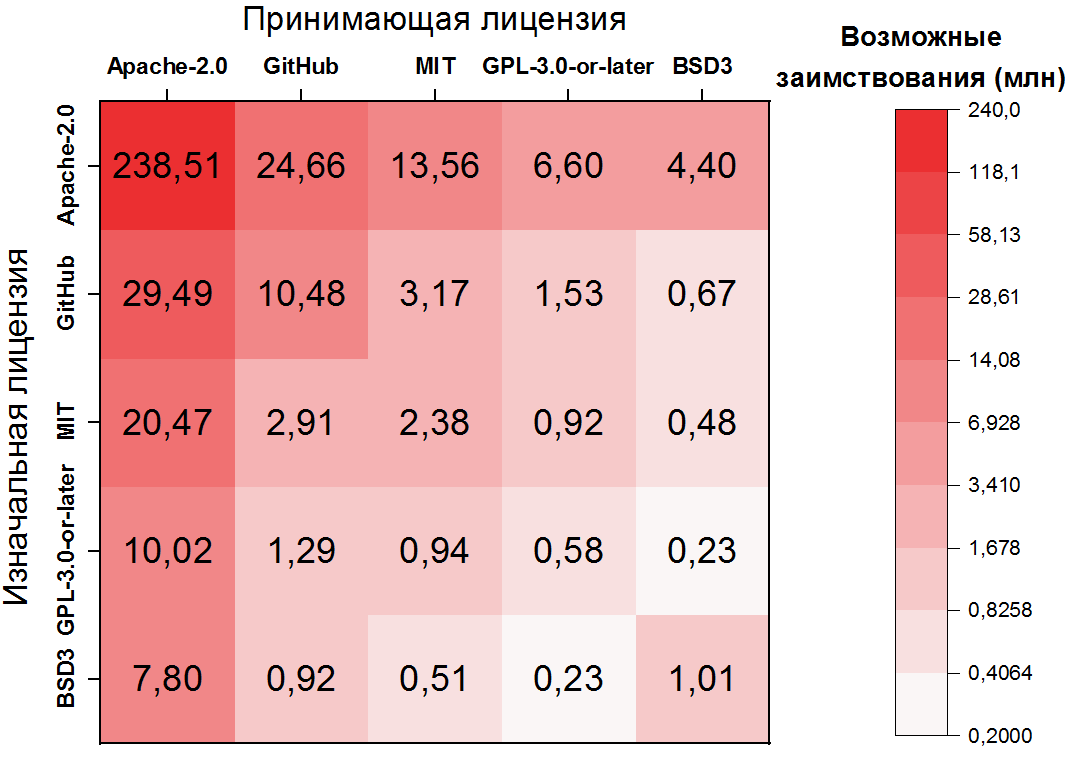
Kemungkinan pelanggaran perizinan
Langkah selanjutnya dalam penelitian kami adalah mengidentifikasi pasangan klon yang berpotensi melanggar , yaitu pinjaman yang melanggar ketentuan asli dan lisensi host. Untuk melakukan ini, Anda perlu menandai pasangan lisensi yang disebutkan di atas sebagai transisi yang diizinkan atau terlarang . Jadi, misalnya, transisi yang paling populer ( Apache-2.0 → Apache-2.0 ), tentu saja, diperbolehkan, tetapi yang kedua ( GitHub → Apache-2.0 ) dilarang. Tapi ada sangat, sangat banyak, ada ribuan pasangan seperti itu.
Untuk mengatasi hal ini, ingatlah bahwa 10 pasang lisensi pertama yang diberikan mencakup 80% dari semua pasang klon. Karena ketidakrataan ini, ternyata cukup untuk menandai secara manual hanya 176 pasang lisensi untuk mencakup 99% pasangan klon, yang menurut kami cukup akurat. Di antara pasangan ini, kami menganggap empat jenis pasangan dilarang:
- Salin dari file tanpa lisensi (GitHub). Seperti yang telah disebutkan, penyalinan seperti itu memerlukan izin langsung dari pembuat kode, dan kami berasumsi bahwa dalam sebagian besar kasus, tidak demikian.
- Menyalin ke file tanpa lisensi juga dilarang, karena ini pada dasarnya adalah menghapus, menghapus lisensi. Lisensi permisif seperti Apache-2.0 atau BSD memungkinkan kode untuk digunakan kembali dalam lisensi lain (termasuk yang berpemilik), tetapi bahkan lisensi ini mengharuskan lisensi asli disimpan dalam file.
- .
- (, Apache-2.0 → GPL-2.0).
Semua pasangan lisensi langka lainnya yang mencakup 1% klon ditandai sebagai permisif (agar tidak menyalahkan siapa pun yang tidak perlu), kecuali yang kode tanpa lisensi muncul (yang tidak pernah dapat disalin).
Alhasil, setelah dilakukan markup, ternyata 72,8% peminjaman adalah peminjaman yang diperbolehkan, dan 27,2% dilarang. Bagan berikut menunjukkan lisensi yang paling banyak dilanggar dan paling banyak dilanggar .

Di sebelah kiri adalah lisensi yang paling banyak dilanggar, yang merupakan sumber kemungkinan pelanggaran terbesar. Di antara mereka, tempat pertama ditempati oleh file tanpa lisensi, yang merupakan catatan praktis penting - Anda perlu memantau file tanpa lisensi dengan cermat.... Orang mungkin bertanya-tanya apa yang dilakukan lisensi permisif Apache-2.0 dalam daftar ini. Namun, seperti yang dapat dilihat dari peta panas di atas, ~ 25 juta pinjaman terlarang darinya adalah pinjaman ke file tanpa lisensi, jadi ini adalah konsekuensi dari popularitasnya.
Di sebelah kanan adalah lisensi yang disalin dengan pelanggaran, dan di sini kebanyakan dari semuanya adalah Apache-2.0 dan GitHub yang sama.
Asal metode individu
Akhirnya, kami sampai pada poin terakhir dari penelitian kami. Selama ini kami berbicara tentang pasangan klon, seperti yang biasa dalam studi semacam itu. Namun, seseorang harus memahami satu sisi, ketidaklengkapan penilaian semacam itu. Faktanya adalah jika, misalnya, sebuah kode memiliki 20 saudara laki-laki yang "lebih tua" (atau "orang tua", siapa tahu), maka semua 20 pasangan tersebut akan dianggap sebagai pinjaman potensial. Itulah mengapa kita berbicara tentang pinjaman "potensial" dan "kemungkinan" - tidak mungkin penulis metode tertentu meminjamnya dari 20 tempat berbeda. Meskipun demikian, alasan ini dapat dilihat sebagai alasan klon antar lisensi yang berbeda.
Untuk menghindari penilaian yang tidak lengkap tersebut, Anda dapat melihat gambar yang sama dari sudut yang berbeda. Gambar kloning sebenarnya adalah grafik berarah: semua metode adalah simpul di atasnya, yang dihubungkan oleh tepi terarah dari senior ke junior (jika Anda tidak memperhitungkan metode akun bertanggal pada hari yang sama). Dalam dua bagian sebelumnya, kita melihat grafik ini dari sudut pandang tepi: kita mengambil setiap tepi dan mempelajari simpulnya (mendapatkan pasangan lisensi itu). Sekarang mari kita lihat dari sudut pandang simpul. Setiap simpul (metode) pada grafik memiliki leluhur (klon "senior") dan turunan (klon "junior"). Tautan di antara mereka juga dapat dibagi menjadi "diizinkan" dan "dilarang".
Berdasarkan hal ini, setiap metode dapat dikaitkan ke salah satu kategori berikut, yang grafiknya ditunjukkan pada gambar (di sini garis padat menunjukkan pinjaman yang dilarang, dan garis putus-putus - diperbolehkan):

Dua dari konfigurasi yang disajikan mungkin merupakan pelanggaran terhadap ketentuan perizinan:
- Pelanggaran berat berarti metode tersebut memiliki leluhur dan semua transisi darinya dilarang. Artinya jika pengembang benar-benar menyalin kode tersebut, maka dia melakukannya dengan melanggar lisensi.
- Pelanggaran lemah berarti metode tersebut memiliki leluhur, dan hanya beberapa dari mereka yang berada di belakang transisi terlarang. Artinya, pengembang mungkin telah menyalin kode yang melanggar lisensi.
Konfigurasi lain bukanlah pelanggaran:
- , , .
- — , — , .
- , , — , . , , — , . : , , , , ( , , ).
Jadi bagaimana metode didistribusikan dalam kumpulan data kami?

Anda dapat melihat bahwa sekitar sepertiga dari metode tidak memiliki klon sama sekali, dan sepertiga lainnya memiliki klon hanya dalam proyek terkait. Di sisi lain, 5,4% metode mewakili "pelanggaran ringan" dan 4% - "pelanggaran berat". Meskipun jumlah ini mungkin tidak terlihat terlalu besar, masih ada ratusan ribu metode dalam proyek yang kurang lebih besar.
TL; DR
Mengingat artikel ini memuat banyak sekali gambar dan grafik empiris, mari kita ulangi lagi temuan utama kami:
- Ada jutaan metode yang memiliki klon, dan ada lebih dari satu miliar pasangan di antaranya.
- , Java- 50 , 94 , : Apache-2.0 . Apache-2.0 .
- , 27,2%, .
- 35,4% , 5,4% «» , 4% «» .
?
Sebagai kesimpulan, saya ingin berbicara tentang mengapa semua hal di atas dibutuhkan. Saya memiliki setidaknya tiga jawaban.
Pertama, ini menarik . Lisensi sama beragamnya dengan semua aspek pemrograman lainnya. Daftar lisensi itu sendiri cukup membuat penasaran karena kekhususan dan kelangkaan beberapa lisensi, orang-orang menulis dan mengerjakannya dengan cara yang berbeda. Ini juga tidak diragukan lagi berlaku untuk klon dalam kode dan kesamaan kode secara umum. Ada metode dengan ribuan klon, dan ada metode tanpa satu pun, sementara sekilas tidak selalu mudah untuk melihat perbedaan mendasar di antara mereka.
Kedua, analisis terperinci dari temuan kami memungkinkan kami merumuskan beberapa tip praktis :
- - . Apache-2.0, MIT, BSD-3-Clause, GPL LGPL.
- : . - , , .
- GitHub, . . — , . : - , , , , . , .
Untuk deskripsi lisensi yang jelas, serta saran dalam memilih lisensi untuk proyek baru Anda, Anda dapat beralih ke layanan seperti tldrlegal atau choosealicense .
Terakhir, data yang diperoleh dapat digunakan untuk membuat alat . Saat ini, kolega kami sedang mengembangkan cara untuk menentukan lisensi dengan cepat menggunakan metode pembelajaran mesin (yang mana Anda hanya memerlukan banyak lisensi khusus) dan plugin IDE yang memungkinkan pengembang melacak dependensi dalam proyek mereka dan melihat kemungkinan ketidaksesuaian sebelumnya.
Semoga Anda telah mempelajari sesuatu yang baru dari artikel ini. Kepatuhan terhadap persyaratan perizinan dasar tidak terlalu merepotkan, dan Anda dapat melakukan segalanya sesuai aturan dengan sedikit usaha. Mari mendidik bersama, mendidik orang lain, dan mendekati impian perangkat lunak open source yang "tepat"!