Ini bukan analisis sistematis dan bukan tabel. Pandangan individu, juga dari sudut pandang ahli geofisika. Tapi saya selalu penasaran membaca Gartner MQ, mereka merumuskan beberapa poin dengan sempurna. Jadi inilah hal-hal yang saya perhatikan dalam istilah teknis, pasar, dan filosofis.
Ini bukan untuk orang yang sangat menyukai ML, tetapi untuk orang yang tertarik dengan apa yang umumnya terjadi di pasar.
Pasar DSML sendiri secara logis berada di antara BI dan layanan pengembang Cloud AI.
Menyukai kutipan dan istilah pertama:
- "Seorang Leader mungkin bukan pilihan terbaik" - Pemimpin pasar belum tentu apa yang Anda butuhkan. Sangat mendesak! Sebagai konsekuensi dari kurangnya pelanggan yang fungsional, mereka selalu mencari solusi yang "terbaik", bukan yang "cocok".
- Operasionalisasi model disingkat MOP. Dan pesek sulit untuk semua orang! - (Tema pug keren membuat modelnya berfungsi).
- Lingkungan notebook adalah konsep penting tempat kode, komentar, data, dan hasil digabungkan. Ini sangat jelas, menjanjikan dan dapat secara signifikan mengurangi jumlah kode UI.
- «Rooted in OpenSource» — – .
- «Citizen Data Scientists» — , , , . .
- «Democratise» — “ ”. «democratise the data» «free the data», . «Democratise» — long tail . — !
- «Exploratory Data Analysis – EDA» — . . . , . ,
- "Reproduksi" - pengawetan maksimum semua parameter lingkungan, masukan dan keluaran, sehingga Anda dapat mengulangi percobaan setelah dilakukan. Istilah paling penting untuk lingkungan pengujian eksperimental!
Begitu:
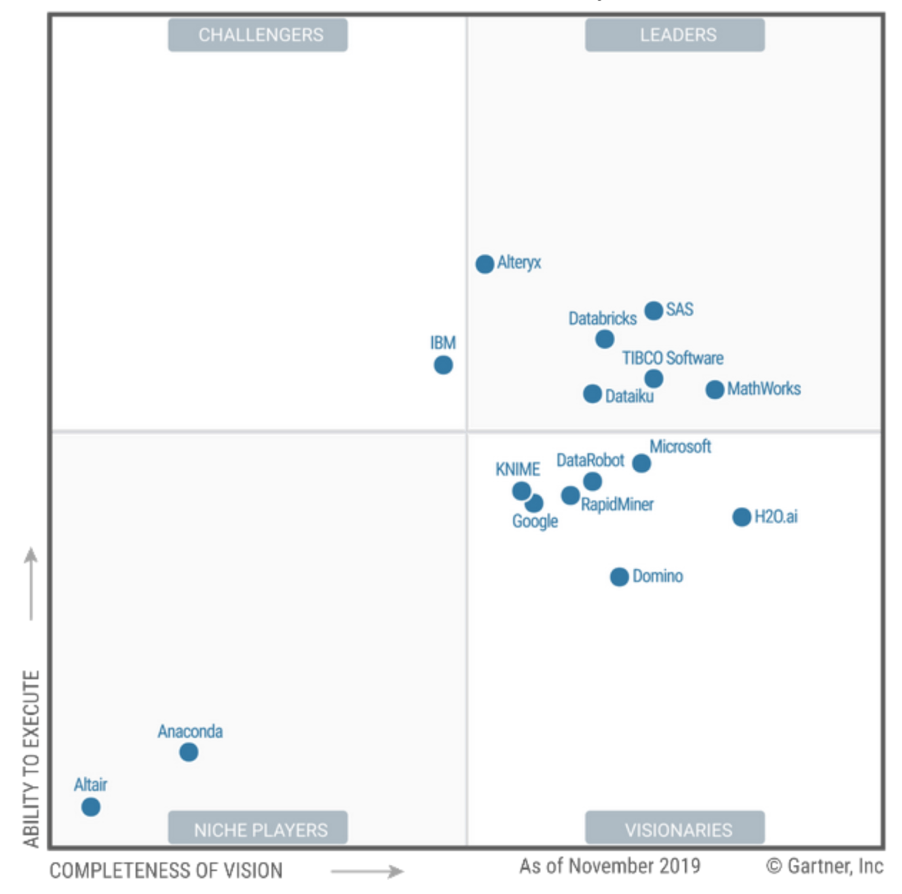
Alteryx
Antarmuka yang keren hanyalah mainan. Skalabilitas, tentu saja, agak ketat. Karenanya, komunitas insinyur warga sekitar sama dengan tsatski untuk bermain. Analytics memiliki semua dalam satu botol sendiri. Ini mengingatkan saya pada Coscad Spectral Korelasi Analisis Data Suite yang diprogram di tahun 90an.
Anaconda
Komunitas di sekitar pakar Python dan R. Open source masing-masing berukuran besar. Ternyata kolega saya terus menggunakan. Saya tidak tahu.
DataBricks
Terdiri dari tiga proyek sumber terbuka - Pengembang Spark telah mengumpulkan banyak uang sejak 2013. Saya harus membaca wiki secara langsung:
“Pada September 2013, Databricks mengumumkan bahwa mereka telah mengumpulkan $ 13,9 juta dari Andreessen Horowitz. Perusahaan mengumpulkan tambahan $ 33 juta pada tahun 2014, $ 60 juta pada tahun 2016, $ 140 juta pada tahun 2017, $ 250 juta pada tahun 2019 (Feb) dan $ 400 juta pada tahun 2019 (Okt) ”!!!Beberapa orang hebat yang digergaji oleh Spark. Tidak familiar, maaf!
Dan proyeknya adalah:
- Delta Lake - ACID on Spark baru-baru ini dirilis (apa yang kami impikan dengan Elasticsearch) - mengubahnya menjadi database: skema kaku, ACID, audit, versi ...
- ML Flow - melacak, mengemas, mengelola dan menyimpan model.
- Koala - Pandas DataFrame API di Spark - Pandas - Python API untuk bekerja dengan tabel dan data secara umum.
Anda bisa melihat Spark, yang tiba-tiba tidak tahu atau lupa: tautan . Vidosiki melihat dengan contoh-contoh dari pelatuk konsultasi yang sedikit membosankan tetapi terperinci: DataBricks untuk Ilmu Data ( tautan ) dan untuk Teknik Data ( tautan ).
Singkatnya, Databricks mengeluarkan Spark. Siapa yang ingin menggunakan Spark secara normal di cloud mengambil DataBricks tanpa ragu-ragu, sebagaimana mestinya :) Spark adalah pembeda utama di sini.
Saya menemukan bahwa Spark Streaming bukanlah realtime atau microbatching palsu yang sebenarnya. Dan jika Anda membutuhkan Real Time yang nyata, ada di Apache STORM. Masih semua orang mengatakan dan menulis bahwa Spark lebih keren daripada MapReduce. Slogannya begini.
DATAIKU
Hal end-to-end yang keren. Ada banyak iklan. Tidak mengerti apa bedanya dengan Alteryx?
DataRobot
Paxata untuk menyiapkan data keren adalah perusahaan terpisah yang dibeli oleh Date Robots pada Desember 2019. Mengumpulkan 20 MUSD dan terjual. Semuanya dalam 7 tahun.
Mempersiapkan data dalam Paxata, bukan Excel - lihat di sini: tautan .
Ada spoof otomatis dan menggabungkan proposal antara dua kumpulan data. Suatu hal yang hebat - untuk memilah data, bahkan lebih menekankan pada informasi teks ( link ).
Katalog Data adalah katalog hebat dari kumpulan data "langsung" yang tidak dibutuhkan siapa pun.
Menarik juga bagaimana katalog dibentuk di Paxata ( tautan ).
«According to analyst firm Ovum, the software is made possible through advances in predictive analytics, machine learning and the NoSQL data caching methodology.[15] The software uses semantic algorithms to understand the meaning of a data table's columns and pattern recognition algorithms to find potential duplicates in a data-set.[15][7] It also uses indexing, text pattern recognition and other technologies traditionally found in social media and search software.»
Produk Robot Data utama ada di sini . Slogan mereka adalah dari Model hingga aplikasi perusahaan! Menemukan konsultasi untuk industri minyak sehubungan dengan krisis, tetapi sangat dangkal dan tidak menarik: tautan . Menonton video mereka di Mops atau MLops ( tautan ). Ini adalah Frankenstein yang terdiri dari 6-7 akuisisi berbagai produk.
Tentu saja, menjadi jelas bahwa tim Ilmuwan Data yang besar harus memiliki lingkungan seperti itu untuk bekerja dengan model, jika tidak, mereka akan menghasilkan banyak model dan tidak pernah menyebarkan apa pun. Dan dalam realitas hulu minyak dan gas kita - satu model akan berhasil dibuat dan ini sudah merupakan kemajuan besar!
Prosesnya sendiri pun sangat mengingatkan pada kerja desain sistem di bidang geologi-geofisika, contohnya Petrel.... Semua dan berbagai macam membuat dan memodifikasi model. Kumpulkan data dalam model. Kemudian kami membuat model referensi dan memasukkannya ke dalam produksi! Ada banyak kesamaan antara, katakanlah, model geologi dan model ML.
Kartu domino
Penekanan pada platform terbuka dan kolaborasi. Pengguna bisnis diizinkan masuk secara gratis. Lab Data mereka sangat mirip dengan titik berbagi. (Dan dari namanya sangat memberikan IBM). Semua eksperimen ditautkan ke set data asli. Seberapa familier :) Seperti dalam praktik kita - beberapa data diseret ke dalam model, kemudian dibersihkan dan diatur dalam model, dan semua ini sudah ada di model dan Anda tidak dapat menemukan ujungnya di data awal.
Domino memiliki virtualisasi infrastruktur yang keren. Saya merakit mesin sebanyak inti per detik dan mulai menghitung. Bagaimana itu dilakukan tidak sepenuhnya jelas. Docker dimana-mana. Banyak kebebasan! Ruang kerja apa pun dari versi terbaru dapat dihubungkan. Jalankan eksperimen secara paralel. Pelacakan dan pemilihan yang berhasil.
Sama seperti DataRobot - hasilnya dipublikasikan untuk pengguna bisnis dalam bentuk aplikasi. Untuk “pemangku kepentingan” yang sangat berbakat. Dan penggunaan sebenarnya dari model juga dipantau. Semuanya untuk Pugs!
Saya tidak sepenuhnya memahami bagaimana model rumit masuk ke produksi. Beberapa API disediakan untuk memberi mereka data dan mendapatkan hasil.
H2O
Driveless AI adalah sistem yang sangat ringkas dan mudah untuk Supervised ML. Semuanya dalam satu kotak. Tidak jelas tentang backend saat ini.
Model secara otomatis dikemas ke dalam server REST atau Aplikasi Java. Ini ide yang bagus. Banyak yang telah dilakukan untuk Interpretability dan Explainability. Interpretasi dan penjelasan hasil operasi model (Apa intinya tidak boleh dijelaskan, jika tidak seseorang dapat menghitung sama?).
Untuk pertama kalinya, studi kasus tentang data tidak terstruktur dan NLP dipertimbangkan secara detail . Gambar arsitektur berkualitas tinggi. Secara umum, saya menyukai gambarnya.
Ada kerangka kerja H2O sumber terbuka besar yang tidak sepenuhnya jelas (sekumpulan algoritme / pustaka?). Laptop visual sendiri tanpa pemrograman seperti Jupiter ( tautan). Saya juga membaca tentang model Pojo dan Mojo - H2O yang dibungkus dalam kenyataan. Yang pertama ada di dahi, yang kedua dengan optimasi. H20 adalah satu-satunya (!) Kepada siapa Gartner telah menulis analitik teks dan NLP dalam kekuatan mereka, serta upaya Explanability mereka. Ini sangat penting!
Ibid: Kinerja Tinggi, Pengoptimalan, dan Standar Industri untuk Integrasi Besi dan Awan.
Dan itu logis dalam kelemahan - Driverles AI lemah dan sempit dibandingkan dengan open source mereka sendiri. Persiapan data timpang dibandingkan dengan Paxata yang sama! Dan abaikan data industri - aliran, grafik, geo. Nah, semuanya tidak mungkin benar.
KNIME
Saya menyukai 6 kasus bisnis yang sangat menarik dan sangat spesifik di beranda. OpenSource yang kuat.
Gartner telah turun dari pemimpin menjadi visioner. Menghasilkan uang yang buruk adalah pertanda baik bagi pengguna, mengingat Leader tidak selalu merupakan pilihan terbaik.
Kata kuncinya sama seperti di H2O - ditambah, artinya membantu ilmuwan data warga miskin. Ini adalah pertama kalinya seseorang dimarahi karena kinerja dalam ulasan! Menarik? Artinya, ada begitu banyak daya komputasi sehingga kinerja tidak bisa menjadi masalah sistemik sama sekali? Gartner memiliki artikel terpisah tentang kata "Augmented" ini , yang tidak mungkin untuk dibaca.
Dan KNIME tampaknya menjadi orang non-Amerika pertama dalam ulasan! (Dan desainer kami sangat menyukai halaman arahan mereka. Orang-orang aneh.
MathWorks
MatLab adalah teman kehormatan lama yang dikenal semua orang! Kotak alat untuk semua bidang kehidupan dan situasi. Sesuatu yang sangat berbeda. Faktanya, banyak, banyak, banyak matematika untuk semua kesempatan secara umum!
Produk tambahan Simulink untuk desain sistem. Saya menggali ke dalam kotak peralatan untuk Digital Twins - Saya tidak mengerti apa-apa tentang hal itu, tapi sebuah banyak yang telah ditulis di sini. Untuk industri perminyakan . Secara umum, ini adalah produk yang secara fundamental berbeda dari kedalaman matematika dan teknik. Untuk memilih toolkit matematika tertentu. Menurut Gartner, mereka semua memiliki masalah seperti insinyur yang cerdas - tidak ada kolaborasi - masing-masing mengobrak-abrik modelnya sendiri, tidak ada demokrasi, tidak ada eksploitasi.
RapidMiner
Saya telah bertemu dan mendengar banyak hal sebelumnya (bersama dengan Matlab) dalam konteks open source yang baik. Dikuburkan sedikit di TurboPrep seperti biasa. Saya tertarik dengan cara mendapatkan data bersih dari data kotor.
Sekali lagi, Anda dapat melihat bahwa orang-orang bagus dalam materi pemasaran 2018 dan penutur bahasa Inggris yang buruk dalam demo fitur.
Dan orang-orang dari Dortmund sejak 2001 dengan masa lalu Jerman yang kuat)

Saya tidak mengerti dari situs apa sebenarnya yang tersedia di open source - Anda perlu menggali lebih dalam. Video bagus tentang penerapan dan konsep AutoML.
Tidak ada yang istimewa tentang backend Server RapidMiner. Ini mungkin akan kompak dan bekerja dengan baik di lokasi di luar kotak. Dikemas dalam Docker. Lingkungan bersama hanya di server RapidMiner. Dan kemudian ada Radoop, data dari hadup, menghitung sajak dari alur kerja Spark di Studio.
Mendorong mereka ke bawah seperti yang diharapkan oleh vendor muda panas "penjual tongkat belang". Akan tetapi, Gartner memprediksi kesuksesan masa depan dalam ruang Perusahaan. Anda bisa mengumpulkan uang di sana. Orang Jerman tahu betapa suci dan sucinya :) Jangan menyebut SAP !!!
Mereka melakukan banyak hal untuk Warga! Namun di halaman tersebut Anda dapat melihat bagaimana Gartner mengatakan bahwa mereka mengalami kesulitan dalam menjual inovasi dan mereka tidak berjuang untuk mendapatkan liputan, tetapi untuk profitabilitas.
Meninggalkan vendor BI tipikal SAS dan Tibco untuk saya ... Dan keduanya berada di atas, yang menegaskan keyakinan saya bahwa DataScience normal secara logis tumbuh
dari BI, dan tidak keluar dari cloud dan infrastruktur Hadoop. Dari bisnis, yaitu bukan dari IT. Seperti di Gazpromneft misalnya: link , lingkungan DSML yang matang tumbuh dari praktik BI yang solid. Tapi mungkin dia memiliki noda dan bias pada MDM dan hal lainnya, siapa tahu.
SAS
Tidak banyak bicara. Hanya hal-hal yang sudah jelas.
TIBCO
Strateginya dibaca dalam daftar belanja di halaman Wiki sepanjang halaman. Ya, cerita panjang, tapi 28 !!! Charles. menyuap BI Spotfire (2007) di masa muda techno saya. Dan juga pelaporan oleh Jaspersoft (2014), kemudian sebanyak tiga vendor analitik prediktif Insightful (S-plus) (2008), Statistica (2017) dan Alpine Data (2017), event processing dan streaming Streambase System (2013), MDM Orchestra Networks (2018 ) dan platform dalam memori Snappy Data (2019).
Hai Frankie!
