
ASIC khusus untuk area tertentu adalah salah satu cara untuk "memulai kembali" Hukum Moore dan mengatasi batasan CPU tujuan umum. Sekarang ini merupakan bidang yang sangat menjanjikan untuk pengembangan mikroelektronika. Google, Amazon, dan perusahaan lain memiliki proyek mereka sendiri. Misalnya, Google membuat Google TPU Tensor Processors , dan pusat data Amazon menjalankan chip AWS Graviton pada inti ARM.
Yang pertama adalah ASIC untuk jaringan neural, dan yang terakhir adalah ARM 64-bit untuk tujuan umum untuk mengoptimalkan rasio harga-performa dalam beban kerja intensif komputasi.
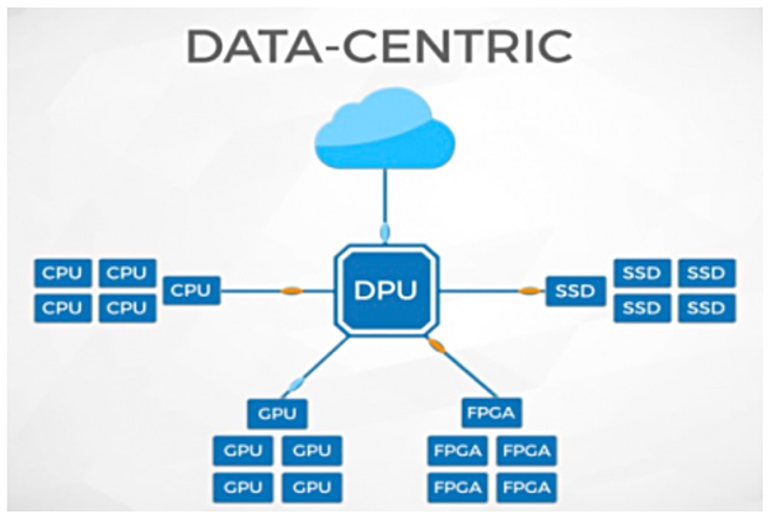
Kelas lain dari ASIC tujuan umum, di mana eksperimen aktif telah berlangsung baru-baru ini, adalah koprosesor khusus untuk pemrosesan data (unit pemrosesan data, DPU), semacam kartu jaringan pintar (SmartNIC). Beberapa contoh spesies ini adalah Nvidia BlueField 2, Fungible dan Pensando DSC-25.
Apa yang mereka suka? Untuk tugas apa mereka cocok? Mari kita lihat.

Apa itu SmartNIC
Kartu jaringan konvensional (NIC) dibangun di sirkuit terintegrasi tujuan khusus (ASIC), yang dirancang untuk beroperasi sebagai pengontrol Ethernet. Seringkali sirkuit mikro ini dirancang untuk melakukan fungsi sekunder. Misalnya, pengontrol Mellanox ConnectX juga mendukung protokol Infiniband berkecepatan tinggi. Ini adalah chip khusus yang hebat, tetapi fungsinya tidak dapat diubah.
Tidak seperti kartu jaringan sederhana, SmartNIC memungkinkan pengguna untuk mengunduh perangkat lunak tambahan ke pengontrol, yaitu, setelah membeli perangkat keras. Ini memperluas atau mengubah fungsionalitas ASIC. Prosedurnya agak mirip dengan membeli smartphone dan menginstal berbagai aplikasi di dalamnya.
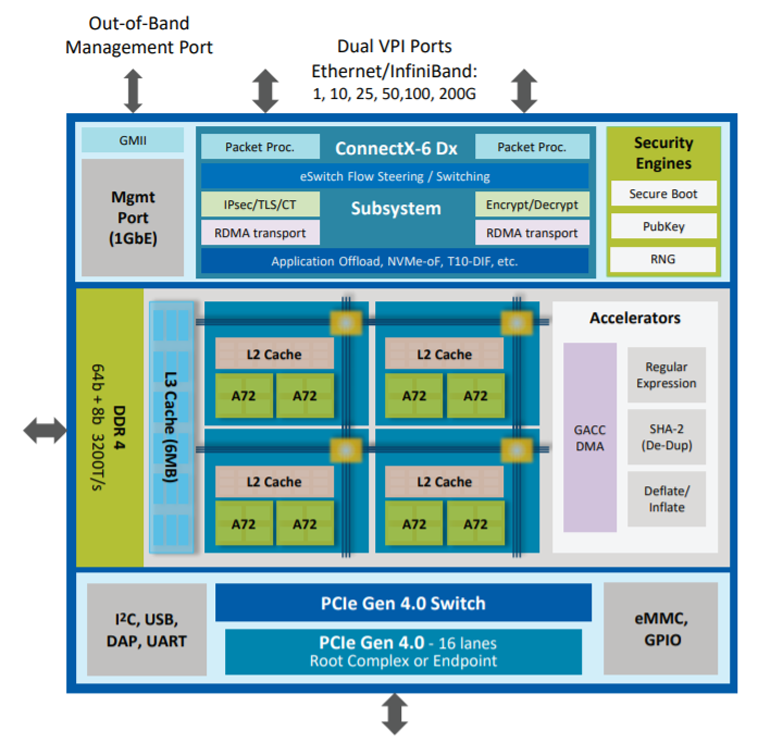
Untuk membuat ini mungkin, SmartNIC membutuhkan lebih banyak daya pemrosesan dan memori tambahan daripada NIC konvensional. Kita berbicara tentang prosesor ARM multi-core yang lebih kuat, pemasangan prosesor jaringan khusus (core pemrosesan aliran, FPC) dan array gerbang yang dapat diprogram lapangan (FPGA).
Xilinx Alveo U25
Schematic SmartNICs sering memiliki inti ARM terpisah untuk bidang kontrol, beberapa papan memungkinkan memuat kernel Linux yang dimodifikasi. Inti ARM khusus ini mendistribusikan beban ke seluruh modul komputasi lainnya, mengumpulkan statistik dan log, serta memantau status SmartNIC. Lalu lintas jaringan langsung tidak melewatinya.
Tugas apa yang cocok untuk DPU?
Koprosesor data (DPU) adalah ekstensi umum SmartNIC yang menambahkan fungsionalitas NVMe atau NVMe over Fabrics (NVMe-oF). Papan semacam itu memungkinkan Anda untuk membongkar prosesor pusat, mengambil alih semua tugas I / O.
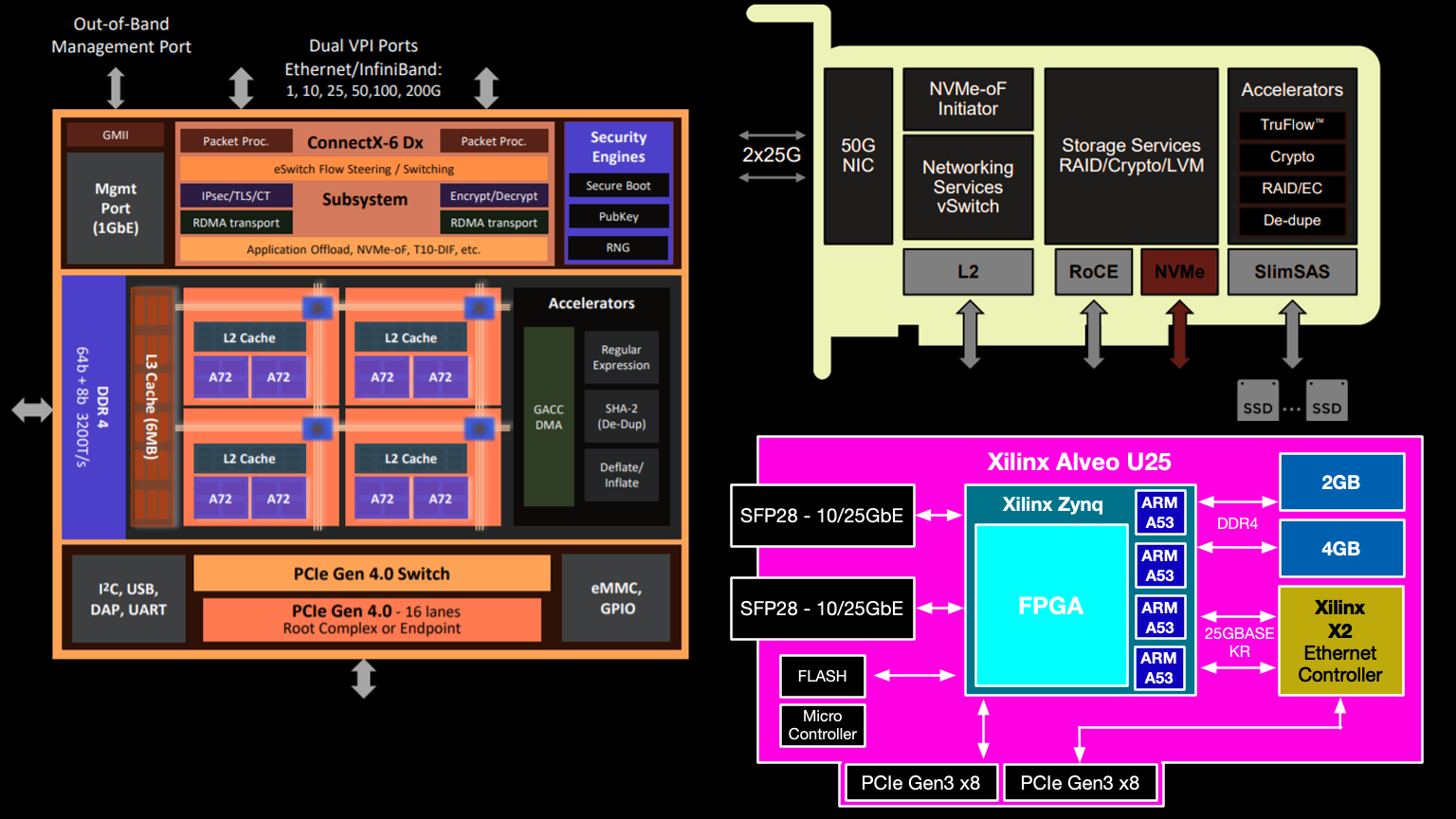
Misalnya, pertimbangkan perangkat SmartNIC dari mikrokontroler Broadcom NetXtreme-S BCM58800 . Ia bekerja sebagai kartu jaringan yang dapat diprogram dan mendukung (NVMe-oF).
Arsitektur kartu Broadcom Stingray berbasis mikrokontroler BCM58800
Broadcom Stingray memiliki delapan core ARM v8 A72 pada 3 GHz, bisa dibilang kecepatan clock tertinggi dari semua ARM di SmartNIC mana pun. Kartu jaringan dilengkapi dengan memori DDR4 hingga 16GB. Enkripsi hingga 90 Gbps didukung pada tingkat perangkat keras dan beberapa fungsi pemrosesan data didukung: deduplikasi, yang menghapus pengkodean dari RAID 5 dan RAID 6.
Diagram juga menunjukkan akselerator TruFlow. Ini adalah teknologi milik Broadcom untuk akselerasi perangkat keras operasi jaringan, termasuk Open vSwitch (OvS) dan banyak lagi.
Nvidia BlueField 2
Nvidia secara tradisional berspesialisasi dalam akselerator grafis, tetapi tahun ini menyelesaikan akuisisi $ 7 miliar dari pembuat chip khusus Mellanox, jadi sekarang secara serius menargetkan bidang baru - pasar HPC di pusat data.
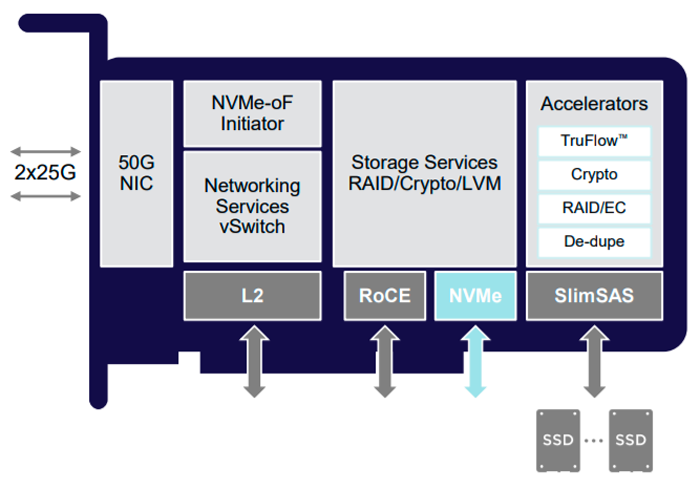
Mellanox adalah salah satu pelopor dalam pengembangan kartu jaringan pintar, dan papan BlueField 2 , yang dipasarkan sebagai Data Processing Unit (DPU), sekarang dianggap sebagai produk terkemuka . Aplikasi DPU Kunci
Arsitektur Nvidia / Mellanox BlueField 2
:
- Awan virtual dan perangkat keras.
- Penyimpanan NVMe di mesin virtual.
- Aplikasi Network Function Virtualization (NFV).
- Aplikasi keamanan informasi seperti Deep Packet Inspection (DPI).
- Microserver untuk komputasi tepi

Nvidia / Mellanox BlueField 2
Ini memiliki fitur array delapan inti ARM v8 A72, pengontrol memori DDR4, dan Ethernet port ganda atau adaptor jaringan InfiniBand (dua pada 100 Gbps atau satu pada 200 Gbps), ditambah ASIC khusus untuk mempercepat berbagai fungsi: ekspresi reguler, hashing SHA-2, dll.
Pensando
Salah satu startup baru di bidang SmartNIC adalah Pensando, yang menawarkan apa yang disebut Kartu Layanan Terdistribusi di pasar, Pensando DSC-25 (untuk server perusahaan) dan Pensando DSC-100 (untuk penyedia cloud).

Pensando DSC-25 dan Pensando DSC-100
Produk utamanya adalah Pensando DSC-25. Ini adalah kartu dengan satu P4 (Capri) DPU untuk pemrosesan data, inti ARM tambahan, dan akselerator perangkat keras untuk fungsi yang dipilih.

Sirkuit Pensando DSC-25
Core DPU dan ARM utama dihubungkan melalui bus interkoneksi bersama ke pengontrol PCIe dan array RAM (hingga 4 GB).
Akselerator perangkat keras individu disebut di sini sebagai Service Processing Offloads. Seperti halnya kartu Mellanox, mereka menangani enkripsi, pemrosesan disk, dan tugas lainnya.
Fungible
Arsitektur tingkat tinggi Fungible
Startup lain yang sedang naik daun , Fungible, mengklaim bahwa dialah yang menemukan istilah DPU pada tahun 2016. Perusahaan mengumumkan prosesor yang disebut F1 DPU, tetapi arsitektur sebenarnya dari chip ini tidak diketahui. Fungible hanya dapat mendemonstrasikan skema umum untuk saat ini, seperti pada ilustrasi di atas. Beberapa ahli telah menyatakan kecurigaan mereka bahwa Fungible hanya menggunakan istilah hype DPU untuk menarik investasi modal ventura. Omong-omong, $ 500 juta telah diinvestasikan di dalamnya di berbagai putaran.
Apa berikutnya?
Ada banyak hype seputar konsep DPU belakangan ini. Tidak semua perusahaan yang mencoba memasuki pasar ini (Intel, Xilinx, dan lainnya) disebutkan dalam ulasan ini.
Faktanya, konsep SmartNIC telah ada sejak lama, dan perusahaan besar seperti Google dan Amazon telah mengembangkan dan menerapkan solusi internal mereka sendiri. Pada saat yang sama, pasar terbentuk, yang diisi oleh pemain pihak ketiga.
Generasi kedua SmartNIC berbasis FPGA sekarang muncul. Teknologi array gerbang yang dapat diprogram pengguna telah matang hingga sekarang dapat menjadi teknologi dasar untuk SmartNIC. Satu dekade yang lalu, pasar benar-benar dibanjiri oleh akselerator grafis - ini adalah gelombang signifikan pertama dalam teknologi akselerasi perangkat keras. Sekarang FPGA telah melampaui tiga juta tanda blok logis, chip ini terintegrasi erat dengan blok bangunan lain untuk menangani lalu lintas jaringan, memori, penyimpanan, dan inti komputasi. Teknologi SmartNIC dan FPGA saling melengkapi dengan sempurna.
Dengan latar belakang ini, kita dapat mengharapkan akselerator perangkat keras gelombang kedua. Dan kemudian elemen ketiga, DPU, akan ditambahkan ke set CPU + GPU. Koprosesor data akan membebaskan prosesor server dari tugas infrastruktur. Penelitian menunjukkan bahwa dalam lingkungan yang sangat tervirtualisasi, proses jaringan seperti transaksi OvS dapat menghabiskan lebih dari 30% waktu CPU di host. Bayangkan operasi disk, enkripsi, DPI, dan perutean kompleks dilakukan dalam modul terpisah. Ini berpotensi menghapus sebagian besar beban CPU.
Startup seperti Pensando dan Fungible telah menghadapi para pemimpin teknologi seperti Xilinx, Intel, Broadcom, dan Nvidia dengan inovasi mereka. Inilah kompetisi teknologi yang selalu asyik ditonton.