Untuk debut saya, saya ingin menemukan topik yang menarik bagi sebanyak mungkin penonton dan membutuhkan pertimbangan yang mendetail. Daniel Defoe berargumen bahwa kematian dan pajak menunggu siapa pun. Bagi saya, saya dapat mengatakan bahwa setiap teknisi dukungan akan memiliki pertanyaan tentang kebijakan penyimpanan titik pemulihan (atau, lebih sederhana, retensi). Bagaimana retensi bekerja, saya mulai menjelaskan 4 tahun yang lalu, sebagai insinyur junior tingkat pertama, dan terus menjelaskan sekarang, sudah menjadi pemimpin tim dari tim berbahasa Spanyol dan Italia. Saya yakin bahwa rekan-rekan saya dari tingkat dukungan kedua dan bahkan ketiga juga secara teratur menjawab pertanyaan yang sama.
Dalam hal ini, saya ingin menulis postingan terakhir yang paling mendetail, yang dapat dilihat oleh pengguna berbahasa Rusia berulang kali sebagai referensi. Momennya tepat - versi ulang tahun ke-10 yang baru dirilis menambahkan fitur-fitur baru ke fungsionalitas dasar yang tidak berubah selama bertahun-tahun. Posting saya difokuskan terutama pada versi ini - meskipun sebagian besar dari apa yang ditulis benar untuk versi sebelumnya, Anda tidak akan menemukan beberapa fungsi yang dijelaskan di sana. Akhirnya, melihat sedikit ke masa depan, saya akan mengatakan bahwa beberapa perubahan diharapkan di versi berikutnya, tetapi kami akan memberi tahu Anda tentang ini ketika saatnya tiba. Jadi mari kita mulai.
Pekerjaan cadangan
Untuk memulai, mari kita lihat bagian yang tidak berubah di versi 10. Kebijakan penyimpanan ditentukan oleh beberapa parameter. Mari buka jendela untuk membuat tugas baru dan pergi ke tab Storage. Di sini kita akan melihat parameter yang menentukan jumlah titik pemulihan yang diinginkan:
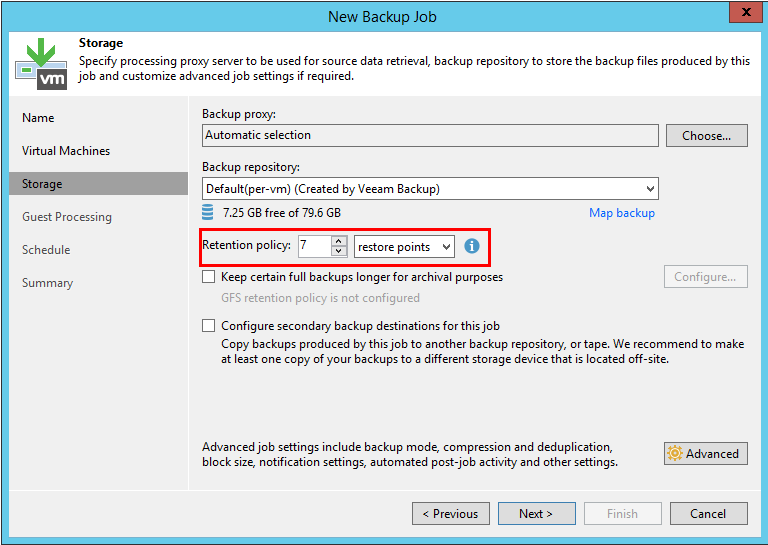
Namun, ini hanya sebagian dari persamaan. Jumlah poin sebenarnya juga ditentukan oleh mode cadangan yang diatur untuk tugas tersebut. Untuk memilih parameter ini, Anda perlu mengklik tombol Advanced pada tab yang sama. Ini akan membuka jendela baru dengan banyak opsi. Mari beri nomor dan pertimbangkan mereka secara bergantian:
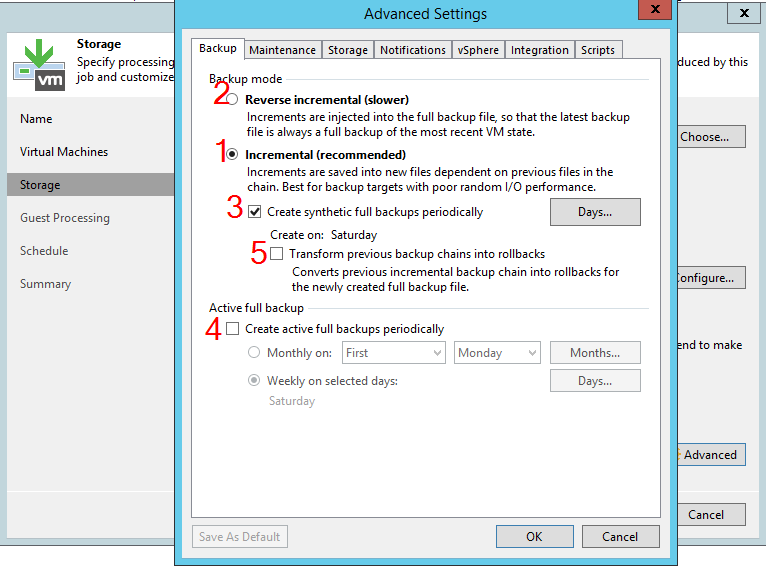
Jika hanya opsi 1 yang diaktifkan, pekerjaan akan dijalankan dalam mode "incremental teruskan selamanya". Tidak ada kesulitan di sini - tugas akan menyimpan sejumlah titik pemulihan dari cadangan penuh (file dengan ekstensi VBK) hingga kenaikan terakhir (file dengan ekstensi VIB). Jika jumlah poin melebihi nilai yang ditentukan, kenaikan terlama akan digabungkan dengan cadangan penuh. Dengan kata lain, jika tugas disetel untuk menyimpan 3 poin, maka segera setelah sesi berikutnya akan ada 4 poin dalam repositori, setelah itu cadangan penuh akan digabungkan dengan kenaikan terlama dan jumlah total poin akan kembali menjadi 3.

Ini juga sangat mudah untuk memperbaiki mode inkremental terbalik (opsi 2). Karena dalam hal ini titik terbaru akan menjadi cadangan penuh, diikuti oleh rangkaian yang disebut rollback (file dengan ekstensi VRB), maka untuk menerapkan retensi, Anda hanya perlu menghapus rollback terlama. Situasinya akan sama: segera setelah sesi, jumlah poin akan melebihi set sebesar 1, setelah itu akan kembali ke nilai yang diinginkan.
Perhatikan bahwa dengan mode reverse-incremental, Anda juga dapat mengaktifkan pencadangan penuh berkala (opsi 4), tetapi ini tidak akan mengubah intinya. Ya, titik pemulihan penuh akan muncul di rantai, tetapi kami masih akan menghapus poin terlama satu per satu.
Akhirnya, kita sampai pada bagian yang menarik. Jika Anda mengaktifkan incremental backup, tetapi juga mengaktifkan opsi 3 atau 4 (atau keduanya pada saat yang sama), tugas akan mulai membuat backup penuh berkala menggunakan metode "aktif" atau sintetis. Metode untuk membuat full backup tidak penting - ini akan berisi data yang sama, dan rantai tambahan akan dipecah menjadi subchains. Metode ini disebut forward incremental, dan dialah yang mengajukan sebagian besar pertanyaan dari klien kami.
Mempertahankan digunakan di sini dengan menghapus bagian terlama dari rantai (dari backup penuh ke increment). Pada saat yang sama, kami tidak hanya akan menghapus cadangan kosong atau hanya sebagian dari kenaikan. Seluruh "subset" dihapus seluruhnya sekaligus. Arti menyetel jumlah poin juga berubah - jika dalam metode lain ini adalah angka maksimum yang diizinkan, setelah itu Anda perlu menerapkan retensi, setelan ini menentukan angka minimum. Dengan kata lain, setelah menghapus "sub-string" terlama, jumlah titik di bagian yang tersisa tidak boleh di bawah jumlah minimum ini.
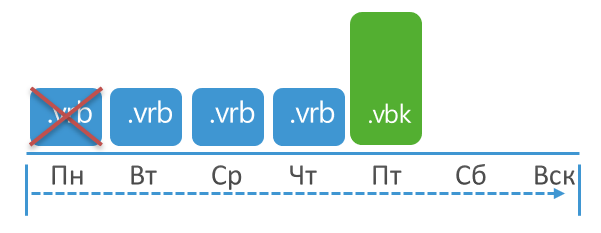
Saya akan mencoba menggambarkan konsep ini secara grafis. Misalkan retensi disetel ke 3 poin, tugas berjalan setiap hari dengan pencadangan penuh pada hari Senin. Dalam hal ini, retensi akan diterapkan ketika jumlah total poin mencapai 10:
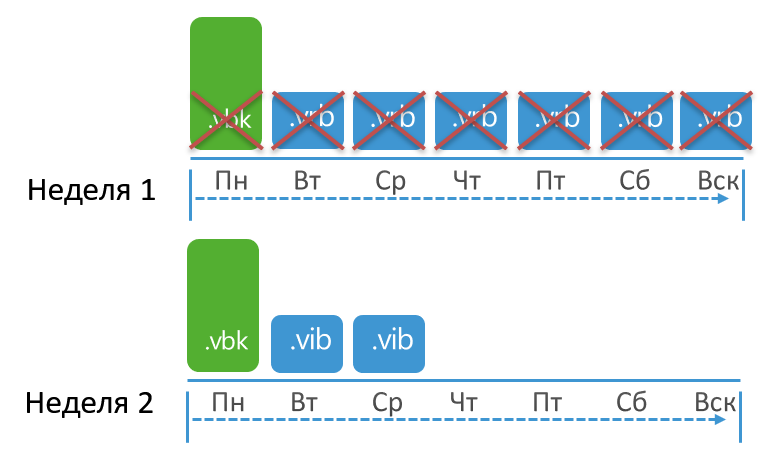
Mengapa sebanyak 10 saat mereka memasang 3? Cadangan lengkap telah dibuat pada hari Senin. Dari Selasa hingga Minggu, pekerjaan menciptakan kenaikan. Akhirnya, Senin depan, cadangan penuh dibuat lagi, dan hanya ketika 2 peningkatan dibuat akhirnya seluruh bagian rantai yang lama dapat dihapus, karena jumlah poin yang tersisa tidak akan jatuh di bawah set 3.
Jika idenya jelas, maka saya sarankan Anda mencoba menghitung retensi sendiri. Mari kita ambil kondisi ini: tugas diluncurkan untuk pertama kalinya pada hari Kamis (tentu saja, pencadangan penuh akan dibuat). Tugas diatur untuk membuat cadangan penuh pada hari Rabu dan Minggu dan menyimpan 8 titik pemulihan. Kapan retensi akan diterapkan untuk pertama kalinya?
Untuk menjawab pertanyaan ini, saya menganjurkan agar Anda mengambil selembar kertas, menyusunnya berdasarkan hari dalam seminggu dan menuliskan titik mana yang dibuat setiap hari. Jawabannya akan menjadi jelas
Menjawab

: « »? – 3 (VBK, VIB, VIB) 8 . , , 11 , . . .
: « »? – 3 (VBK, VIB, VIB) 8 . , , 11 , . . .
Beberapa pembaca mungkin berpendapat: "Mengapa semua ini jika ada rps.dewin.me ?" Tanpa ragu, ini adalah alat yang sangat berguna, dan dalam beberapa kasus saya akan menggunakannya, tetapi juga memiliki keterbatasan. Pertama-tama, ini tidak memungkinkan Anda untuk menentukan kondisi awal, dan dalam banyak kasus pertanyaannya adalah “kita memiliki rantai seperti itu, apa yang akan terjadi jika kita mengubah pengaturan ini dan itu?”. Kedua, alat masih kurang jelas. Menunjukkan halaman RPS ke klien, saya tidak menemukan pengertian, tetapi setelah mengecatnya seperti pada contoh (bahkan menggunakan Paint yang sama), hari demi hari, semuanya menjadi jelas.
Terakhir, kami belum membahas opsi "Transformasi rantai cadangan sebelumnya menjadi rollback" (ditandai dengan 5). Opsi ini terkadang membingungkan klien yang mengaktifkannya "secara otomatis", yang ingin mengaktifkan cadangan sintetis. Sementara itu, opsi ini mengaktifkan mode cadangan yang sangat khusus. Tanpa membahas secara detail, saya akan segera mengatakan bahwa pada tahap pengembangan produk ini "Transformasi rantai cadangan sebelumnya menjadi rollback" adalah opsi yang sudah ketinggalan zaman, dan saya tidak dapat memikirkan satu skenario pun kapan harus digunakan. Nilainya sangat dipertanyakan sehingga untuk sementara Anton Gostev sendiri berteriak melalui forum, memintanya untuk mengiriminya contoh penggunaan yang berguna (jika Anda memilikinya, tulis di komentar, saya sangat tertarik). Jika tidak ada (menurut saya akan demikian), opsi akan dihapus di versi mendatang.
Pekerjaan akan membuat kenaikan (VIB) hingga hari saat backup penuh sintetis dijadwalkan. Pada hari ini, VBK benar-benar dibuat, tetapi semua titik sebelum VBK ini diubah menjadi rollback (VRB). Setelah itu, tugas akan terus membuat penambahan ke full backup hingga backup sintetis berikutnya. Akibatnya, campuran file VBK, VBR, dan VIB yang eksplosif dibuat dalam rangkaian. Mempertahankan diterapkan dengan sangat sederhana - dengan menghapus VBR terakhir:

Masalah
Selain memahami cara kerjanya, sebagian besar masalah yang muncul saat menggunakan mode incremental biasanya terkait dengan full backup. Cadangan lengkap reguler diperlukan untuk mode ini, jika tidak, repositori akan mengumpulkan poin hingga meluap.
Misalnya, cadangan lengkap mungkin terlalu jarang dibuat. Katakanlah tugas diatur untuk menyimpan 10 poin, dan cadangan penuh dibuat sebulan sekali. Jelas bahwa jumlah poin sebenarnya di sini akan jauh lebih tinggi daripada yang ditetapkan. Atau tugas biasanya diatur untuk bekerja dalam mode inkremental tak terbatas dan menyimpan 50 poin. Kemudian seseorang secara tidak sengaja membuat cadangan lengkap. Itu saja, mulai sekarang, tugas akan menunggu hingga poin penuh mengumpulkan 49 peningkatan, setelah itu akan menerapkan retensi dan kembali ke mode penuh tanpa batas.
Dalam kasus lain, pencadangan lengkap diatur untuk dibuat secara teratur, tetapi karena alasan tertentu tidak. Saya akan menuliskan alasan paling populer di sini. Beberapa pelanggan lebih suka menggunakan opsi penjadwalan "jalankan setelah" dan menyiapkan pekerjaan untuk dijalankan secara berantai. Mari kita ambil contoh ini: ada 3 pekerjaan yang berjalan setiap hari dan membuat cadangan penuh pada hari Minggu. Tugas pertama dimulai pukul 22.30, sisanya diluncurkan secara berantai. Pencadangan tambahan membutuhkan waktu 10 menit, dan oleh karena itu pada pukul 23.00 semua tugas selesai. Tetapi pencadangan penuh membutuhkan waktu satu jam, jadi yang berikut ini terjadi pada hari Minggu: tugas pertama berjalan dari pukul 22.30 hingga 23.30. Yang berikutnya dari pukul 23.30 hingga 00.30. Tetapi tugas ketiga dimulai pada hari Senin. Cadangan lengkap disetel untuk hari Minggu, jadi dalam hal ini cadangan tidak akan ada.Tugas akan menunggu cadangan penuh untuk menerapkan retensi. Jadi berhati-hatilah saat menggunakan opsi "jalankan setelah" atau jangan gunakan sama sekali - cukup setel pekerjaan untuk dimulai pada waktu yang sama dan biarkan penjadwal sumber daya melakukan tugasnya.
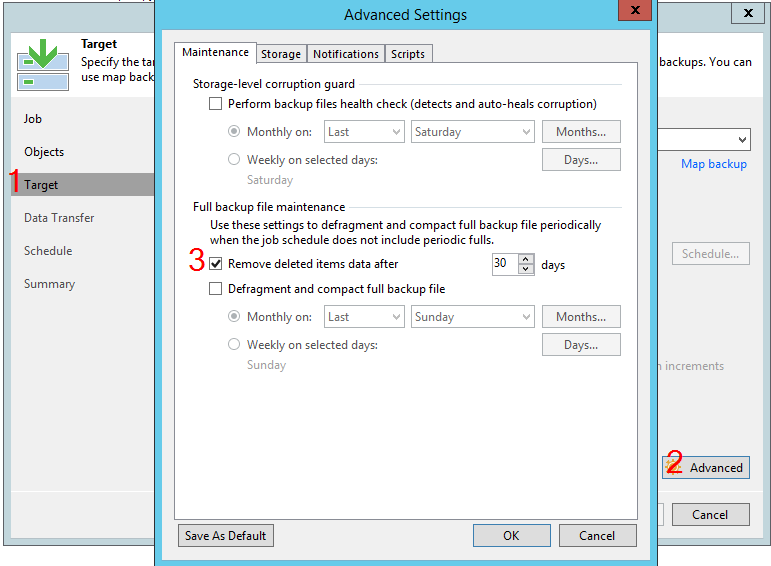
Opsi sulit "Hapus item yang dihapus"
Melalui pengaturan tugas Penyimpanan - Lanjutan - Pemeliharaan, Anda dapat menemukan opsi "hapus data item yang dihapus setelah", dihitung dalam beberapa hari.
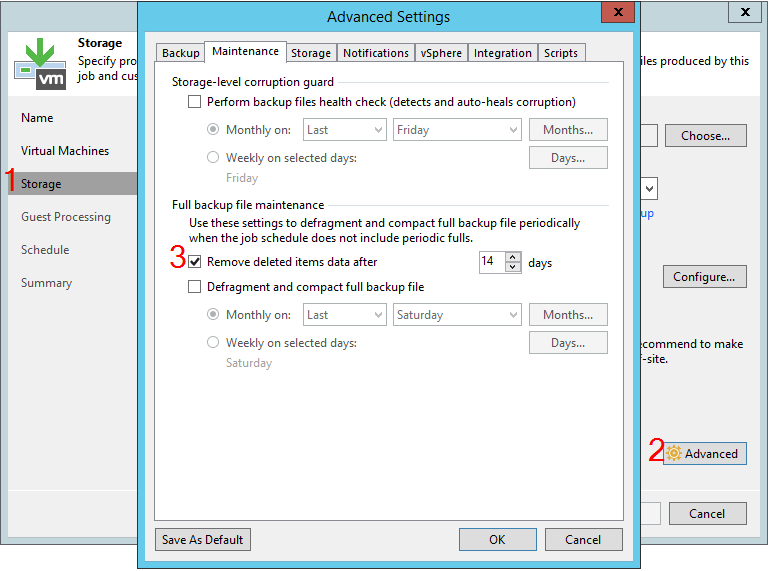
Beberapa klien mengharapkan ini menjadi retensi. Faktanya, ini adalah opsi yang sepenuhnya terpisah, kesalahpahaman yang dapat menyebabkan konsekuensi yang tidak terduga. Namun, langkah pertama adalah menjelaskan bagaimana B&R bereaksi terhadap situasi di mana hanya beberapa mesin yang berhasil dicadangkan selama satu sesi.
Pertimbangkan skenario ini: pekerjaan inkremental tak terbatas yang dikonfigurasi untuk menyimpan 6 poin. Dalam tugas ada 2 mesin, yang satu selalu berhasil di-backup, yang lain terkadang error. Akibatnya, hingga poin ketujuh berkembang situasi berikut:
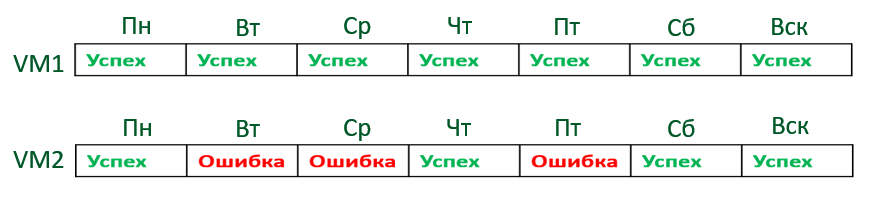
Saatnya menerapkan retensi, tetapi satu mobil memiliki 7 poin dan yang lainnya hanya memiliki 4. Apakah retensi akan diterapkan di sini? Jawabannya ya itu akan. Jika setidaknya satu objek telah dicadangkan, B&R akan mempertimbangkan titik yang akan dibuat.
Situasi serupa dapat muncul jika mesin tertentu tidak disertakan dalam tugas selama sesi tertentu. Hal ini terjadi, misalnya, saat mesin tidak ditambahkan ke tugas satu per satu, tetapi sebagai bagian dari penampung (folder, penyimpanan) dan beberapa mesin dipindahkan sementara ke penampung lain. Dalam hal ini, tugas akan dianggap berhasil, tetapi dalam statistik Anda akan menemukan pesan yang mendesak Anda untuk memperhatikan bahwa mesin ini dan itu tidak lagi diproses oleh tugas.

Apa yang akan terjadi jika Anda tidak memperhatikan hal ini? Dalam kasus mode incremental-incremental atau reverse-incremental yang tak terbatas, jumlah titik pemulihan dari mesin "masalah" akan berkurang dengan setiap sesi hingga mencapai 1 yang disimpan di VBK. Dengan kata lain, meskipun mesin tidak dicadangkan untuk waktu yang lama, satu titik pemulihan akan tetap ada. Ini tidak terjadi jika pencadangan penuh berkala diaktifkan. Jika Anda mengabaikan sinyal dari B&R, titik terakhir dapat dihapus bersama dengan bagian rantai yang lama.
Dengan jelasnya detail ini, akhirnya kita dapat melihat opsi "Hapus data item yang dihapus setelah". Ini akan menghapus semua poin untuk kendaraan tertentu jika kendaraan itu tidak dicadangkan selama X hari. Harap dicatat bahwa pengaturan ini tidak menanggapi kesalahan (mencobanya - tidak berhasil). Bahkan seharusnya tidak ada upaya untuk membuat cadangan mesin. Tampaknya opsi ini berguna dan harus selalu diaktifkan. Jika administrator menghapus mesin dari tugas tersebut, maka logis untuk menghapus rantai dari data yang tidak perlu setelah beberapa saat. Namun, penyetelan membutuhkan disiplin dan perhatian.
Izinkan saya memberi Anda contoh dari latihan: beberapa kontainer ditambahkan ke tugas, yang komposisinya cukup dinamis. Karena kurangnya RAM B&R, server mengalami masalah yang tidak diketahui. Tugas dimulai dan mencoba mencadangkan mesin, kecuali yang tidak ada di penampung pada saat itu. Karena banyak mesin memberikan kesalahan, secara default B&R harus melakukan 3 upaya tambahan untuk membuat cadangan mesin yang "bermasalah". Karena masalah terus-menerus dengan RAM, upaya ini membutuhkan waktu beberapa hari. Tidak ada upaya berulang untuk membuat cadangan VM yang hilang (tidak adanya VM bukan merupakan kesalahan). Akibatnya, selama salah satu pengulangan, kondisi "Hapus item yang dihapus" terpenuhi dan semua titik mesin dihapus.
Dalam hal ini, saya dapat mengatakan yang berikut: jika Anda telah mengonfigurasi pemberitahuan tentang hasil tugas, atau bahkan lebih baik - Anda menggunakan integrasi dengan Veeam ONE, kemungkinan besar hal ini tidak akan terjadi pada Anda. Jika Anda memeriksa server B&R sekali seminggu untuk memeriksa apakah semuanya berfungsi, lebih baik menolak opsi yang berpotensi mengarah pada penghapusan cadangan.
Apa yang ditambahkan di v.10
Apa yang kita bicarakan sebelumnya telah ada di B&R untuk banyak versi. Setelah memahami prinsip-prinsip kerja ini, sekarang mari kita lihat apa yang telah ditambahkan ke peringatan "sepuluh".
Retensi harian
Di atas, kami menganggap kebijakan penyimpanan "klasik" berdasarkan jumlah poin. Pendekatan alternatif adalah dengan menetapkan "hari" daripada "titik pemulihan" di menu yang sama.
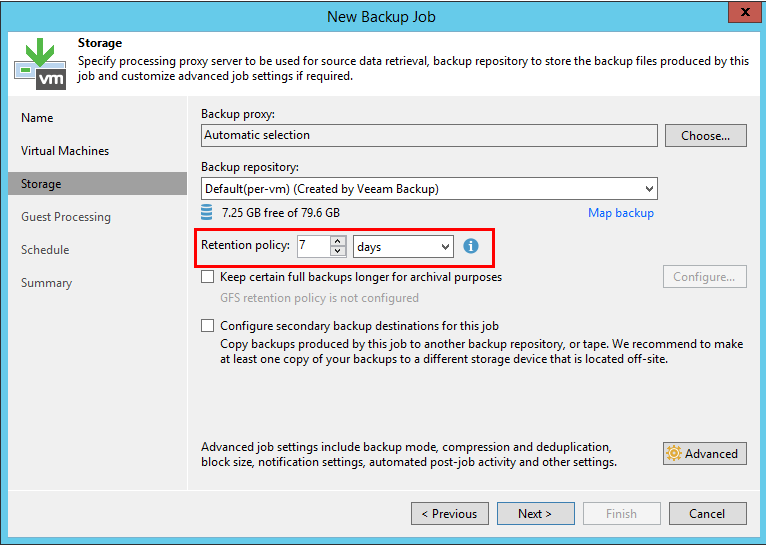
Idenya jelas dari namanya - retensi akan menyimpan sejumlah hari tertentu, tetapi jumlah poin dalam setiap hari tidak menjadi masalah. Saat melakukannya, ingatlah yang berikut ini:
- Hari ini tidak diperhitungkan saat menghitung retensi
- Hari-hari ketika tugas tidak berhasil sama sekali juga dihitung. Ini harus diingat agar tidak kehilangan poin dari tugas-tugas yang bekerja tidak teratur secara tidak sengaja.
- Titik pemulihan dihitung sejak hari pembuatannya dimulai (yaitu, jika tugas mulai bekerja pada hari Senin dan selesai pada hari Selasa, maka titik ini adalah dari hari Senin)
Adapun sisanya, prinsip penerapan retensi menurut tugas juga ditentukan oleh metode cadangan yang dipilih. Mari kita coba tugas kalkulasi lain menggunakan metode inkremental yang sama. Misalkan retensi disetel selama 8 hari, tugas berjalan setiap 6 jam dengan pencadangan penuh pada hari Rabu. Namun, tugas tersebut tidak bekerja pada hari Minggu. Pekerjaan dimulai pada hari Senin untuk pertama kalinya. Kapan retensi akan diterapkan?
Menjawab
, . , , . , , 4 .
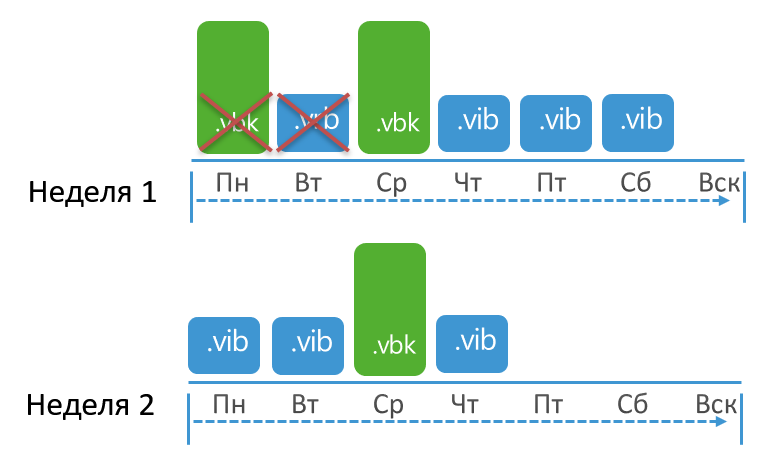
. ? 8 . , , , . – .
. ? 8 . , , , . – .
Pengarsipan GFS untuk Pekerjaan Normal
Sebelum v.10, metode penyimpanan Kakek-Ayah-Anak (GFS) hanya tersedia untuk pekerjaan salinan Cadangan dan penyalinan pita. Sekarang tersedia untuk backup biasa.
Meskipun ini tidak relevan dengan topik saat ini, saya tidak bisa tidak mengatakan bahwa fungsi baru tidak berarti penyimpangan dari strategi 3-2-1. Kehadiran titik arsip di repositori utama tidak memengaruhi keandalannya dengan cara apa pun. Ini dimaksudkan agar GFS akan digunakan bersama dengan repositori Scale-out untuk memindahkan titik-titik ini ke S3 dan repositori serupa. Jika Anda tidak menggunakannya, yang terbaik adalah terus menyimpan poin utama dan arsip di repositori yang berbeda.Sekarang mari kita lihat prinsip-prinsip pembuatan poin GFS. Dalam pengaturan tugas, pada langkah Penyimpanan, tombol khusus telah muncul yang memanggil menu berikut:
Inti dari GFS dapat dikurangi menjadi beberapa poin (perhatikan bahwa GFS bekerja secara berbeda dalam jenis tugas lain, tetapi lebih lanjut tentang itu nanti):
- Tugas tidak membuat cadangan lengkap terpisah untuk titik GFS. Sebagai gantinya, cadangan lengkap yang paling sesuai yang tersedia akan digunakan. Oleh karena itu, tugas harus bekerja dalam mode inkremental dengan pencadangan penuh berkala, atau pencadangan penuh harus dibuat secara manual oleh pengguna.
- Jika hanya satu periode yang diaktifkan (misalnya, seminggu), maka di awal periode GFS, tugas akan mulai menunggu pencadangan penuh dan menandai yang pertama yang sesuai sebagai GFS.
Contoh: Pekerjaan dikonfigurasi untuk menyimpan GFS mingguan menggunakan cadangan hari Rabu. Tugas berjalan setiap hari, tetapi pencadangan penuh dijadwalkan untuk hari Jumat. Dalam hal ini, periode GFS akan dimulai pada hari Rabu dan pekerjaan akan mulai menunggu titik yang sesuai. Ini akan muncul pada hari Jumat dan akan ditandai dengan bendera GFS.
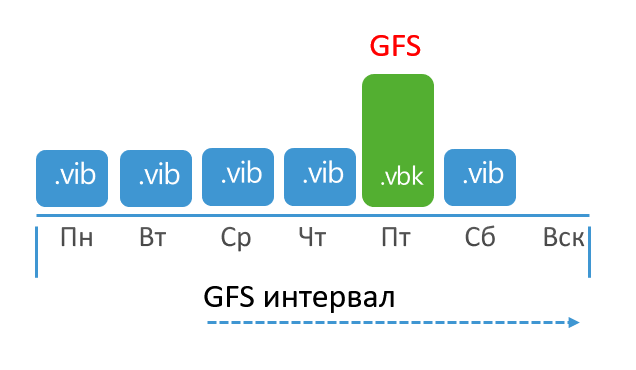
- (, ), B&R , GFS ( ). , .
Contoh: GFS mingguan ditagih pada hari Rabu, dan GFS bulanan ditagih pada minggu terakhir setiap bulan. Tugas ini berjalan setiap hari dan membuat cadangan penuh pada hari Senin dan Jumat.
Untuk mempermudah, mari kita mulai menghitung dari minggu terakhir setiap bulan. Minggu ini, pencadangan penuh akan dibuat pada hari Senin, tetapi akan diabaikan karena interval GFS mingguan dimulai pada hari Rabu. Tetapi full backup hari Jumat sepenuhnya cocok untuk titik GFS. Sistem ini sudah tidak asing lagi bagi kita.
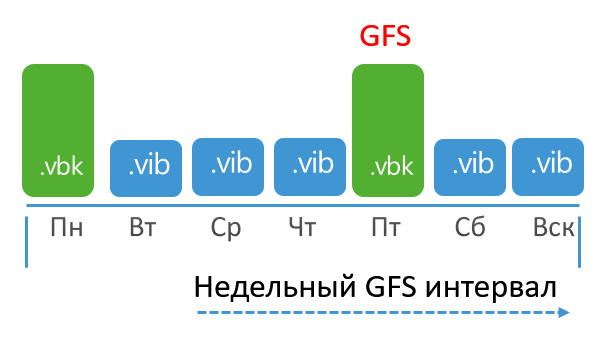
Sekarang pertimbangkan apa yang terjadi pada minggu terakhir setiap bulan. Interval GFS bulanan akan dimulai pada hari Senin, tetapi VBK hari Senin tidak akan ditandai sebagai GFS karena tugas berusaha menandai satu VBK sebagai titik GFS bulanan dan mingguan. Dalam hal ini, pencarian dimulai dengan pencarian mingguan, oleh karena itu, menurut definisi, bisa juga menjadi bulanan.
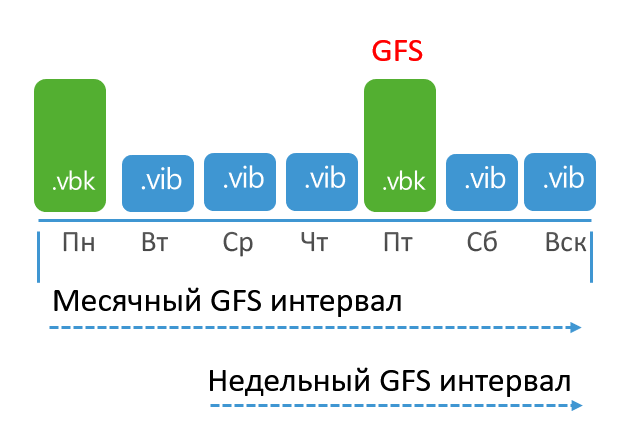
Dalam kasus ini, jika Anda hanya menyertakan interval mingguan dan tahunan, maka keduanya akan bertindak secara independen satu sama lain dan dapat menandai 2 VBK terpisah sebagai sesuai dengan interval GFS.
Tugas salin cadangan
Jenis tugas lain yang sering membutuhkan klarifikasi dalam pekerjaan. Pertama, mari kita analisis metode kerja "klasik", tanpa inovasi v.10
Metode retensi sederhana
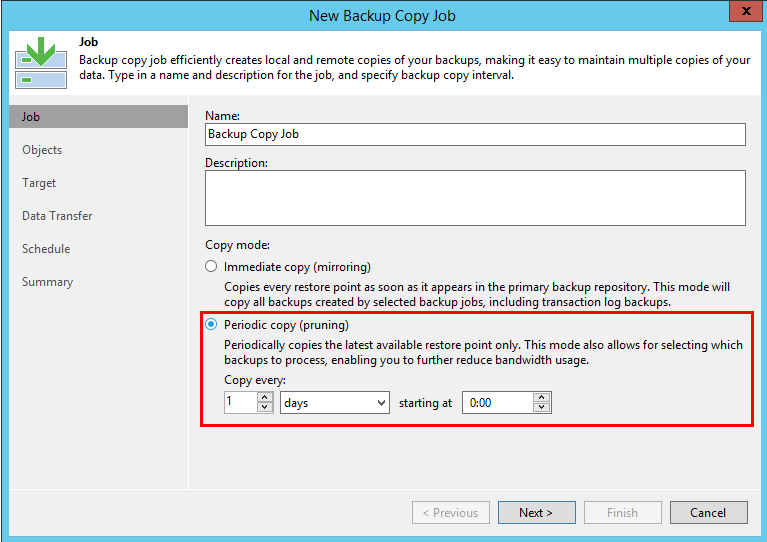
Secara default, pekerjaan semacam itu berjalan dalam mode inkremental tak terbatas. Pembuatan titik ditentukan oleh dua parameter - interval salinan dan jumlah titik pemulihan yang diinginkan (tidak ada retensi berdasarkan hari). Interval penyalinan diatur pada tab Pekerjaan pertama saat membuat pekerjaan:
Jumlah poin ditentukan lebih jauh pada
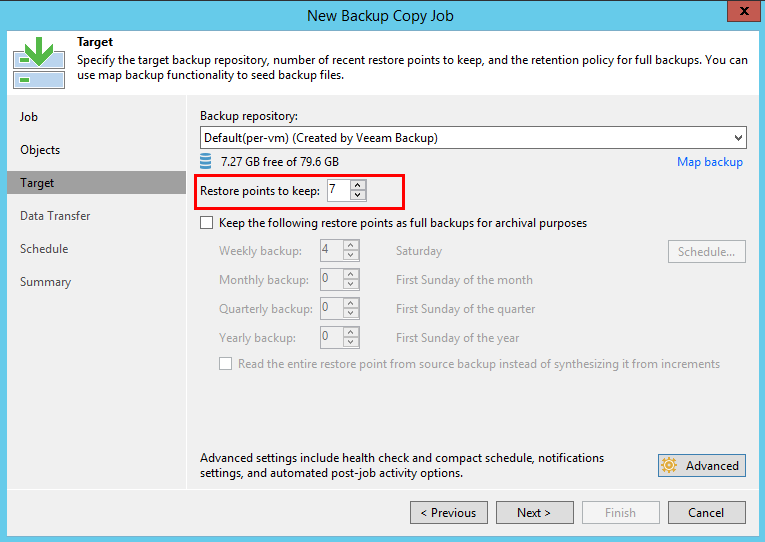
tab Target. Pekerjaan membuat 1 poin baru untuk setiap interval (tidak peduli berapa banyak poin yang dibuat untuk VM oleh pekerjaan asli). Di akhir interval, titik baru diselesaikan dan, jika perlu, retensi diterapkan dengan menggabungkan VBK dan kenaikan terlama. Kami sudah akrab dengan mekanisme ini.
Mempertahankan metode menggunakan GFS
BCJ juga tahu cara menyimpan poin arsip. Ini dikonfigurasi pada tab Target yang sama, tepat di bawah pengaturan untuk jumlah titik pemulihan: Titik

GFS dapat dibuat dengan dua cara - secara sintetis, menggunakan data di repositori sekunder, atau dengan mensimulasikan cadangan penuh dan membaca semua data dari repositori utama (diaktifkan dengan opsi yang ditandai dengan angka 3) ... Retensi dalam kedua kasus akan sangat berbeda, jadi kami akan mempertimbangkannya secara terpisah.
GFS sintetis
Dalam kasus ini, titik GFS tidak dibuat pada tanggal yang tepat. Sebaliknya, titik GFS akan dibuat ketika VIB pada hari saat titik GFS dijadwalkan untuk dibuat digabungkan dengan cadangan penuh. Hal ini terkadang menyebabkan kebingungan, karena waktu berlalu, tetapi masih belum ada titik GFS. Dan hanya dukun yang kuat dari dukungan teknis yang dapat memprediksi pada hari apa poin tersebut akan muncul. Faktanya, sihir tidak diperlukan - lihat saja jumlah titik yang ditetapkan dan interval sinkronisasi (berapa banyak titik yang dibuat setiap hari). Coba hitung sendiri menggunakan contoh ini: tugas disetel untuk menyimpan 7 poin, interval sinkronisasi adalah 12 jam (yaitu 2 poin per hari). Saat ini, sudah ada 7 titik dalam rantai, hari ini adalah Senin, dan pembuatan titik GFS dijadwalkan untuk hari ini. Hari apa itu akan dibuat?
Menjawab
, , :
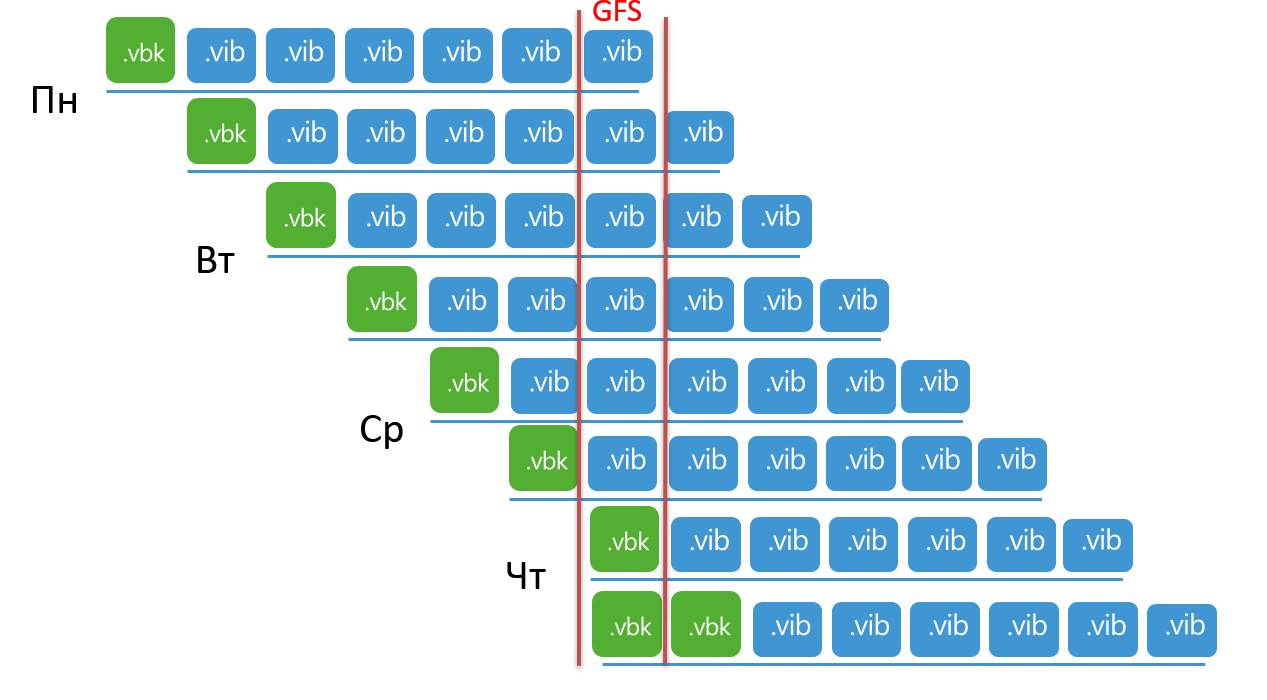
, GFS, . 2 , . , . , – «» . 8 – 7 + GFS.
, GFS, . 2 , . , . , – «» . 8 – 7 + GFS.
Membuat Poin GFS dengan opsi "Baca seluruh poin"
Di atas, saya katakan bahwa BCJ bekerja dalam mode inkremental tak terbatas. Sekarang kita akan menganalisis satu-satunya pengecualian untuk aturan ini. Jika Anda mengaktifkan opsi "Baca seluruh poin", poin GFS akan dibuat tepat pada hari yang dijadwalkan. Tugas itu sendiri akan bekerja dalam mode inkremental dengan pencadangan penuh berkala, yang telah kita bahas di atas. Penahan juga akan diterapkan dengan melepas bagian rantai terlama. Namun, dalam kasus ini, hanya kenaikan yang akan dihapus, dan cadangan penuh akan ditinggalkan sebagai titik GFS. Karenanya, poin yang ditandai dengan bendera GFS tidak diperhitungkan saat menghitung retensi.
Katakanlah tugas diatur untuk menyimpan 7 poin dan membuat titik GFS mingguan pada hari Senin. Dalam kasus ini, setiap hari Senin, pekerjaan akan benar-benar membuat cadangan lengkap dan menandainya sebagai GFS. Mempertahankan akan diterapkan jika, setelah menghapus penambahan dari bagian terlama, jumlah penambahan yang tersisa tidak berada di bawah 7. Ini adalah tampilannya pada diagram:

Jadi, di akhir minggu kedua, ada 14 poin di rantai. Selama minggu kedua, tugas menciptakan 7 poin. Jika itu adalah tugas sederhana, retensi sudah diterapkan. Tapi ini BCJ dengan retensi GFS, jadi kami tidak menghitung poin GFS, yang artinya hanya ada 6 poin. Artinya, kami belum bisa menerapkan retensi. Di minggu ketiga kami membuat full backup lainnya dengan flag GFS. 15 poin, tapi kami tidak menghitung yang ini lagi. Terakhir, pada hari Selasa minggu ketiga, kami membuat kenaikan. Sekarang, jika kita menghapus penambahan rantai pada minggu pertama, jumlah total kenaikan akan memenuhi retensi yang ditetapkan.
Seperti disebutkan di atas, dalam metode ini sangat penting untuk membuat full backup secara teratur. Misalnya, jika Anda menetapkan retensi utama selama 7 hari, tetapi hanya 1 poin tahunan, mudah untuk membayangkan bahwa kenaikan akan terakumulasi secara kuat, lebih dari 7. Dalam kasus seperti itu, lebih baik menggunakan metode sintetis untuk membuat GFS.
Dan lagi "Hapus item yang dihapus"
Opsi ini juga ada untuk BCJ:
Logika opsi ini di sini sama seperti di pekerjaan pencadangan biasa - jika mesin tidak diproses selama jumlah hari yang ditentukan, maka datanya akan dihapus dari rantai. Namun, untuk BCJ, kegunaan opsi ini secara obyektif lebih tinggi, dan inilah alasannya.
Dalam mode normal, BCJ bekerja dalam mode inkremental tak terhingga, jadi jika pada titik tertentu mesin dihapus dari pekerjaan tersebut, maka retensi akan secara bertahap menghapus semua titik pemulihan hingga hanya tersisa satu - di VBK. Sekarang bayangkan tugas tersebut masih dikonfigurasi untuk membuat titik GFS sintetis. Jika saatnya tiba, tugas perlu membuat GFS untuk semua mesin dalam rangkaian tersebut. Jika beberapa mobil tidak memiliki poin baru sama sekali - yah, Anda harus menggunakan yang ada. Dan setiap saat. Akibatnya, situasi berikut mungkin muncul:
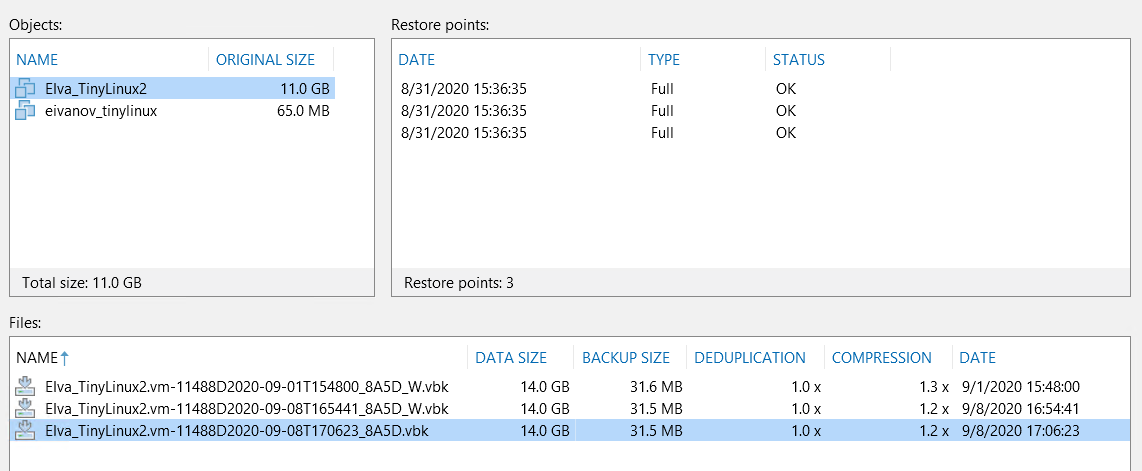
Perhatikan bagian File: kami memiliki VBK utama dan 2 poin GFS mingguan. Dan sekarang di bagian Pulihkan poin - sebenarnya, file-file ini berisi gambar yang sama dari mesin. Secara alami, tidak ada gunanya poin GFS seperti itu, mereka hanya membutuhkan ruang.
Situasi ini hanya mungkin jika menggunakan GFS sintetis. Untuk mencegahnya, gunakan opsi "Buang item yang dihapus". Jangan lupa untuk mengaturnya selama beberapa hari. Dukungan teknis melihat kasus ketika opsi ditetapkan untuk hari yang lebih sedikit daripada interval sinkronisasi - BCJ mulai mengamuk dan menghapus titik sebelum mereka dapat membuatnya.
Perhatikan juga bahwa opsi ini tidak memengaruhi poin GFS yang ada. Jika Anda ingin membersihkan arsip, Anda harus melakukannya secara manual - dengan mengklik kanan pada mesin dan memilih "Hapus dari disk" (di jendela yang muncul, jangan lupa untuk mencentang kotak "Hapus cadangan penuh GFS"):

Baru di v.10 - salinan langsung
Setelah berurusan dengan fungsionalitas "klasik", mari beralih ke yang baru. Inovasi itu satu, tapi sangat penting. Ini adalah mode operasi baru.
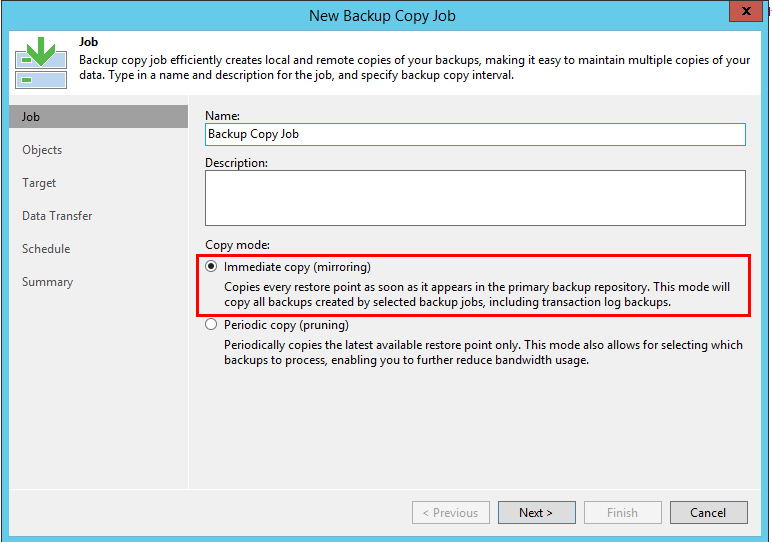
Tidak ada yang namanya "interval sinkronisasi", tugas akan terus memantau apakah titik baru telah muncul, dan menyalin semuanya, tidak peduli berapa banyak dari mereka. Namun, pekerjaan tetap inkremental, yaitu, meskipun pekerjaan utama membuat VBK atau VRB, poin ini akan disalin sebagai VIB. Jika tidak, tidak ada kejutan dalam mode ini - baik retensi standar dan GFS berfungsi sesuai dengan aturan yang dijelaskan di atas (meskipun hanya GFS sintetis yang tersedia di sini).
Disk berputar. Fitur repositori drive yang diputar
Ancaman terus-menerus dari virus ransomware telah menjadikannya standar keamanan de facto untuk memiliki salinan data pada media yang tidak dapat dijangkau oleh virus. Salah satu opsinya adalah menggunakan repositori disk yang diputar, di mana disk digunakan satu per satu: saat satu disk terhubung dan dapat ditulis, sisanya disimpan di tempat yang aman.
Untuk mengajari B&R bekerja dengan repositori semacam itu, dalam pengaturan repositori, pada langkah Repositori, klik tombol Advanced dan pilih opsi yang sesuai:
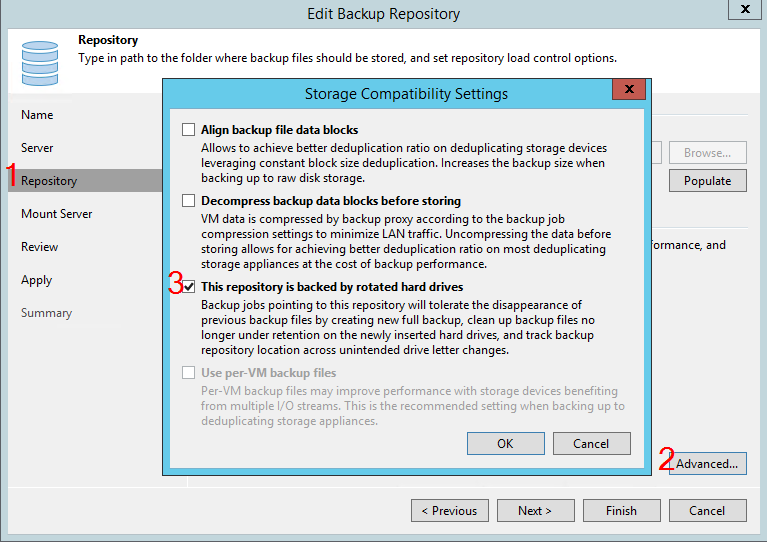
Setelah itu, VBR akan berharap bahwa rantai yang ada secara berkala akan menghilang dari repositori, yang berarti rotasi disk. B&R akan berperilaku berbeda tergantung pada jenis repositori dan jenis pekerjaan. Ini dapat diwakili oleh tabel berikut:
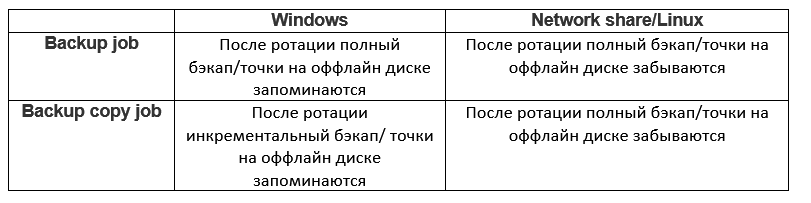
Pertimbangkan setiap opsi.
Pekerjaan biasa dan repositori Windows
Jadi, kami memiliki tugas yang menyimpan rantai ke disk pertama. Selama rotasi, rantai yang dibuat benar-benar menghilang, dan tugas harus bertahan dari kerugian ini. Ia menemukan penghiburan dalam membuat cadangan penuh. Jadi, setiap rotasi berarti cadangan penuh. Tapi apa yang terjadi pada titik-titik pada disk yang terputus? Mereka diingat dan diperhitungkan saat menghitung retensi. Jadi, jumlah titik yang ditetapkan dalam tugas adalah berapa banyak titik yang harus disimpan di semua disk. Berikut ini contohnya:
Pekerjaan sedang berjalan dalam mode inkremental tak terbatas dan dikonfigurasi untuk menyimpan 3 titik pemulihan. Tetapi kami juga memiliki disk kedua, dan kami memutar seminggu sekali (mungkin ada lebih banyak disk, ini tidak mengubah intinya).
Di minggu pertama, tugas akan membuat poin pada disk pertama dan menggabungkan yang ekstra. Jadi, jumlah total poin akan menjadi tiga:

Kemudian kami menghubungkan disk kedua. Saat memulai, B&R akan melihat bahwa disk telah berubah. Rantai pada disk pertama akan hilang dari antarmuka, tetapi informasi tentangnya akan tetap ada di database. Sekarang tugas akan menyimpan 3 poin pada disk kedua. Situasi umumnya adalah sebagai berikut:

Terakhir, kami menghubungkan kembali drive pertama. Sebelum membuat titik baru, tugas akan memeriksa apa yang ada dengan retensi. Dan retensi, saya ingatkan, disetel untuk menyimpan 3 poin. Sementara itu, kami memiliki 3 titik pada disk 2 (tetapi dinonaktifkan dan disimpan di tempat yang aman di mana B&R tidak dapat dijangkau) dan 3 titik pada disk 1 (dan yang ini terhubung). Ini berarti Anda dapat dengan aman menghapus 3 poin dari disk 1, karena melebihi retensi. Setelah itu, tugas kembali membuat cadangan penuh, dan rantai kami mulai terlihat seperti ini:

Jika retensi dikonfigurasi untuk menyimpan hari, bukan jumlah poin, maka logikanya tidak berubah. Selain itu, retensi GFS sama sekali tidak didukung saat menggunakan repositori yang dirotasi.
Pekerjaan Reguler dan Linux Repository \ Network Storage
Opsi ini juga memungkinkan, tetapi umumnya kurang disarankan karena pembatasan yang diberlakukan. Tugas tersebut akan bereaksi terhadap rotasi disk dan hilangnya rantai dengan cara yang sama - dengan membuat cadangan lengkap. Batasannya adalah karena mekanisme retensi yang dipangkas.
Di sini, selama rotasi, seluruh rantai pada disk yang terputus hanya dihapus dari database B&R. Harap dicatat - dari database, file itu sendiri tetap ada di disk. Mereka dapat diimpor dan digunakan untuk pemulihan, tetapi tidak sulit untuk menebak bahwa cepat atau lambat rantai yang terlupakan akan memenuhi seluruh repositori.
Solusinya adalah menambahkan DWORD ForceDeleteBackupFiles seperti yang ditunjukkan di halaman ini: www.veeam.com/kb1154... Pekerjaan kemudian akan mulai menghapus semua konten folder pekerjaan atau folder repositori (tergantung pada nilainya) pada setiap rotasi.
Namun, ini bukanlah retensi elegan, tetapi pembersihan semua konten. Sayangnya, dukungan teknis mengalami kasus ketika hanya direktori root dari disk yang ditetapkan sebagai repositori, di mana, selain cadangan, terdapat data lain. Semua ini dihancurkan selama rotasi.
Selain itu, saat Anda mengaktifkan ForceDeleteBackupFiles, ini berfungsi untuk semua jenis repositori, bahkan repositori di Windows akan berhenti menerapkan retensi dan mulai menghapus konten. Dengan kata lain, disk lokal di Windows adalah pilihan terbaik untuk sistem penyimpanan cadangan tersebut.
Salinan cadangan dan repositori Windows
Segalanya menjadi lebih menarik dengan BCJ. Tidak hanya ada retensi penuh, tetapi tidak perlu membuat cadangan penuh dengan setiap perubahan disk! Cara kerjanya seperti ini:
B&R Pertama mulai membuat poin pada disk pertama. Katakanlah kita menetapkan retensi pada 3 poin. Tugas akan bekerja dalam mode inkremental tak terbatas dan menggabungkan semua yang tidak perlu (ingat, retensi GFS tidak didukung dalam kasus ini).

Kemudian kami menghubungkan drive kedua. Karena belum ada rantai di atasnya, kami membuat cadangan penuh, setelah itu kami memiliki rantai kedua yang terdiri dari tiga titik:

Akhirnya, saatnya menyambungkan kembali disk pertama. Dan di sinilah keajaiban dimulai, karena pekerjaan tidak akan membuat cadangan penuh, tetapi hanya akan melanjutkan rantai inkremental:

Setelah itu, hampir setiap disk akan memiliki rantai independennya sendiri. Oleh karena itu, retensi di sini tidak berarti jumlah titik pada semua disk, tetapi jumlah titik pada setiap disk secara terpisah.
Salinan cadangan dan penyimpanan jaringan \ repositori Linux
Sekali lagi, semua keanggunan hilang jika repositori tidak ada di drive Windows lokal. Skrip ini berfungsi mirip dengan yang dibahas di atas dengan tugas sederhana. Dengan setiap rotasi, BCJ akan membuat cadangan penuh, dan poin yang ada akan dilupakan. Agar tidak dibiarkan tanpa ruang kosong, Anda perlu menggunakan DWORD ForceDeleteBackupFiles.
Kesimpulan
Jadi, sebagai hasil dari teks yang begitu panjang, kami mempertimbangkan dua jenis tugas. Tentu saja, ada lebih banyak tugas, tetapi tidak mungkin untuk mempertimbangkan semuanya dalam format satu artikel. Jika, setelah membaca, Anda masih memiliki pertanyaan, kemudian tulis di komentar, saya akan dengan senang hati menjawabnya secara pribadi.