
Masalah tekstur besar
Ide untuk membuat tekstur raksasa bukanlah hal baru. Tampaknya apa yang bisa lebih mudah - memuat tekstur besar sejuta megapiksel, dan menggambar objek dengannya. Tapi, seperti biasa, ada beberapa nuansa:
- API Grafik membatasi ukuran maksimum tekstur dalam lebar dan tinggi. Itu dapat bergantung pada perangkat keras dan driver. Ukuran maksimum untuk hari ini adalah 32768x32768 piksel.
- Bahkan jika kami naik ke batas ini, tekstur 32768x32768 RGBA akan membutuhkan memori video sebesar 4 gigabyte. Memori videonya cepat, terletak pada bus yang lebar, tetapi relatif mahal. Oleh karena itu, biasanya lebih kecil dari memori sistem dan jauh lebih sedikit dari memori disk.
1. Rendering modern dari tekstur besar
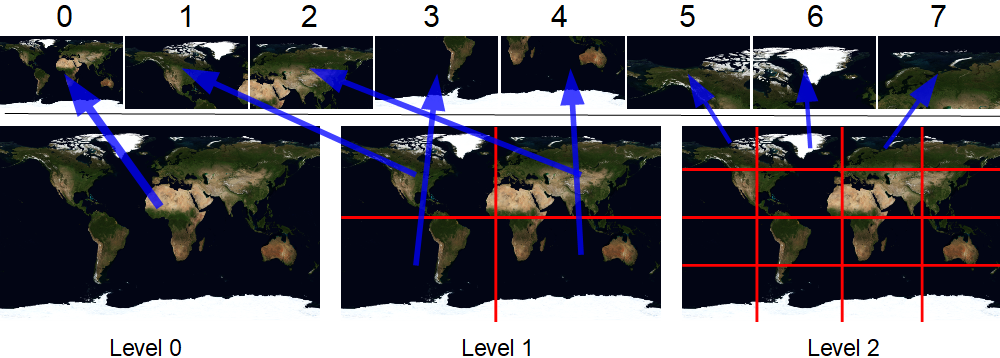
Karena gambar tidak sesuai dengan batasannya, maka solusi akan muncul dengan sendirinya - cukup pecah menjadi beberapa bagian (ubin):

Berbagai variasi pendekatan ini masih digunakan untuk geometri analitik. Ini bukan pendekatan universal; ini membutuhkan kalkulasi non-sepele pada CPU. Setiap ubin digambar sebagai objek terpisah, yang menambahkan overhead dan mengecualikan kemungkinan penerapan pemfilteran tekstur bilinear (akan ada garis yang terlihat di antara batas ubin). Namun, batasan ukuran tekstur dapat dielakkan oleh susunan tekstur! Ya, tekstur ini masih memiliki lebar dan tinggi yang terbatas, tetapi lapisan tambahan telah muncul. Jumlah lapisan juga terbatas, tetapi Anda dapat mengandalkan 2048Padahal spesifikasi gunung berapi hanya menjanjikan 256. Pada video card 1060 GTX, Anda bisa membuat tekstur yang mengandung 32768 * 32768 * 2048 piksel. Itu tidak mungkin untuk membuatnya, karena dibutuhkan 8 terabyte, dan tidak ada banyak memori video. Jika Anda menerapkannya pada blok kompresi perangkat keras BC1 , tekstur seperti itu akan menempati "hanya" 1 terabyte. Ini masih tidak muat ke dalam kartu video, tapi saya akan memberitahu Anda apa yang harus Anda lakukan dengan itu lebih lanjut.
Jadi, kami tetap memotong gambar asli menjadi beberapa bagian. Tapi sekarang ini bukan tekstur terpisah untuk setiap ubin, tetapi hanya sepotong di dalam susunan tekstur besar yang berisi semua ubin. Setiap bagian memiliki indeksnya sendiri, semua bagian diatur secara berurutan. Pertama dengan kolom, lalu dengan baris, lalu dengan lapisan:
Penyimpangan kecil tentang sumber tekstur tes
Misalnya - Saya mengambil gambar bumi dari sini . Saya meningkatkan ukuran aslinya 43200x2160 menjadi 65536x32768. Ini, tentu saja, tidak menambahkan detail, tetapi saya mendapatkan gambar yang saya butuhkan, yang tidak muat dalam satu lapisan tekstur. Kemudian saya secara rekursif menguranginya menjadi dua dengan filter bilinear, sampai saya mendapatkan ubin 512 x 256 piksel. Kemudian saya mengalahkan lapisan yang dihasilkan menjadi ubin 512x256. Kompres BC1 dan tuliskan secara berurutan ke file. Sesuatu seperti ini:
Hasilnya, kami mendapat file 1.431.633.920 byte, terdiri dari 21845 ubin. Ukuran 512 x 256 tidak acak. Gambar terkompresi 512 x 256 BC1 persis 65536 byte, yang merupakan ukuran blok dari gambar jarang - tokoh utama artikel ini. Ukuran ubin tidak penting untuk rendering.
Deskripsi teknik melukis tekstur besar
Jadi kami telah memuat array tekstur di mana ubin disusun secara berurutan dalam kolom / garis / lapisan.
Kemudian shader yang menggambar tekstur ini mungkin terlihat seperti ini:
layout(set=0, binding=0) uniform sampler2DArray u_Texture;
layout(location = 0) in vec2 v_uv;
layout(location = 0) out vec4 out_Color;
int lodBase[8] = { 0, 1, 5, 21, 85, 341, 1365, 5461};
int tilesInWidth = 32768 / 512;
int tilesInHeight = 32768 / 256;
int tilesInLayer = tilesInWidth * tilesInHeight;
void main() {
float lod = log2(1.0f / (512.0f * dFdx(v_uv.x)));
int iLod = int(clamp(floor(lod),0,7));
int cellsSize = int(pow(2,iLod));
int tX = int(v_uv.x * cellsSize); //column index in current level of detail
int tY = int(v_uv.y * cellsSize); //row index in current level of detail
int tileID = lodBase[iLod] + tX + tY * cellsSize; //global tile index
int layer = tileID / tilesInLayer;
int row = (tileID % tilesInLayer) / tilesInWidth;
int column = (tileID % tilesInWidth);
vec2 inTileUV = fract(v_uv * cellsSize);
vec2 duv = (inTileUV + vec2(column,row)) / vec2(tilesInWidth,tilesInHeight);
out_Color = texelFetch(u_Texture,ivec3(duv * textureSize(u_Texture,0).xy,layer),0);
}
Mari kita lihat shader ini. Pertama-tama, kita perlu menentukan tingkat detail apa yang harus dipilih. Fungsi luar biasa dFdx akan membantu kita dalam hal ini . Untuk menyederhanakannya, ini mengembalikan nilai yang lebih besar atribut yang diteruskan di piksel tetangga. Dalam demo saya menggambar persegi panjang datar dengan koordinat tekstur dalam kisaran 0..1. Ketika persegi panjang ini berukuran X piksel, dFdx (v_uv.x) akan mengembalikan 1 / X. Dengan demikian, petak tingkat pertama akan menurunkan piksel ke piksel dengan dFdx == 1/512. Yang kedua pada 1/1024, yang ketiga pada 1/2048, dll. Tingkat detailnya sendiri dapat dihitung sebagai berikut: log2 (1.0f / (512.0f * dFdx (v_uv.x))). Mari kita potong bagian pecahan darinya. Kemudian kami menghitung berapa banyak ubin dalam lebar / tinggi di level tersebut.
Mari pertimbangkan perhitungan sisanya menggunakan contoh:

di sini lod = 2, u = 0.65, v = 0.37
karena lod sama dengan dua, maka cellSize sama dengan empat. Gambar menunjukkan bahwa level ini terdiri dari 16 ubin (4 baris 4 kolom) - semuanya benar.
tX = int (0.65 * 4) = int (2.6) = 2
tY = int (0.37 * 4) = int (1.48) = 1
yaitu di dalam level, ubin ini berada di kolom ketiga dan baris kedua (mengindeks dari nol).
Kami juga membutuhkan koordinat lokal dari fragmen (panah kuning di gambar). Mereka dapat dengan mudah dihitung hanya dengan mengalikan koordinat tekstur asli dengan jumlah sel dalam satu baris / kolom dan mengambil bagian pecahannya. Dalam perhitungan di atas, mereka sudah ada - 0,6 dan 0,48.
Sekarang kita membutuhkan indeks global untuk ubin ini. Untuk ini saya menggunakan array yang dihitung sebelumnya lodBase. Di dalamnya, berdasarkan indeks, nilai dari berapa banyak ubin di semua tingkat sebelumnya (lebih kecil) disimpan. Tambahkan ke indeks lokal ubin di dalam level. Misalnya, ternyata lodBase [2] + 1 * 4 + 2 = 5 + 4 + 2 = 11. Yang juga benar.
Mengetahui indeks global, sekarang kita perlu menemukan koordinat petak dalam susunan tekstur kita. Untuk melakukan ini, kita perlu mengetahui berapa banyak ubin yang sesuai untuk lebar dan tinggi. Produk mereka adalah berapa banyak ubin yang masuk ke dalam lapisan. Dalam contoh ini, saya menjahit konstanta ini tepat di kode shader, untuk kesederhanaan. Selanjutnya, kita mendapatkan koordinat tekstur dan membaca texel darinya. Perhatikan bahwa sampler2DArray digunakan sebagai sampler . Oleh karena itu texelFetch kami melewati vektor tiga komponen, di koordinat ketiga - nomor lapisan.
Tekstur tidak dimuat sepenuhnya (gambar residensi sebagian)
Seperti yang saya tulis di atas, tekstur yang besar menghabiskan banyak memori video. Selain itu, sejumlah kecil piksel digunakan dari tekstur ini. Solusi untuk masalah ini - Partial Residency Textures muncul pada tahun 2011. Intinya singkat - ubin mungkin tidak secara fisik ada di memori! Pada saat yang sama, spesifikasi menjamin bahwa aplikasi tidak macet, dan semua implementasi yang diketahui menjamin bahwa angka nol dikembalikan. Selain itu, spesifikasi menjamin bahwa jika ekstensi didukung, maka ukuran blok yang dijamin dalam byte didukung - 64 kibyte. Resolusi blok penyusun dalam tekstur terikat pada ukuran ini:
| UKURAN TEXEL (bit) | Bentuk Blok (2D) | Bentuk Blok (3D) |
|---|---|---|
| ? 4-Bit? | ? 512 × 256 × 1 | tidak mendukung |
| 8-Bit | 256 × 256 × 1 | 64 × 32 × 32 |
| 16-Bit | 256 × 128 × 1 | 32 × 32 × 32 |
| 32-Bit | 128 × 128 × 1 | 32 × 32 × 16 |
| 64-Bit | 128 × 64 × 1 | 32 × 16 × 16 |
| 128-Bit | 64 × 64 × 1 | 16 × 16 × 16 |
Sebenarnya, tidak ada dalam spesifikasi tentang texel 4-bit, tetapi kami selalu dapat mengetahuinya menggunakan vkGetPhysicalDeviceSparseImageFormatProperties .
VkSparseImageFormatProperties sparseProps;
ermy::u32 propsNum = 1;
vkGetPhysicalDeviceSparseImageFormatProperties(hphysicalDevice, VK_FORMAT_BC1_RGB_SRGB_BLOCK, VkImageType::VK_IMAGE_TYPE_2D,
VkSampleCountFlagBits::VK_SAMPLE_COUNT_1_BIT, VkImageUsageFlagBits::VK_IMAGE_USAGE_SAMPLED_BIT | VkImageUsageFlagBits::VK_IMAGE_USAGE_TRANSFER_DST_BIT
, VkImageTiling::VK_IMAGE_TILING_OPTIMAL, &propsNum, &sparseProps);
int pageWidth = sparseProps.imageGranularity.width;
int pageHeight = sparseProps.imageGranularity.height;
Penciptaan tekstur yang jarang seperti itu berbeda dari yang biasanya.
Pertama di VkImageCreateInfo di flag harus ditentukan VK_IMAGE_CREATE_SPARSE_BINDING_BIT dan VK_IMAGE_CREATE_SPARSE_RESIDENCY_BIT
Kedua, mengikat melalui memori vkBindImageMemory tidak perlu.
Anda perlu mencari tahu jenis memori apa yang dapat digunakan melalui vkGetImageMemoryRequirements . Ini juga akan memberi tahu Anda berapa banyak memori yang diperlukan untuk memuat seluruh tekstur, tetapi kita tidak membutuhkan gambar ini.
Sebaliknya, kita perlu memutuskan di tingkat aplikasi berapa banyak ubin yang dapat terlihat secara bersamaan?
Setelah memuat beberapa ubin, ubin lainnya akan dibongkar, karena sudah tidak diperlukan lagi. Dalam demo, saya hanya mengarahkan jari saya ke langit dan mengalokasikan memori untuk seribu dua puluh empat ubin. Kedengarannya boros, tetapi hanya 50 megabyte versus 1.4GB dari tekstur yang terisi penuh. Anda juga perlu mengalokasikan memori pada host, untuk pementasan - buffer.
const int sparseBlockSize = 65536;
int numHotPages = 512; //
VkMemoryRequirements memReqsOpaque;
vkGetImageMemoryRequirements(device, mySparseImage, &memReqsOpaque); // memoryTypeBits. -
VkMemoryRequirements image_memory_requirements;
image_memory_requirements.alignment = sparseBlockSize ; //
image_memory_requirements.size = sparseBlockSize * numHotPages;
image_memory_requirements.memoryTypeBits = memReqsOpaque.memoryTypeBits;
Dengan cara ini kita akan memiliki tekstur besar di mana hanya beberapa bagian yang dimuat. Ini akan terlihat seperti ini:

Manajemen ubin
Berikut ini, saya akan menggunakan istilah ubin untuk menunjukkan sepotong tekstur (kotak hijau tua dan abu-abu pada gambar) dan istilah halaman untuk menunjukkan bagian dalam blok besar yang telah dialokasikan sebelumnya dalam memori video (persegi panjang hijau muda dan biru muda pada gambar).
Setelah membuat VkImage yang jarang , ini bisa digunakan melalui VkImageView di shader. Tentu saja, ini tidak akan berguna - pengambilan sampel akan mengembalikan nol, tidak ada data, tetapi tidak seperti VkImage biasa , tidak ada yang jatuh dan lapisan debug tidak akan bersumpah. Data dalam tekstur ini tidak hanya perlu dimuat, tetapi juga dibongkar, karena kami menghemat memori video.
Pendekatan OpenGL, yang menyediakan alokasi memori oleh driver untuk setiap blok, tampaknya tidak benar bagi saya. Ya, mungkin beberapa pengalokasi yang pintar dan cepat digunakan di sana, karena ukuran bloknya tetap. Ini juga diisyaratkan oleh fakta bahwa pendekatan serupa digunakan dalam contoh tekstur tempat tinggal yang jarang di gunung berapi. Tetapi bagaimanapun juga, pilih blok halaman linier besar dan, di sisi aplikasi, ikat halaman-halaman ini ke ubin tekstur tertentu dan mengisinya dengan data pasti tidak akan lebih lambat.
Dengan demikian, antarmuka tekstur renggang kami akan menyertakan metode seperti:
void CommitTile(int tileID, void* dataPtr); // 64
void FreeTile(int tileID);
void Flush();
Metode terakhir diperlukan untuk mengelompokkan pengisian / pelepasan ubin. Memperbarui ubin satu per satu cukup mahal, hanya sekali per bingkai. Mari kita lihat mereka secara berurutan.
//void CommitTile(int tileID, void* dataPtr)
int freePageID = _getFreePageID();
if (freePageID != -1)
{
tilesByPageIndex[freePageID] = tileID;
tilesByTileID[tileID] = freePageID;
memcpy(stagingPtr + freePageID * pageDataSize, tileData, pageDataSize);
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = optimalTilingMem;
mbind.memoryOffset = freePageID * pageDataSize;
mbind.flags = 0;
memoryBinds.push_back(mbind);
VkBufferImageCopy copyRegion;
copyRegion.bufferImageHeight = pageHeight;
copyRegion.bufferRowLength = pageWidth;
copyRegion.bufferOffset = mbind.memoryOffset;
copyRegion.imageExtent.depth = 1;
copyRegion.imageExtent.width = pageWidth;
copyRegion.imageExtent.height = pageHeight;
copyRegion.imageOffset.x = mbind.offset.x;
copyRegion.imageOffset.y = mbind.offset.y;
copyRegion.imageOffset.z = 0;
copyRegion.imageSubresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
copyRegion.imageSubresource.baseArrayLayer = layer;
copyRegion.imageSubresource.layerCount = 1;
copyRegion.imageSubresource.mipLevel = 0;
copyRegions.push_back(copyRegion);
return true;
}
return false;
Pertama, kita perlu mencari blok gratis. Saya hanya memeriksa array halaman-halaman ini dan mencari yang pertama, yang berisi nomor rintisan -1. Ini akan menjadi indeks halaman gratis. Saya menyalin data dari disk ke buffer pementasan menggunakan memcpy. Sumber adalah file yang dipetakan memori dengan offset untuk ubin tertentu. Selanjutnya, dengan ID ubin, saya mempertimbangkan posisinya (x, y, layer) dalam larik tekstur.
Selanjutnya, hal yang paling menarik dimulai - mengisi struktur VkSparseImageMemoryBind . Dialah yang mengikat memori video ke ubin. Bidang pentingnya adalah:
memori . Ini adalah objek VkDeviceMemory . Ini pra-alokasi memori untuk semua halaman.
memoryOffset . Ini adalah offset dalam byte ke halaman yang kita butuhkan.
Selanjutnya, kita perlu menyalin data dari staging buffer ke dalam memori yang baru saja diikat ini. Ini dilakukan dengan menggunakan vkCmdCopyBufferToImage .
Karena kami akan menyalin banyak bagian sekaligus, di tempat ini kami hanya mengisi struktur, dengan deskripsi di mana dan di mana kami akan menyalin. Yang penting di sini adalah bufferOffset yang menunjukkan offset sudah dalam staging buffer. Dalam hal ini, ini bertepatan dengan offset dalam memori video, tetapi strateginya bisa berbeda. Misalnya, bagi ubin menjadi panas, hangat, dan dingin. Yang panas ada di memori video, yang hangat ada di RAM, dan yang dingin ada di disk. Maka buffer pementasan bisa lebih besar dan offsetnya akan berbeda.
//void FreeTile(int tileID)
if (tilesByTileID.count(tileID) > 0)
{
i16 hotPageID = tilesByTileID[tileID];
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.memory = optimalTilingMem;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = VK_NULL_HANDLE;
mbind.memoryOffset = 0;
mbind.flags = 0;
memoryBinds.push_back(mbind);
tilesByPageIndex[hotPageID] = -1;
tilesByTileID.erase(tileID);
return true;
}
return false;
Di sinilah kami memisahkan memori dari ubin. Untuk melakukan ini, tetapkan memori VK_NULL_HANDLE .
//void Flush();
cbuff = hostDevice->CreateOneTimeSubmitCommandBuffer();
VkImageSubresourceRange imageSubresourceRange;
imageSubresourceRange.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
imageSubresourceRange.baseMipLevel = 0;
imageSubresourceRange.levelCount = 1;
imageSubresourceRange.baseArrayLayer = 0;
imageSubresourceRange.layerCount = numLayers;
VkImageMemoryBarrier bSamplerToTransfer;
bSamplerToTransfer.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bSamplerToTransfer.pNext = nullptr;
bSamplerToTransfer.srcAccessMask = 0;
bSamplerToTransfer.dstAccessMask = VK_ACCESS_TRANSFER_WRITE_BIT;
bSamplerToTransfer.oldLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bSamplerToTransfer.newLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bSamplerToTransfer.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.image = opaqueImage;
bSamplerToTransfer.subresourceRange = imageSubresourceRange;
VkSparseImageMemoryBindInfo imgBindInfo;
imgBindInfo.image = opaqueImage;
imgBindInfo.bindCount = memoryBinds.size();
imgBindInfo.pBinds = memoryBinds.data();
VkBindSparseInfo sparseInfo;
sparseInfo.sType = VK_STRUCTURE_TYPE_BIND_SPARSE_INFO;
sparseInfo.pNext = nullptr;
sparseInfo.waitSemaphoreCount = 0;
sparseInfo.pWaitSemaphores = nullptr;
sparseInfo.bufferBindCount = 0;
sparseInfo.pBufferBinds = nullptr;
sparseInfo.imageOpaqueBindCount = 0;
sparseInfo.pImageOpaqueBinds = nullptr;
sparseInfo.imageBindCount = 1;
sparseInfo.pImageBinds = &imgBindInfo;
sparseInfo.signalSemaphoreCount = 0;
sparseInfo.pSignalSemaphores = nullptr;
VkImageMemoryBarrier bTransferToSampler;
bTransferToSampler.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bTransferToSampler.pNext = nullptr;
bTransferToSampler.srcAccessMask = 0;
bTransferToSampler.dstAccessMask = VK_ACCESS_SHADER_READ_BIT;
bTransferToSampler.oldLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bTransferToSampler.newLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bTransferToSampler.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.image = opaqueImage;
bTransferToSampler.subresourceRange = imageSubresourceRange;
vkQueueBindSparse(graphicsQueue, 1, &sparseInfo, fence);
vkWaitForFences(device, 1, &fence, true, UINT64_MAX);
vkResetFences(device, 1, &fence);
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, VK_PIPELINE_STAGE_TRANSFER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bSamplerToTransfer);
if (copyRegions.size() > 0)
{
vkCmdCopyBufferToImage(cbuff, stagingBuffer, opaqueImage, VkImageLayout::VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL, copyRegions.size(), copyRegions.data());
}
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TRANSFER_BIT, VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bTransferToSampler);
hostDevice->ExecuteCommandBuffer(cbuff);
copyRegions.clear();
memoryBinds.clear();
Pekerjaan utama terjadi dalam metode ini. Pada saat panggilannya, kami sudah memiliki dua array dengan VkSparseImageMemoryBind dan VkBufferImageCopy. Kami mengisi struktur untuk memanggil vkQueueBindSparse dan memanggilnya. Ini bukan fungsi pemblokiran (seperti hampir semua fungsi di Vulkan), jadi kita harus menunggu secara eksplisit untuk menjalankannya. Untuk ini, parameter terakhir diteruskan ke VkFence , eksekusi yang akan kita tunggu. Nyatanya, dalam kasus saya, menunggu flu ini sama sekali tidak mempengaruhi kinerja program. Tapi, secara teori, itu dibutuhkan di sini.
Setelah kita memasang memori ke ubin, kita perlu mengisi gambar di dalamnya. Ini dilakukan dengan fungsi vkCmdCopyBufferToImage .
Anda bisa mengisi data ke dalam tekstur dengan layoutVK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL , dan dapatkan di shader dengan tata letak VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL . Oleh karena itu, diperlukan dua halangan. Harap perhatikan bahwa di VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL kamimenerjemahkan secara ketat dari VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL , bukan dari VK_IMAGE_LAYOUT_UNDEFINED . Karena kami hanya mengisi sebagian dari tekstur, penting bagi kami untuk tidak kehilangan bagian yang telah diisi sebelumnya.
Berikut video cara kerjanya. Satu tekstur. Satu objek. Puluhan ribu ubin.
Apa yang tersisa di balik layar adalah bagaimana menentukan dalam aplikasi bagaimana benar-benar mengetahui ubin mana yang waktu untuk memuat dan mana yang akan dibongkar. Pada bagian yang menjelaskan manfaat dari pendekatan baru, salah satu poinnya adalah Anda dapat menggunakan geometri kompleks. Dalam pengujian yang sama, saya sendiri menggunakan proyeksi ortografik dan persegi panjang yang paling sederhana. Dan saya menghitung id ubin secara analitis. Tdk sportif.
Faktanya, id ubin yang terlihat dihitung dua kali. Secara analitis pada CPU dan jujur pada shader fragmen. Tampaknya, mengapa tidak mengambilnya dari shader fragmen? Tapi tidak sesederhana itu. Ini akan menjadi artikel kedua.