Setelah mempelajari KMath , saya memutuskan untuk menggeneralisasi pengoptimalan ini ke berbagai struktur matematika dan operator yang ditentukan padanya.
KMath adalah pustaka untuk matematika dan aljabar komputer yang memanfaatkan pemrograman berorientasi konteks secara ekstensif di Kotlin. KMath memisahkan entitas matematika (bilangan, vektor, matriks) dan operasi pada mereka - mereka disediakan sebagai objek terpisah, aljabar yang sesuai dengan jenis operan, Aljabar <T> .
import scientifik.kmath.operations.*
ComplexField {
(i pow 2) + Complex(1.0, 3.0)
}Jadi, setelah menulis generator bytecode, dengan mempertimbangkan pengoptimalan JVM, Anda bisa mendapatkan penghitungan cepat untuk objek matematika apa pun - cukup untuk menentukan operasi pada objek tersebut di Kotlin.
API
Untuk memulainya, perlu untuk mengembangkan API ekspresi dan baru kemudian melanjutkan ke tata bahasa dan pohon sintaks. Itu juga muncul dengan ide pintar untuk mendefinisikan aljabar di atas ekspresi itu sendiri untuk menyajikan antarmuka yang lebih intuitif.
Basis dari seluruh API ekspresi adalah antarmuka <T> Ekspresi , dan cara termudah untuk mengimplementasikannya adalah dengan langsung menentukan metode pemanggilan dari parameter yang diberikan atau, misalnya, ekspresi bertingkat. Implementasi serupa diintegrasikan ke dalam modul root sebagai referensi, meskipun paling lambat.
interface Expression<T> {
operator fun invoke(arguments: Map<String, T>): T
}Implementasi yang lebih maju sudah didasarkan pada MST. Ini termasuk:
- Penerjemah MST,
- Generator kelas MST.
API untuk mengurai ekspresi dari string ke MST sudah tersedia di cabang pengembang KMath, seperti generator kode JVM yang lebih atau kurang final.
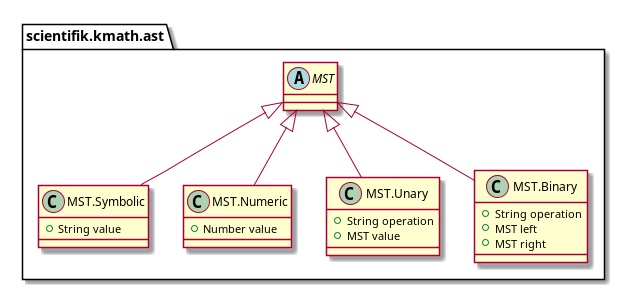
Mari beralih ke MST. Saat ini ada empat jenis node di MST:
- terminal:
- simbol (yaitu variabel)
- angka;
- operasi unary;
- operasi biner.
Hal pertama yang dapat Anda lakukan adalah memotong dan menghitung hasil dari data yang tersedia. Dengan meneruskan ID operasi ke aljabar target, misalnya "+", dan argumennya, misalnya 1.0 dan 1.0 , kita dapat mengharapkan hasil jika operasi ini ditentukan. Jika tidak, saat dievaluasi, ekspresi akan gagal dengan pengecualian.

Untuk bekerja dengan MST, selain bahasa ekspresi, ada juga aljabar - misalnya, MstField:
import scientifik.kmath.ast.*
import scientifik.kmath.operations.*
import scientifik.kmath.expressions.*
RealField.mstInField { number(1.0) + number(1.0) }() // 2.0Hasil dari metode di atas adalah implementasi Expression <T> yang, ketika dipanggil, menyebabkan traversal dari pohon yang diperoleh dengan mengevaluasi fungsi yang diteruskan ke mstInField .
Menghasilkan kode
Namun bukan itu saja: saat melakukan traverse, kita dapat menggunakan parameter pohon sesuka kita dan tidak mengkhawatirkan urutan tindakan dan kesiapan operasi. Inilah yang digunakan untuk menghasilkan bytecode.
Pembuatan kode dalam kmath-ast adalah perakitan berparameter dari kelas JVM. Inputnya adalah MST dan aljabar target, outputnya adalah instance Expression <T> .
Kelas yang sesuai, AsmBuilder , dan beberapa ekstensi lainnya menyediakan metode untuk membangun bytecode di atas ObjectWeb ASM. Mereka membuat MST traversal dan perakitan kelas terlihat bersih dan mengambil kurang dari 40 baris kode.
Pertimbangkan kelas yang dihasilkan untuk ekspresi "2 * x" , kode sumber Java yang didekompilasi dari bytecode ditampilkan:
package scientifik.kmath.asm.generated;
import java.util.Map;
import scientifik.kmath.asm.internal.MapIntrinsics;
import scientifik.kmath.expressions.Expression;
import scientifik.kmath.operations.RealField;
public final class AsmCompiledExpression_1073786867_0 implements Expression<Double> {
private final RealField algebra;
public final Double invoke(Map<String, ? extends Double> arguments) {
return (Double)this.algebra.add(((Double)MapIntrinsics.getOrFail(arguments, "x")).doubleValue(), 2.0D);
}
public AsmCompiledExpression_1073786867_0(RealField algebra) {
this.algebra = algebra;
}
}Pertama, Invoke metode dihasilkan di sini , di mana operan yang berurutan diatur (karena mereka lebih dalam pohon), maka add panggilan . Setelah pemanggilan , metode jembatan yang sesuai dicatat. Selanjutnya, kolom aljabar dan konstruktor ditulis . Dalam beberapa kasus, ketika konstanta tidak bisa begitu saja ditempatkan ke kumpulan konstanta kelas , kolom konstanta , larik java.lang.Object , juga ditulis .
Namun, karena banyaknya kasus edge dan pengoptimalan, implementasi generator menjadi agak rumit.
Mengoptimalkan panggilan ke Aljabar
Untuk memanggil operasi dari aljabar, Anda perlu meneruskan ID dan argumennya:
RealField { binaryOperation("+", 1.0, 1.0) } // 2.0Namun, panggilan semacam itu mahal dalam hal kinerja: untuk memilih metode mana yang akan dipanggil, RealField akan menjalankan pernyataan tableswitch yang relatif mahal , dan Anda juga perlu mengingat tentang tinju. Oleh karena itu, meskipun semua operasi MST dapat direpresentasikan dalam formulir ini, lebih baik melakukan panggilan langsung:
RealField { add(1.0, 1.0) } // 2.0Tidak ada konvensi khusus tentang pemetaan ID operasi ke metode dalam implementasi Aljabar <T> , jadi kami harus memasukkan kruk, yang secara manual tertulis bahwa "+" , misalnya, sesuai dengan metode penambahan. Ada juga dukungan untuk situasi yang menguntungkan saat Anda dapat menemukan metode untuk ID operasi dengan nama yang sama, jumlah argumen yang diperlukan, dan tipenya.
private val methodNameAdapters: Map<Pair<String, Int>, String> by lazy {
hashMapOf(
"+" to 2 to "add",
"*" to 2 to "multiply",
"/" to 2 to "divide",
...private fun <T> AsmBuilder<T>.findSpecific(context: Algebra<T>, name: String, parameterTypes: Array<MstType>): Method? =
context.javaClass.methods.find { method ->
...
nameValid && arityValid && notBridgeInPrimitive && paramsValid
}Masalah besar lainnya adalah tinju. Jika kita melihat tanda tangan metode Java yang diperoleh setelah mengompilasi RealField yang sama, kita akan melihat dua metode:
public Double add(double a, double b)
// $FF: synthetic method
// $FF: bridge method
public Object add(Object var1, Object var2)Tentu saja, lebih mudah untuk tidak repot-repot dengan tinju dan unboxing dan memanggil metode jembatan: ini muncul di sini karena penghapusan tipe, untuk mengimplementasikan metode add (T, T): T dengan benar , tipe T dalam deskriptor yang sebenarnya dihapus ke java.lang .Objek .
Memanggil menambahkan langsung dari dua ganda juga tidak ideal, karena nilai kembalian bauksit (ada pembahasan tentang ini di YouTrack Kotlin ( KT-29460 ), tetapi lebih baik memanggilnya untuk menyimpan dua cetakan objek masukan ke java.lang paling baik .Nomor dan unboxing mereka menjadi ganda .
Butuh waktu paling lama untuk menyelesaikan masalah ini. Kesulitannya di sini bukan dalam membuat panggilan ke metode primitif, tetapi dalam kenyataan bahwa Anda perlu menggabungkan pada tumpukan kedua tipe primitif (seperti double) dan pembungkusnya ( java.lang.Double , misalnya), dan menyisipkan tinju di tempat yang tepat (misalnya, java.lang.Double.valueOf ) dan unboxing ( doubleValue ) - sama sekali tidak perlu bekerja dengan tipe instruksi di bytecode.
Saya punya ide untuk menggantung abstraksi yang saya ketik di atas bytecode. Untuk melakukan ini, saya harus menggali lebih dalam tentang ObjectWeb ASM API. Saya akhirnya beralih ke backend Kotlin / JVM, memeriksa kelas StackValue secara mendetail(fragmen bytecode yang diketik, yang pada akhirnya mengarah pada penerimaan beberapa nilai pada tumpukan operan), menemukan utilitas Type , yang memungkinkan Anda untuk mengoperasikan dengan mudah dengan tipe yang tersedia dalam bytecode (primitif, objek, array), dan menulis ulang generator dengan penggunaannya. Masalah apakah akan mengemas atau membuka kotak nilai pada tumpukan diselesaikan dengan sendirinya dengan menambahkan ArrayDeque yang menyimpan tipe yang diharapkan oleh panggilan berikutnya.
internal fun loadNumeric(value: Number) {
if (expectationStack.peek() == NUMBER_TYPE) {
loadNumberConstant(value, true)
expectationStack.pop()
typeStack.push(NUMBER_TYPE)
} else ...?.number(value)?.let { loadTConstant(it) }
?: error(...)
}kesimpulan
Pada akhirnya, saya bisa membuat generator kode menggunakan ObjectWeb ASM untuk mengevaluasi ekspresi MST di KMath. Peningkatan kinerja melalui traversal MST sederhana bergantung pada jumlah node, karena bytecode bersifat linier dan tidak membuang waktu untuk pemilihan dan rekursi node. Misalnya, untuk ekspresi dengan 10 node, perbedaan waktu antara evaluasi dengan class yang dihasilkan dan interpreter adalah 19 hingga 30%.
Setelah memeriksa masalah yang saya hadapi, saya membuat kesimpulan sebagai berikut:
- Anda perlu segera mempelajari kapabilitas dan utilitas ASM - mereka sangat menyederhanakan pengembangan dan membuat kode dapat dibaca ( Type , InstructionAdapter , GeneratorAdapter );
- MaxStack , , — ClassWriter COMPUTE_MAXS COMPUTE_FRAMES;
- ;
- , , , ;
- , — , , ByteBuddy cglib.
Terima kasih sudah membaca.
Penulis artikel:
Yaroslav Sergeevich Postovalov , MBOU “Lyceum № 130 dinamai menurut Academician Lavrentyev ”, anggota laboratorium pemodelan matematika di bawah kepemimpinan Voytishek Anton Vatslavovich
Tatyana Abramova , peneliti laboratorium metode eksperimen fisika nuklir di JetBrains Research .