
Apakah perusahaan Anda ingin mengumpulkan dan menganalisis data untuk mempelajari tren tanpa mengorbankan privasi? Atau mungkin Anda sudah menggunakan berbagai alat untuk melestarikannya dan ingin memperdalam ilmu atau berbagi pengalaman? Bagaimanapun, materi ini untuk Anda.
Apa yang mendorong kami untuk memulai rangkaian artikel ini? NIST (Institut Standar dan Teknologi Nasional) meluncurkan Ruang Kolaborasi Teknik Privasi tahun lalu- platform untuk kerja sama, yang berisi alat open source, serta solusi dan deskripsi proses yang diperlukan untuk desain kerahasiaan sistem dan manajemen risiko. Sebagai moderator ruang ini, kami membantu NIST mengumpulkan alat privasi diferensial yang tersedia di area anonimisasi. NIST juga menerbitkan Kerangka Privasi: Alat untuk Meningkatkan Privasi melalui Manajemen Risiko Perusahaan dan rencana tindakan yang menguraikan berbagai masalah privasi, termasuk anonimisasi. Sekarang kami ingin membantu Collaboration Space mencapai tujuan yang ditetapkan dalam rencana anonimisasi (de-identifikasi). Pada akhirnya, bantu NIST mengembangkan rangkaian publikasi ini menjadi panduan yang lebih dalam untuk privasi diferensial.
Setiap artikel akan dimulai dengan konsep dasar dan contoh aplikasi untuk membantu para profesional - seperti pemilik proses bisnis atau petugas privasi data - cukup belajar untuk menjadi berbahaya (bercanda). Setelah meninjau dasar-dasarnya, kami akan menganalisis alat yang tersedia dan pendekatan yang digunakan di dalamnya, yang akan berguna bagi mereka yang sedang mengerjakan penerapan tertentu.
Kami akan memulai artikel pertama kami dengan menjelaskan konsep dan konsep utama privasi diferensial, yang akan kami gunakan di artikel berikutnya.
Rumusan masalah
Bagaimana Anda dapat mempelajari data populasi tanpa mempengaruhi anggota populasi tertentu? Mari kita coba menjawab dua pertanyaan:
- Berapa banyak orang yang tinggal di Vermont?
- Berapa banyak orang yang bernama Joe Near tinggal di Vermont?
Pertanyaan pertama menyangkut properti seluruh populasi, dan pertanyaan kedua mengungkapkan informasi tentang orang tertentu. Kami harus dapat mengetahui tren untuk seluruh populasi, sementara tidak mengizinkan informasi tentang individu tertentu.
Tapi bagaimana kita bisa menjawab pertanyaan "berapa banyak orang yang tinggal di Vermont?" - yang selanjutnya akan kita sebut "penyelidikan" - tanpa menjawab pertanyaan kedua "Berapa banyak orang bernama Joe Nier yang tinggal di Vermont?" Solusi paling umum adalah de-identifikasi (atau anonimisasi), yang terdiri dari penghapusan semua informasi pengenal dari kumpulan data (selanjutnya, kami yakin bahwa kumpulan data kami berisi informasi tentang orang-orang tertentu). Pendekatan lain adalah dengan hanya mengizinkan kueri agregat, misalnya, dengan rata-rata. Sayangnya, sekarang kita sudah tahu bahwa tidak ada pendekatan yang memberikan perlindungan privasi yang diperlukan. Data yang dianonimkan adalah target serangan yang menjalin hubungan dengan database lain. Agregasi melindungi privasi hanya jika ukuran grup sampelnya adalahCukup besar. Tetapi bahkan dalam kasus seperti itu, serangan yang berhasil dimungkinkan [1, 2, 3, 4].
Privasi diferensial
Privasi diferensial [5, 6] adalah definisi matematis dari konsep "memiliki privasi". Ini bukan proses khusus, melainkan properti yang dapat dimiliki oleh suatu proses. Misalnya, Anda dapat menghitung (membuktikan) bahwa proses tertentu memenuhi prinsip privasi diferensial.
Sederhananya, untuk setiap orang yang datanya termasuk dalam kumpulan data yang sedang dianalisis, privasi diferensial memastikan bahwa hasil analisis privasi diferensial hampir tidak dapat dibedakan, terlepas dari apakah data Anda ada dalam kumpulan data atau tidak . Analisis privasi diferensial sering disebut sebagai mekanisme , dan kami akan menyebutnya sebagai...
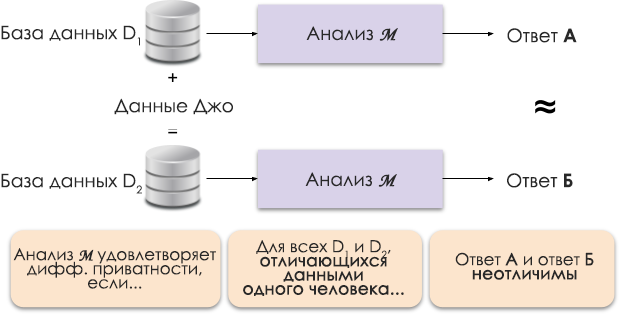
Gambar 1: Representasi skema privasi diferensial.
Prinsip privasi diferensial ditunjukkan pada Gambar 1. Jawaban A dihitung tanpa data Joe, dan jawaban B dengan datanya. Dan dikatakan bahwa kedua jawaban tersebut tidak dapat dibedakan. Artinya, siapa pun yang melihat hasilnya tidak akan dapat mengetahui dalam kasus apa data Joe digunakan, dan mana yang tidak.
Kami mengontrol tingkat privasi yang diperlukan dengan mengubah parameter privasi ε, yang juga disebut hilangnya privasi atau anggaran privasi. Semakin kecil nilai ε, semakin kurang dapat dibedakan hasilnya dan semakin aman data individu.
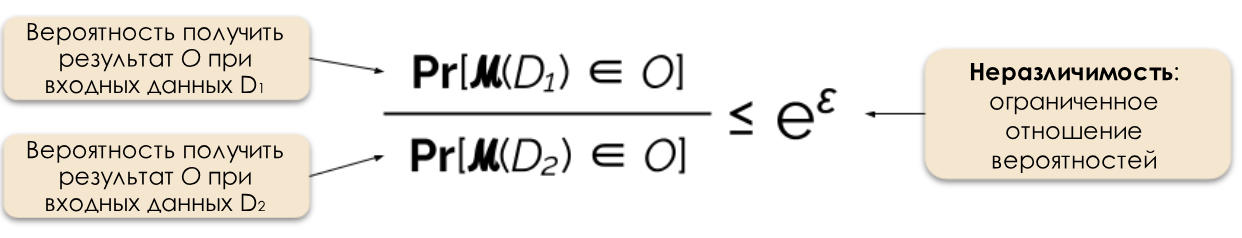
Gambar 2: Definisi formal privasi diferensial.
Seringkali kami dapat menanggapi permintaan dengan privasi diferensial dengan menambahkan gangguan acak ke respons. Kesulitannya terletak pada menentukan secara tepat di mana dan berapa banyak kebisingan yang akan ditambahkan. Salah satu mekanisme kebisingan yang paling populer adalah mekanisme Laplace [5, 7].
Permintaan privasi yang meningkat membutuhkan lebih banyak kebisingan untuk memenuhi nilai epsilon privasi diferensial tertentu. Dan kebisingan tambahan ini dapat mengurangi kegunaan dari hasil yang diperoleh. Di artikel mendatang, kami akan membahas lebih detail tentang privasi dan trade-off antara privasi dan kegunaan.
Manfaat privasi diferensial
Privasi diferensial memiliki beberapa keunggulan penting dibandingkan teknik sebelumnya.
- , , ( ) .
- , .
- : , . , . , .
Karena kelebihan ini, penerapan metode privasi diferensial dalam praktiknya lebih disukai daripada beberapa metode lain. Sisi lain dari masalah ini adalah bahwa metodologi ini cukup baru, dan tidak mudah untuk menemukan alat, standar, dan pendekatan yang telah terbukti di luar komunitas riset akademis. Namun, kami yakin bahwa situasi akan membaik dalam waktu dekat karena meningkatnya permintaan akan solusi yang andal dan sederhana untuk menjaga privasi data.
Apa berikutnya?
Berlanggananlah ke blog kami, dan segera kami akan menerbitkan terjemahan artikel berikutnya, yang menceritakan tentang model ancaman yang harus dipertimbangkan ketika membangun sistem untuk privasi diferensial, serta berbicara tentang perbedaan antara model privasi diferensial pusat dan lokal .
Sumber
[1] Garfinkel, Simson, John M. Abowd, dan Christian Martindale. "Memahami serangan rekonstruksi database pada data publik." Komunikasi ACM 62.3 (2019): 46-53.
[2] Gadotti, Andrea, dkk. "Ketika sinyal dalam kebisingan: memanfaatkan kebisingan lengket diffix." Simposium Keamanan USENIX ke-28 (Keamanan USENIX 19). 2019.
[3] Dinur, Irit, dan Kobbi Nissim. "Mengungkap informasi sambil menjaga privasi." Prosiding simposium ACM SIGMOD-SIGACT-SIGART dua puluh dua tentang Prinsip-prinsip sistem database. 2003.
[4] Sweeney, Latanya. "Demografi sederhana sering mengidentifikasi orang secara unik." Kesehatan (San Francisco) 671 (2000): 1-34.
[5] Dwork, Cynthia, dkk. "Mengkalibrasi noise ke sensitivitas dalam analisis data pribadi." Teori konferensi kriptografi. Springer, Berlin, Heidelberg, 2006.
[6] Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O'Brien, Thomas Steinke, dan Salil Vadhan. « Privasi diferensial: Panduan utama untuk audiens non-teknis. »Vand. J. Ent. & Teknologi. L. 21 (2018): 209.
[7] Dwork, Cynthia, dan Aaron Roth. "Dasar algoritmik dari privasi diferensial." Yayasan dan Tren Ilmu Komputer Teoretis 9, no. 3-4 (2014): 211-407.