Google: Google: 90% teknisi kami menggunakan program yang Anda tulis (Homebrew), tetapi Anda tidak bisa membalikkan pohon biner di papan, jadi selamat tinggal.
Meskipun saya tidak pernah membutuhkan inversi pohon biner, saya menemukan contoh penggunaan nyata dari struktur data dan algoritme dalam pekerjaan saya sehari-hari ketika saya bekerja di Skype / Microsoft, Skyscanner, dan Uber . Ini termasuk pengkodean dan pengambilan keputusan berdasarkan spesifikasi struktur data dan algoritma. Tetapi saya, untuk sebagian besar, menggunakan pengetahuan yang relevan untuk memahami bagaimana sistem tertentu diciptakan, dan mengapa sistem itu dibuat seperti itu. Pengetahuan tentang konsep yang relevan membuatnya lebih mudah untuk memahami arsitektur dan implementasi sistem di mana konsep ini digunakan.

Dalam artikel ini, saya telah memasukkan cerita tentang situasi di mana struktur data seperti pohon dan grafik, serta berbagai algoritme, telah digunakan dalam proyek nyata. Di sini saya berharap dapat menunjukkan kepada pembaca bahwa pengetahuan dasar tentang struktur data dan algoritme bukanlah teori yang tidak berguna yang hanya diperlukan untuk wawancara, tetapi sesuatu yang sangat mungkin benar-benar dibutuhkan oleh seseorang yang bekerja di perusahaan teknologi inovatif yang berkembang pesat.
Di sini kita akan berbicara tentang sejumlah kecil algoritma, tetapi sejauh menyangkut struktur data, saya dapat mencatat bahwa saya akan menyentuh hampir semuanya di sini. Tidak mengherankan bagi siapa pun bahwa saya bukan penggemar pertanyaan wawancara yang terlalu menekankan algoritme, tidak berhubungan dengan praktik, dan menargetkan struktur data eksotis seperti pohon merah-hitam atau pohon AVL. Saya tidak pernah menanyakan pertanyaan seperti itu dalam wawancara dan tidak akan menanyakannya. Di akhir artikel ini, saya akan membagikan pemikiran saya tentang wawancara semacam itu. Namun terlepas dari hal di atas, pengetahuan tentang struktur data yang mendasarinya memiliki nilai yang sangat besar. Pengetahuan ini memungkinkan Anda untuk memilih dengan tepat apa yang diperlukan untuk menyelesaikan masalah praktis tertentu.
Sekarang mari beralih ke contoh penggunaan struktur data dan algoritme dalam kehidupan nyata.
Trees and tree traversal: Skype, Uber, dan framework UI
Saat kami mengembangkan Skype untuk Xbox One, kode tersebut harus ditulis untuk OS Xbox murni yang tidak memiliki perpustakaan yang kami butuhkan. Kami mengembangkan salah satu aplikasi full-blown pertama untuk platform ini. Kami membutuhkan sistem navigasi aplikasi yang dapat dioperasikan menggunakan layar sentuh dan memberikan perintah suara ke aplikasi tersebut.
Kami telah membuat kerangka kerja navigasi berbasis WinJS dasar. Untuk melakukan ini, kami perlu mempertahankan grafik seperti DOM, yang diperlukan untuk mengatur pengamatan elemen yang dapat berinteraksi dengan pengguna. Untuk menemukan elemen seperti itu, kami melakukan DOM traversal, yang diringkas menjadi traversal pohon, yaitu struktur elemen DOM yang ada. Ini adalah contoh klasik BFS atau DFS (pencarian luas-pertama atau pencarian kedalaman-pertama - pencarian luas-pertama atau pencarian kedalaman-pertama).
Jika Anda melakukan pengembangan web, artinya Anda sudah bekerja dengan struktur pohon, yaitu DOM. Semua simpul DOM dapat memiliki simpul anak. Browser menampilkan node di layar setelah melintasi pohon DOM. Jika Anda perlu menemukan elemen tertentu, Anda dapat menggunakan metode DOM bawaan untuk mengatasi masalah ini. Misalnya, metode getElementById. Alternatifnya adalah mengembangkan solusi BFS atau DFS Anda sendiri untuk melintasi node dan menemukan apa yang Anda butuhkan. Misalnya, hal serupa dilakukan di sini .
Banyak kerangka kerja yang merender elemen UI menggunakan struktur pohon di kedalamannya. Jadi, React mendukung DOM virtual dan menggunakan algoritma rekonsiliasi cerdas(perbandingan). Ini memungkinkan Anda mencapai kinerja tinggi karena fakta bahwa hanya bagian antarmuka yang diubah yang dirender ulang. Sebuah visualisasi dari proses ini dapat ditemukan di sini.
Dalam arsitektur seluler Uber, RIB, pohon juga digunakan. Ini membuat arsitektur ini mirip dengan kebanyakan framework UI lainnya yang menampilkan struktur hierarki elemen. Arsitektur RIB mempertahankan pohon RIB untuk tujuan manajemen negara. Memasang RIB ke dan melepaskannya dari itu mengontrol renderingnya. Saat bekerja dengan RIB, kami terkadang membuat sketsa, mencoba memahami apakah RIB sesuai dengan hierarki yang ada, dan mendiskusikan apakah RIB yang dimaksud harus memiliki elemen yang terlihat. Artinya, mereka berbicara tentang apakah struktur ini akan mengambil bagian dalam pembentukan presentasi visual dari antarmuka, atau hanya akan digunakan untuk manajemen negara.

Status transisi saat menggunakan RIB. Anda dapat menemukan detail selengkapnya tentang RIB di sini.
Jika Anda perlu merender elemen hierarki, perhatikan bahwa struktur pohon biasanya digunakan untuk ini, melintasi dan merender elemen yang dikunjungi. Saya telah menemukan banyak alat internal yang menggunakan pendekatan ini. Contoh alat tersebut adalah perender RIB yang dibuat oleh tim Platform Seluler di Uber. Berikut adalah laporan tentang topik ini.
Grafik berbobot dan pencari jalur terpendek: Skyscanner
Skyscanner adalah proyek yang bertujuan untuk menemukan penawaran terbaik untuk tiket pesawat. Pencarian proposal tersebut dilakukan dengan melihat dan menganalisis semua rute yang ada di dunia dan menggabungkannya. Inti dari tugas ini lebih terkait dengan pengumpulan data otomatis oleh robot pencari, dan bukan untuk menyimpan semua data ini, karena maskapai penerbangan secara mandiri menghitung waktu tunggu untuk penerbangan berikutnya. Tetapi kemungkinan merencanakan perjalanan untuk mengunjungi beberapa kota bergantung pada tugas menemukan jalur terpendek.
Perencanaan perjalanan multi-kota adalah salah satu kemungkinan yang membutuhkan waktu lama untuk diterapkan oleh Skyscanner. Pada saat yang sama, kesulitan terutama terkait dengan sistem yang dikembangkan itu sendiri. Penawaran terbaik semacam ini ditemukan dengan menggunakan algoritma jalur terpendek seperti Dijkstra atau A *. Rute penerbangan disajikan dalam bentuk grafik berarah. Masing-masing tepinya diberi bobot dalam bentuk harga tiket. Saat mencari rute terbaik, pencarian rute termurah antara dua kota dilakukan menggunakan implementasi algoritma A * yang dimodifikasi . Jika Anda tertarik dengan topik memilih tiket dan menemukan rute terpendek, maka berikut adalah artikel bagus tentang penggunaan BFS untuk menyelesaikan masalah tersebut.
Namun, dalam kasus Skyscanner, algoritme mana yang digunakan untuk menyelesaikan masalah tidak terlalu penting. Caching, menggunakan robot pencari, mengatur pekerjaan dengan berbagai situs - semua ini jauh lebih sulit daripada memilih algoritma. Tetapi pada saat yang sama, varian yang berbeda dari masalah menemukan jalur terpendek muncul di banyak perusahaan perencanaan perjalanan yang berbeda dan mengoptimalkan biaya perjalanan tersebut. Tidak mengherankan, topik ini juga menjadi topik pembicaraan di balik layar di Skyscanner.
Urutkan: Skype (atau semacamnya)
Saya jarang memiliki alasan untuk menerapkan algoritme pengurutan sendiri atau untuk mempelajari seluk-beluk strukturnya secara mendalam. Meskipun demikian, sangat menarik untuk memahami bagaimana algoritma tersebut bekerja - dari bubble sort, insertion sort, merge sort dan selection sort, hingga algoritma yang paling kompleks - quicksort. Saya telah menemukan bahwa jarang ada kebutuhan untuk mengimplementasikan algoritma seperti itu, terutama jika Anda tidak perlu menulis fungsi sortir yang merupakan bagian dari pustaka.
Di Skype, bagaimanapun, saya harus menggunakan pengetahuan saya tentang algoritma pengurutan. Salah satu programmer kami memutuskan untuk menerapkan pengurutan dengan sisipan untuk menampilkan kontak. Pada 2013, saat Skype online, kontak diunduh secara berkelompok. Butuh beberapa saat untuk mengunduh semuanya. Alhasil, programmer tersebut berpikir bahwa akan lebih baik jika membuat daftar kontak yang diurutkan berdasarkan nama menggunakan insertion sort. Kami banyak membahas algoritme ini, memikirkan mengapa tidak menggunakan saja sesuatu yang sudah diterapkan. Akibatnya, kami membutuhkan waktu paling lama untuk menguji implementasi algoritme kami dengan benar dan memeriksa kinerjanya. Secara pribadi, saya tidak melihat banyak gunanya membuat implementasi saya sendiri dari algoritma ini. Tapi kemudian proyek itu berada pada tahap seperti itudi mana kami punya waktu untuk hal-hal seperti itu.
Tentu saja, ada situasi dunia nyata di mana penyortiran yang efisien memainkan peran yang sangat penting dalam sebuah proyek. Dan jika pengembang dapat secara mandiri, berdasarkan fitur data, memilih algoritme yang paling sesuai, ini dapat memberikan peningkatan yang nyata dalam kinerja solusi. Jenis penyisipan bisa sangat berguna jika Anda bekerja dengan kumpulan data besar yang dikirimkan ke suatu tempat secara real time, dan segera memvisualisasikan data ini. Merge Sort dapat bekerja dengan baik untuk membagi dan menaklukkan pendekatan saat menangani sejumlah besar data yang disimpan di node yang berbeda. Saya tidak pernah bekerja dengan sistem seperti itu, jadi untuk saat ini saya terus mempertimbangkan algoritma pengurutan sebagai sesuatu yang penggunaannya terbatas dalam pekerjaan sehari-hari. Itu benar,ini bukan tentang pentingnya memahami bagaimana algoritma pengurutan yang berbeda bekerja.
Tabel hashing dan hashing: di mana-mana
Struktur data yang saya gunakan secara teratur adalah tabel hash. Ini juga termasuk fungsi hash. Ini adalah alat yang sangat berguna yang dapat digunakan untuk menyelesaikan berbagai tugas - mulai dari menghitung jumlah entitas tertentu, mendeteksi duplikat, menyimpan cache, hingga skenario seperti sharding yang digunakan dalam sistem terdistribusi . Tabel hash, setelah array, adalah struktur data yang paling umum dalam pemrograman. Saya telah menggunakannya dalam situasi yang tak terhitung jumlahnya. Ini ada di hampir semua bahasa pemrograman, dan jika perlu, mudah untuk diterapkan sendiri.
Tumpukan dan antrian: dari waktu ke waktu
Tumpukan adalah struktur data yang dikenal oleh siapa saja yang memiliki kode debug yang ditulis dalam bahasa yang mendukung pelacakan tumpukan. Jika kita berbicara tentang tumpukan sebagai struktur data, maka, dalam proses kerja, saya mengalami beberapa masalah untuk solusinya yang diperlukan. Tetapi perlu dicatat bahwa saya harus mengetahui tumpukan dengan benar saat men-debug dan membuat profil kinerja kode. Tumpukan juga merupakan pilihan alami untuk struktur data yang akan digunakan saat melakukan DFS.
Saya jarang harus menggunakan antrean, tetapi saya cukup sering menemukannya di basis kode berbagai project. Katakanlah ada sesuatu yang ditempatkan dalam antrian dan ada sesuatu yang diambil darinya. Biasanya, antrean digunakan untuk mengimplementasikan penjelajahan pohon luas pertama, dan antrean tersebut ideal untuk tugas ini. Antrian juga dapat digunakan dalam banyak situasi lain. Suatu hari saya menemukan beberapa kode penjadwalan pekerjaan di mana saya menemukan contoh penggunaan yang layak dari antrian prioritas yang diterapkan oleh modul Python heapq , ketika pekerjaan terpendek dieksekusi terlebih dahulu.
Algoritma Kriptografi: Uber
Data penting yang dimasukkan pengguna ke aplikasi seluler atau web harus dienkripsi sebelum dikirim melalui jaringan. Dan mereka mendekripsi mereka hanya di tempat yang dibutuhkan. Untuk mengatur skema kerja seperti itu, implementasi algoritma kriptografi harus ada di bagian klien dan server aplikasi.
Memahami algoritma kriptografi sangat menarik. Pada saat yang sama, Anda tidak boleh menawarkan algoritme Anda sendiri untuk memecahkan masalah tertentu. Ini adalah salah satu ide terburuk yang terpikirkan oleh seorang programmer. Sebaliknya, ini mengambil standar yang ada dan terdokumentasi dengan baik dan menggunakan primitif asli dari kerangka masing-masing. Biasanya, AES bertindak sebagai standar yang dipilih saat mengimplementasikan solusi kriptografi.... Cukup aman untuk menggunakannya untuk mengenkripsi informasi rahasia di Amerika Serikat . Tidak ada serangan yang berfungsi pada protokol. AES-192 dan AES-256 biasanya cukup andal untuk sebagian besar tugas praktis.
Ketika saya datang ke Uber, sistem enkripsi seluler dan sistem enkripsi aplikasi web sudah diterapkan, mereka didasarkan pada mekanisme yang dijelaskan di atas, jadi saya punya alasan untuk mempelajari detail tentang AES (Standar Enkripsi Lanjutan), tentang HMAC (Kode Otentikasi Pesan Hashed) , tentang algoritme RSA dan hal semacam itu. Menarik juga untuk mendapatkan pemahaman tentang bagaimana kekuatan kriptografi dari urutan tindakan yang digunakan dalam enkripsi terbukti. Misalnya, jika kita berbicara tentang enkripsi terotentikasi dengan data terlampir, ternyata menganalisis mode enkripsi-dan-MAC, MAC-lalu-enkripsi, dan enkripsi-kemudian-MAC, adalah mungkin untuk membuktikan kekuatan kriptografi hanya salah satunya , meskipun ini tidak berarti bahwa sisanya tidak aman secara kriptografis.
Anda tidak mungkin perlu menerapkan primitif kriptografi sendiri, kecuali Anda menerapkan kerangka kriptografi yang benar-benar baru. Tetapi Anda mungkin dihadapkan pada kebutuhan untuk membuat keputusan tentang primitif mana yang akan digunakan dan bagaimana menggabungkannya. Anda mungkin juga membutuhkan pengetahuan di bidang algoritma kriptografi untuk memahami mengapa sistem tertentu menggunakan pendekatan tertentu untuk enkripsi data.
Pohon keputusan: Uber
Saat mengerjakan salah satu proyek, kami harus menerapkan logika bisnis yang kompleks dalam aplikasi seluler. Yakni, berdasarkan setengah lusin aturan, salah satu dari beberapa layar harus ditampilkan. Aturan-aturan ini sangat kompleks karena hasil urutan pengujian dan preferensi pengguna harus diperhitungkan.
Programmer yang mulai memecahkan masalah ini pertama kali mencoba mengekspresikan semua aturan ini dalam bentuk pernyataan if-else. Ini menghasilkan kode yang sangat membingungkan. Akibatnya, diputuskan untuk menggunakan pohon keputusan. Dengan bantuannya, mudah untuk melakukan semua pemeriksaan yang diperlukan. Ini relatif mudah diterapkan. Selain itu, jika diperlukan, dapat diubah tanpa banyak masalah. Kami perlu membuat implementasi pohon keputusan kami sendiri, sehingga kondisi diperiksa di tepinya. Ini yang kami butuhkan dari pohon ini. Meskipun kami dapat menghemat waktu yang dihabiskan untuk menerapkan pohon dengan mengambil pendekatan berbeda, tim memutuskan bahwa pohon tertentu akan lebih mudah dipelihara, dan mulai bekerja. Pohon ini terlihat seperti ini:tepi melambangkan hasil pemeriksaan kondisi (ini adalah hasil biner, atau hasil yang diwakili oleh rentang nilai), dan simpul daun dari pohon mendeskripsikan layar yang perlu Anda tuju.
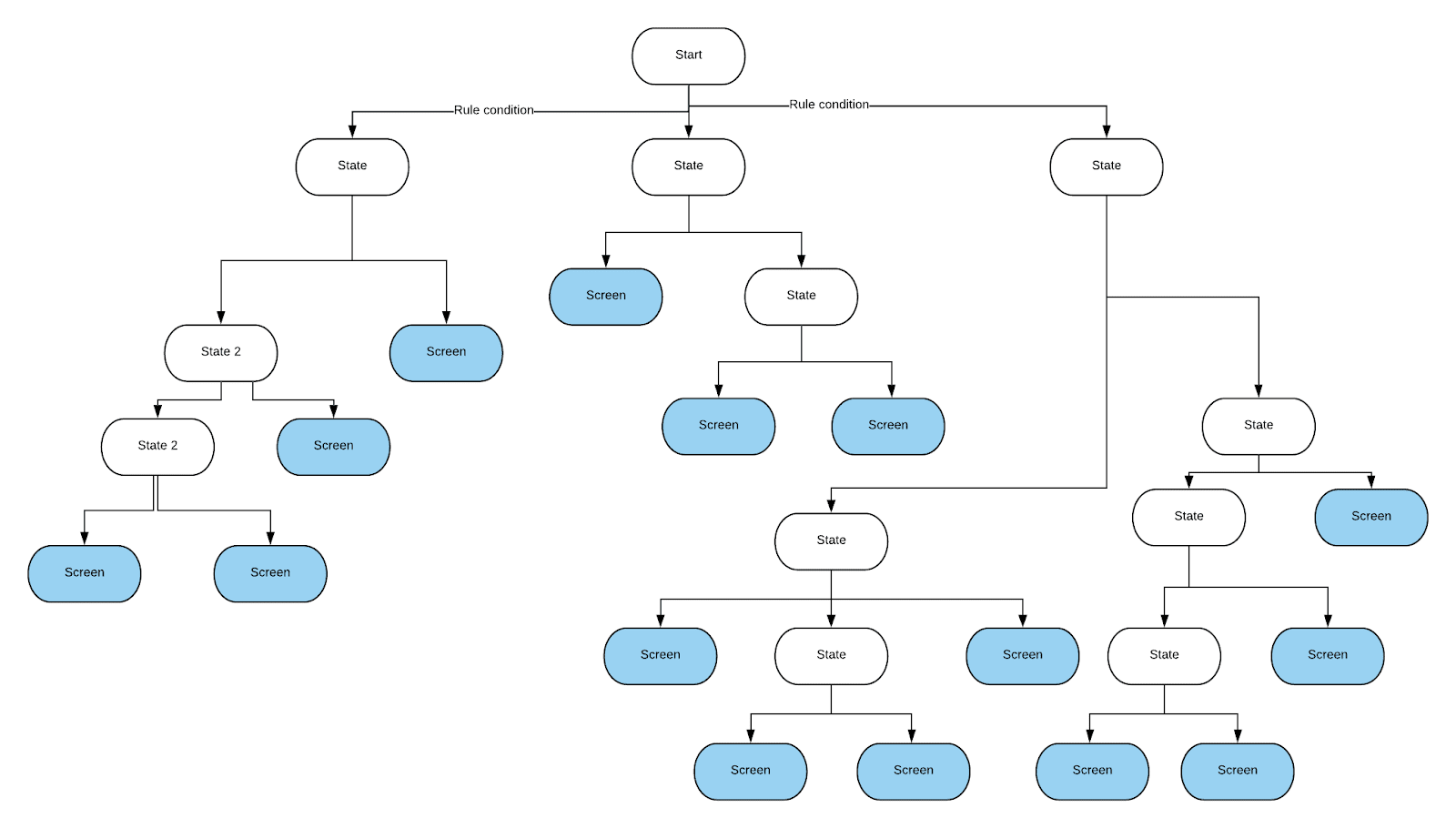
, , .
Sistem build untuk aplikasi seluler Uber, yang disebut SubmitQueue, juga menggunakan pohon keputusan, tetapi dibuat secara dinamis. Tim Pengalaman Pengembang harus mengatasi masalah sulit dalam melakukan penggabungan harian ratusan cabang sumber dengan cabang target. Pada saat yang sama, setiap perakitan membutuhkan waktu sekitar 30 menit untuk menyelesaikannya. Ini termasuk kompilasi, menjalankan unit dan tes integrasi, dan tes antarmuka. Paralelisasi majelis bukanlah solusi yang cukup baik, karena sering terjadi perubahan tumpang tindih di majelis yang berbeda, yang menyebabkan konflik penggabungan. Dalam praktiknya, ini berarti bahwa terkadang programmer harus menunggu 2-3 jam, menggunakan rebase, dan memulai kembali proses penggabungan lagi, dengan harapan kali ini mereka tidak akan menghadapi konflik.
Tim Pengalaman Pengembang mengambil pendekatan inovatif untuk memprediksi gabungan konflik dan susunan antrian yang sesuai. Ini dilakukan dengan menggunakan pohon keputusan biner khusus (pohon spekulasi).

SubmitQueue menggunakan pohon keputusan biner dengan tepi yang dianotasi dengan probabilitas yang diprediksi. Pendekatan ini memungkinkan Anda untuk menentukan kumpulan rakitan mana yang dapat dijalankan secara paralel. Ini dilakukan demi mempersingkat waktu antara menerima dan menjalankan tugas dan demi meningkatkan throughput sistem. Dalam kasus ini, hanya kode yang sepenuhnya teruji dan dapat diterapkan yang harus masuk ke cabang master. Tim
Pengalaman Pengembang, yang membuat sistem ini, menulis materi yang sangat bagustentangnya. Tapi disini- artikel lain dengan topik yang sama, diilustrasikan dengan baik. Hasil dari pengenalan sistem ini adalah terciptanya sistem perakitan proyek yang jauh lebih cepat dari sebelumnya. Ini memungkinkan kami untuk mengoptimalkan waktu pembuatan proyek dan membantu membuat hidup ratusan pemrogram seluler lebih mudah.
Kisi heksagonal, indeks hierarki: Uber
Ini adalah proyek terakhir yang ingin saya bicarakan di sini. Itu sepenuhnya didasarkan pada satu struktur data tertentu. Dengan melakukannya saya belajar tentang struktur data ini. Kita berbicara tentang kisi heksagonal dengan indeks hierarki.
Salah satu masalah yang paling menantang dan menarik di Uber adalah optimalisasi biaya perjalanan dan distribusi pesanan antar mitra. Tarif perjalanan dapat berubah secara dinamis, pengemudi selalu bergerak. Insinyur Uber menciptakan sistem jaringan H3. Ini dirancang untuk memvisualisasikan dan menganalisis data di seluruh kota pada skala yang berbeda. Struktur data yang digunakan untuk menyelesaikan permasalahan diatas adalah grid heksagonal dengan indeks hirarki. Beberapa alat internal khusus digunakan untuk memvisualisasikan data.

Memisahkan peta menjadi sel-sel heksagonal
Struktur data ini memiliki sistem pengindeksan sendiri, traversal, definisi sendiri dari area grid, fungsinya sendiri. Penjelasan mendetail tentang semua ini dapat ditemukan di dokumentasi untuk API yang sesuai. Baca lebih lanjut tentang H3 di sini . Ini kode sumbernya. Di sini Anda dapat menemukan cerita tentang bagaimana dan mengapa sistem ini dibuat.
Pengalaman dengan sistem ini memungkinkan saya untuk merasakan fakta bahwa membuat struktur data khusus Anda sendiri dapat masuk akal saat memecahkan masalah yang sangat spesifik. Ada sangat sedikit masalah dalam solusi di mana kisi heksagonal dapat diterapkan, jika Anda tidak memperhitungkan pembagian ke dalam fragmen peta dengan perbandingan dengan setiap fragmen data yang dihasilkan pada tingkat yang berbeda. Tetapi seperti dalam kasus lain, jika Anda terbiasa dengan struktur data lain, ini akan lebih mudah dipahami. Dan untuk orang yang pernah berurusan dengan grid heksagonal, akan lebih mudah untuk membuat struktur data baru yang dirancang untuk memecahkan masalah yang serupa dengan yang diselesaikan menggunakan grid semacam itu.
Struktur data dan algoritma dalam wawancara
Di atas, saya berbicara tentang struktur data dan algoritme apa yang saya temui saat bekerja di berbagai perusahaan untuk waktu yang lama. Saya mengusulkan sekarang untuk kembali ke tweet oleh Max Howell, yang saya sebutkan di awal artikel. Di sana, Max mengeluh bahwa dalam sebuah wawancara dengan Google dia diminta untuk membalikkan pohon biner di papan. Dia tidak melakukannya. Dia ditunjukkan pintu. Dalam situasi ini, saya berada di pihak Max.
Saya percaya bahwa mengetahui cara kerja algoritme populer, atau cara kerja struktur data eksotis, bukanlah jenis pengetahuan yang Anda butuhkan untuk bekerja di perusahaan teknologi. Anda perlu mengetahui apa itu algoritme, Anda harus dapat membuat algoritme sederhana secara mandiri, misalnya, bekerja dengan prinsip "serakah". Anda juga perlu memiliki pengetahuan tentang struktur data yang paling umum seperti tabel hash, antrian, dan tumpukan. Tetapi sesuatu yang cukup spesifik, seperti algoritma Dijkstra atau A *, atau sesuatu yang lebih kompleks, bukanlah sesuatu yang perlu dipelajari dengan hati. Jika Anda benar-benar membutuhkan algoritme ini, Anda dapat dengan mudah menemukan materi referensi tentangnya. Misalnya, jika kita berbicara tentang algoritma yang tidak terkait dengan algoritma pengurutan, saya biasanya mencoba memahaminya secara umum dan memahami esensinya.Hal yang sama berlaku untuk struktur data eksotis seperti pohon merah-hitam dan pohon AVL. Saya tidak pernah merasa perlu untuk menggunakannya. Dan jika saya membutuhkannya, saya selalu dapat menyegarkan pengetahuan saya tentang mereka dengan menggunakan publikasi yang sesuai. Saat wawancara, seperti yang saya katakan, saya tidak pernah menanyakan pertanyaan seperti itu, dan saya tidak berencana untuk menanyakannya.
Saya mendukung masalah praktis yang berkaitan dengan pemrograman, dalam pemecahannya Anda dapat menerapkan berbagai pendekatan: dari metode varian "brute force" dan "serakah" hingga ide algoritmik yang lebih maju. Misalnya, menurut saya tidak masalah untuk memiliki tugas perataan teks seperti ini . Misalnya, saya harus menyelesaikan masalah ini saat membuat komponen untuk merender teks di Windows Phone. Anda dapat menyelesaikan masalah ini hanya dengan menggunakan array dan beberapa pernyataan if-else, tanpa menggunakan beberapa struktur data yang rumit.
Faktanya, banyak tim dan perusahaan membesar-besarkan pentingnya masalah algoritmik. Saya memahami daya tarik pertanyaan algoritma. Mereka memungkinkan Anda untuk mengevaluasi pelamar dalam waktu singkat, pertanyaan-pertanyaan mudah diulang, artinya jika pertanyaan yang diajukan kepada seseorang diketahui publik, tidak akan menimbulkan masalah khusus. Pertanyaan algoritme bagus untuk mengatur uji coba untuk sejumlah besar pelamar. Misalnya, Anda dapat membuat kumpulan lebih dari seratus pertanyaan dan mendistribusikannya secara acak kepada pelamar. Pertanyaan tentang pemrograman dinamis dan struktur data eksotis menjadi semakin umum. Apalagi di Silicon Valley. Pertanyaan-pertanyaan ini dapat membantu perusahaan mempekerjakan pemrogram yang kuat. Tetapi pertanyaan yang sama ini dapat menutup jalan di perusahaan untuk orang-orang yang telah berhasil dalam bisnis,di mana pengetahuan mendalam tentang algoritme tidak diperlukan.
Jika Anda berasal dari perusahaan yang hanya mempekerjakan orang-orang yang memiliki pengetahuan mendalam tentang algoritme kompleks hampir sejak lahir, saya sarankan agar Anda memikirkan dengan cermat apakah ini orang yang Anda butuhkan. Misalnya, saya mempekerjakan tim hebat di Skyscanner (London) dan Uber (Amsterdam) tanpa mengajukan pertanyaan algoritme yang rumit. Saya telah membatasi diri saya pada struktur data yang paling umum dan untuk menguji kemampuan orang yang diwawancarai terkait dengan pemecahan masalah. Artinya, mereka perlu mengetahui tentang struktur data umum dan dapat menghasilkan algoritme sederhana untuk memecahkan masalah yang mereka hadapi. Struktur dan algoritma data hanyalah alat.
Intinya: struktur data dan algoritme adalah alat
Jika Anda bekerja untuk perusahaan teknologi yang dinamis dan inovatif, maka Anda mungkin akan menemukan implementasi berbagai macam struktur data dan algoritme dalam kode produk perusahaan ini. Jika Anda sedang mengembangkan sesuatu yang benar-benar baru, maka Anda sering kali harus mencari struktur data yang memudahkan untuk menyelesaikan masalah yang Anda hadapi. Dalam situasi seperti ini, Anda memerlukan pengetahuan umum tentang algoritme dan struktur data serta pro dan kontranya untuk membuat pilihan yang tepat.
Struktur data dan algoritme adalah alat yang harus Anda gunakan dengan percaya diri saat menulis program. Jika Anda mengetahui alat-alat ini, Anda akan melihat banyak hal yang sudah Anda ketahui di basis kode yang menggunakannya. Selain itu, pengetahuan semacam itu akan memungkinkan Anda memecahkan masalah yang kompleks dengan lebih percaya diri. Anda akan menyadari batasan teoritis dari algoritma dan bagaimana mereka dapat dioptimalkan. Ini akan membantu Anda pada akhirnya mencapai solusi yang, dengan semua trade-off yang diperlukan, ternyata menjadi sebaik mungkin.
Jika Anda ingin lebih memahami struktur data dan algoritme, berikut adalah beberapa tip dan sumber:
- -, , , , , , . , , . , . — , .
- « ». , , , . — , , . , , , .
- Berikut adalah beberapa buku lagi: “ Algoritma. Panduan Pengembangan "dan" Algoritma di Java, Edisi ke-4 ". Saya menggunakannya untuk menyegarkan pengetahuan universitas saya tentang algoritme. Benar, saya belum membacanya sampai akhir. Bagi saya, mereka tampak agak kering dan tidak dapat diterapkan untuk pekerjaan saya sehari-hari.
Struktur dan algoritme data apa yang Anda temui dalam praktik?
