Memproses bahkan beberapa gigabyte data di laptop hanya dapat menjadi tugas yang menakutkan jika tidak memiliki banyak RAM dan daya pemrosesan yang baik.
Meskipun demikian, para ilmuwan data masih harus mencari solusi alternatif untuk masalah ini. Ada opsi untuk menyiapkan Pandas untuk menangani kumpulan data besar, membeli GPU, atau membeli daya komputasi awan. Pada artikel ini, kita akan melihat cara menggunakan Dask untuk kumpulan data besar di komputer lokal Anda.
Dask dan Python
Dask adalah pustaka komputasi paralel fleksibel untuk Python. Ia bekerja dengan baik dengan proyek sumber terbuka lainnya seperti NumPy, Pandas, dan scikit-learn. Dask memiliki struktur array yang setara dengan array NumPy, dataframe Dask mirip dengan dataframe Pandas, dan Dask-ML adalah scikit-learn.
Kesamaan ini memudahkan pengintegrasian Dask ke dalam pekerjaan Anda. Keuntungan menggunakan Dask adalah Anda dapat menskalakan komputasi ke beberapa inti di komputer Anda. Jadi Anda mendapatkan kesempatan untuk bekerja dengan data dalam jumlah besar yang tidak muat di memori. Anda juga dapat mempercepat penghitungan yang biasanya memakan banyak ruang.
Sumber
Dask DataFrame
Saat memuat data dalam jumlah besar, Dask biasanya membaca sampel data untuk mengenali tipe datanya. Ini paling sering menyebabkan kesalahan, karena mungkin ada tipe data berbeda dalam kolom yang sama. Direkomendasikan agar Anda mendeklarasikan jenis-jenis tersebut sebelumnya untuk menghindari kesalahan. Dask dapat mengunduh file besar dengan mengirisnya menjadi blok-blok yang ditentukan oleh parameter
blocksize.
data_types ={'column1': str,'column2': float}
df = dd.read_csv(“data,csv”,dtype = data_types,blocksize=64000000 )
Perintah Sumber di Dask DataFrame mirip dengan perintah Pandas. Misalnya,get
headdantail dataframe serupa:
df.head()
df.tail()Fungsi di DataFrame bersifat malas. Artinya, mereka tidak dievaluasi sampai fungsinya dipanggil
compute.
df.isnull().sum().compute()Karena data dimuat dalam potongan, beberapa fungsi Pandas seperti
sort_values()tidak dapat dijalankan. Tapi Anda bisa menggunakan fungsinyanlargest().
Cluster di Dask
Komputasi paralel adalah kunci dalam Dask karena memungkinkan Anda membaca di beberapa inti secara bersamaan. Dask menyediakan
machine scheduleryang berjalan pada satu mesin. Itu tidak berskala. Ada juga satu distributed scheduleryang memungkinkan Anda menskalakan ke beberapa mesin.
Penggunaan
dask.distributedmembutuhkan konfigurasi klien. Ini adalah hal pertama yang Anda lakukan jika Anda berencana menggunakannya dask.distributed dalam analisis Anda. Ini menyediakan latensi rendah, lokalitas data, komunikasi pekerja-ke-pekerja, dan mudah dikonfigurasi.
from dask.distributed import Client
client = Client()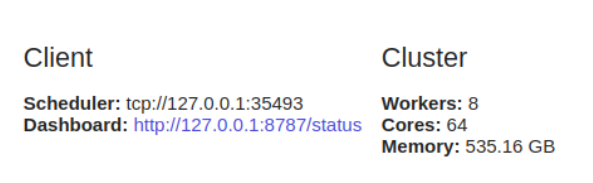
Ini
dask.distributedbermanfaat untuk digunakan bahkan pada satu mesin karena menawarkan fungsi diagnostik melalui dasbor.
Jika Anda tidak mengkonfigurasi
Client, maka secara default Anda akan menggunakan penjadwal mesin untuk satu mesin. Ini akan memberikan konkurensi pada satu komputer menggunakan proses dan utas.
Dask ML
Dask juga memungkinkan pelatihan dan perkiraan model paralel. Sasarannya
dask-mladalah menawarkan pembelajaran mesin yang skalabel. Saat Anda mendeklarasikan n_jobs = -1 scikit-learn, Anda dapat menjalankan penghitungan secara paralel. Dask menggunakan fitur ini untuk memungkinkan Anda melakukan komputasi dalam sebuah cluster. Anda dapat melakukan ini dengan paket joblib , yang memungkinkan paralelisme dan pipelining dengan Python. Dengan Dask ML, Anda dapat menggunakan model scikit-learn dan pustaka lain seperti XGboost.
Implementasi sederhana akan terlihat seperti ini.
Pertama, impor
train_test_splituntuk membagi data Anda menjadi kasus pelatihan dan pengujian.
from dask_ml.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Kemudian impor model yang ingin Anda gunakan dan buat instance-nya.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(verbose=1)Kemudian Anda perlu mengimpor
joblibuntuk mengaktifkan komputasi paralel.
import joblibKemudian mulai pelatihan dan perkiraan dengan backend paralel.
from sklearn.externals.joblib import parallel_backend
with parallel_backend(‘dask’):
model.fit(X_train,y_train)
predictions = model.predict(X_test)Batasan dan penggunaan memori
Tugas individu di Dask tidak dapat dijalankan secara paralel. Pekerja adalah proses Python yang mewarisi keuntungan dan kerugian dari komputasi Python. Selain itu, saat bekerja dalam lingkungan terdistribusi, kehati-hatian harus diberikan untuk memastikan keamanan dan privasi data Anda.
Dask memiliki penjadwal pusat yang memantau data di node pekerja dan di cluster. Itu juga mengelola rilis data dari cluster. Ketika tugas selesai, itu akan segera menghapusnya dari memori untuk memberi ruang bagi tugas lain. Tetapi jika sesuatu dibutuhkan oleh klien tertentu, atau penting untuk kalkulasi saat ini, itu akan disimpan dalam memori.
Batasan lain dari Dask adalah tidak mengimplementasikan semua fungsionalitas Pandas. Antarmuka Pandas sangat besar, jadi Dask tidak menutupinya sepenuhnya. Artinya, melakukan beberapa operasi ini di Dask bisa jadi menantang. Selain itu, operasi lambat dari Pandas juga akan lambat di Dask.
Saat Anda tidak membutuhkan Dask DataFrame
Dalam situasi berikut, Dask mungkin bukan pilihan yang tepat untuk Anda:
- Saat Pandas memiliki fungsi yang Anda butuhkan, tetapi Dask belum mengimplementasikannya.
- Saat data Anda cocok dengan memori komputer Anda.
- Saat data Anda tidak dalam bentuk tabel. Jika ya, coba dask.bag atau disk.array .
Pikiran terakhir
Pada artikel ini, kami melihat bagaimana Anda dapat menggunakan Dask untuk bekerja secara terdistribusi dengan kumpulan data besar di komputer lokal Anda. Kami melihat bahwa kami dapat menggunakan Dask karena sintaksnya sudah tidak asing lagi bagi kami. Dask juga dapat menskalakan hingga ribuan inti.
Kami juga melihat bahwa kami dapat menggunakannya dalam pembelajaran mesin untuk prediksi dan pelatihan. Jika Anda ingin tahu lebih banyak, lihat materi ini di dokumentasi .
