Perlu saya perhatikan bahwa sebulan setelah saya mengenal teknologi ini, saya mulai menggunakan antidepresan. Apakah NiFi adalah pemicunya atau yang terakhir tidak diketahui secara pasti, serta keterlibatannya dalam fakta ini. Tetapi, karena saya berusaha menjelaskan segala sesuatu yang menunggu calon pemula di jalur ini, saya harus sejujur mungkin.
Pada saat, secara teknis, Apache NiFi adalah penghubung yang kuat antara berbagai layanan (ia bertukar data di antara mereka, memungkinkan mereka untuk diperkaya dan dimodifikasi sepanjang jalan), saya melihatnya dari sudut pandang seorang analis . Ini karena NiFi adalah alat ETL yang sangat berguna. Secara khusus, sebagai sebuah tim, kami fokus membangun arsitektur SaaS mereka.
Pengalaman mengotomatiskan salah satu alur kerja saya, yaitu pembentukan dan pendistribusian laporan mingguan di Jira Software , ingin saya ungkapkan di artikel ini. Ngomong-ngomong, saya juga akan menjelaskan dan mempublikasikan metodologi analitik pelacak tugas, yang dengan jelas menjawab pertanyaan - apa yang dilakukan karyawan - saya juga akan menjelaskan dan menerbitkannya dalam waktu dekat.
Terlepas dari dedikasi artikel ini untuk pemula, saya pikir itu benar dan berguna jika arsitek yang lebih berpengalaman (ahli, boleh dikatakan) mengulasnya dalam sebutan atau membagikan kasus penggunaan NiFi mereka di berbagai bidang aktivitas. Banyak pria, termasuk saya, akan berterima kasih.
Konsep Apache NiFi secara singkat.
Apache NiFi adalah produk open source untuk otomatisasi dan kontrol aliran data antar sistem. Memulai dengan itu penting untuk segera menyadari dua hal.
Yang pertama adalah zona Kode Rendah. Apa yang saya maksud? Diasumsikan bahwa semua manipulasi dengan data dari saat mereka memasuki NiFi hingga ekstraksi dapat dilakukan menggunakan alat standar (prosesor). Untuk kasus khusus, ada prosesor untuk menjalankan skrip dari bash.
Ini menunjukkan bahwa melakukan sesuatu di NiFi itu salah - itu cukup sulit (tapi saya berhasil! - itu poin kedua). Sulit karena prosesor apa pun akan langsung menendang Anda - Ke mana mengirim kesalahan? Apa hubungannya dengan mereka? Berapa lama menunggu? Dan di sini Anda memberi saya sedikit ruang! Sudahkah Anda membaca dokumentasi dengan cermat? dll.

Kedua (kunci) adalah konsep pemrograman streaming, dan tidak lebih. Di sini, saya pribadi, tidak langsung mendapatkannya (tolong, jangan menilai). Memiliki pengalaman dalam pemrograman fungsional di R, tanpa sadar saya membentuk fungsi di NiFi. Akhirnya - ulangi - kolega saya memberi tahu saya ketika mereka melihat upaya sia-sia saya untuk menjadikan "fungsi" ini sebagai teman.
Menurut saya teorinya sudah cukup untuk hari ini, mari kita pelajari semuanya dari praktek dengan lebih baik. Mari kita rumuskan kesamaan spesifikasi teknis untuk analisis Jira mingguan.
- Dapatkan log kerja dan riwayat perubahan dari lemak untuk minggu ini.
- Tampilkan statistik dasar untuk periode ini dan jawab pertanyaan: apa yang dilakukan tim?
- Kirim laporan ke atasan dan kolega.
Untuk memberikan lebih banyak manfaat bagi dunia, saya tidak berhenti pada periode mingguan dan mengembangkan proses dengan kemampuan untuk mengunduh data dalam jumlah yang jauh lebih besar.
Mari kita cari tahu.
Langkah pertama. Mengambil data dari API
Apache NiFi tidak memiliki proyek terpisah. Kami hanya memiliki ruang kerja yang sama dan kemampuan untuk membentuk kelompok proses di dalamnya. Ini sudah cukup.
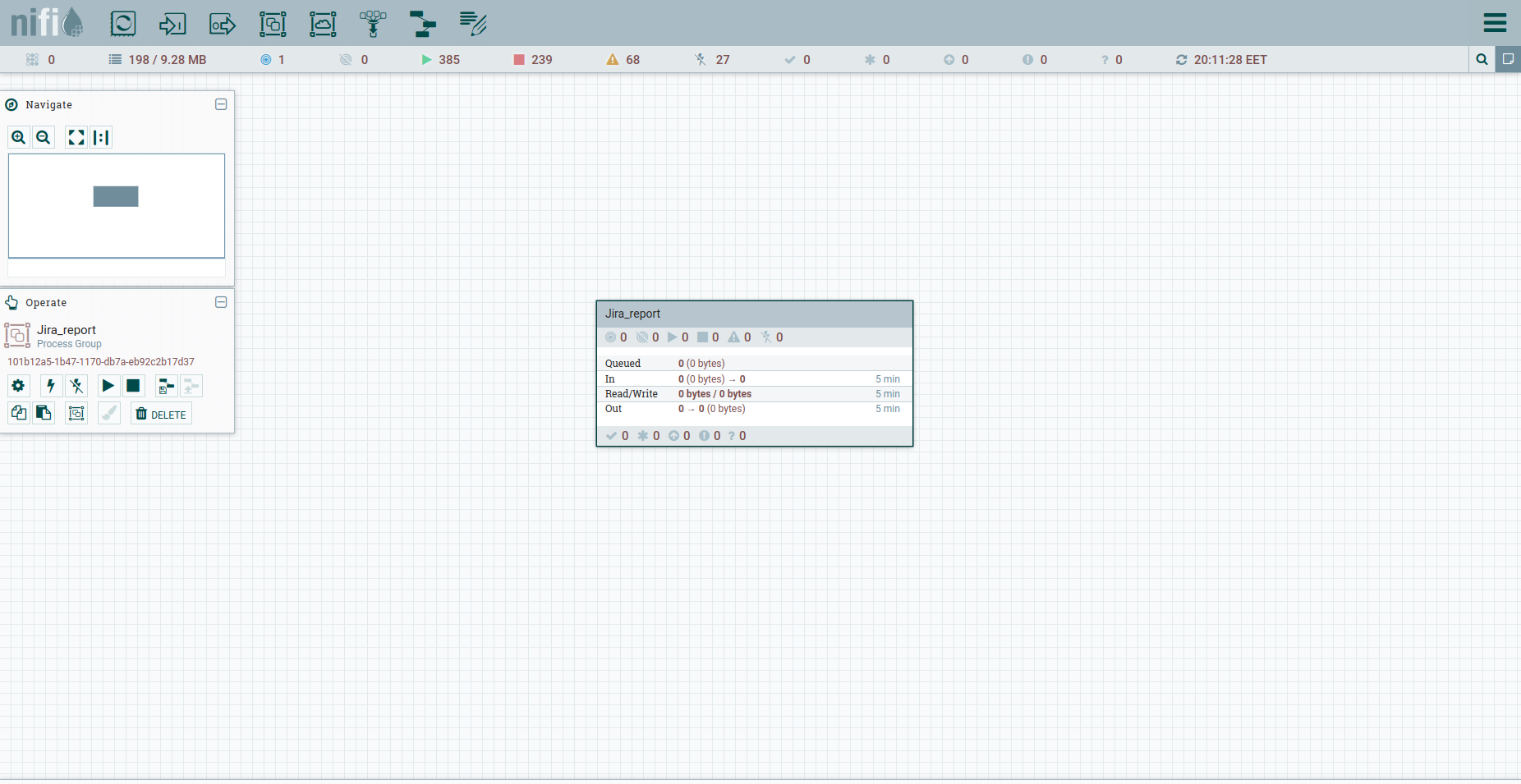
Temukan Grup Proses di bilah alat dan buat grup Jira_report. Masuk ke grup dan mulai buat alur kerja. Sebagian besar prosesor tempat ia dapat dirakit memerlukan Koneksi Hulu. Dengan kata sederhana, ini adalah pemicu di mana prosesor akan menyala. Oleh karena itu, logis bahwa seluruh aliran akan dimulai dengan pemicu biasa - di NiFi, ini adalah prosesor GenerateFlowFile. Apa yang dia lakukan. Membuat file streaming yang terdiri dari sekumpulan atribut dan konten. Atribut adalah pasangan kunci / nilai string yang terkait dengan konten.
Konten adalah file biasa, sekumpulan byte. Bayangkan bahwa konten adalah lampiran ke FlowFile.
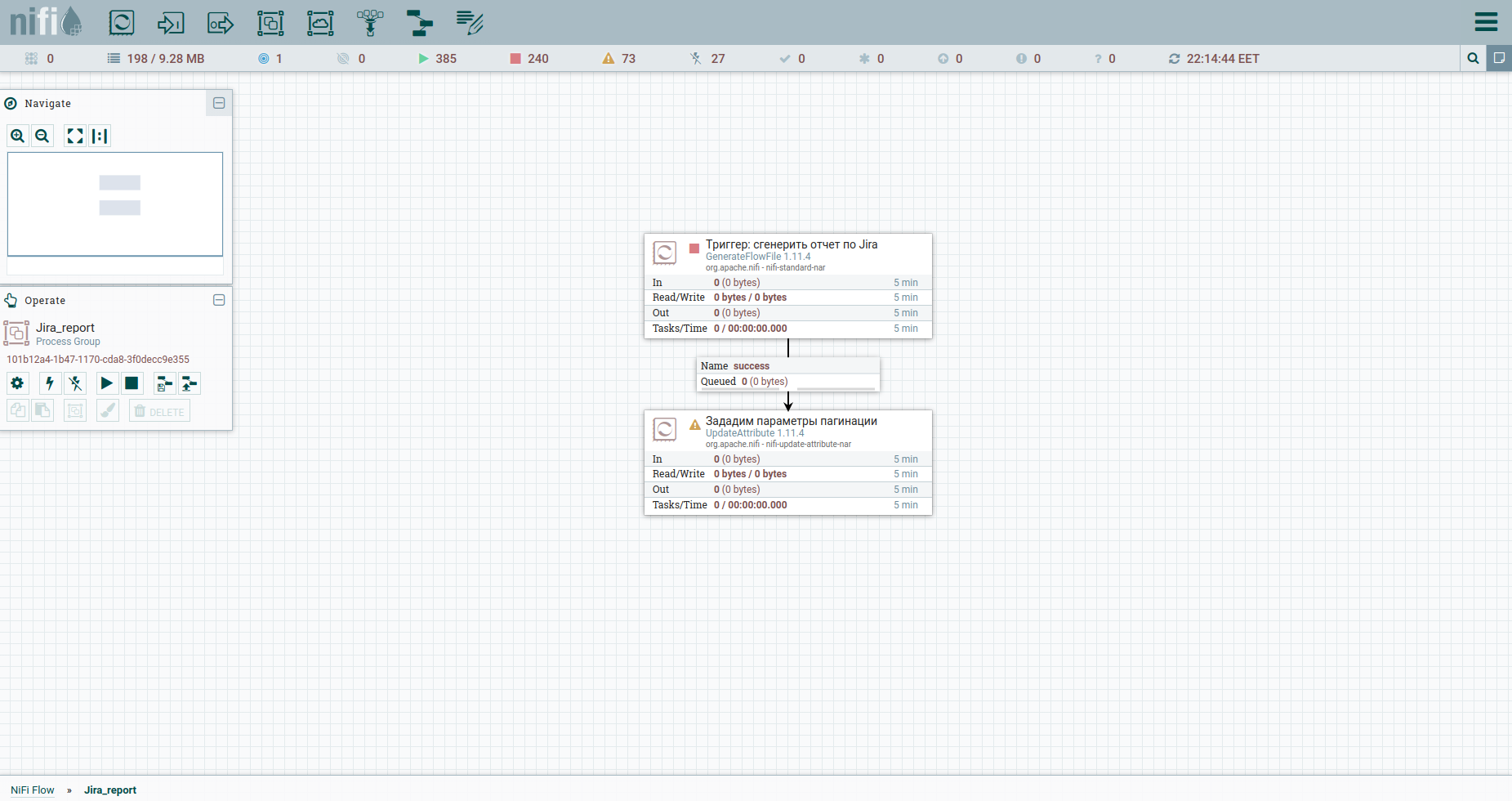
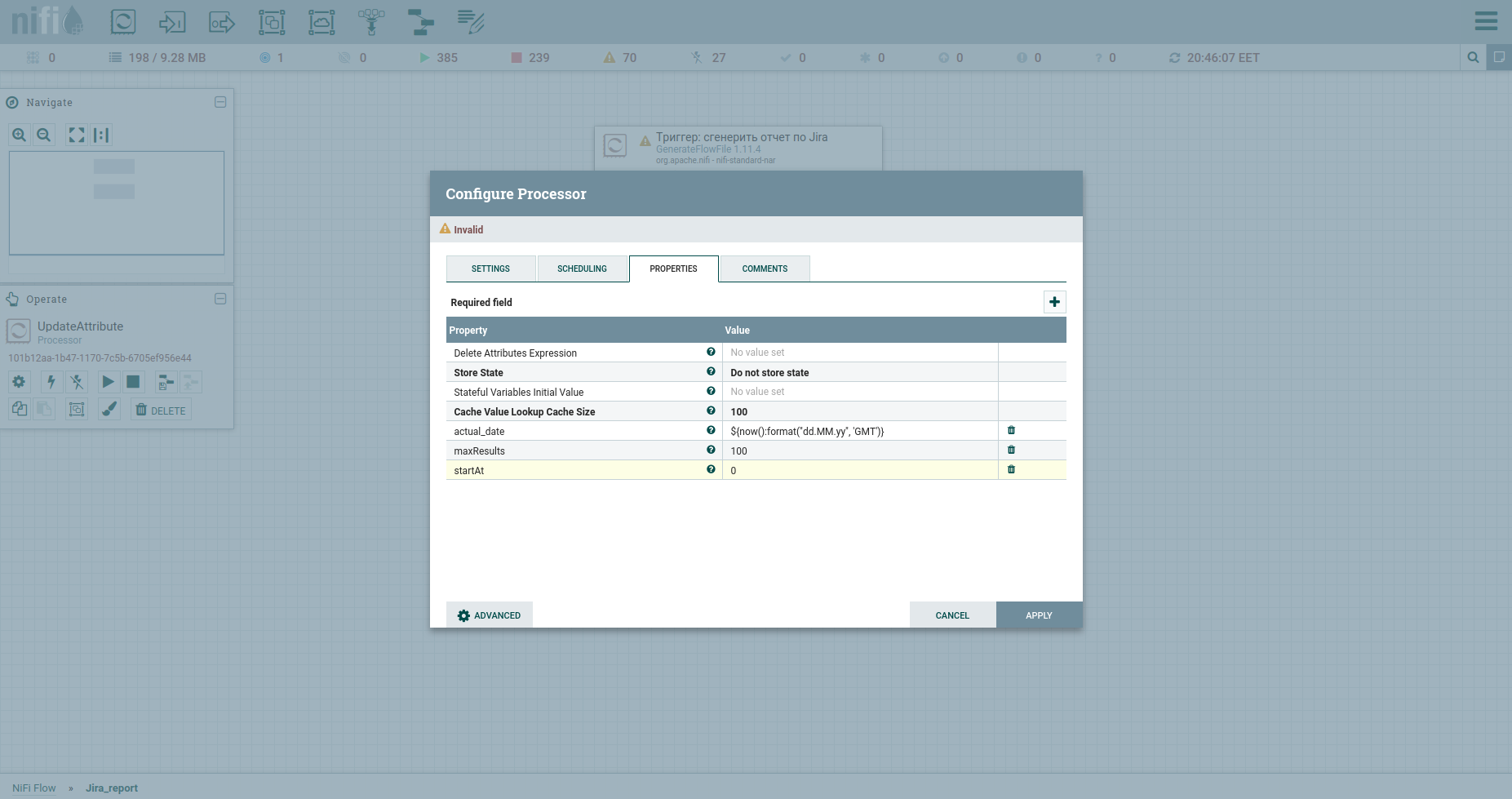
Kami melakukan Add Processor → GenerateFlowFile. Dalam pengaturan, pertama-tama, saya sangat menyarankan pengaturan nama prosesor (ini adalah nada yang bagus) - tab Pengaturan. Poin lain: secara default, GenerateFlowFile menghasilkan file aliran terus menerus. Kecil kemungkinan Anda akan membutuhkan ini. Kami segera meningkatkan Jadwal Proses, misalnya, hingga 60 detik - tab Penjadwalan. Selain itu, pada tab Properti, kami akan menunjukkan tanggal mulai periode pelaporan - atribut report_from dengan nilai dalam format - yyyy / mm / dd. Menurut dokumentasi Jira API, kami memiliki batasan pada masalah pembongkaran - tidak lebih dari 1000. Oleh karena itu, untuk mendapatkan semua tugas, kita harus membentuk permintaan JQL, yang menentukan parameter pagination: startAt dan maxResults.

Mari kita atur dengan atribut menggunakan prosesor UpdateAttribute. Pada saat yang sama, kami akan mempercepat tanggal pembuatan laporan. Kami akan membutuhkannya nanti. Anda mungkin telah memperhatikan atribut tanggal_tual. Nilainya diatur menggunakan Expression Language. Lihat lembar contekan keren di atasnya. Itu saja, kita dapat membentuk JQL menjadi lemak - kita akan menunjukkan parameter pagination dan bidang yang wajib diisi. Selanjutnya, ini akan menjadi badan permintaan HTTP, oleh karena itu, kami akan mengirimkannya ke konten. Untuk melakukan ini, kami menggunakan prosesor ReplaceText dan menentukan Nilai Penggantiannya seperti ini:
{"startAt": ${startAt}, "maxResults": ${maxResults}, "jql": "updated >= '2020/11/02'", "fields":["summary", "project", "issuetype", "timespent", "priority", "created", "resolutiondate", "status", "customfield_10100", "aggregatetimespent", "timeoriginalestimate", "description", "assignee", "parent", "components"]}Perhatikan bagaimana tautan atribut ditulis.
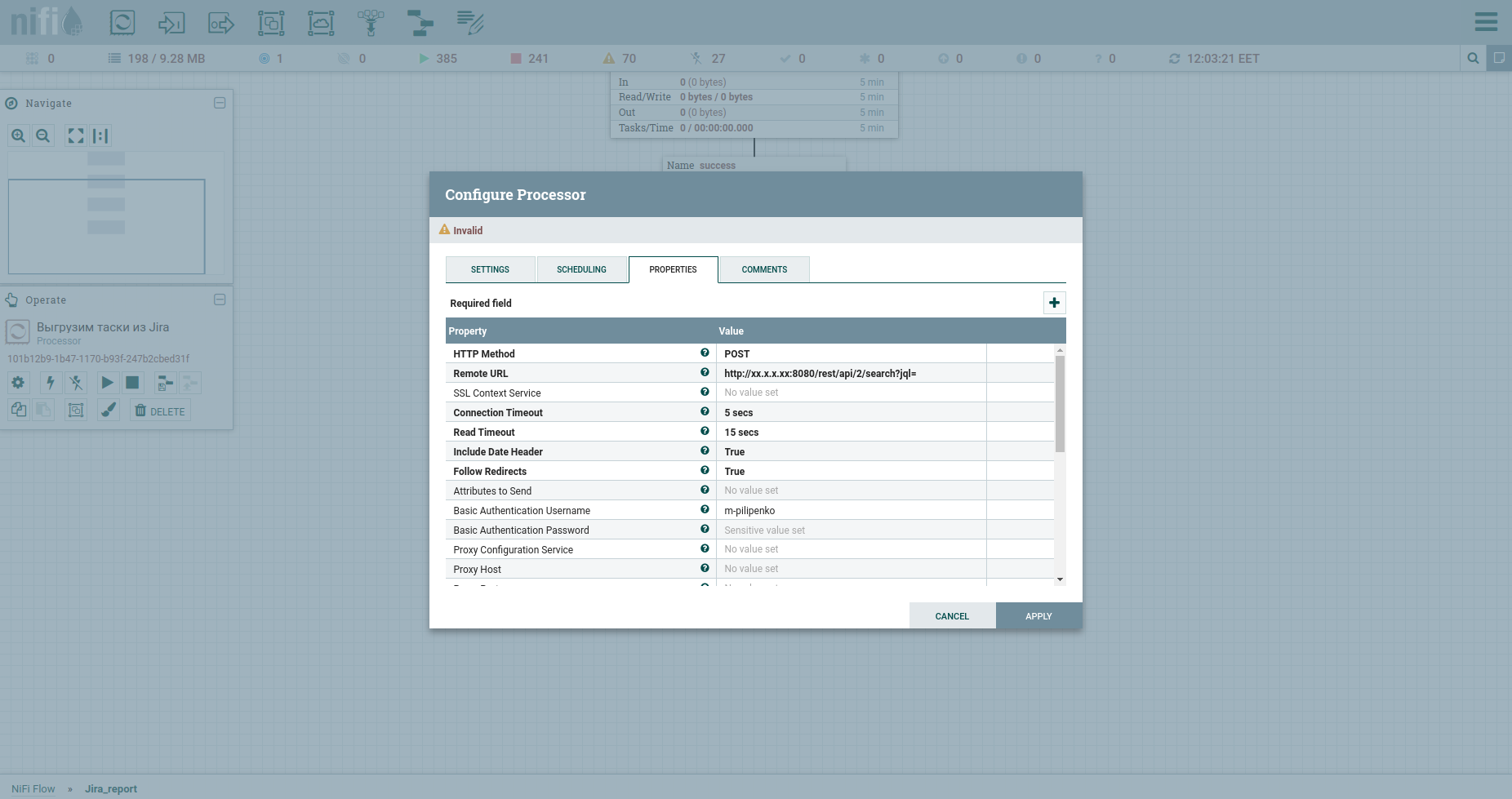
Selamat, kami siap membuat permintaan HTTP. Prosesor InvokeHTTP akan muat di sini. Omong-omong, dia bisa melakukan apa saja ... Maksud saya metode GET, POST, PUT, PATCH, DELETE, HEAD, OPTIONS. Mari memodifikasi propertinya sebagai berikut:
Metode HTTP kita memiliki POST.
URL jarak jauh dari lemak kami termasuk IP, port, dan / rest / api / 2 / search? Jql =.
Nama Pengguna Otentikasi Dasar dan Kata Sandi Otentikasi Dasar adalah kredensial untuk lemak.
Ubah Content-Type menjadi application / json b menjadi true di Send Message Body, artinya mengirim JSON yang akan datang dari prosesor sebelumnya di request body.
MENERAPKAN.
Respons apish adalah file JSON yang akan dimasukkan ke dalam konten. Kami tertarik pada dua hal di dalamnya: bidang total yang berisi jumlah total tugas di sistem dan larik masalah, yang sudah berisi beberapa di antaranya. Mari kita uraikan jawabannya dan berkenalan dengan prosesor EvaluateJsonPath.
Jika JsonPath menunjuk ke satu objek, hasil parsing akan ditulis ke atribut file aliran. Berikut adalah contoh - bidang total dan layar berikut. Dalam kasus ketika JsonPath menunjuk ke larik objek, sebagai hasil dari penguraian, file alur akan dipecah menjadi satu set dengan konten yang sesuai dengan setiap objek. Berikut adalah contohnya - bidang masalah. Kami menempatkan EvaluateJsonPath lain dan menulis: Properti - masalah, Nilai - $ .issue.

Sekarang aliran kami sekarang tidak akan terdiri dari satu file, tetapi dari banyak file. Konten masing-masing akan berisi JSON dengan informasi tentang satu tugas tertentu.
Berpindah. Ingat kami menyetel maxResults ke 100? Setelah langkah sebelumnya, kita akan memiliki seratus tasoks pertama. Mari kita dapatkan lebih banyak dan terapkan pagination.
Untuk melakukan ini, mari tingkatkan nomor tugas awal dengan maxResults. Mari kita gunakan UpdateAttribute lagi: kita akan menunjukkan atribut startAt dan memberinya nilai baru $ {startAt: plus ($ {maxResults})}.
Ya, kami tidak dapat melakukannya tanpa pemeriksaan untuk mencapai jumlah tugas maksimum - prosesor RouteOnAttribute. Pengaturannya adalah sebagai berikut: And loop. Secara total, siklus akan berjalan selama jumlah tugas mulai kurang dari jumlah total tugas. Di pintu keluarnya - aliran tasoks. Beginilah prosesnya terlihat sekarang:
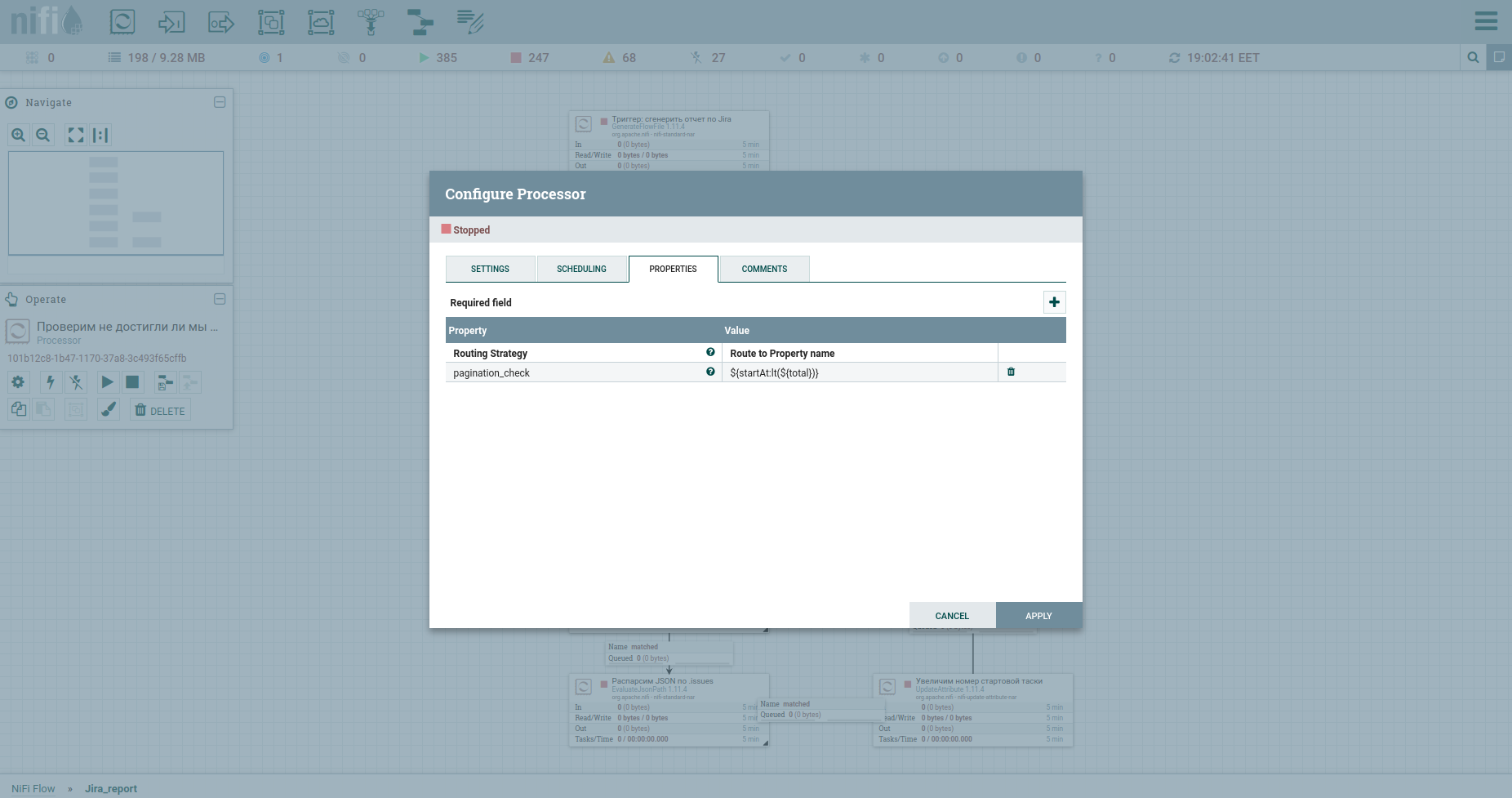

Ya, teman-teman, saya tahu - Anda lelah membaca komentar saya di setiap kotak. Anda ingin memahami prinsip itu sendiri. Saya tidak menentangnya.
Bagian ini akan memudahkan pemula mutlak untuk memasuki NiFi. Kemudian, memiliki template yang disajikan dengan murah hati oleh saya, tidak akan sulit untuk mempelajari detailnya.
Berderap melintasi Eropa. Mengupload worklog, dll.
Nah, mari kita percepat. Seperti yang mereka katakan, temukan perbedaannya: Untuk persepsi yang lebih mudah, saya memindahkan proses pembongkaran log kerja dan riwayat perubahan ke dalam kelompok terpisah. Ini dia: Untuk mengatasi batasan ketika secara otomatis menurunkan worklog dari Jira, disarankan untuk merujuk ke setiap tugas secara terpisah. Itu sebabnya kami membutuhkan kunci mereka. Kolom pertama hanya mengubah aliran tasoks menjadi aliran kunci. Selanjutnya, kita beralih ke kera dan menyimpan jawabannya. Akan lebih mudah bagi kami untuk mengatur worklog dan changelog untuk semua tugas dalam bentuk dokumen terpisah. Oleh karena itu, kami akan menggunakan prosesor MergeContent dan merekatkan konten semua file aliran dengannya.
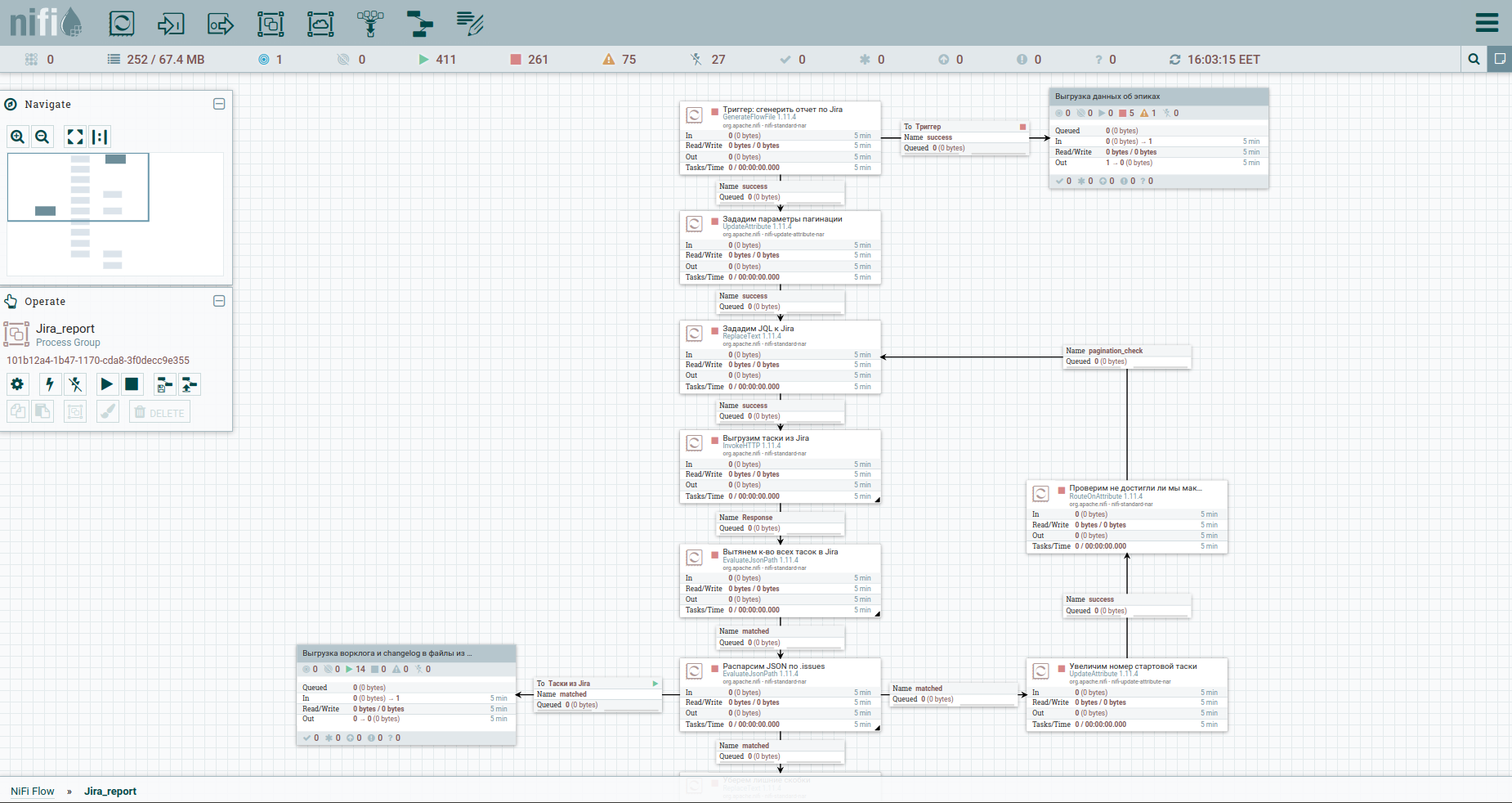
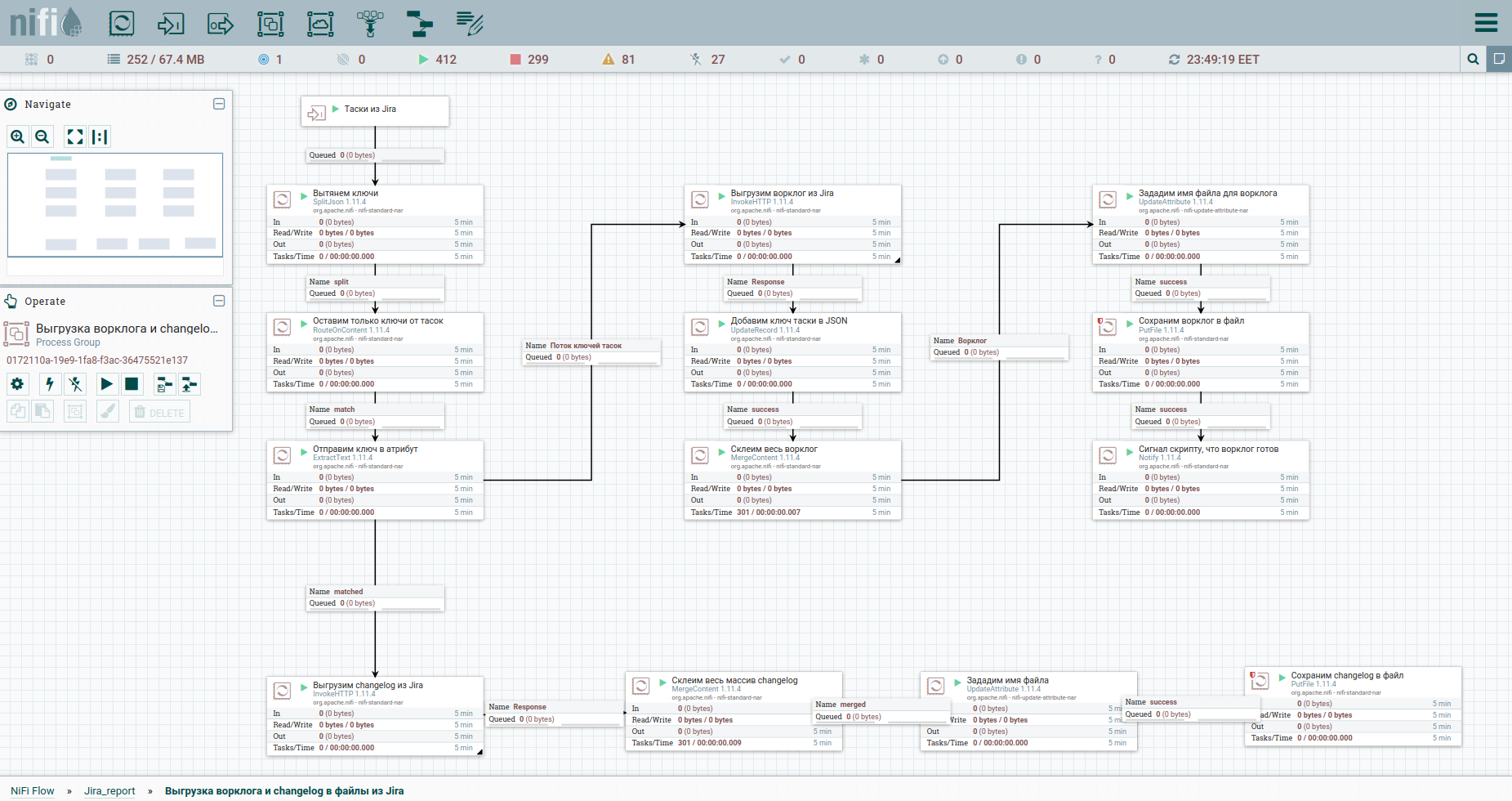
Juga di template Anda akan melihat grup untuk membongkar data dengan epos. Sebuah epik di Jira adalah tugas umum yang mengikat banyak orang. Grup ini akan berguna jika hanya sebagian dari tugas yang ditambang, agar tidak kehilangan informasi tentang epos beberapa dari mereka.
Tahap terakhir. Laporkan pembuatan dan pengiriman melalui email
Baik. Semua titik dibongkar dan digunakan dalam dua cara: ke grup untuk membongkar worklog dan ke skrip untuk membuat laporan. Dengan yang terakhir, kami memiliki satu STDIN, jadi kami perlu mengumpulkan semua tugas dalam satu tumpukan. Kami akan melakukan ini di MergeContent, tetapi sebelum itu kami akan sedikit memperbaiki konten sehingga json terakhir benar. Prosesor Tunggu yang menarik hadir di depan kotak pembuatan skrip (ExecuteStreamCommand). Dia menunggu sinyal dari prosesor Notify, yang ada di grup pembongkaran worklog, bahwa semuanya sudah siap di sana dan Anda dapat melanjutkan. Selanjutnya, kami menjalankan skrip dari bash-a - ExecuteStreamCommand. Dan kami mengirimkan laporan menggunakan PutEmail ke seluruh tim.

Saya akan memberi tahu Anda secara detail tentang skrip, serta tentang pengalaman menerapkan analitik Perangkat Lunak Jira di perusahaan kami dalam artikel terpisah, yang akan siap beberapa hari yang lalu.
Singkatnya, pelaporan yang kami kembangkan memberikan pandangan strategis tentang apa yang sedang dilakukan suatu unit atau tim. Dan ini sangat berharga bagi bos mana pun, Anda harus setuju.
Kata Penutup
Mengapa melelahkan diri jika Anda bisa melakukan semua ini dengan skrip sekaligus, Anda bertanya. Ya, saya setuju, tetapi sebagian.
Apache NiFi tidak menyederhanakan proses pengembangan, tetapi menyederhanakan pengoperasian. Kami dapat menghentikan utas apa pun kapan saja, mengedit, dan memulai kembali.
Selain itu, NiFi memberi kita pandangan dari atas ke bawah tentang proses yang dijalankan perusahaan. Di grup berikutnya, saya akan memiliki skrip lain. Satu lagi akan menjadi uji coba rekan saya. Anda mengerti, bukan? Arsitektur di telapak tangan Anda. Seperti lelucon bos kami, kami menerapkan Apache NiFi sehingga kami dapat memecat Anda semua nanti, dan saya adalah satu-satunya yang menekan tombol. Tapi ini lelucon.
Nah, pada contoh ini roti-roti dalam bentuk tugas jadwal untuk menghasilkan laporan dan mengirim surat juga sangat-sangat menyenangkan.
Saya akui, saya berencana untuk mencurahkan jiwa saya dan memberi tahu Anda tentang penggaruk yang saya injak dalam proses mempelajari teknologi - berapa banyak dari mereka. Tapi di sini sudah lama dibaca. Jika topiknya menarik, beri tahu saya. Sementara itu teman-teman, terima kasih dan tunggu kamu di komentar.
tautan berguna
Artikel cerdik yang mencakup Apache NiFi tepat di jari Anda dan dengan huruf.
Panduan singkat dalam bahasa Rusia.
Lembar contekan Bahasa Ekspresi yang keren .
Komunitas Apache NiFi yang berbahasa Inggris terbuka untuk pertanyaan.
Komunitas Apache NiFi berbahasa Rusia di Telegram lebih hidup daripada semua makhluk hidup, silakan masuk.