
Saya tahu dari pengalaman pribadi apa yang berguna di mana dan kapan. Survei dan tesis, sehingga jelas apa dan di mana untuk menggali selanjutnya - tetapi di sini saya memiliki pengalaman pribadi yang sangat subjektif, mungkin semuanya sama sekali berbeda dengan Anda.
Mengapa penting untuk mengetahui dan dapat menangani bahasa kueri? Pada intinya, dalam Ilmu Data ada beberapa tahapan pekerjaan yang paling penting dan yang pertama dan terpenting (tanpanya, tidak ada yang akan berhasil, tentu saja!) Adalah akuisisi atau pengambilan data. Paling sering, data dalam beberapa bentuk tersimpan di suatu tempat dan Anda perlu "mendapatkannya" dari sana.
Bahasa kueri memungkinkan Anda mengekstrak data ini! Dan hari ini saya akan memberi tahu Anda tentang bahasa kueri yang berguna bagi saya dan saya akan memberi tahu-menunjukkan di mana dan bagaimana tepatnya - mengapa itu diperlukan untuk belajar.
Secara total, akan ada tiga blok utama jenis kueri ke data, yang akan kami analisis di artikel ini:
- Bahasa kueri "standar" adalah bahasa yang biasanya mereka pahami saat berbicara tentang bahasa kueri seperti aljabar relasional atau SQL.
- Bahasa kueri skrip seperti trik python pandas, skrip numpy atau shell.
- Bahasa kueri untuk grafik pengetahuan dan database grafik.
Semua yang ditulis di sini hanyalah pengalaman pribadi, yang berguna, dengan deskripsi situasi dan "mengapa hal itu diperlukan" - setiap orang dapat mencoba bagaimana situasi serupa dapat menemui Anda dan mencoba mempersiapkannya sebelumnya, setelah berurusan dengan bahasa-bahasa ini sebelum Anda harus melakukannya untuk (segera) melamar proyek atau bahkan mendapatkan proyek di mana mereka dibutuhkan.
Bahasa kueri "Standar"
Bahasa kueri standar persis seperti yang biasanya kita pikirkan saat berbicara tentang kueri.
Aljabar relasional
Mengapa aljabar relasional dibutuhkan saat ini? Untuk mengetahui dengan baik mengapa bahasa kueri disusun dengan cara tertentu dan menggunakannya secara sadar, Anda perlu memahami inti yang mendasarinya.
Apa itu Aljabar Relasional?
Definisi formal adalah sebagai berikut: aljabar relasional adalah sistem operasi tertutup pada relasi dalam model data relasional. Lebih manusiawi, ini adalah sistem operasi di atas tabel, sehingga hasilnya selalu berupa tabel.
Lihat semua operasi relasional dalam artikel ini dari Habr - di sini kami menjelaskan mengapa Anda perlu tahu dan di mana hal itu berguna.
Untuk apa?
Anda mulai memahami bahasa kueri apa yang umumnya digunakan dan operasi apa yang ada di balik ekspresi bahasa kueri tertentu - sering kali memberikan pemahaman yang lebih dalam tentang apa dan bagaimana bekerja dalam bahasa kueri.
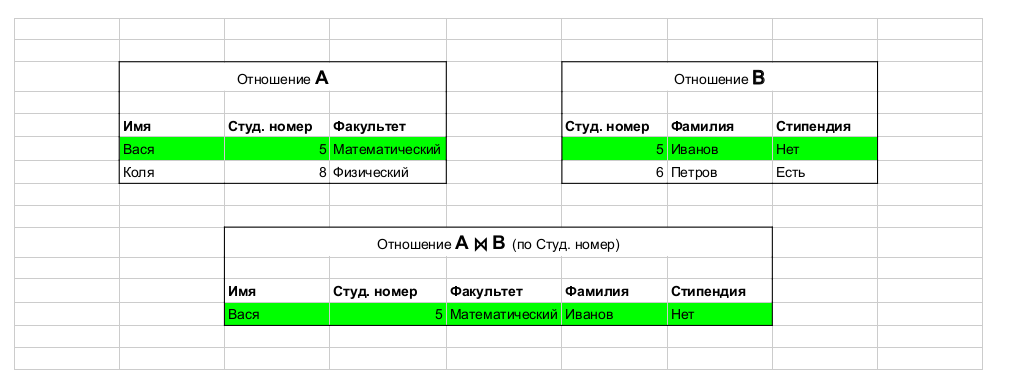
Diambil dari artikel ini . Contoh operasi: join, yang menggabungkan tabel.
Materi Studi:
Kursus pengantar yang bagus dari Stanford . Secara umum, ada banyak materi tentang aljabar dan teori relasional - Coursera, Udacity. Ada juga sejumlah besar materi online, termasuk kursus akademis yang bagus . Saran pribadi saya adalah memahami aljabar relasional dengan sangat baik - ini adalah fondasinya.
SQL

Diambil dari artikel ini .
Sebenarnya SQL adalah implementasi dari aljabar relasional - dengan peringatan penting, SQL bersifat deklaratif! Yaitu, menulis kueri dalam bahasa aljabar relasional, Anda sebenarnya mengatakan cara menghitung - tetapi dengan SQL Anda menentukan apa yang ingin Anda ekstrak, dan kemudian DBMS sudah menghasilkan ekspresi (efektif) dalam bahasa aljabar relasional (kesetaraannya diketahui kami di bawah teorema Codd ) ...
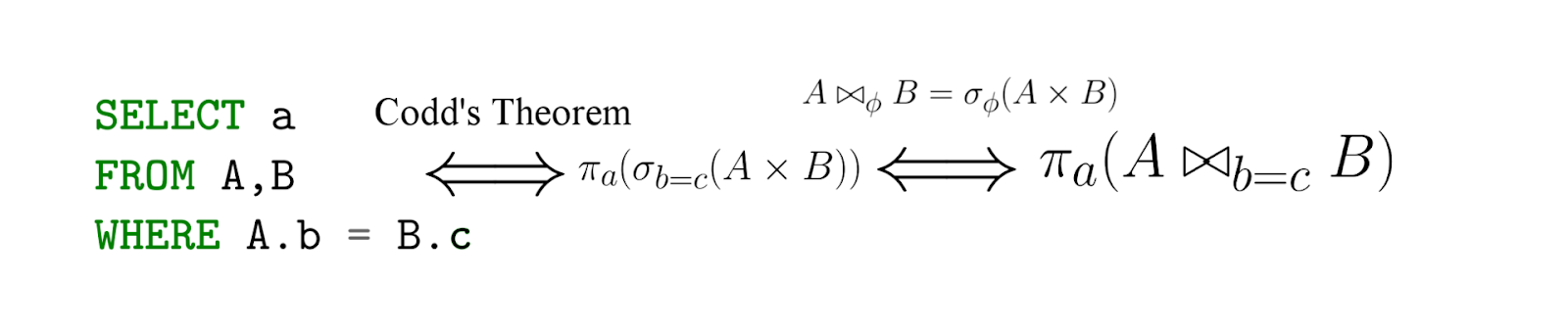
Diambil dari artikel ini .
Untuk apa?
Relasional DBMS: Oracle, Postgres, SQL Server, dll. Secara virtual masih ada di mana-mana dan ada kemungkinan yang sangat tinggi bahwa Anda harus berinteraksi dengannya, yang berarti Anda harus membaca SQL (yang sangat mungkin) atau menulis di dalamnya ( juga tidak mungkin).
Apa yang harus dibaca dan dipelajari
Dari tautan yang sama di atas (tentang aljabar relasional), ada banyak sekali materi, seperti yang satu ini .
Ngomong-ngomong, apa itu NoSQL?
"Perlu ditekankan sekali lagi bahwa istilah" NoSQL "memiliki asal yang sepenuhnya spontan dan tidak memiliki definisi yang diterima secara umum atau lembaga ilmiah di belakangnya." Artikel terkait di Habré.
Faktanya, orang-orang menyadari bahwa model relasional lengkap tidak diperlukan untuk menyelesaikan banyak masalah, terutama bagi mereka yang, misalnya, kinerja adalah fundamental dan kueri sederhana tertentu dengan agregasi mendominasi - sangat penting untuk membaca metrik dengan cepat dan menuliskannya ke dalam database, dan sebagian besar fiturnya bersifat relasional. ternyata tidak hanya tidak perlu, tetapi juga berbahaya - mengapa menormalkan sesuatu jika itu akan merusak hal yang paling penting bagi kita (untuk beberapa tugas tertentu) - kinerja?
Selain itu, sering kali diperlukan skema yang fleksibel daripada skema matematika tetap dari model relasional klasik - dan ini sangat menyederhanakan pengembangan aplikasi, ketika sangat penting untuk menerapkan sistem dan mulai bekerja dengan cepat, memproses hasilnya - atau skema dan jenis data yang disimpan tidak begitu penting.
Misalnya, kami membuat sistem pakar dan kami ingin menyimpan informasi pada domain tertentu bersama dengan beberapa informasi meta - kami mungkin tidak mengetahui semua bidang dan klise menyimpan JSON untuk setiap rekaman - ini memberi kami lingkungan yang sangat fleksibel untuk memperluas model data dan iterasi cepat - oleh karena itu, dalam kasus NoSQL akan lebih disukai dan dapat dibaca. Contoh entri (dari salah satu proyek saya, di mana NoSQL tepat jika diperlukan)
{"en_wikipedia_url":"https://en.wikipedia.org/wiki/Johnny_Cash",
"ru_wikipedia_url":"https://ru.wikipedia.org/wiki/?curid=301643",
"ru_wiki_pagecount":149616,
"entity":[42775," ","ru"],
"en_wiki_pagecount":2338861}
Anda dapat membaca lebih lanjut tentang NoSQL di sini .
Apa yang Harus Dipelajari?
Sebaliknya, Anda hanya perlu pandai menganalisis tugas Anda, properti apa yang dimilikinya dan sistem NoSQL apa yang tersedia yang sesuai dengan deskripsi ini - dan sudah mempelajari sistem ini.
Bahasa kueri skrip
Pada awalnya, tampaknya, apa hubungannya Python dengan itu - ini adalah bahasa pemrograman, dan bukan tentang kueri sama sekali.

- Panda adalah pisau Swiss langsung untuk Ilmu Data, sejumlah besar transformasi data, agregasi, dll. Terjadi di dalamnya.
- Numpy adalah komputasi vektor, matriks, dan aljabar linier.
- Scipy banyak matematika dalam paket ini, terutama statistik.
- Lab Jupyter - banyak analisis data eksplorasi cocok dengan laptop - bagus untuk bisa.
- Permintaan - jaringan.
- Pyspark sangat populer di kalangan insinyur data, kemungkinan besar Anda perlu berinteraksi dengan ini atau dan spark, hanya karena popularitasnya.
- * Selenium sangat berguna untuk mengumpulkan data dari situs dan sumber daya, terkadang tidak ada cara lain untuk mendapatkan data.
Tip teratas saya: Pelajari Python!
Panda
Mari kita ambil kode berikut sebagai contoh:
import pandas as pd
df = pd.read_csv(“data/dataset.csv”)
# Calculate and rename aggregations
all_together = (df[df[‘trip_type’] == “return”]
.groupby(['start_station_name','end_station_name'])\
.agg({'trip_duration_seconds': [np.size, np.mean, np.min, np.max]})\
.rename(columns={'size': 'num_trips',
'mean': 'avg_duration_seconds',
'amin': min_duration_seconds',
‘amax': 'max_duration_seconds'}))Faktanya, kita dapat melihat bahwa kode tersebut cocok dengan pola SQL klasik.
SELECT start_station_name, end_station_name, count(trip_duration_seconds) as size, …..
FROM dataset
WHERE trip_type = ‘return’
GROUPBY start_station_name, end_station_nameTetapi bagian yang penting adalah bahwa kode ini adalah bagian dari skrip dan pipeline, sebenarnya, kami menyematkan permintaan ke pipeline Python. Dalam situasi ini, bahasa kueri datang dari perpustakaan seperti Pandas atau pySpark.
Secara umum, di pySpark kami melihat jenis transformasi data yang serupa melalui bahasa kueri dalam semangat:
df.filter(df.trip_type = “return”)\
.groupby(“day”)\
.agg({duration: 'mean'})\
.sort()Di mana dan apa yang harus dibaca
Tentang python itu sendiri, sama sekali tidak menjadi masalah untuk menemukan bahan untuk dipelajari. Ada banyak sekali tutorial tentang panda , pySpark , dan kursus tentang Spark (serta di DS itu sendiri ) di internet . Secara umum, materi di sini bagus untuk googling dan jika saya harus memilih satu paket untuk difokuskan, itu akan menjadi panda, tentu saja. Ada juga banyak materi di bundel DS + Python .
Shell sebagai bahasa kueri
Banyak proyek pemrosesan dan analisis data yang telah saya kerjakan, pada kenyataannya, skrip shell yang memanggil kode dengan Python, di java, dan perintah shell itu sendiri. Oleh karena itu, secara umum, Anda dapat mempertimbangkan pipeline di bash / zsh / etc, sebagai beberapa permintaan tingkat tinggi (Anda dapat, tentu saja, mendorong loop di sana, tetapi ini tidak umum untuk kode DS dalam bahasa shell), mari berikan contoh sederhana - Saya perlu memetakan QID dari wikidata dan tautan lengkap ke wiki Rusia dan Inggris, untuk ini saya menulis kueri sederhana dari perintah di bash dan untuk output saya menulis skrip sederhana dengan Python, yang saya kumpulkan seperti ini:
pv “data/latest-all.json.gz” |
unpigz -c |
jq --stream $JQ_QUERY |
python3 scripts/post_process.py "output.csv"
Dimana
JQ_QUERY = 'select((.[0][1] == "sitelinks" and (.[0][2]=="enwiki" or .[0][2] =="ruwiki") and .[0][3] =="title") or .[0][1] == "id")' Faktanya, ini adalah keseluruhan pipeline yang membuat pemetaan yang diperlukan, seperti yang kita lihat semuanya, ini bekerja dalam mode streaming:
- pv filepath - memberikan bilah kemajuan berdasarkan ukuran file dan meneruskan isinya
- unpigz -c membaca bagian dari arsip dan memberikan jq
- jq dengan key - stream segera menghasilkan hasilnya dan meneruskannya ke postprocessor (seperti pada contoh pertama) dengan Python
- internal prosesor pos adalah mesin keadaan sederhana yang memformat output
Secara total, pipeline kompleks yang bekerja dalam mode streaming pada big data (0,5TB), tanpa sumber daya yang signifikan dan terbuat dari pipeline sederhana dan beberapa alat.
Tip penting lainnya: jadilah baik dan efisien di terminal dan tulis di bash / zsh / dll.Dimana itu berguna? Ya, hampir di mana-mana - sekali lagi, ada BANYAK bahan untuk dipelajari di internet. Secara khusus, ini adalah artikel saya sebelumnya.
R scripting
Sekali lagi, pembaca mungkin berseru - yah, ini adalah bahasa pemrograman lengkap! Dan tentu saja dia benar. Namun, saya biasanya harus selalu berurusan dengan R dalam konteks yang, pada kenyataannya, sangat mirip dengan bahasa kueri.
R adalah kerangka kerja komputasi statistik dan komputasi statis dan bahasa visualisasi (menurut ini ).
Diambil dari sini . Ngomong-ngomong, saya sarankan, material yang bagus.
Mengapa berkencan dengan seorang Ilmuwan untuk mengetahui R? Setidaknya, karena ada lapisan besar orang non-IT yang terlibat dalam analisis data di R. Saya telah bertemu di tempat-tempat berikut:
- Sektor farmasi.
- Ahli biologi.
- Sektor keuangan.
- Orang dengan pendidikan matematika murni, berurusan dengan statistik.
- Model statistik dan pembelajaran mesin khusus (yang seringkali hanya dapat ditemukan di versi upstream sebagai paket R).
Mengapa sebenarnya ini adalah bahasa kueri? Dalam bentuk yang sering dijumpai, sebenarnya adalah permintaan untuk membuat model, termasuk membaca data dan memperbaiki parameter kueri (model), serta memvisualisasikan data dalam paket seperti ggplot2 - ini juga merupakan bentuk penulisan kueri.
Contoh kueri untuk rendering
ggplot(data = beav,
aes(x = id, y = temp,
group = activ, color = activ)) +
geom_line() +
geom_point() +
scale_color_manual(values = c("red", "blue"))Secara umum, banyak ide dari R telah bermigrasi ke paket python seperti pandas, numpy atau scipy, seperti dataframes dan vektorisasi data - oleh karena itu, secara umum, banyak hal di R akan tampak akrab dan nyaman bagi Anda.
Ada banyak sumber untuk dipelajari, misalnya yang ini .
Grafik pengetahuan
Di sini saya memiliki pengalaman yang sedikit tidak biasa, karena saya masih cukup sering bekerja dengan grafik pengetahuan dan bahasa kueri untuk grafik. Jadi mari kita membahas dasar-dasarnya secara singkat, karena bagian ini sedikit lebih eksotis.
Dalam database relasional klasik kami memiliki skema tetap - di sini skema fleksibel, setiap predikat sebenarnya adalah "kolom" dan bahkan lebih.
Bayangkan Anda akan mencontoh seseorang dan ingin menjelaskan hal-hal penting, misalnya, mari kita ambil orang tertentu oleh Douglas Adams, kami akan mengambil deskripsi ini sebagai dasar.
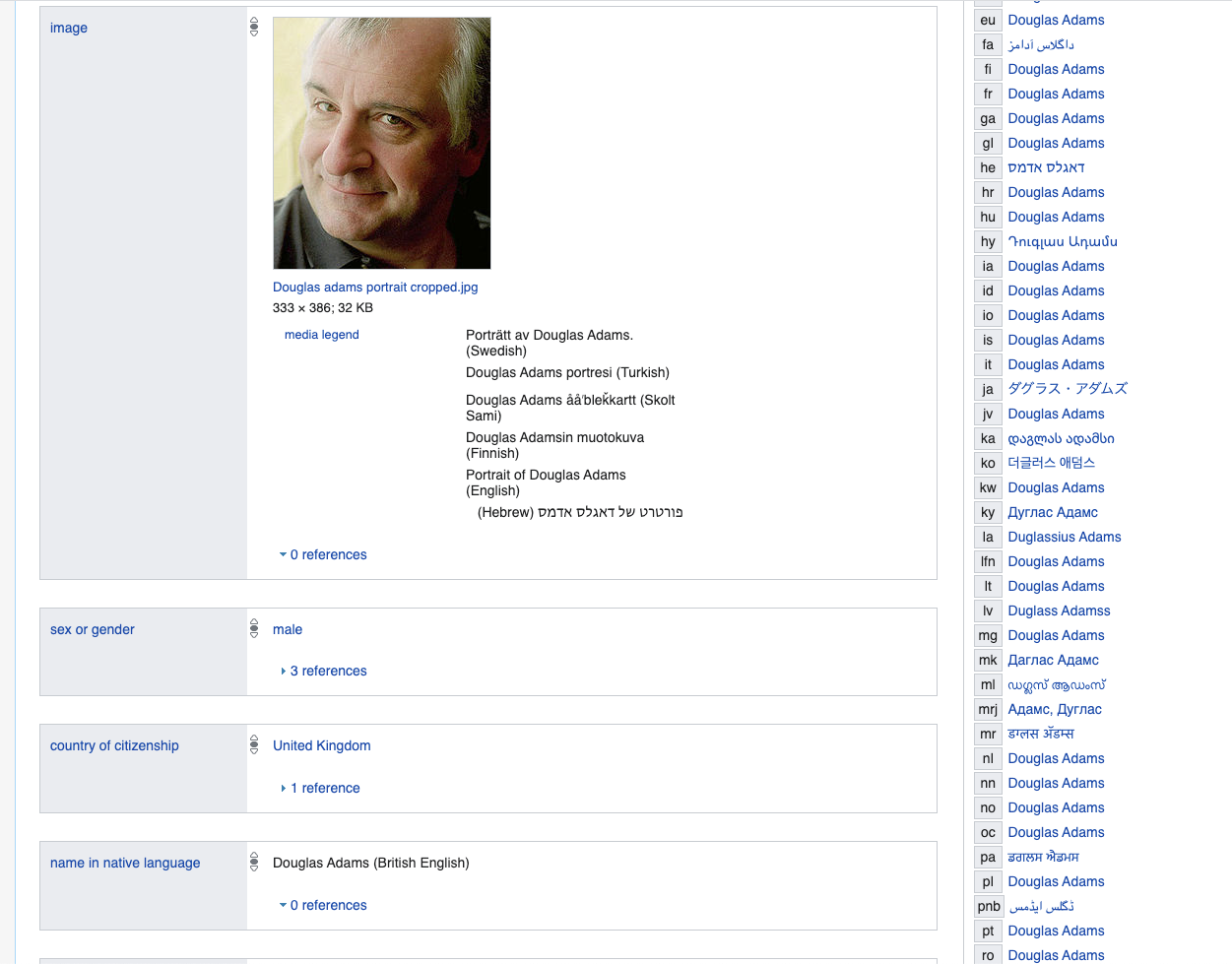
www.wikidata.org/wiki/Q42
Jika kita menggunakan database relasional, kita harus membuat tabel atau tabel yang sangat besar dengan sejumlah besar kolom, sebagian besar akan menjadi NULL atau diisi dengan beberapa nilai False default, misalnya, tidak mungkin banyak dari kita memiliki entri di perpustakaan nasional Korea - tentu saja, kita dapat meletakkannya di tabel terpisah, tetapi itu pada akhirnya akan menjadi upaya untuk membuat model logika fleksibel dengan predikat menggunakan predikat relasional tetap.
Oleh karena itu, bayangkan semua data disimpan sebagai grafik atau sebagai ekspresi logika biner dan uner.
Di mana Anda bisa mengalami ini? Pertama, bekerja dengan data wiki , dan dengan database grafik atau data yang terhubung.
Berikut ini adalah bahasa kueri utama yang telah saya gunakan dan kerjakan.
SPARQL
Wiki:
SPARQL ( . SPARQL Protocol and RDF Query Language) — , RDF, . SPARQL W3C .
Tetapi pada kenyataannya ini adalah bahasa kueri untuk predikat unary dan biner yang logis. Anda hanya menyatakan secara kondisional apa yang ditetapkan dalam ekspresi boolean dan apa yang tidak (sangat sederhana).
Dasar RDF (Resource Description Framework) itu sendiri, di mana kueri SPARQL dijalankan, adalah triplet
object, predicate, subject- dan kueri memilih triplet yang diperlukan sesuai dengan batasan yang ditentukan dalam semangat: temukan X sehingga p_55 (X, q_33) benar - di mana, tentu saja, p_55 adalah apa -hubungan itu dengan ID 55, dan q_33 adalah objek dengan ID 33 (itulah keseluruhan cerita, sekali lagi mengabaikan segala macam detail).
Contoh penyajian data:
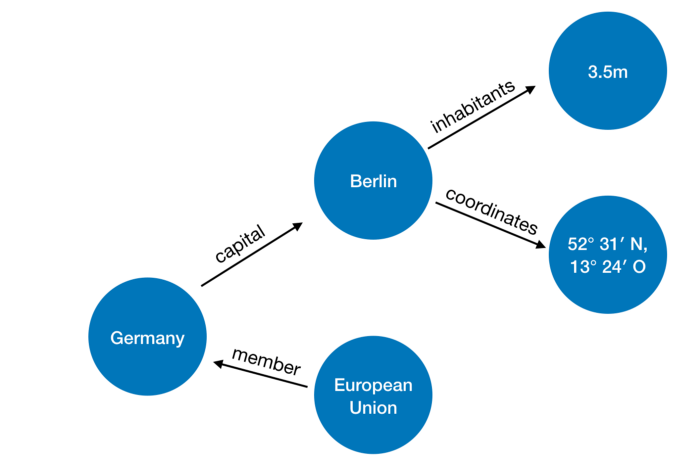
Gambar dan contoh dengan negara berasal dari sini .
Contoh kueri dasar

Sebenarnya kita ingin mencari nilai variabel? Country, sehingga untuk predikat
member_of, benar bahwa member_of (? Country, q458) dan q458 adalah ID Uni Eropa.
Contoh kueri SPARQL nyata di dalam mesin python:
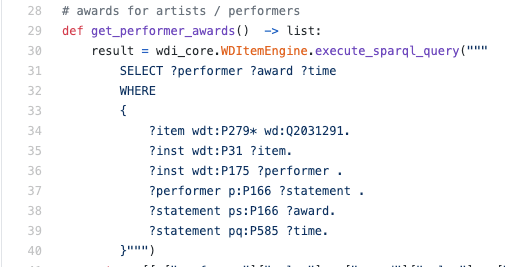
Sebagai aturan, saya harus membaca SPARQL, bukan menulis - dalam situasi seperti itu, kemungkinan besar, ini akan menjadi keterampilan yang berguna untuk memahami bahasa setidaknya pada tingkat dasar, untuk memahami dengan tepat bagaimana data diambil.
Ada banyak bahan pelajaran online, seperti ini dan yang ini . Saya sendiri biasanya google konstruksi dan contoh khusus, dan sejauh ini saya sudah cukup.
Bahasa kueri logis
Anda dapat membaca lebih lanjut tentang topik di artikel saya di sini . Di sini, kami hanya akan membahas secara singkat mengapa bahasa logis cocok untuk menulis kueri. Faktanya, RDF hanyalah kumpulan pernyataan logis dari bentuk p (X) dan h (X, Y), dan kueri logis terlihat seperti ini:
output(X) :- country(X), member_of(X,“EU”).
Di sini kita berbicara tentang membuat keluaran predikat baru / 1 (/ 1 berarti unary), ketika asalkan benar untuk X negara itu (X) - yaitu, X adalah negara dan juga member_of (X, “EU”).
Artinya, kami memiliki data dan aturan dalam hal ini biasanya disajikan dengan cara yang sama, yang membuatnya sangat mudah dan bagus untuk memodelkan tugas.
Di mana Anda bertemu di industri: proyek besar secara keseluruhan dengan perusahaan yang menulis pertanyaan dalam bahasa seperti itu, serta pada proyek saat ini di inti sistem - tampaknya hal yang agak eksotis, tetapi kadang-kadang terjadi.
Contoh potongan kode dalam bahasa logika yang memproses wikidata:
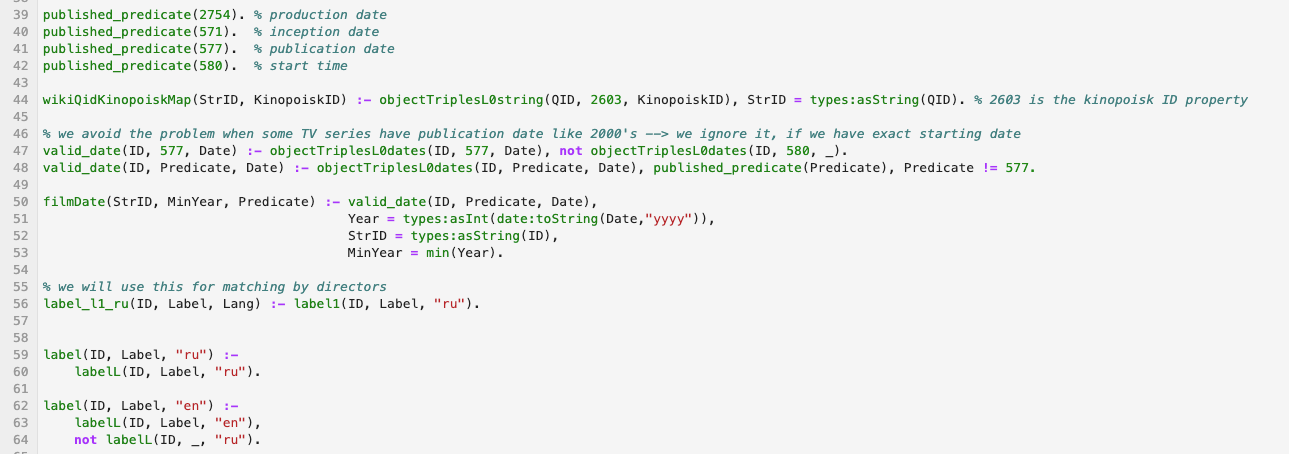
Bahan: Saya akan memberikan di sini beberapa tautan ke bahasa pemrograman logis modern. Pemrograman Set Jawaban - Saya sarankan untuk mempelajarinya:
- http://peace.eas.asu.edu/aaai12tutorial/asp-tutorial-aaai.pdf
- http://ceur-ws.org/Vol-1145/tutorial1.pdf
- https://www.youtube.com/watch?v=gVQ0bP8zyHw
- https://www.youtube.com/watch?v=kdcd7Je2glc
- https://potassco.org/book/
- http://potassco.sourceforge.net/teaching.html
- https://www.cs.uni-potsdam.de/~torsten/Potassco/Tutorials/fmcad12.pdf
