Pada artikel ini saya akan menyentuh topik yang sedikit lebih kompleks dan menarik (setidaknya bagi saya, pengembang tim pencari): pencarian teks lengkap. Kami akan menambahkan node Elasticsearch ke wilayah penampung kami, mempelajari cara membuat indeks dan mencari konten, mengambil deskripsi lima ribu film dari TMDB 5000 Movie Dataset sebagai data pengujian... Kita juga akan belajar bagaimana membuat filter pencarian dan menggali lebih dalam tentang ranking.
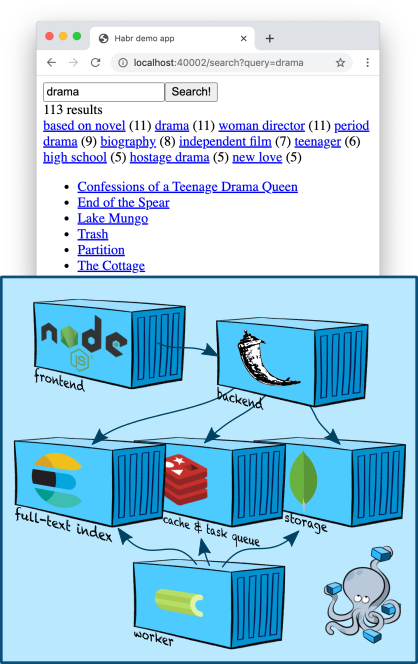
Infrastruktur: Elasticsearch
Elasticsearch adalah penyimpanan dokumen populer yang dapat membangun indeks teks lengkap dan, biasanya, digunakan secara khusus sebagai mesin pencari. Elasticsearch menambahkan ke mesin Apache Lucene , yang menjadi basisnya, sharding, replikasi, API JSON yang nyaman, dan jutaan detail lainnya yang menjadikannya salah satu solusi pencarian teks lengkap terpopuler.
Mari tambahkan satu simpul Elasticsearch ke kita
docker-compose.yml:
services:
...
elasticsearch:
image: "elasticsearch:7.5.1"
environment:
- discovery.type=single-node
ports:
- "9200:9200"
...
Variabel lingkungan
discovery.type=single-nodememberi tahu Elasticsearch untuk mempersiapkan pekerjaan sendiri, dan tidak mencari node lain dan menggabungkannya ke dalam cluster (ini adalah perilaku default).
Perhatikan bahwa kami menerbitkan port 9200 ke luar, meskipun aplikasi kami menavigasi di dalam jaringan yang dibuat oleh docker-compose. Ini murni untuk debugging: dengan cara ini kita dapat mengakses Elasticsearch langsung dari terminal (sampai kita menemukan cara yang lebih cerdas - lebih lanjut di bawah).
Menambahkan klien Elasticsearch di kabel kami tidaklah sulit - bagus, Elastic menyediakan klien Python minimalis .
Pengindeksan
Di artikel terakhir, kami menempatkan entitas utama kami - "kartu" ke dalam koleksi MongoDB. Kita dapat dengan cepat mengambil isinya dari koleksi dengan pengenal, karena MongoDB telah membuat indeks langsung untuk kita - ia menggunakan B-tree untuk ini .
Sekarang kita dihadapkan pada tugas kebalikan - oleh konten (atau fragmennya) untuk mendapatkan pengenal kartu. Oleh karena itu diperlukan reverse index . Di sinilah Elasticsearch berguna!
Skema umum untuk membangun indeks biasanya terlihat seperti ini.
- Buat indeks kosong baru dengan nama unik, konfigurasikan sesuai kebutuhan.
- Kami menelusuri semua entitas kami di database dan memasukkannya ke dalam indeks baru.
- Kami mengalihkan produksi sehingga semua kueri mulai menuju ke indeks baru.
- Menghapus indeks lama. Di sini, sesuka hati - Anda mungkin ingin menyimpan beberapa indeks terakhir, sehingga, misalnya, akan lebih mudah untuk men-debug beberapa masalah.
Mari buat kerangka pengindeks dan kemudian bahas lebih detail dengan setiap langkah.
import datetime
from elasticsearch import Elasticsearch, NotFoundError
from backend.storage.card import Card, CardDAO
class Indexer(object):
def __init__(self, elasticsearch_client: Elasticsearch, card_dao: CardDAO, cards_index_alias: str):
self.elasticsearch_client = elasticsearch_client
self.card_dao = card_dao
self.cards_index_alias = cards_index_alias
def build_new_cards_index(self) -> str:
# .
# .
index_name = "cards-" + datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
# .
# .
self.create_empty_cards_index(index_name)
# .
#
# .
for card in self.card_dao.get_all():
self.put_card_into_index(card, index_name)
return index_name
def create_empty_cards_index(self, index_name):
...
def put_card_into_index(self, card: Card, index_name: str):
...
def switch_current_cards_index(self, new_index_name: str):
...
Pengindeksan: membuat indeks
Indeks di Elasticsearch dibuat dengan permintaan PUT sederhana ke
/-atau, dalam kasus menggunakan klien Python (dalam kasus kami), dengan memanggil
elasticsearch_client.indices.create(index_name, {
...
})
Badan permintaan dapat berisi tiga bidang.
- Deskripsi alias (
"aliases": ...). Sistem alias memungkinkan Anda untuk tetap mengetahui indeks mana yang saat ini mutakhir di sisi Elasticsearch; kami akan membicarakannya di bawah. - Pengaturan (
"settings": ...). Saat kita menjadi orang besar dengan produksi nyata, kita akan dapat mengonfigurasi replikasi, sharding, dan kegembiraan SRE lainnya di sini. - Skema data (
"mappings": ...). Di sini kita dapat menentukan jenis field apa dalam dokumen yang akan kita indeks, untuk field mana kita memerlukan indeks inversi, agregasi mana yang harus didukung, dan seterusnya.
Sekarang kami hanya tertarik pada skema, dan kami membuatnya sangat sederhana:
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "english"
},
"text": {
"type": "text",
"analyzer": "english"
},
"tags": {
"type": "keyword",
"fields": {
"text": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
Kami telah menandai bidang tersebut
name, dan textsebagai teks dalam bahasa Inggris. Parser adalah entitas di Elasticsearch yang memproses teks sebelum menyimpannya ke dalam indeks. Dalam kasus englishpenganalisis, teks akan dipecah menjadi token di sepanjang batas kata ( detail ), setelah itu token individu akan lemmatized sesuai dengan aturan bahasa Inggris (misalnya, kata treesakan disederhanakan menjadi tree), lemma yang terlalu umum (semacam the) akan dihapus dan lemma yang tersisa akan dimasukkan ke dalam indeks terbalik.
Lapangannya
tagssedikit lebih rumit. Sebuah tipekeywordmengasumsikan bahwa nilai bidang ini adalah beberapa konstanta string yang tidak perlu diproses oleh penganalisis; indeks terbalik akan dibuat berdasarkan nilai "mentah" - tanpa tokenisasi dan lemmatisasi. Tetapi Elasticsearch akan membuat struktur data khusus sehingga agregasi dapat dibaca oleh nilai kolom ini (misalnya, sehingga, bersamaan dengan pencarian, Anda dapat mengetahui tag mana yang ditemukan dalam dokumen yang memenuhi permintaan pencarian, dan berapa jumlahnya). Ini bagus untuk bidang yang pada dasarnya adalah enum; kami akan menggunakan fitur ini untuk membuat beberapa filter pencarian keren.
Tetapi agar teks dari tag dapat dicari dengan pencarian teks juga, kami menambahkan subkolom padanya
"text", dikonfigurasi dengan analogi dengan namedantextdi atas - pada dasarnya, ini berarti bahwa Elasticsearch akan membuat bidang "virtual" lain dengan nama di semua dokumen yang diterimanya tags.text, yang akan digunakan untuk menyalin konten tags, tetapi mengindeksnya sesuai dengan aturan yang berbeda.
Indexing: mengisi index
Untuk mengindeks dokumen, cukup membuat permintaan PUT ke
/-/_create/id-atau, saat menggunakan klien Python, panggil saja metode yang diperlukan. Implementasi kami akan terlihat seperti ini:
def put_card_into_index(self, card: Card, index_name: str):
self.elasticsearch_client.create(index_name, card.id, {
"name": card.name,
"text": card.markdown,
"tags": card.tags,
})
Perhatikan bidangnya
tags. Meskipun kami mendeskripsikannya sebagai berisi kata kunci, kami tidak mengirimkan satu string pun, tetapi daftar string. Elasticsearch mendukung ini; dokumen kita akan ditempatkan di salah satu nilai.
Pengindeksan: mengganti indeks
Untuk mengimplementasikan pencarian, kita perlu mengetahui nama dari index terbaru yang dibangun sepenuhnya. Mekanisme alias memungkinkan kami menyimpan informasi ini di sisi Elasticsearch.
Alias adalah penunjuk ke nol atau lebih indeks. API Elasticsearch memungkinkan Anda menggunakan nama alias alih-alih nama indeks saat mencari (POST
/-/_searchalih-alih POST /-/_search); dalam hal ini, Elasticsearch akan mencari semua indeks yang ditunjuk oleh alias.
Kami akan membuat alias dipanggil
cards, yang akan selalu mengarah ke indeks saat ini. Karenanya, peralihan ke indeks aktual setelah konstruksi selesai akan terlihat seperti ini:
def switch_current_cards_index(self, new_index_name: str):
try:
# , .
remove_actions = [
{
"remove": {
"index": index_name,
"alias": self.cards_index_alias,
}
}
for index_name in self.elasticsearch_client.indices.get_alias(name=self.cards_index_alias)
]
except NotFoundError:
# , - .
# , .
remove_actions = []
#
# .
self.elasticsearch_client.indices.update_aliases({
"actions": remove_actions + [{
"add": {
"index": new_index_name,
"alias": self.cards_index_alias,
}
}]
})
Saya tidak akan membahas lebih detail tentang alias API; semua detailnya dapat ditemukan di dokumentasi .
Di sini perlu dibuat pernyataan bahwa dalam layanan yang sangat sarat muatan, peralihan semacam itu bisa sangat menyakitkan dan mungkin masuk akal untuk melakukan pemanasan awal - memuat indeks baru dengan semacam kumpulan kueri pengguna yang disimpan.
Semua kode yang mengimplementasikan pengindeksan dapat ditemukan di komit ini .
Pengindeksan: menambahkan konten
Untuk demonstrasi di artikel ini, saya menggunakan data dari TMDB 5000 Movie Dataset . Untuk menghindari masalah hak cipta, saya hanya memberikan kode untuk utilitas yang mengimpornya dari file CSV, yang saya sarankan Anda unduh sendiri dari situs web Kaggle. Setelah mengunduh, jalankan saja perintahnya
docker-compose exec -T backend python -m tools.add_movies < ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv
untuk membuat lima ribu kartu film dan sebuah tim
docker-compose exec backend python -m tools.build_index
untuk membuat indeks. Harap dicatat bahwa perintah terakhir tidak benar-benar membangun indeks, tetapi hanya menempatkan tugas di antrian tugas, setelah itu akan dieksekusi pada pekerja - Saya membahas pendekatan ini lebih detail di artikel terakhir .
docker-compose logs workertunjukkan bagaimana pekerja itu mencoba!
Sebelum kita mulai, sebenarnya, pencarian, kita ingin melihat dengan mata kepala kita sendiri apakah ada sesuatu yang tertulis di Elasticsearch, dan jika demikian, bagaimana tampilannya!
Cara paling langsung dan tercepat untuk melakukannya adalah dengan menggunakan API HTTP Elasticsearch. Pertama, mari kita periksa di mana alias menunjuk ke:
$ curl -s localhost:9200/_cat/aliases
cards cards-2020-09-20-16-14-18 - - - -
Bagus, indeksnya ada! Mari kita lihat lebih dekat:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18 | jq
{
"cards-2020-09-20-16-14-18": {
"aliases": {
"cards": {}
},
"mappings": {
...
},
"settings": {
"index": {
"creation_date": "1600618458522",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "iLX7A8WZQuCkRSOd7mjgMg",
"version": {
"created": "7050199"
},
"provided_name": "cards-2020-09-20-16-14-18"
}
}
}
}
Terakhir, mari kita lihat isinya:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18/_search | jq
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4704,
"relation": "eq"
},
"max_score": 1,
"hits": [
...
]
}
}
Secara total, indeks kami adalah 4704 dokumen, dan di lapangan
hits(yang saya lewati karena terlalu besar) Anda bahkan dapat melihat isi beberapa di antaranya. Keberhasilan!
Cara yang lebih mudah untuk menelusuri konten indeks dan secara umum segala jenis memanjakan dengan Elasticsearch adalah dengan menggunakan Kibana . Mari tambahkan wadah ke
docker-compose.yml:
services:
...
kibana:
image: "kibana:7.5.1"
ports:
- "5601:5601"
depends_on:
- elasticsearch
...
Setelah kedua kalinya,
docker-compose upkita bisa pergi ke Kibana di alamat localhost:5601(perhatian, server mungkin tidak memulai dengan cepat) dan, setelah pengaturan singkat, lihat isi indeks kita di antarmuka web yang bagus.
Saya sangat merekomendasikan tab Alat Dev - selama pengembangan, Anda akan sering kali perlu membuat permintaan tertentu di Elasticsearch, dan dalam mode interaktif dengan pelengkapan otomatis dan pemformatan otomatis, jauh lebih nyaman.
Cari
Setelah semua persiapan yang sangat membosankan, sekarang saatnya kita menambahkan fungsionalitas pencarian ke aplikasi web kita!
Mari bagi tugas non-sepele ini menjadi tiga tahap dan diskusikan masing-masing secara terpisah.
- Tambahkan komponen yang
Searcherbertanggung jawab untuk logika pencarian ke backend . Ini akan membentuk kueri ke Elasticsearch dan mengubah hasilnya menjadi lebih mudah dicerna untuk backend kami. - Tambahkan titik akhir ke API (pegangan / rute / apa yang Anda sebut di perusahaan Anda?) Yang
/cards/searchmelakukan pencarian. Ini akan memanggil metode komponenSearcher, memproses hasil yang dihasilkan, dan mengembalikannya ke klien. - Mari terapkan antarmuka pencarian di frontend. Ini akan menghubungi
/cards/searchketika pengguna telah memutuskan apa yang ingin dia cari, dan menampilkan hasil (dan, mungkin, beberapa kontrol tambahan).
Pencarian: kami menerapkan
Tidak terlalu sulit untuk menulis pengelola pencarian untuk merancangnya. Mari kita gambarkan hasil pencarian dan antarmuka pengelola dan diskusikan mengapa demikian dan tidak berbeda.
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0) -> CardSearchResult:
pass
Beberapa hal sudah jelas. Misalnya, pagination. Kami adalah startup
Beberapa kurang jelas. Misalnya, daftar ID, bukan kartu sebagai hasilnya. Elasticsearch menyimpan seluruh dokumen kami secara default dan mengembalikannya dalam hasil pencarian. Perilaku ini dapat dimatikan untuk menghemat ukuran indeks pencarian, tetapi ini jelas merupakan pengoptimalan prematur bagi kami. Jadi mengapa tidak segera mengembalikan kartunya? Jawaban: ini akan melanggar prinsip tanggung jawab tunggal. Mungkin suatu hari nanti kita akan menemukan logika kompleks di pengelola kartu yang menerjemahkan kartu ke bahasa lain tergantung pada pengaturan pengguna. Tepat saat ini, data di halaman kartu dan data di hasil pencarian akan tersebar, karena kita akan lupa menambahkan logika yang sama ke pengelola pencarian. Dan lain sebagainya.
Implementasi antarmuka ini sangat sederhana sehingga saya terlalu malas untuk menulis bagian ini :-(
# backend/backend/search/searcher_impl.py
from typing import Any
from elasticsearch import Elasticsearch
from backend.search.searcher import CardSearchResult, Searcher
ElasticsearchQuery = Any #
class ElasticsearchSearcher(Searcher):
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query
})
total_count = result["hits"]["total"]["value"]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
)
def _make_text_query(self, query: str) -> ElasticsearchQuery:
return {
# Multi-match query
# ( match
# query, ).
"multi_match": {
"query": query,
# ^ – .
# , .
"fields": ["name^3", "tags.text", "text"],
}
}
_match_all_query: ElasticsearchQuery = {"match_all": {}}
Faktanya, kami hanya pergi ke API Elasticsearch dan dengan hati-hati mengekstrak ID dari kartu yang ditemukan dari hasilnya.
Implementasi endpoint juga cukup sepele:
# backend/backend/server.py
...
def search_cards(self):
request = flask.request.json
search_result = self.wiring.searcher.search_cards(**request)
cards = self.wiring.card_dao.get_by_ids(search_result.card_ids)
return flask.jsonify({
"totalCount": search_result.total_count,
"cards": [
{
"id": card.id,
"slug": card.slug,
"name": card.name,
# ,
# ,
# .
} for card in cards
],
"nextCardOffset": search_result.next_card_offset,
})
...
Implementasi frontend menggunakan endpoint ini, meskipun banyak, umumnya cukup mudah dan saya tidak ingin fokus pada artikel ini. Seluruh kode dapat dilihat dalam komit ini .

Sejauh ini bagus, mari kita lanjutkan.
 Pencarian: menambahkan filter
Pencarian: menambahkan filter
Pencarian teks itu keren, tetapi jika Anda pernah mencari sumber daya yang serius, Anda mungkin pernah melihat segala macam barang seperti filter.
Deskripsi kami tentang film dari database TMDB 5000 memiliki tag selain judul dan deskripsi, jadi mari kita terapkan filter menurut tag untuk pelatihan. Tujuan kami ada di tangkapan layar: saat Anda mengeklik sebuah tag, hanya film dengan tag ini yang harus tetap berada di hasil penelusuran (nomornya ditunjukkan dalam tanda kurung di sebelahnya).

Untuk menerapkan filter, kita perlu menyelesaikan dua masalah.
- Belajar untuk memahami set filter yang tersedia sesuai permintaan. Kami tidak ingin menampilkan semua nilai filter yang mungkin pada setiap layar, karena ada banyak nilai dan sebagian besar akan mengarah ke hasil kosong; Anda perlu memahami tag apa yang dimiliki dokumen yang ditemukan berdasarkan permintaan, dan idealnya membiarkan N paling populer.
- Untuk mempelajari, pada kenyataannya, untuk menerapkan filter - untuk membiarkan dalam hasil pencarian hanya dokumen dengan tag, filter yang dipilih pengguna.
Yang kedua di Elasticsearch hanya diimplementasikan melalui API kueri (lihat kueri istilah ), yang pertama adalah melalui mekanisme agregasi yang sedikit lebih sederhana .
Jadi, kita perlu mengetahui tag apa yang ditemukan di kartu yang ditemukan, dan dapat memfilter kartu dengan tag yang diperlukan. Pertama, mari perbarui desain manajer pencarian:
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class TagStats:
tag: str
cards_count: int
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
tag_stats: Iterable[TagStats]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0,
tags: Optional[Iterable[str]] = None) -> CardSearchResult:
pass
Sekarang mari kita lanjutkan ke implementasinya. Hal pertama yang perlu kita lakukan adalah memulai agregasi berdasarkan lapangan
tags:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -10,6 +10,8 @@ ElasticsearchQuery = Any
class ElasticsearchSearcher(Searcher):
+ TAGS_AGGREGATION_NAME = "tags_aggregation"
+
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
@@ -18,7 +20,12 @@ class ElasticsearchSearcher(Searcher):
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query,
+ "aggregations": {
+ self.TAGS_AGGREGATION_NAME: {
+ "terms": {"field": "tags"}
+ }
+ }
})
Sekarang, di hasil pencarian dari Elasticsearch, sebuah field akan muncul
aggregationsdari mana, dengan menggunakan sebuah kunci, TAGS_AGGREGATION_NAMEkita bisa mendapatkan bucket yang berisi informasi tentang nilai apa yang ada di field tagsuntuk dokumen yang ditemukan dan seberapa sering mereka muncul. Mari ekstrak data ini dan kembalikan seperti yang dirancang di atas:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -28,10 +28,15 @@ class ElasticsearchSearcher(Searcher):
total_count = result["hits"]["total"]["value"]
+ tag_stats = [
+ TagStats(tag=bucket["key"], cards_count=bucket["doc_count"])
+ for bucket in result["aggregations"][self.TAGS_AGGREGATION_NAME]["buckets"]
+ ]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
+ tag_stats=tag_stats,
)
Menambahkan aplikasi filter adalah bagian yang paling mudah:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -16,11 +16,17 @@ class ElasticsearchSearcher(Searcher):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
- def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
+ def search_cards(self, query: str = "", count: int = 20, offset: int = 0,
+ tags: Optional[Iterable[str]] = None) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
- "query": self._make_text_query(query) if query else self._match_all_query,
+ "query": {
+ "bool": {
+ "must": self._make_text_queries(query),
+ "filter": self._make_filter_queries(tags),
+ }
+ },
"aggregations": {
Subquery yang termasuk dalam must-clause bersifat wajib, tetapi juga akan diperhitungkan saat menghitung kecepatan dokumen dan, karenanya, peringkat; jika kita pernah menambahkan beberapa ketentuan lagi pada teks, lebih baik menambahkannya di sini. Subkueri di klausa filter hanya memfilter tanpa memengaruhi kecepatan dan peringkat.
Tetap menerapkan
_make_filter_queries():
def _make_filter_queries(self, tags: Optional[Iterable[str]] = None) -> List[ElasticsearchQuery]:
return [] if tags is None else [{
"term": {
"tags": {
"value": tag
}
}
} for tag in tags]
Sekali lagi, saya tidak akan memikirkan bagian depan; semua kode ada di komit ini .
Mulai
Jadi, pencarian kami mencari kartu, memfilternya sesuai dengan daftar tag yang diberikan dan menampilkannya dalam beberapa urutan. Tapi yang mana? Urutan sangat penting untuk pencarian praktis, tetapi semua yang kami lakukan selama proses pengadilan dalam hal urutan telah mengisyaratkan kepada Elasticsearch bahwa menemukan kata-kata dalam tajuk kartu lebih menguntungkan daripada dalam deskripsi atau tag dengan menentukan prioritas
^3dalam kueri multi-pencocokan.
Terlepas dari kenyataan bahwa secara default Elasticsearch memeringkat dokumen dengan formula berbasis TF-IDF yang agak rumit, untuk startup ambisius imajiner kami, ini tidaklah cukup. Jika dokumen kita adalah barang, kita harus bisa mempertanggungjawabkan penjualannya; jika itu adalah konten yang dibuat pengguna, dapat mempertimbangkan kesegarannya, dan sebagainya. Tetapi kami tidak bisa begitu saja mengurutkan berdasarkan jumlah penjualan / tanggal penambahan, karena kami tidak akan memperhitungkan relevansinya dengan kueri penelusuran.
Peringkat adalah bidang teknologi yang besar dan membingungkan yang tidak dapat dibahas dalam satu bagian di akhir artikel ini. Jadi di sini saya beralih ke pukulan besar; Saya akan mencoba memberi tahu dalam istilah paling umum bagaimana peringkat kelas industri dapat diatur dalam pencarian, dan saya akan mengungkapkan beberapa detail teknis tentang bagaimana hal itu dapat diterapkan dengan Elasticsearch.
Tugas pemeringkatan sangat kompleks, sehingga tidak mengherankan bahwa salah satu metode modern utama untuk menyelesaikannya adalah pembelajaran mesin. Penerapan teknologi pembelajaran mesin ke peringkat secara kolektif disebut belajar untuk menentukan peringkat .
Proses tipikal terlihat seperti ini.
Kami memutuskan apa yang ingin kami rangking . Kami menempatkan entitas yang kami minati di indeks, mempelajari cara mendapatkan beberapa teratas yang masuk akal (misalnya, beberapa penyortiran dan pemotongan sederhana) dari entitas ini untuk kueri penelusuran tertentu, dan sekarang kami ingin mempelajari cara memberi peringkat dengan cara yang lebih cerdas.
Menentukan bagaimana kita ingin menentukan peringkat... Kami memutuskan karakteristik apa yang kami inginkan untuk memberi peringkat hasil kami sesuai dengan tujuan bisnis layanan kami. Misalnya, jika entitas kita adalah produk yang kita jual, kita mungkin ingin mengurutkan mereka dalam urutan kemungkinan pembelian; jika meme - kemungkinan suka atau berbagi, dan sebagainya. Kami, tentu saja, tidak tahu bagaimana menghitung probabilitas ini - paling banter kami dapat memperkirakan, dan bahkan hanya untuk entitas lama yang statistiknya cukup kami miliki - tetapi kami akan mencoba mengajarkan model untuk memprediksinya berdasarkan tanda tidak langsung.
Mengekstraksi tanda... Kami menghadirkan sekumpulan fitur untuk entitas kami yang dapat membantu kami menilai relevansi entitas dengan kueri penelusuran. Selain TF-IDF yang sama, yang sudah mengetahui cara menghitung Elasticsearch untuk kami, contoh tipikal adalah CTR (rasio klik-tayang): kami mengambil log layanan kami sepanjang waktu, untuk setiap pasangan entitas + kueri penelusuran kami menghitung berapa kali entitas muncul di hasil pencarian untuk permintaan ini dan berapa kali diklik, kita bagi satu per satu, et voilà - perkiraan paling sederhana dari probabilitas klik bersyarat sudah siap. Kami juga dapat menemukan ciri khusus pengguna dan ciri berpasangan entitas pengguna untuk mempersonalisasi peringkat. Setelah mendapatkan tanda, kami menulis kode yang menghitungnya, menempatkannya di semacam penyimpanan, dan mengetahui cara memberikannya secara real time untuk kueri penelusuran tertentu, pengguna, dan sekumpulan entitas.
Menyusun kumpulan data pelatihan . Ada banyak opsi, tetapi semuanya, sebagai aturan, dibentuk dari log peristiwa "baik" (misalnya, klik dan kemudian pembelian) dan "buruk" (misalnya, klik dan kembali ke masalah) di layanan kami. Ketika kami telah mengumpulkan kumpulan data, baik itu daftar pernyataan "penilaian relevansi produk X ke kueri Q kira-kira sama dengan P", daftar pasangan "produk X lebih relevan dengan produk Y untuk kueri Q" atau serangkaian daftar "untuk kueri Q, produk P 1 , P 2 , ... peringkat dengan benar seperti ini -bahwa ", kami mengencangkan tanda yang sesuai ke semua garis yang muncul di dalamnya.
Kami melatih modelnya . Berikut semua ML klasik: latih / uji, hiperparameter, pelatihan ulang,
Kami menyematkan modelnya . Tetap bagi kita, dengan satu atau lain cara, untuk mengacaukan perhitungan model dengan cepat untuk keseluruhan atas, sehingga hasil yang sudah diperingkat mencapai pengguna. Ada banyak pilihan; untuk tujuan ilustrasi, saya akan (sekali lagi) fokus pada plugin Elasticsearch sederhana, Learning to Rank .
Peringkat: Elasticsearch Learning to Rank Plugin
Elasticsearch Learning to Rank adalah plugin yang menambah kemampuan Elasticsearch untuk menghitung model ML di SERP dan segera memberi peringkat hasil sesuai dengan tarif yang dihitung. Ini juga akan membantu kami mendapatkan fitur yang identik dengan yang digunakan secara real time, sambil menggunakan kembali kemampuan Elasticsearch (TF-IDF dan sejenisnya).
Pertama, kita perlu menghubungkan plugin di penampung kita dengan Elasticsearch. Kami membutuhkan Dockerfile sederhana
# elasticsearch/Dockerfile
FROM elasticsearch:7.5.1
RUN ./bin/elasticsearch-plugin install --batch http://es-learn-to-rank.labs.o19s.com/ltr-1.1.2-es7.5.1.zip
dan perubahan terkait ke
docker-compose.yml:
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -5,7 +5,8 @@ services:
elasticsearch:
- image: "elasticsearch:7.5.1"
+ build:
+ context: elasticsearch
environment:
- discovery.type=single-node
Kami juga membutuhkan dukungan plugin di klien Python. Saya kagum menemukan bahwa dukungan untuk Python tidak disertakan dengan plugin, jadi saya menuliskannya khusus untuk artikel ini . Tambahkan
elasticsearch_ltrke requirements.txtdan upgrade klien di kabel:
--- a/backend/backend/wiring.py
+++ b/backend/backend/wiring.py
@@ -1,5 +1,6 @@
import os
+from elasticsearch_ltr import LTRClient
from celery import Celery
from elasticsearch import Elasticsearch
from pymongo import MongoClient
@@ -39,5 +40,6 @@ class Wiring(object):
self.task_manager = TaskManager(self.celery_app)
self.elasticsearch_client = Elasticsearch(hosts=self.settings.ELASTICSEARCH_HOSTS)
+ LTRClient.infect_client(self.elasticsearch_client)
self.indexer = Indexer(self.elasticsearch_client, self.card_dao, self.settings.CARDS_INDEX_ALIAS)
self.searcher: Searcher = ElasticsearchSearcher(self.elasticsearch_client, self.settings.CARDS_INDEX_ALIAS)
Peringkat: tanda gergaji
Setiap permintaan di Elasticsearch tidak hanya mengembalikan daftar ID dokumen yang ditemukan, tetapi juga beberapa di antaranya segera (bagaimana Anda menerjemahkan skor kata ke dalam bahasa Rusia?). Jadi, jika ini adalah kueri kecocokan atau multi-kecocokan yang kita gunakan, maka cepat adalah hasil dari penghitungan rumus yang sangat rumit yang melibatkan TF-IDF; jika kueri bool adalah kombinasi dari tingkat kueri bersarang; jika kueri skor fungsi- hasil penghitungan fungsi tertentu (misalnya, nilai beberapa bidang numerik dalam dokumen), dan seterusnya. Plugin ELTR memberi kami kemampuan untuk menggunakan kecepatan kueri apa pun sebagai tanda, memungkinkan kami untuk dengan mudah menggabungkan data tentang seberapa cocok dokumen tersebut dengan permintaan (melalui kueri multi-pencocokan) dan beberapa statistik yang telah dihitung sebelumnya yang kami masukkan ke dalam dokumen sebelumnya (melalui kueri skor fungsi) ...
Karena kami memiliki basis data TMDB 5000 di tangan kami, yang berisi deskripsi film dan, antara lain, peringkatnya, anggap saja peringkat tersebut sebagai fitur teladan yang telah dihitung sebelumnya.
Dalam komit iniSaya menambahkan beberapa infrastruktur dasar untuk menyimpan fitur ke bagian belakang aplikasi web kami dan mendukung pemuatan peringkat dari file film. Agar tidak memaksa Anda untuk membaca sekumpulan kode lain, saya akan menjelaskan yang paling dasar.
- Kami akan menyimpan fitur dalam koleksi terpisah dan mendapatkannya oleh manajer terpisah. Membuang semua data menjadi satu entitas adalah praktik yang buruk.
- Kami akan menghubungi manajer ini pada tahap pengindeksan dan meletakkan semua tanda yang tersedia di dokumen yang diindeks.
- Untuk mengetahui skema indeks, kita perlu mengetahui daftar semua fitur yang ada sebelum memulai pembuatan indeks. Kami akan membuat hardcode daftar ini untuk saat ini.
- Karena kami tidak akan memfilter dokumen berdasarkan nilai fitur, tetapi hanya akan mengekstraknya dari dokumen yang sudah ditemukan untuk menghitung model, kami akan menonaktifkan pembuatan indeks inversi dengan kolom baru dengan opsi
index: falsedi skema dan menghemat sedikit ruang karena hal ini.
Peringkat: mengumpulkan dataset
Karena, pertama, kami tidak memiliki produksi, dan kedua, margin artikel ini terlalu kecil untuk cerita tentang telemetri, Kafka, NiFi, Hadoop, Spark, dan proses pembuatan ETL, saya hanya akan membuat tampilan dan klik acak untuk kartu kami dan semacam kueri penelusuran. Setelah itu, Anda perlu menghitung karakteristik pasangan kartu-permintaan yang dihasilkan.
Saatnya untuk menggali lebih dalam API plugin ELTR. Untuk menghitung fitur, kita perlu membuat entitas penyimpanan fitur (sejauh yang saya mengerti, ini sebenarnya hanya indeks di Elasticsearch tempat plugin menyimpan semua datanya), lalu membuat kumpulan fitur - daftar fitur dengan deskripsi cara menghitung masing-masing. Setelah itu, kita cukup membuka Elasticsearch dengan permintaan khusus untuk mendapatkan vektor nilai fitur untuk setiap entitas yang ditemukan sebagai hasilnya.
Mari kita mulai dengan membuat satu set fitur:
# backend/backend/search/ranking.py
from typing import Iterable, List, Mapping
from elasticsearch import Elasticsearch
from elasticsearch_ltr import LTRClient
from backend.search.features import CardFeaturesManager
class SearchRankingManager:
DEFAULT_FEATURE_SET_NAME = "card_features"
def __init__(self, elasticsearch_client: Elasticsearch,
card_features_manager: CardFeaturesManager,
cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.card_features_manager = card_features_manager
self.cards_index_name = cards_index_name
def initialize_ranking(self, feature_set_name=DEFAULT_FEATURE_SET_NAME):
ltr: LTRClient = self.elasticsearch_client.ltr
try:
# feature store ,
# ¯\_(ツ)_/¯
ltr.create_feature_store()
except Exception as exc:
if "resource_already_exists_exception" not in str(exc):
raise
# feature set !
ltr.create_feature_set(feature_set_name, {
"featureset": {
"features": [
#
# ,
# ,
# .
self._make_feature("name_tf_idf", ["query"], {
"match": {
# ELTR
# , .
# , ,
# ,
# match query.
"name": "{{query}}"
}
}),
# , .
self._make_feature("combined_tf_idf", ["query"], {
"multi_match": {
"query": "{{query}}",
"fields": ["name^3", "tags.text", "text"]
}
}),
*(
#
# function score.
# -
# , 0.
# (
# !)
self._make_feature(feature_name, [], {
"function_score": {
"field_value_factor": {
"field": feature_name,
"missing": 0
}
}
})
for feature_name in sorted(self.card_features_manager.get_all_feature_names_set())
)
]
}
})
@staticmethod
def _make_feature(name, params, query):
return {
"name": name,
"params": params,
"template_language": "mustache",
"template": query,
}
Sekarang - fungsi yang menghitung fitur untuk kueri dan kartu tertentu:
def compute_cards_features(self, query: str, card_ids: Iterable[str],
feature_set_name=DEFAULT_FEATURE_SET_NAME) -> Mapping[str, List[float]]:
card_ids = list(card_ids)
result = self.elasticsearch_client.search({
"query": {
"bool": {
# ,
# — ,
# .
# ID.
"filter": [
{
"terms": {
"_id": card_ids
}
},
# — ,
# SLTR.
#
# feature set.
# ( ,
# filter, .)
{
"sltr": {
"_name": "logged_featureset",
"featureset": feature_set_name,
"params": {
# .
# , ,
#
# {{query}}.
"query": query
}
}
}
]
}
},
#
# .
"ext": {
"ltr_log": {
"log_specs": {
"name": "log_entry1",
"named_query": "logged_featureset"
}
}
},
"size": len(card_ids),
})
# (
# ) .
# ( ,
# , Kibana.)
return {
hit["_id"]: [feature.get("value", float("nan")) for feature in hit["fields"]["_ltrlog"][0]["log_entry1"]]
for hit in result["hits"]["hits"]
}
Skrip sederhana yang menerima CSV dengan permintaan dan kartu ID sebagai input dan output CSV dengan fitur berikut:
# backend/tools/compute_movie_features.py
import csv
import itertools
import sys
import tqdm
from backend.wiring import Wiring
if __name__ == "__main__":
wiring = Wiring()
reader = iter(csv.reader(sys.stdin))
header = next(reader)
feature_names = wiring.search_ranking_manager.get_feature_names()
writer = csv.writer(sys.stdout)
writer.writerow(["query", "card_id"] + feature_names)
query_index = header.index("query")
card_id_index = header.index("card_id")
chunks = itertools.groupby(reader, lambda row: row[query_index])
for query, rows in tqdm.tqdm(chunks):
card_ids = [row[card_id_index] for row in rows]
features = wiring.search_ranking_manager.compute_cards_features(query, card_ids)
for card_id in card_ids:
writer.writerow((query, card_id, *features[card_id]))
Akhirnya, Anda bisa menjalankan semuanya!
# feature set
docker-compose exec backend python -m tools.initialize_search_ranking
#
docker-compose exec -T backend \
python -m tools.generate_movie_events \
< ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv \
> ~/Downloads/habr-app-demo-dataset-events.csv
#
docker-compose exec -T backend \
python -m tools.compute_features \
< ~/Downloads/habr-app-demo-dataset-events.csv \
> ~/Downloads/habr-app-demo-dataset-features.csv
Sekarang kami memiliki dua file - dengan acara dan tanda - dan kami dapat memulai pelatihan.
Peringkat: latih dan terapkan model
Mari lewati detail memuat dataset (Anda dapat melihat skrip lengkap dalam komit ini ) dan langsung ke intinya.
# backend/tools/train_model.py
...
if __name__ == "__main__":
args = parser.parse_args()
feature_names, features = read_features(args.features)
events = read_events(args.events)
# train test 4 1.
all_queries = set(events.keys())
train_queries = random.sample(all_queries, int(0.8 * len(all_queries)))
test_queries = all_queries - set(train_queries)
# DMatrix — , xgboost.
#
# . 1, ,
# 0, ( . ).
train_dmatrix = make_dmatrix(train_queries, events, feature_names, features)
test_dmatrix = make_dmatrix(test_queries, events, feature_names, features)
# !
#
# ML,
# XGBoost.
param = {
"max_depth": 2,
"eta": 0.3,
"objective": "binary:logistic",
"eval_metric": "auc",
}
num_round = 10
booster = xgboost.train(param, train_dmatrix, num_round, evals=((train_dmatrix, "train"), (test_dmatrix, "test")))
# .
booster.dump_model(args.output, dump_format="json")
# , :
# ROC-.
xgboost.plot_importance(booster)
plt.figure()
build_roc(test_dmatrix.get_label(), booster.predict(test_dmatrix))
plt.show()
Meluncurkan
python backend/tools/train_search_ranking_model.py \
--events ~/Downloads/habr-app-demo-dataset-events.csv \
--features ~/Downloads/habr-app-demo-dataset-features.csv \
-o ~/Downloads/habr-app-demo-model.xgb
Harap dicatat bahwa karena kami mengekspor semua data yang diperlukan dengan skrip sebelumnya, skrip ini tidak lagi perlu dijalankan di dalam buruh pelabuhan - harus dijalankan di komputer Anda, setelah sebelumnya diinstal
xgboostdan sklearn. Demikian pula, dalam produksi nyata, skrip sebelumnya perlu dijalankan di suatu tempat di mana ada akses ke lingkungan produksi, tetapi yang ini tidak.
Jika semuanya dilakukan dengan benar, model akan berhasil dilatih dan kita akan melihat dua gambar yang indah. Yang pertama adalah grafik signifikansi fitur:

Meskipun peristiwa dibuat secara acak,
combined_tf_idfternyata jauh lebih signifikan daripada yang lain - karena saya membuat trik dan secara artifisial menurunkan kemungkinan klik untuk kartu yang lebih rendah dalam hasil penelusuran, diberi peringkat dengan cara lama kita. Fakta bahwa model memperhatikan ini adalah pertanda baik dan pertanda bahwa kami tidak membuat kesalahan yang sama sekali bodoh dalam proses pembelajaran.
Grafik kedua adalah kurva KOP : Garis

biru berada di atas garis merah, yang berarti model kami memprediksi label sedikit lebih baik daripada lemparan koin. (Kurva insinyur ML teman ibu seharusnya hampir menyentuh sudut kiri atas.)
Masalahnya cukup kecil - kami menambahkan skrip untuk mengisi model , mengisinya dan menambahkan item kecil baru ke kueri penelusuran - menilai ulang:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -27,6 +30,19 @@ class ElasticsearchSearcher(Searcher):
"filter": list(self._make_filter_queries(tags, ids)),
}
},
+ "rescore": {
+ "window_size": 1000,
+ "query": {
+ "rescore_query": {
+ "sltr": {
+ "params": {
+ "query": query
+ },
+ "model": self.ranking_manager.get_current_model_name()
+ }
+ }
+ }
+ },
"aggregations": {
self.TAGS_AGGREGATION_NAME: {
"terms": {"field": "tags"}
Sekarang, setelah Elasticsearch melakukan pencarian yang kami butuhkan dan memberi peringkat hasil dengan algoritme (cukup cepat), kami akan mengambil 1000 hasil teratas dan memberi peringkat ulang menggunakan rumus pembelajaran mesin (relatif lambat) kami. Keberhasilan!
Kesimpulan
Kami mengambil aplikasi web minimalis kami dan beralih dari tanpa fitur pencarian menjadi solusi yang dapat diskalakan dengan banyak fitur lanjutan. Ini tidak mudah dilakukan. Tapi itu juga tidak sulit! Aplikasi terakhir terletak pada repositori di Github di cabang dengan nama sederhana
feature/searchdan membutuhkan Docker dan Python 3 dengan pustaka pembelajaran mesin untuk dijalankan.
Saya menggunakan Elasticsearch untuk menunjukkan cara kerjanya secara umum, masalah apa yang dihadapi dan bagaimana mengatasinya, tetapi ini jelas bukan satu-satunya alat yang dapat dipilih. Solr , indeks teks lengkap PostgreSQL, dan mesin lainnya juga pantas mendapatkan perhatian Anda saat memilih untuk membangun perusahaan
Dan, tentu saja, solusi ini mengaku tidak lengkap dan siap produksi, tetapi murni ilustrasi bagaimana segala sesuatu bisa dilakukan. Anda dapat meningkatkannya hampir tanpa akhir!
- Pengindeksan tambahan. Saat memodifikasi kartu kita melaluinya
CardManager, akan lebih baik untuk segera memperbaruinya di indeks. AgarCardManagertidak mengetahui bahwa kita juga memiliki pencarian dalam layanan, dan untuk melakukannya tanpa dependensi siklik, kita harus mengencangkan inversi dependensi dalam satu bentuk atau lainnya. - Untuk pengindeksan dalam kasus khusus kami, paket MongoDB dengan Elasticsearch, Anda dapat menggunakan solusi siap pakai seperti konektor mongo .
- , — Elasticsearch .
- , , .
- , , . -, -, - … !
- ( , ), ( ). , .
- , , .
- Mengatur sekumpulan node dengan sharding dan replikasi adalah kesenangan yang terpisah.
Tetapi untuk menjaga ukuran artikel agar dapat dibaca, saya akan berhenti di situ dan meninggalkan Anda sendirian dengan tantangan ini. Terima kasih atas perhatiannya!