
Siapa saya
Nama saya Dmitry Ivanov. Saya adalah mahasiswa pascasarjana tahun kedua di bidang ekonomi di St. Petersburg HSE. Saya bekerja dalam kelompok penelitian " Sistem Agen dan Pembelajaran Penguatan " di JetBrains Research , serta di Laboratorium Internasional Teori Permainan dan Pengambilan Keputusan di Sekolah Tinggi Ekonomi . Selain pembelajaran PU, saya tertarik dengan pembelajaran penguatan dan penelitian di persimpangan pembelajaran mesin dan ekonomi.
Pembukaan
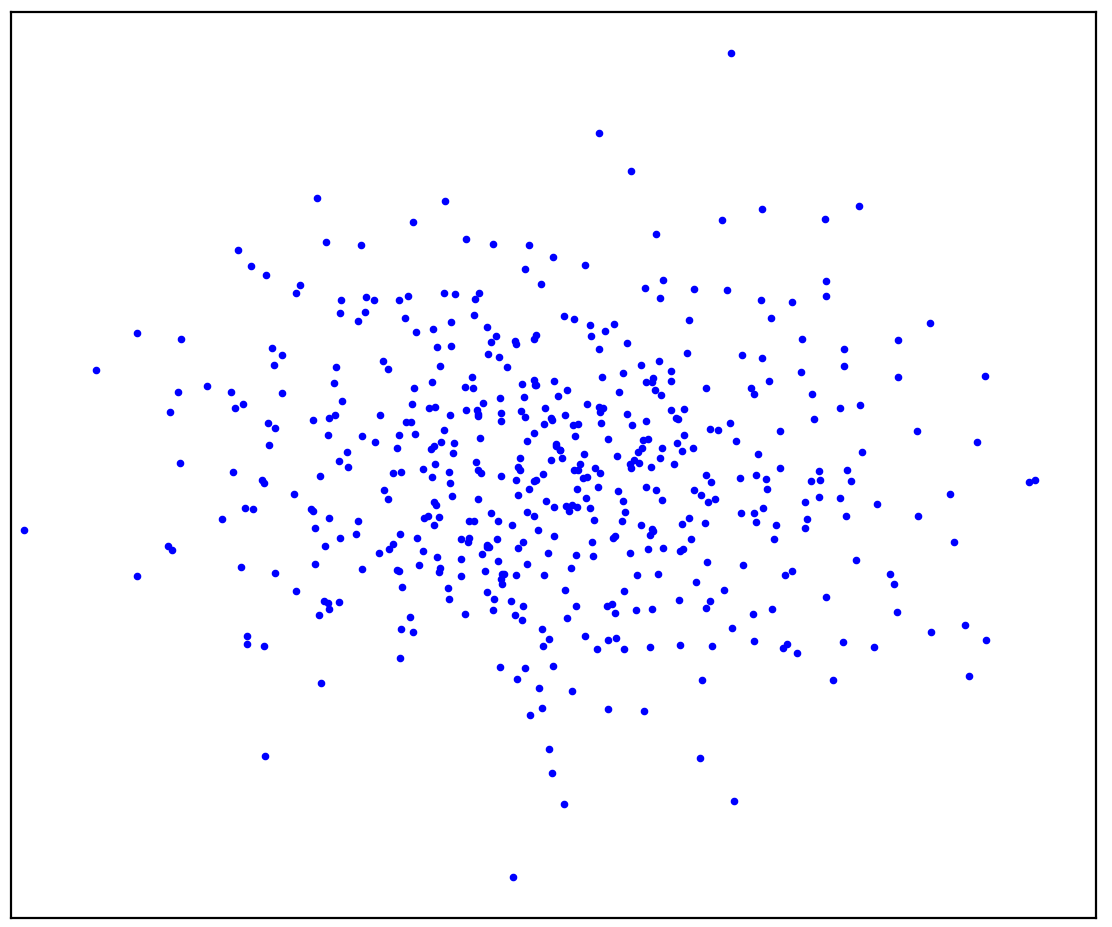
Angka: 1a. Data positif
Gambar 1a menunjukkan sekumpulan titik yang dihasilkan oleh beberapa distribusi, yang akan kita sebut positif. Semua kemungkinan titik lain yang tidak termasuk dalam distribusi positif akan disebut negatif. Cobalah menggambar garis yang memisahkan poin-poin positif yang disajikan dari semua poin negatif yang mungkin secara mental. Omong-omong, tugas ini disebut "deteksi anomali".
Jawabannya ada disini

. 1.
. 1.
Anda mungkin pernah membayangkan sesuatu seperti Gambar 1b: melingkari data dalam bentuk elips. Faktanya, ini adalah cara kerja metode deteksi anomali.
Sekarang mari kita ubah masalahnya sedikit: mari kita memiliki informasi tambahan bahwa garis lurus harus memisahkan titik positif dari yang negatif. Cobalah untuk menariknya ke dalam pikiran Anda.
Jawabannya ada disini
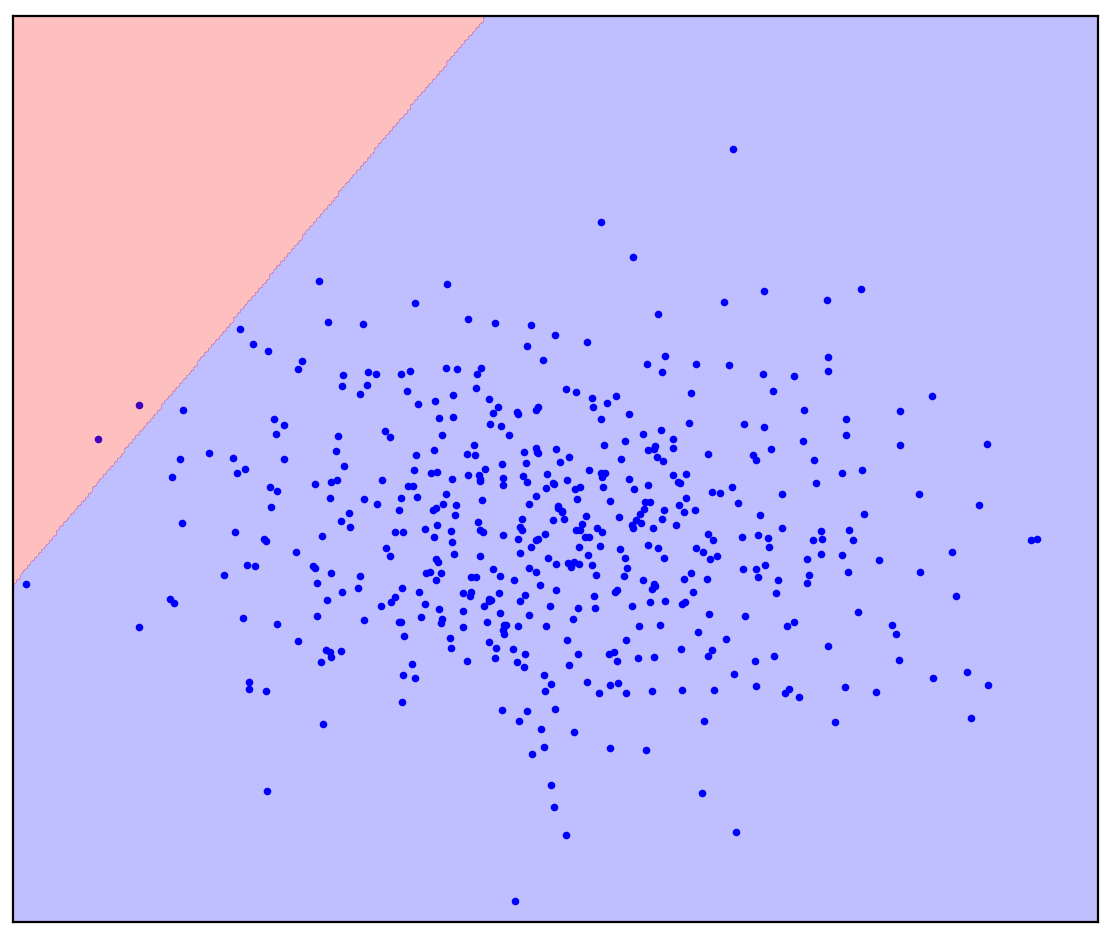
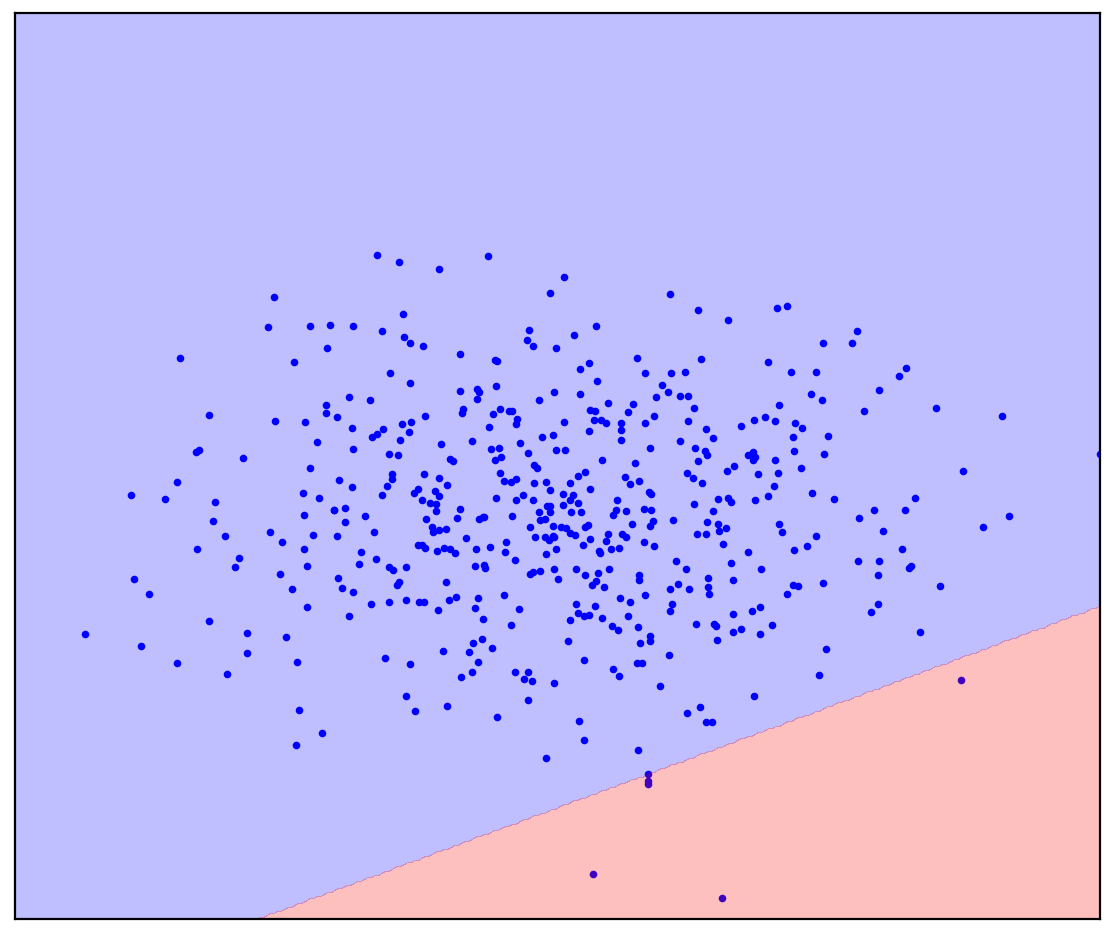
. 1. ( One-Class SVM)
. 1. ( One-Class SVM)
Dalam kasus garis pemisah lurus, tidak ada jawaban tunggal. Tidak jelas ke arah mana harus menggambar garis lurus.
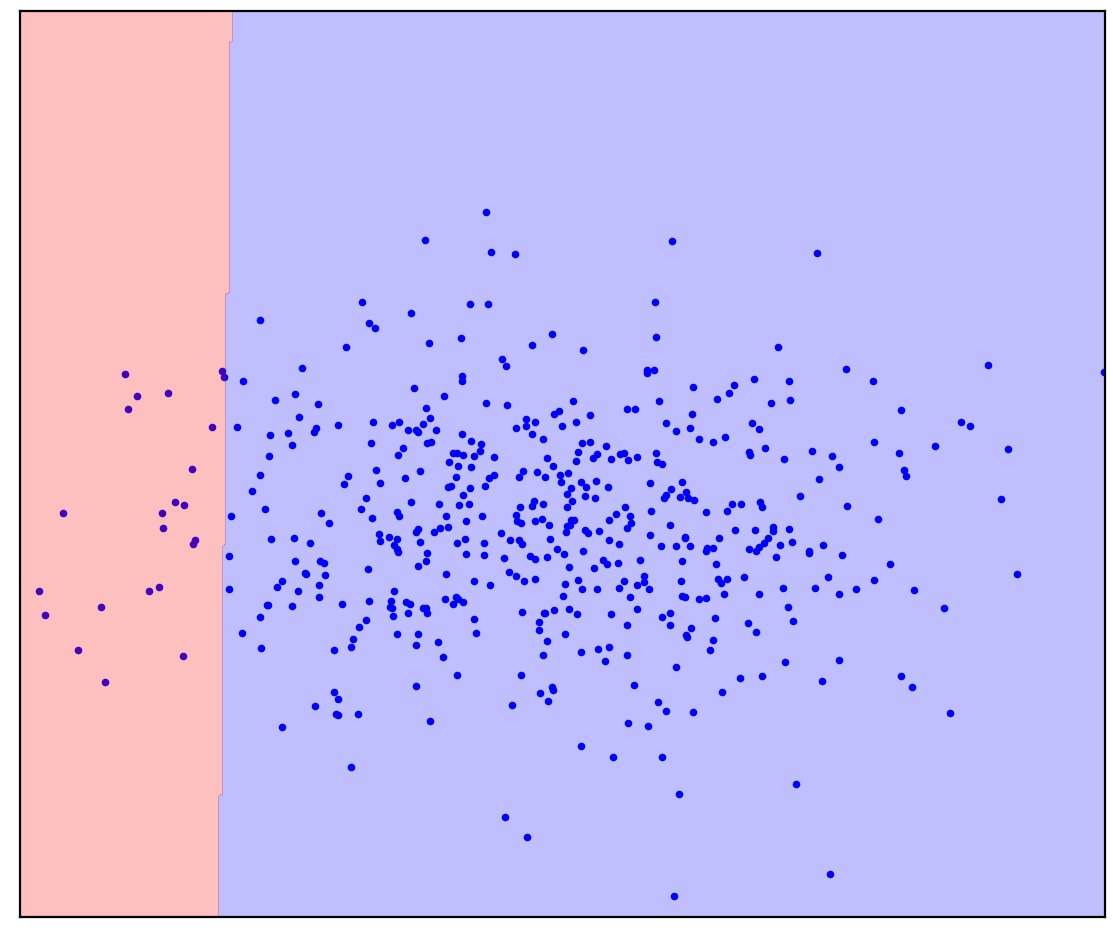
Sekarang saya akan menambahkan beberapa poin yang tidak terisi ke Gambar 1d yang berisi campuran positif dan negatif. Untuk terakhir kalinya, saya akan meminta Anda untuk melakukan upaya mental dan membayangkan garis yang memisahkan poin positif dan negatif. Tapi kali ini, Anda dapat menggunakan data yang tidak berlabel!

Angka: 1d. Poin positif (biru) dan tidak berlabel (merah). Poin yang tidak ditandai terdiri dari positif dan negatif
Jawabannya ada disini

. 1.
. 1.
Menjadi lebih mudah! Meskipun kami tidak tahu sebelumnya bagaimana setiap titik tak bertanda tertentu dihasilkan, kami dapat menandainya secara kasar dengan membandingkannya dengan titik positif. Titik merah yang terlihat seperti biru mungkin positif. Sebaliknya, yang berbeda mungkin negatif. Akibatnya, terlepas dari kenyataan bahwa kami tidak memiliki data negatif "murni", informasi tentang data tersebut dapat diperoleh dari campuran tanpa label dan digunakan untuk klasifikasi yang lebih akurat. Inilah yang dilakukan oleh algoritma pembelajaran Positif-Tanpa Label, yang ingin saya bicarakan.
pengantar
Pembelajaran Positive-Unlabeled (PU) dapat diterjemahkan sebagai “belajar dari data positif dan tidak berlabel”. Faktanya, pembelajaran PU adalah analog dari klasifikasi biner untuk kasus-kasus ketika hanya ada data berlabel dari satu kelas, tetapi tersedia campuran data tak berlabel dari kedua kelas tersebut. Dalam kasus umum, kita bahkan tidak tahu berapa banyak data dalam campuran yang berkorespondensi dengan kelas positif dan berapa banyak data dalam campuran yang berkorespondensi dengan kelas positif dan kelas negatif. Berdasarkan kumpulan data tersebut, kami ingin membuat pengklasifikasi biner: sama seperti dengan adanya data murni dari kedua kelas.
Sebagai contoh mainan, pertimbangkan pengklasifikasi untuk gambar kucing dan anjing. Kami memiliki beberapa gambar kucing dan banyak lagi gambar kucing dan anjing. Pada keluaran, kita ingin mendapatkan pengklasifikasi: sebuah fungsi yang memprediksi untuk setiap gambar kemungkinan seekor kucing digambarkan. Pada saat yang sama, pengklasifikasi dapat menandai campuran gambar yang ada untuk kucing dan anjing. Pada saat yang sama, mungkin sulit / mahal / memakan waktu / tidak mungkin memberi markup gambar secara manual untuk melatih pengklasifikasi, Anda ingin melakukannya tanpanya.
Pembelajaran PU adalah tugas yang cukup alami. Data yang ditemukan di dunia nyata seringkali kotor. Kemampuan untuk belajar dari data kotor tampaknya menjadi peretasan yang berguna dengan kualitas yang relatif tinggi. Meskipun demikian, saya bertemu secara paradoks hanya sedikit orang yang pernah mendengar tentang pembelajaran PU, dan bahkan lebih sedikit lagi yang tahu tentang metode tertentu. Jadi saya memutuskan untuk membicarakan area ini.

Angka: 2. Jürgen Schmidhuber dan Yann LeCun, NeurIPS 2020
Penerapan pembelajaran PU
Secara informal, saya akan membagi kasus-kasus di mana pembelajaran PU dapat bermanfaat menjadi tiga kategori.
Kategori pertama mungkin yang paling jelas: pembelajaran PU dapat digunakan sebagai pengganti klasifikasi biner biasa. Dalam beberapa tugas, data secara inheren sedikit kotor. Pada prinsipnya, kontaminasi ini dapat diabaikan dan pengklasifikasi konvensional dapat digunakan. Tetapi sangat mungkin untuk mengubah sedikit fungsi kerugian saat melatih pengklasifikasi (Kiryo et al., 2017) atau bahkan prediksi itu sendiri setelah pelatihan (Elkan & Noto, 2008) , dan klasifikasi menjadi lebih akurat.
Sebagai contoh, perhatikan identifikasi gen baru yang bertanggung jawab atas perkembangan gen penyakit. Pendekatan standar adalah memperlakukan gen penyakit yang telah ditemukan sebagai gen positif dan semua gen lain sebagai negatif. Jelas bahwa gen penyakit yang belum ditemukan mungkin ada dalam data negatif ini. Selain itu, tugasnya sendiri adalah mencari gen penyakit tersebut di antara data "negatif". Kontradiksi internal ini terlihat di sini: (Yang et al., 2012) . Para peneliti menyimpang dari pendekatan standar dan menganggap gen yang tidak terkait dengan gen penyakit yang sudah ditemukan sebagai campuran tak berlabel, kemudian menerapkan metode pembelajaran PU.
Contoh lain adalah pembelajaran penguatan dari demonstrasi ahli. Tantangannya adalah melatih agen untuk bertindak dengan cara yang sama seperti seorang ahli. Ini dapat dicapai dengan menggunakan metode pembelajaran imitasi adversarial generatif (GAIL). GAIL menggunakan arsitektur GAN-like (generative adversarial networks): agen menghasilkan lintasan sehingga diskriminator (pengklasifikasi) tidak dapat membedakannya dari demonstrasi pakar. Peneliti dari DeepMind baru-baru ini memperhatikan bahwa di GAIL, diskriminator memecahkan masalah pembelajaran PU (Xu & Denil, 2019)... Biasanya, diskriminator menganggap data ahli sebagai positif, dan data yang dihasilkan negatif. Perkiraan ini cukup akurat pada awal pelatihan ketika generator tidak dapat menghasilkan data yang terlihat positif. Namun, seiring berjalannya pelatihan, data yang dihasilkan semakin terlihat seperti data pakar hingga tidak dapat dibedakan oleh pembeda di akhir pelatihan. Oleh karena itu, peneliti (Xu & Denil, 2019) menganggap data yang dihasilkan sebagai data yang tidak berlabel dengan rasio campuran variabel. Kemudian, GAN dimodifikasi dengan cara yang sama saat menghasilkan gambar (Guo et al., 2020) .

Angka: 3. Pembelajaran PU sebagai analog dari klasifikasi PN standar
Pada kategori kedua, pembelajaran PU dapat digunakan untuk deteksi anomali sebagai analog dari klasifikasi satu kelas (OCC). Kita telah melihat di Pembukaan bagaimana tepatnya data yang tidak diberi tag dapat membantu. Semua metode OSS, tanpa pengecualian, dipaksa untuk membuat asumsi tentang distribusi data negatif. Misalnya, sebaiknya lingkari data positif menjadi elips (hipersfer dalam kasus multidimensi) yang di luarnya semua titik bernilai negatif. Dalam hal ini, kami mengasumsikan bahwa data negatif didistribusikan secara merata (Blanchard et al., 2010)... Daripada membuat asumsi seperti itu, metode pembelajaran PU dapat memperkirakan sebaran data negatif berdasarkan data yang tidak berlabel. Ini terutama penting jika distribusi kedua kelas tersebut tumpang tindih secara kuat (Scott & Blanchard, 2009) . Salah satu contoh deteksi anomali menggunakan pembelajaran PU adalah deteksi ulasan palsu (Ren et al., 2014) .

Angka: 4. Contoh review palsu
Deteksi korupsi dalam lelang pengadaan publik Rusia
Kategori ketiga dari pembelajaran PU dapat dikaitkan dengan masalah di mana klasifikasi biner atau kelas tunggal tidak dapat digunakan. Sebagai contoh, saya akan memberi tahu Anda tentang proyek kami untuk mendeteksi korupsi dalam lelang pengadaan publik Rusia (Ivanov & Nesterov, 2019) .
Menurut undang-undang, data lengkap tentang semua lelang pengadaan publik ditempatkan di domain publik untuk semua orang yang ingin menghabiskan waktu sebulan untuk menguraikannya. Kami telah mengumpulkan data dari lebih dari satu juta lelang yang diadakan dari 2014 hingga 2018. Siapa yang meletakkan, kapan dan berapa, siapa yang menang, selama periode apa pelelangan berlangsung, siapa yang memegang, apa yang dibeli - semua ini ada di data. Namun, tentu saja, tidak ada label "korupsi di sini", jadi Anda tidak dapat membuat pengklasifikasi biasa. Sebagai gantinya, kami menerapkan pembelajaran PU. Asumsi dasar: Peserta dengan keuntungan yang tidak adil akan selalu menang. Dengan asumsi ini, yang kalah dalam lelang dapat dianggap adil (positif), dan pemenang berpotensi tidak jujur (tanpa tag).Ketika diatur dengan cara ini, metode pembelajaran PU dapat menemukan pola yang mencurigakan dalam data berdasarkan perbedaan halus antara pemenang dan pecundang. Tentu saja, dalam praktiknya, kesulitan muncul: desain fitur yang akurat untuk pengklasifikasi, analisis interpretabilitas prediksi, dan verifikasi statistik asumsi tentang data diperlukan.
Menurut perkiraan kami yang sangat konservatif, sekitar 9% lelang dalam data tersebut korup, akibatnya negara kehilangan sekitar 120 juta rubel setahun. Kerugiannya mungkin tidak terlihat terlalu besar, tetapi lelang yang kami pelajari hanya menempati sekitar 1% dari pasar pengadaan publik.


Angka: 5. Pangsa lelang pengadaan publik yang korup di berbagai wilayah Rusia (Ivanov & Nesterov, 2019)
Ucapan terakhir
Agar tidak menimbulkan kesan bahwa PU adalah solusi untuk semua masalah umat manusia, saya akan menyebutkan jebakannya. Dalam klasifikasi konvensional, semakin banyak data yang kami miliki, semakin akurat pengklasifikasi tersebut. Selain itu, dengan meningkatkan jumlah data hingga tak terbatas, kita dapat mendekati pengklasifikasi ideal (menurut rumus Bayesian). Jadi, tangkapan utama dari pembelajaran PU adalah bahwa ini adalah masalah yang tidak diharapkan, yaitu masalah yang tidak dapat diselesaikan dengan pasti bahkan dengan jumlah data yang tidak terbatas. Situasi menjadi lebih baik jika proporsi dua kelas dalam data tidak berlabel diketahui, namun menentukan proporsi ini juga merupakan masalah yang tidak diharapkan (Jain et al., 2016)... Yang terbaik yang bisa kita tentukan adalah jarak proporsi. Selain itu, metode pembelajaran PU seringkali tidak menawarkan cara untuk memperkirakan proporsi ini dan menganggapnya diketahui. Ada metode terpisah yang memperkirakannya (tugas ini disebut Estimasi Proporsi Campuran), tetapi metode ini sering lambat dan / atau tidak stabil, terutama jika kedua kelas sangat tidak merata diwakili dalam campuran.
Dalam posting ini, saya berbicara tentang definisi intuitif dan penerapan pembelajaran PU. Selain itu, saya dapat berbicara tentang definisi formal pembelajaran PU dengan rumus dan penjelasannya, serta tentang metode pembelajaran PU klasik dan modern. Jika posting ini membangkitkan minat, saya akan menulis sekuelnya.
Bibliografi
Blanchard, G., Lee, G., & Scott, C. (2010). Semi-supervised novelty detection. Journal of Machine Learning Research, 11(Nov), 2973–3009.
Elkan, C., & Noto, K. (2008). Learning classifiers from only positive and unlabeled data. Proceeding of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining — KDD 08, 213. https://doi.org/10.1145/1401890.1401920
Guo, T., Xu, C., Huang, J., Wang, Y., Shi, B., Xu, C., & Tao, D. (2020). On Positive-Unlabeled Classification in GAN. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8385–8393.
Ivanov, D. I., & Nesterov, A. S. (2019). Identifying Bid Leakage In Procurement Auctions: Machine Learning Approach. ArXiv Preprint ArXiv:1903.00261.
Jain, S., White, M., Trosset, M. W., & Radivojac, P. (2016). Nonparametric semi-supervised learning of class proportions. ArXiv Preprint ArXiv:1601.01944.
Kiryo, R., Niu, G., du Plessis, M. C., & Sugiyama, M. (2017). Positive-unlabeled learning with non-negative risk estimator. Advances in Neural Information Processing Systems, 1675–1685.
Ren, Y., Ji, D., & Zhang, H. (2014). Positive Unlabeled Learning for Deceptive Reviews Detection. EMNLP, 488–498.
Scott, C., & Blanchard, G. (2009). Novelty detection: Unlabeled data definitely help. Artificial Intelligence and Statistics, 464–471.
Xu, D., & Denil, M. (2019). Positive-Unlabeled Reward Learning. ArXiv:1911.00459 [Cs, Stat]. http://arxiv.org/abs/1911.00459
Yang, P., Li, X.-L., Mei, J.-P., Kwoh, C.-K., & Ng, S.-K. (2012). Positive-unlabeled learning for disease gene identification. Bioinformatics, 28(20), 2640–2647.